Búsqueda 3 veces más rápida: escalado en paralelo en tiempo de prueba con Instructed-Retriever-1
Hoy anunciamos una actualización importante que hace que Agent Bricks Knowledge Assistant sea más rápido y de mayor calidad. El tiempo de generación de respuestas se ha reducido a la mitad (2x) y el tiempo de búsqueda ha disminuido más de 3 veces (3x), lo que sitúa el Time To First Token (TTFT) en unos dos segundos.¹ De este modo, los usuarios de Knowledge Assistant obtendrán respuestas notablemente más rápidas en todos sus casos de uso, sin necesidad de reconfiguración y sin perder calidad.
Estas mejoras son posibles gracias a Instructed-Retriever-1, un modelo especializado en recuperación de información diseñado para el escalado paralelo en tiempo de prueba (parallel test-time scaling). A diferencia de la recuperación agéntica estándar, en la que un agente trabaja de forma secuencial y analiza cada resultado antes de decidir el siguiente paso, nuestro enfoque distribuye este trabajo en paralelo. Instructed-Retriever-1 es un único modelo entrenado para ambas etapas de recuperación: la generación de consultas para aumentar la exhaustividad (recall) y la reclasificación (reranking) para aumentar la precisión, ejecutadas en paralelo para mantener una latencia baja. En esta publicación, describimos cómo este enfoque logra un rendimiento óptimo de Pareto, cómo entrenamos un único modelo para dar soporte a todo el pipeline de recuperación y cómo validamos el rendimiento en cargas de trabajo empresariales reales.
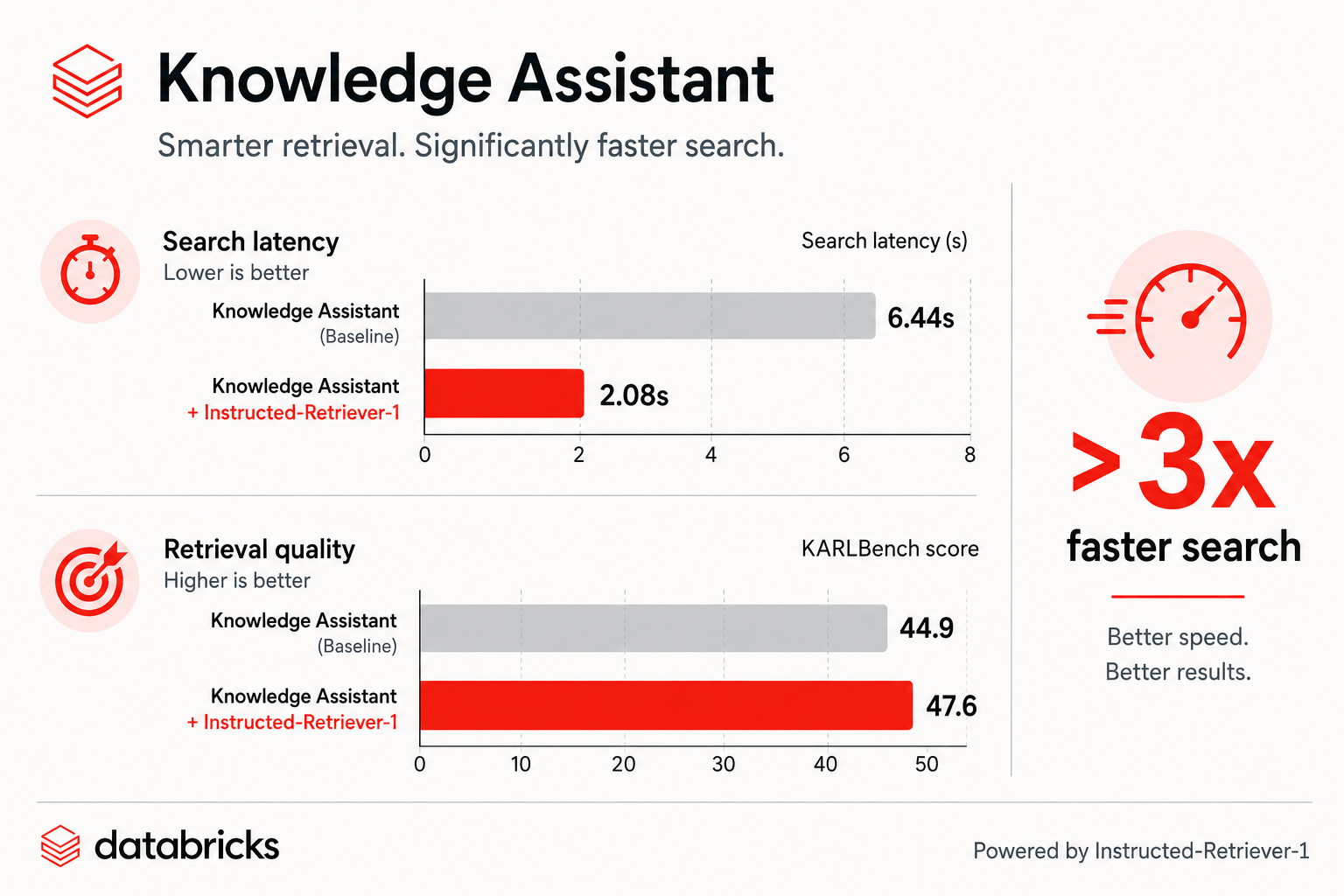
Figura: En KARLBench, Knowledge Assistant con Instructed-Retriever-1 mejora tanto la latencia de búsqueda como la calidad de la recuperación.
