API de Pandas en el próximo Apache Spark™ 3.2
por Hyukjin Kwon y Xinrong Meng
Free Edition reemplazó a Community Edition y ofrece funciones mejoradas sin costo. Comience a usar Free Edition hoy mismo.
Nos complace anunciar que la API de pandas será parte de la próxima versión de Apache Spark™ 3.2. pandas es una biblioteca potente y flexible, y ha crecido rápidamente hasta convertirse en una de las bibliotecas estándar de la ciencia de datos. Ahora los usuarios de pandas podrán aprovechar la API de pandas en sus clústeres de Spark existentes.
Hace unos años, lanzamos Koalas, un proyecto de código abierto que implementa la API de DataFrame de pandas sobre Spark, que fue ampliamente adoptado entre los científicos de datos. Recientemente, Koalas se fusionó oficialmente con PySpark mediante SPIP: Support pandas API layer on PySpark como parte del Proyecto Zen (consulte también Project Zen: Making Data Science Easier in PySpark del Data + AI Summit 2021).
Los usuarios de pandas podrán escalar sus cargas de trabajo con un simple cambio de una línea en el próximo lanzamiento de Spark 3.2:
Esta entrada de blog resume la compatibilidad de la API de pandas en Spark 3.2 y destaca las características, los cambios y la hoja de ruta más notables.
Escalabilidad más allá de una sola máquina
Una de las limitaciones conocidas de pandas es que no escala linealmente con el volumen de datos debido al procesamiento en una sola máquina. Por ejemplo, pandas falla por falta de memoria si intenta leer un conjunto de datos que es más grande que la memoria disponible en una sola máquina:
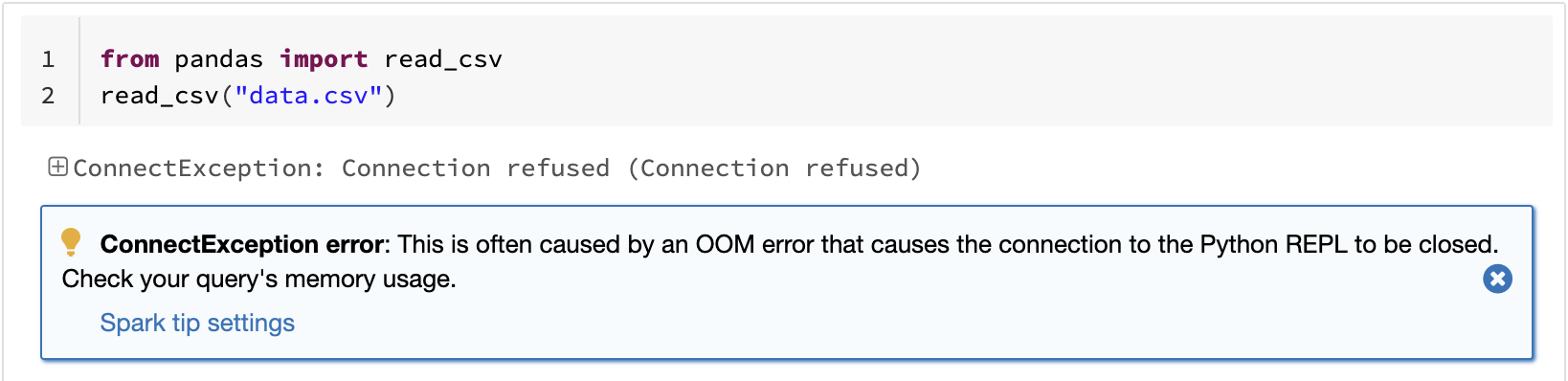
La API de pandas en Spark supera la limitación y permite a los usuarios trabajar con grandes conjuntos de datos aprovechando Spark:

La API de pandas en Spark también escala bien para grandes clústeres de nodos. El siguiente gráfico muestra su rendimiento al analizar un conjunto de datos Parquet de 15 TB con clústeres de diferentes tamaños. Cada máquina del clúster tiene 8 vCPU y 61 GiB de memoria.
