Despliegue LLM privados con Model Serving de Databricks
por Ahmed Bilal, Ankit Mathur, Kasey Uhlenhuth y Joshua Hartman
¡Nos complace anunciar la versión preliminar pública del soporte de optimización de GPU y LLM para Databricks Model Serving! Con este lanzamiento, puede desplegar modelos de IA de código abierto o sus propios modelos personalizados de cualquier tipo, incluidos los LLM y los modelos de visión, en la plataforma Lakehouse. Databricks Model Serving optimiza automáticamente su modelo para el servicio de LLM, lo que proporciona un rendimiento de primer nivel sin necesidad de configuración.
Databricks Model Serving es el primer producto de servicio de GPU sin servidor desarrollado en una plataforma unificada de datos e IA. Esto le permite crear e implementar aplicaciones de IA generativa, desde la ingesta de datos y el ajuste fino hasta la implementación y el monitoreo de modelos, todo en una sola plataforma.
Crea aplicaciones de IA generativa con Model Serving de Databricks
"Con Databricks Model Serving, podemos integrar IA generativa en nuestros procesos para mejorar la experiencia del cliente y aumentar la eficiencia operativa. Model Serving nos permite implementar modelos de LLM mientras mantenemos el control total sobre nuestros datos y modelos". —Ben Dias, Director de Ciencia de Datos y Analítica en easyJet - Más información
Aloja modelos de IA de forma segura sin preocuparte por la administración de la infraestructura
Databricks Model Serving ofrece una única solución para implementar cualquier modelo de IA sin la necesidad de comprender una infraestructura compleja. Esto significa que puede implementar cualquier modelo de lenguaje natural, de visión, de audio, tabular o personalizado, independientemente de cómo se haya entrenado, ya sea creado desde cero, de código abierto o ajustado con datos propios. Simplemente, registre su modelo con MLflow y prepararemos automáticamente un contenedor listo para producción con bibliotecas de GPU como CUDA y lo implementaremos en GPU sin servidor. Nuestro servicio totalmente administrado se encargará de todo el trabajo pesado por usted, lo que elimina la necesidad de administrar instancias, mantener la compatibilidad de versiones y aplicar parches. El servicio escalará las instancias automáticamente para adaptarse a los patrones de tráfico, lo que ahorra costos de infraestructura y optimiza el rendimiento de la latencia.
"Databricks Model Serving está acelerando nuestra capacidad para infundir inteligencia en una amplia gama de casos de uso, que van desde aplicaciones de búsqueda semántica significativas hasta la predicción de tendencias de los medios. Al abstraer y simplificar el intrincado funcionamiento del escalado de CUDA y servidores GPU, Databricks nos permite centrarnos en nuestras áreas reales de especialización, es decir, expandir el uso de la IA de Condé Nast en todas nuestras aplicaciones sin la molestia y la carga de la infraestructura".