1. Escalado paralelo en tiempo de prueba para búsquedas
Nuestra investigación anterior demostró que la calidad puede mejorar con cómputo adicional en tiempo de prueba (test-time compute). Sin embargo, la mayoría de los sistemas de búsqueda agénticos actuales dedican ese cómputo a operaciones secuenciales, como llamadas a herramientas, bucles de razonamiento y acción (reason-act loops) y razonamiento de cadena de pensamiento (chain-of-thought). Aunque estos métodos mejoran la calidad de la búsqueda, lo hacen a costa de una latencia y un coste sustancialmente mayores. Para entrenar Instructed-Retriever-1, tomamos un camino diferente: en lugar de escalar el cómputo de forma secuencial, lo paralelizamos durante la fase de búsqueda inicial. Al ampliar el rango de evidencias recuperadas y seleccionar el contexto más relevante desde el principio, logramos una búsqueda muy eficaz con una latencia significativamente menor.
La mejora de la búsqueda inicial depende en gran medida del entorno de entrenamiento (training harness). Nuestro entorno proporciona al modelo las instrucciones del usuario y el esquema preciso del índice de recuperación subyacente, y los propaga a todas las etapas posteriores de generación de consultas y filtros, reclasificación y generación de respuestas. Ya describimos cómo lograr esto en nuestra publicación anterior del blog sobre Instructed Retriever, y utilizamos el mismo entorno de búsqueda para entrenar nuestro modelo Instructed-Retriever-1. Este enfoque es especialmente importante para las preguntas empresariales, que a menudo implican restricciones específicas del dominio, como el período de tiempo, la organización, el tipo de documento o el área de producto.
La generación paralela de consultas y filtros mejora la exhaustividad (recall) del conjunto de candidatos al explorar simultáneamente múltiples formulaciones y aspectos de la misma solicitud. Esto permite al sistema realizar búsquedas más amplias manteniendo una latencia baja. Una búsqueda más amplia plantea un desafío de agregación. Diferentes formulaciones pueden devolver fragmentos (chunks) duplicados o solo parcialmente relevantes. Para seleccionar el contexto más útil del conjunto de candidatos fusionado, utilizamos un reclasificador por grupos multipivote (multi-pivot groupwise reranker). Los candidatos se clasifican en grupos paralelos, cada uno de ellos anclado por uno o más fragmentos pivote (pivot chunks), y las clasificaciones de los grupos se fusionan en un orden final. Esto aprovecha las ventajas clave de comparar la evidencia en contexto, al tiempo que mantiene la eficiencia de la reclasificación.
Juntas, estas etapas proporcionan dos controles de escalado en tiempo de prueba: aumentar el número de formulaciones de consultas y filtros mejora la exhaustividad (recall), mientras que aumentar el número de pivotes mejora la precisión. Dado que ambas etapas pueden utilizar el paralelismo, el sistema puede intercambiar un mayor cómputo en tiempo de prueba por un contexto de mayor calidad, manteniendo al mismo tiempo una latencia baja.