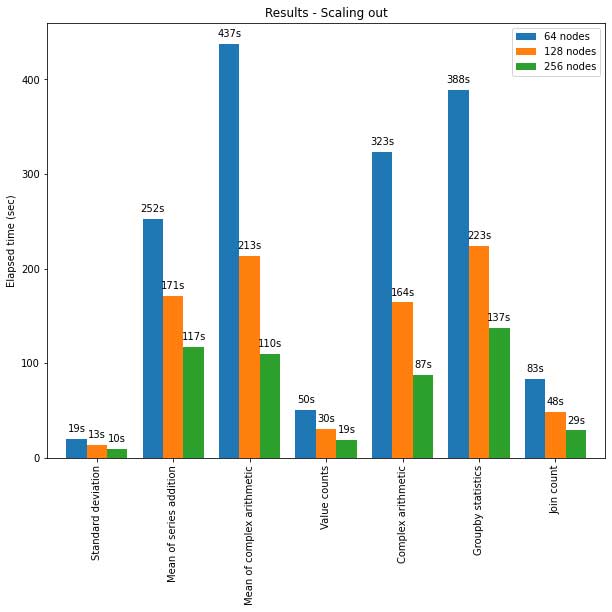
La ejecución distribuida de la API de pandas en Spark escala de forma casi lineal en esta prueba. El tiempo transcurrido disminuye a la mitad cuando se duplica el número de máquinas dentro de un clúster. La aceleración en comparación con una sola máquina también es significativa. Por ejemplo, en el benchmark de desviación estándar, un clúster de 256 máquinas puede procesar ~250 veces más datos que una sola máquina en aproximadamente el mismo tiempo (cada máquina tiene 8 vCPU y 61 GiB de memoria):
| Una sola máquina | Clúster de 256 máquinas | |
| Conjunto de datos Parquet | 60 GB | 60 GB x 250 (15 TB) |
| Tiempo transcurrido (seg) de la desviación estándar | 12s | 10 s |
Rendimiento optimizado en una sola máquina
La API de pandas en Spark suele superar el rendimiento de pandas incluso en una sola máquina gracias a las optimizaciones del motor de Spark. El gráfico a continuación demuestra la API de pandas en Spark en comparación con pandas en una máquina (con 96 vCPU y 384 GiB de memoria) frente a un conjunto de datos CSV de 130 GB:
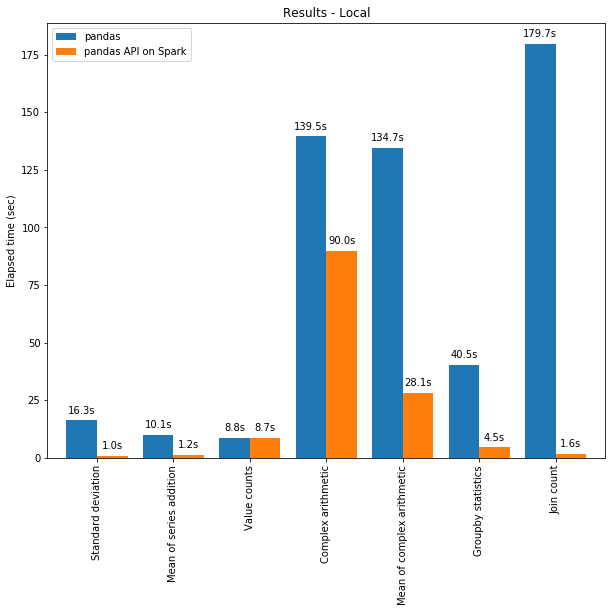
Tanto el multihilo como el Catalyst Optimizer de Spark SQL contribuyen al rendimiento optimizado. Por ejemplo, la operación Join count es ~4 veces más rápida con la generación de código de etapa completa: 5,9 s sin generación de código, 1,6 s con generación de código.
Spark tiene una ventaja especialmente significativa en el encadenamiento de operaciones. El optimizador de consultas Catalyst puede reconocer filtros para omitir datos de forma inteligente y puede aplicar uniones basadas en disco, mientras que pandas tiende a cargar todos los datos en la memoria en cada paso.