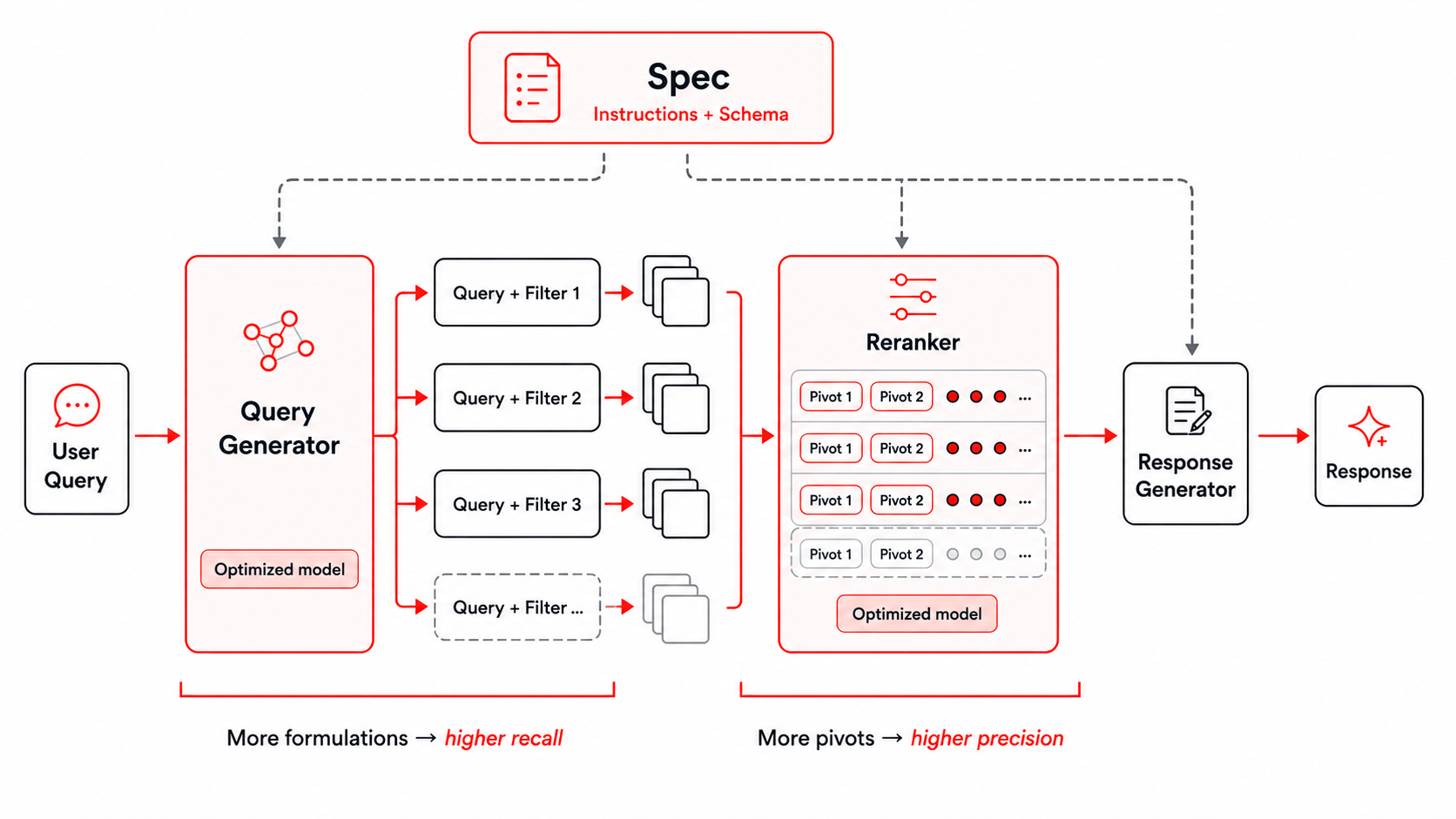
Figura: El entorno de búsqueda utilizado para Instructed-Retriever-1.
2. Entrenamiento de Instructed-Retriever-1
El escalado paralelo en tiempo de prueba para búsquedas requiere un modelo que pueda hacer bien dos cosas: generar búsquedas eficaces y evaluar la evidencia recuperada. Entrenamos Instructed-Retriever-1 como un único modelo especializado en recuperación que admite la generación paralela de consultas y la reclasificación. El resultado es un modelo que iguala la calidad de recuperación de Claude Sonnet 4.5 en KARLBench, manteniendo al mismo tiempo una latencia baja.
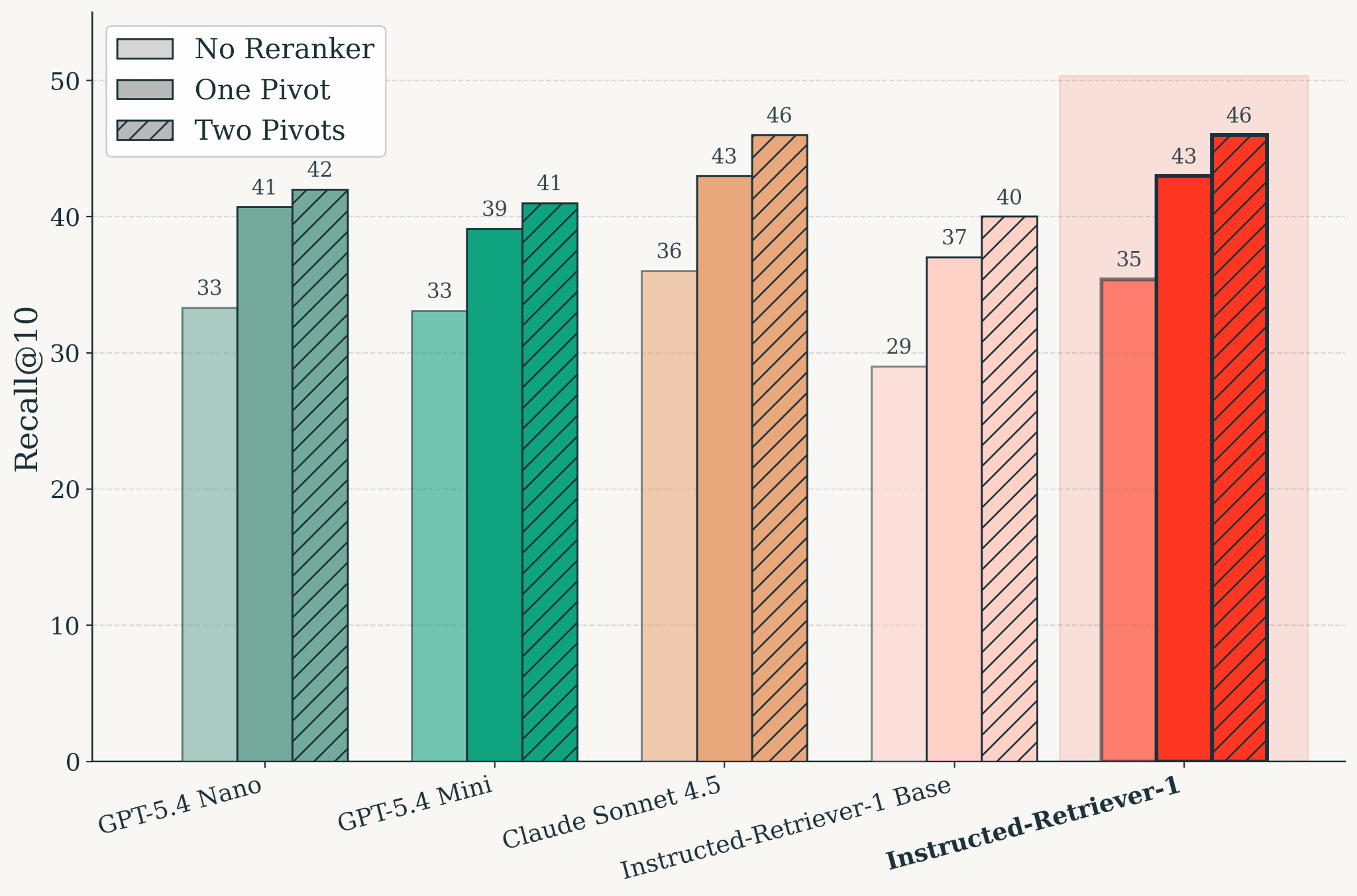
Figura: Calidad de recuperación en KARLBench después del entrenamiento, evaluada en distintas configuraciones de reclasificación. Instructed-Retriever-1 iguala la calidad de recuperación de Claude Sonnet 4.5. En todos los modelos, la reclasificación basada en pivotes mejora el Recall@10 en comparación con la configuración sin reclasificador, y el uso de dos pivotes mejora aún más la calidad en comparación con un solo pivote.