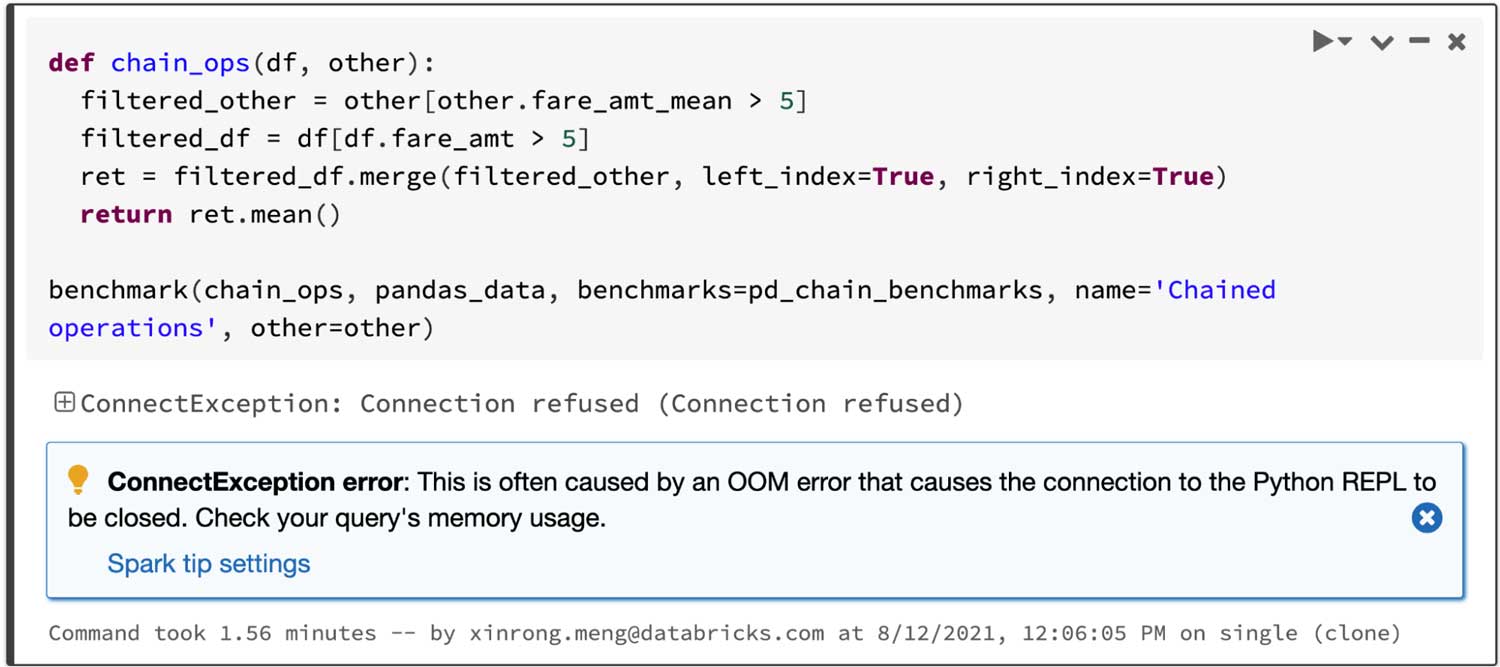
Considerando una consulta que une dos marcos filtrados y luego calcula el promedio del marco unido, la API de pandas en Spark se ejecuta con éxito en 4.5 s, mientras que pandas falla debido al error OOM (Out of memory) como se muestra a continuación:
Visualización interactiva de datos
pandas usa matplotlib por defecto, que proporciona gráficos estáticos. Por ejemplo, los siguientes códigos generan un gráfico estático:
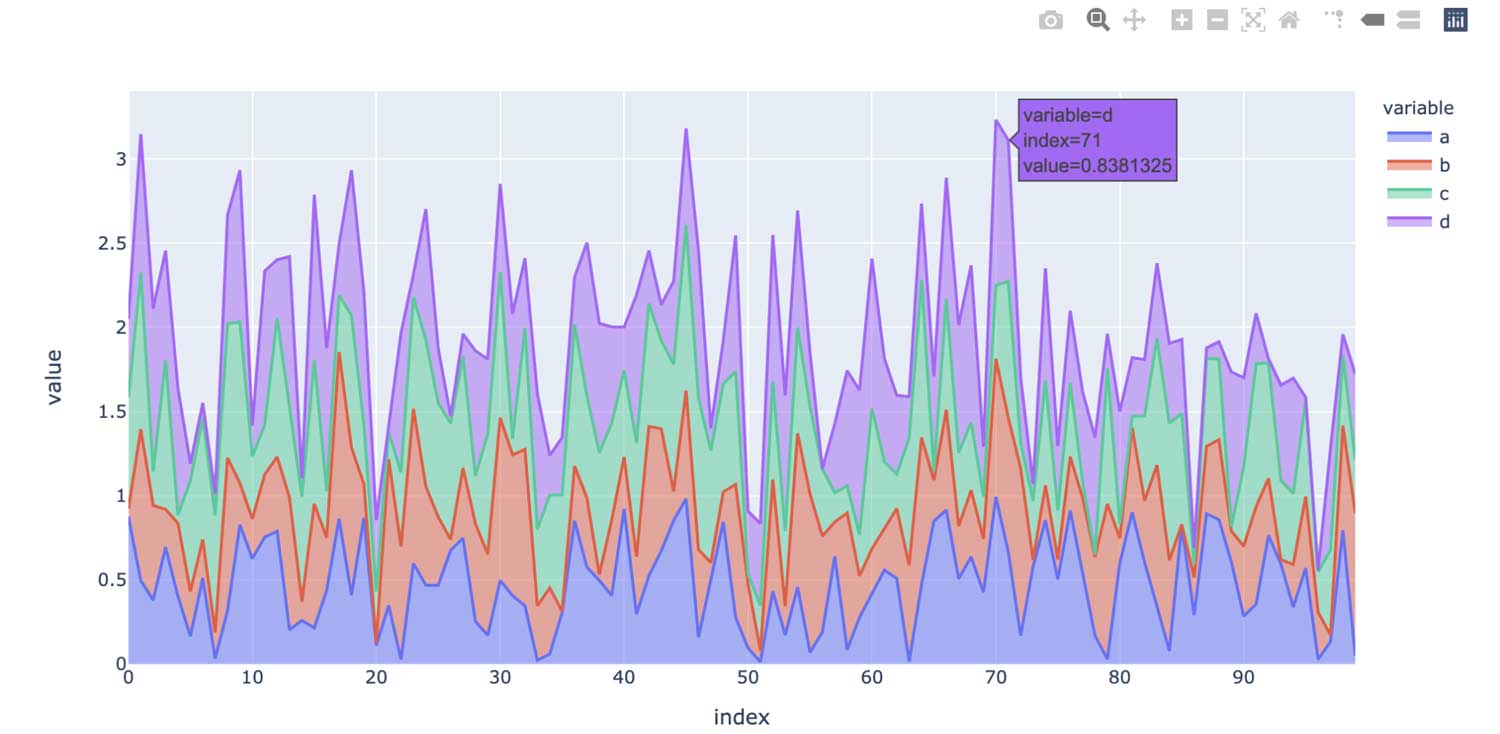
En cambio, la API de pandas en Spark usa un backend de plotly por defecto, que proporciona gráficos interactivos. Por ejemplo, permite a los usuarios acercar y alejar el zoom de forma interactiva. Según el tipo de gráfico, la API de pandas en Spark determina automáticamente la mejor manera de ejecutar el cálculo internamente al generar gráficos interactivos:
Aprovechamiento de la funcionalidad de analítica unificada en Spark
pandas está diseñado para la ciencia de datos de Python con procesamiento por lotes, mientras que Spark está diseñado para el análisis unificado, que incluye SQL, el procesamiento de streaming y el machine learning. Para cerrar la brecha entre ellos, la API de pandas en Spark ofrece muchas maneras diferentes para que los usuarios avanzados aprovechen el motor de Spark; por ejemplo:
- Los usuarios pueden consultar datos directamente a través de SQL con el motor de SQL optimizado de Spark, como se muestra a continuación:
- También es compatible con la sintaxis de interpolación de cadenas para interactuar con objetos de Python de forma natural:
- La API de pandas en Spark también admite el procesamiento de streaming:
- Los usuarios pueden llamar fácilmente a las bibliotecas de aprendizaje automático escalables en Spark:
Consulta también la publicación del blog sobre la interoperabilidad entre PySpark y la API de pandas en Spark.
¿Y ahora qué?
Para las próximas versiones de Spark, la hoja de ruta se centra en lo siguiente:
• Más sugerencias de tipo (type hints)
Actualmente, el código en la API de pandas en Spark está parcialmente tipado, lo que todavía permite el análisis estático y el autocompletado. En el futuro, todo el código estará completamente tipado.
• Mejoras de rendimiento
Hay varios lugares en la API de pandas en Spark donde podemos mejorar aún más el rendimiento al interactuar más de cerca con el motor y el optimizador de SQL.
• Estabilización
Hay varios lugares que corregir, especialmente en relación con los valores faltantes, como NaN y NA, que tienen casos extremos de diferencias de comportamiento.
Además, la API de pandas en Spark seguirá y adaptará su comportamiento a la última versión de pandas en estos casos.
• Mayor cobertura de la API
La API de pandas en Spark alcanzó una cobertura del 83 % de la API de pandas, y este número sigue aumentando. Ahora el objetivo es alcanzar el 90 %.
Por favor, registre un problema si hay errores o características que necesita y que no están, y, por supuesto, siempre agradecemos las contribuciones de la comunidad.
Comenzar
Si quiere probar la API de pandas en Spark en Databricks Runtime 10.0 Beta (próximo Apache Spark 3.2), regístrese en Databricks Community Edition o Databricks Trial de forma gratuita y empiece a usarlo en cuestión de minutos.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.