Para preparar los datos para el entrenamiento, creamos entornos de recuperación sintéticos de estilo empresarial a partir de un amplio corpus de preentrenamiento, de forma independiente de nuestro benchmark de evaluación. Los creamos utilizando el enfoque de síntesis de datos agénticos descrito en el informe KARL. Los entornos resultantes reflejan el tipo de tareas que Knowledge Assistant debe gestionar, como la búsqueda de datos objetivos, el resumen, la recomendación, la resolución de problemas y el soporte para la toma de decisiones en corpus que combinan documentos no estructurados con metadatos estructurados.
El modelo se entrena en dos etapas para capturar múltiples capacidades de búsqueda. El modelo resultante admite tanto la generación de consultas y filtros como capacidades de recuperación de tipo verificación, lo que permite las dos etapas que hacen que el escalado paralelo en tiempo de prueba sea útil en la práctica.
3. Validación de Instructed-Retriever-1 en producción
Mejorar la recuperación solo es importante si funciona en cargas de trabajo reales y se ajusta a las restricciones de latencia de producción. Evaluamos Instructed-Retriever-1 en un conjunto de datos interno a gran escala representativo del uso de Knowledge Assistant, midiendo si los dos mecanismos de escalado presentados anteriormente mejoran la calidad de la recuperación: la generación paralela de consultas y filtros para la exhaustividad (recall), y la reclasificación multipivote para la precisión.
Figura: Demostración de Knowledge Assistant impulsado por Instructed-Retriever-1.
Calidad de recuperación en cargas de trabajo reales
Nuestro conjunto de datos de evaluación se basa en cargas de trabajo reales de Knowledge Assistant, donde las respuestas útiles a menudo requieren múltiples pruebas de respaldo en lugar de un único documento de referencia (ground-truth). Evaluamos la recuperación en dos etapas. En primer lugar, medimos la latencia y la calidad de la generación de consultas en todos los sistemas candidatos. Para evaluar la calidad, utilizamos puntuaciones de rúbrica basadas en un LLM como juez (LLM-judge) para medir la especificidad, la amplitud y la relevancia. Estas métricas determinan si las consultas generadas están bien orientadas, cubren los aspectos importantes de la solicitud y siguen siendo útiles para responder a la pregunta.
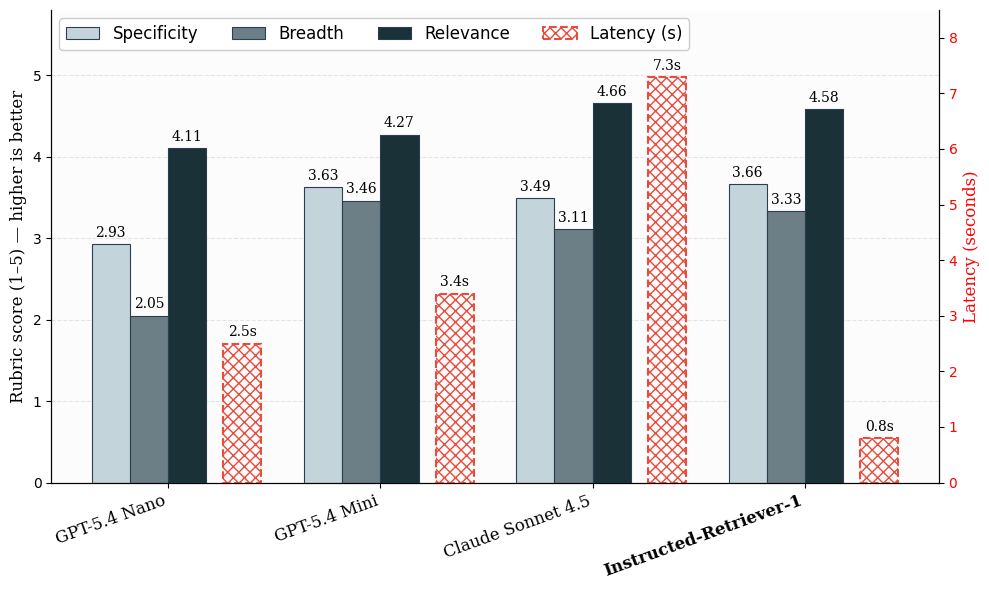
Figura: Calidad y latencia de la generación de consultas en ejemplos internos similares a los de producción. Las puntuaciones medias de la rúbrica evalúan la calidad de la generación de consultas en cuanto a especificidad, amplitud y relevancia en una escala del 1 al 5. La latencia se calcula para una etapa de generación de consultas.
Para el reranking, mantenemos fijo el conjunto de candidatos recuperados y evaluamos con qué eficacia cada reranker muestra la evidencia más útil. Para obtener etiquetas de relevancia densas, utilizamos un juez LLM para calificar cada fragmento en una escala de relevancia de 0 a 3 al estilo TREC, y luego calculamos nDCG@10 a partir de las clasificaciones resultantes. Claude Sonnet 4.5 e Instructed-Retriever-1 obtienen una puntuación de 80.1 y 81.0 de nDCG@10, respectivamente. Esto representa mejoras del +12.8% y +14.1% en comparación con un escenario sin reranking, lo que demuestra la efectividad de nuestro reranker grupal multipivote.
En general, en cargas de trabajo realistas, Instructed-Retriever-1 tiene un sólido rendimiento en todas las métricas de la rúbrica de generación de consultas y sigue siendo competitivo con la línea base más sólida en reranking. Esto respalda el uso de un único modelo especializado en recuperación tanto para la generación de consultas como para la selección de candidatos.
Rendimiento de servicio
El escalado paralelo en tiempo de prueba solo es útil si el cómputo adicional se puede servir de manera eficiente y escala con el número de búsquedas. Para lograr esto, Instructed-Retriever-1 utiliza una arquitectura de Mixture-of-Experts y optimizaciones de servicio que incluyen cuantización FP8,2 decodificación especulativa y un ajuste adicional de la infraestructura para todo el pipeline de recuperación. En nuestras evaluaciones, FP8 no muestra degradación de calidad, al tiempo que mejora la velocidad de inferencia y el rendimiento de procesamiento en comparación con BF16.3 La decodificación especulativa añade otra aceleración de más del 30% para la ruta combinada de generación de consultas y reranking.
Conclusión
Esta actualización incorpora el escalado paralelo en tiempo de prueba (Parallel Test-Time Scaling) a la pila de búsqueda en producción. El sistema realiza una recuperación amplia mediante la generación paralela de consultas y filtros, y luego realiza un reranking preciso con una comparación de evidencia multipivote. Instructed-Retriever-1 impulsa ambas etapas con un único modelo especializado en recuperación, entrenado para la generación de búsquedas y la clasificación de evidencias. El resultado es un Knowledge Assistant que es mejor y más rápido: el tiempo de búsqueda disminuye más de 3 veces, el tiempo de generación de respuestas disminuye 2 veces, el TTFT es de alrededor de 2 s y la latencia de extremo a extremo está constantemente por debajo de los 10 s en nuestra configuración de evaluación sin conexión.¹ Los primeros usuarios, como la Universidad de Baylor y otros, ya están notando la diferencia.
"(La nueva experiencia es) más concisa, con una sensación de agilidad que muestra la información clave más rápido, una mejora notable de la UX para nuestros casos de uso”. —Kyle Van Pelt, Director de Procesos y Gobernanza, Gestión de Inscripciones en la Universidad de Baylor.
Comience a exigirle más a su Knowledge Assistant hoy mismo. Instructed-Retriever-1 ha comenzado a implementarse para todos los clientes, lo que ayuda a los equipos a recuperar contexto de mayor calidad con menos tiempo de espera; puede hacer más preguntas, descubrir más conocimientos y pasar de la pregunta a la respuesta más rápido. Pruébelo ahora.
1 Las estimaciones de latencia se miden como el promedio de las evaluaciones sin conexión, con una longitud promedio de alrededor de 256 tokens de salida. La latencia real puede variar según la estructura de los datos en instancias y consultas específicas de Knowledge Assistant.
2 Utilizamos la biblioteca ModelOpt de NVIDIA para la cuantización FP8.
3 Evaluamos los modelos BF16 y FP8 en KARLBench en 10 ensayos. FP8 no mostró una degradación de calidad estadísticamente significativa con respecto a BF16: la diferencia de puntuación media fue de +0.33 puntos, con un error estándar de 1.69 puntos y un intervalo de confianza del 95% de [-2.99, 3.65].
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.