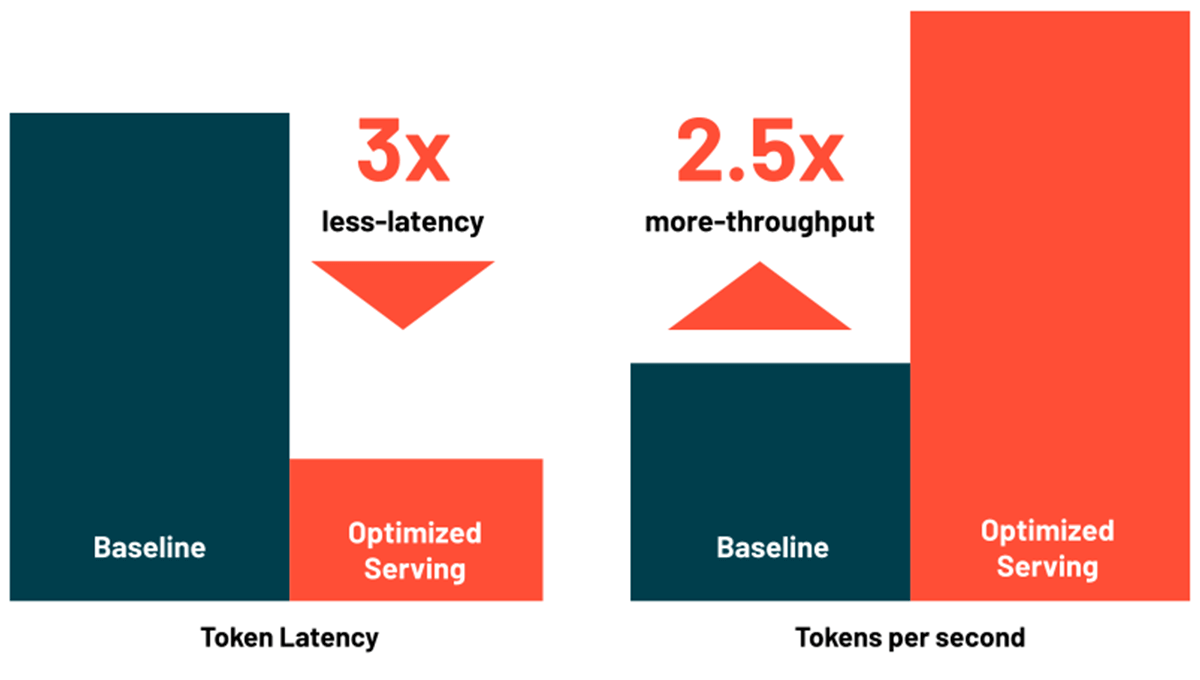
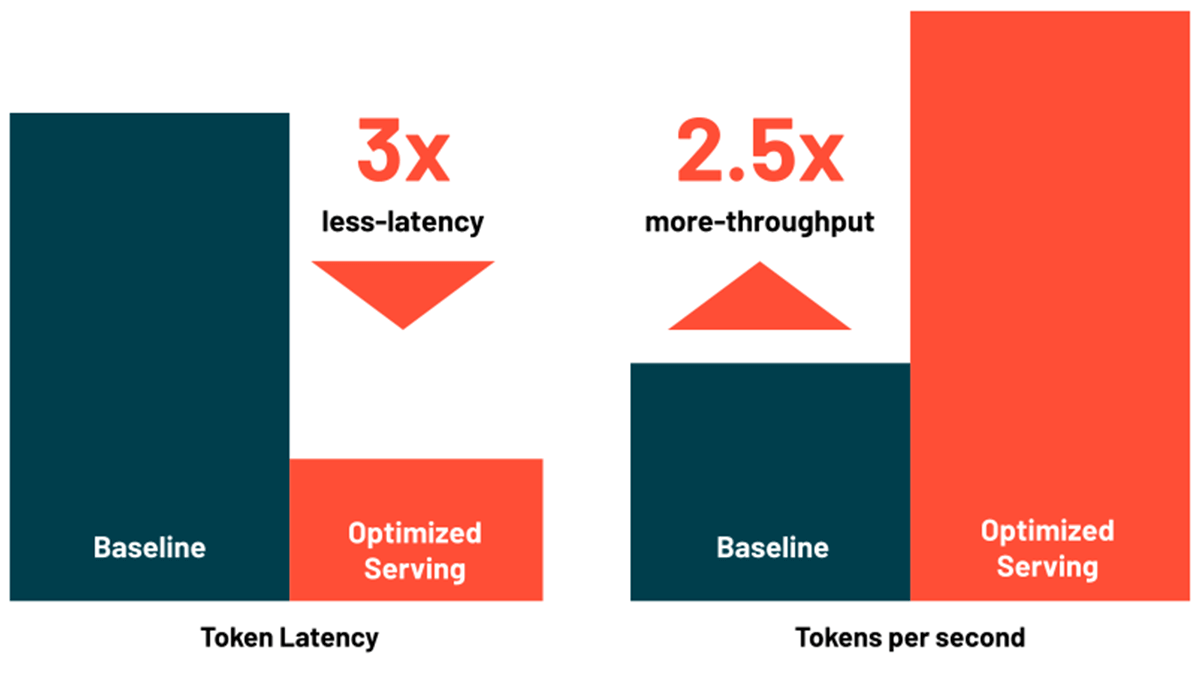
Reduce la latencia y el costo con el servicio optimizado de LLM
Model Serving de Databricks ahora incluye optimizaciones para servir grandes modelos de lenguaje (LLM) de manera eficiente, lo que reduce la latencia y el costo hasta 3-5 veces. Usar LLM Serving optimizado es increíblemente fácil: solo proporciona el modelo junto con sus pesos OSS o ajustados y nosotros nos encargaremos del resto para garantizar que el modelo se sirva con un rendimiento optimizado. Esto te permite enfocarte en integrar el LLM en tu aplicación en lugar de escribir bibliotecas de bajo nivel para las optimizaciones del modelo. Databricks Model Serving optimiza automáticamente la clase de modelos MPT y Llama2, y próximamente será compatible con más modelos.
{kind=link}
Acelere las implementaciones a través de las integraciones de IA de Lakehouse
Al llevar los LLM a producción, no se trata solo de implementar modelos. También debe complementar el modelo con técnicas como la generación aumentada por recuperación (RAG), el ajuste fino de parámetros eficientes (PEFT) o el ajuste fino estándar. Además, debes evaluar la calidad del LLM y supervisar continuamente el rendimiento y la seguridad del modelo. Esto a menudo provoca que los equipos dediquen un tiempo considerable a la integración de herramientas dispares, lo que aumenta la complejidad operativa y crea una sobrecarga de mantenimiento.
El Servicio de Modelos de Databricks se basa en una plataforma unificada de datos e IA que te permite gestionar todo el LLMOps, desde la ingesta de datos y el ajuste fino hasta la implementación y el monitoreo, todo en una sola plataforma, lo que crea una vista consistente a lo largo del ciclo de vida de la IA que acelera la implementación y minimiza los errores. El Servicio de Modelos se integra con varios servicios de LLM dentro de la Lakehouse, entre ellos:
- Ajuste fino: mejore la precisión y diferénciese ajustando los modelos fundacionales con sus datos propios directamente en Lakehouse.
- Integración de la búsqueda vectorial: integra y realiza búsquedas vectoriales de forma fluida para casos de uso de generación aumentada por recuperación y búsqueda semántica. Regístrate para la vista previa aquí.
- Gestión de LLM integrada: Se integra con Databricks AI Gateway como una capa de API central para todas sus llamadas de LLM.
- MLflow: evalúa, compara y gestiona los LLM a través de PromptLab de MLflow.
- Calidad y diagnósticos: Captura automáticamente las solicitudes y respuestas en una tabla Delta para monitorear y depurar modelos. También puedes combinar estos datos con tus etiquetas para generar conjuntos de datos de entrenamiento a través de nuestra asociación con Labelbox.
- Gobernanza unificada: administre y gobierne todos los activos de datos y de IA, incluidos los que consume y produce Model Serving, con Unity Catalog.
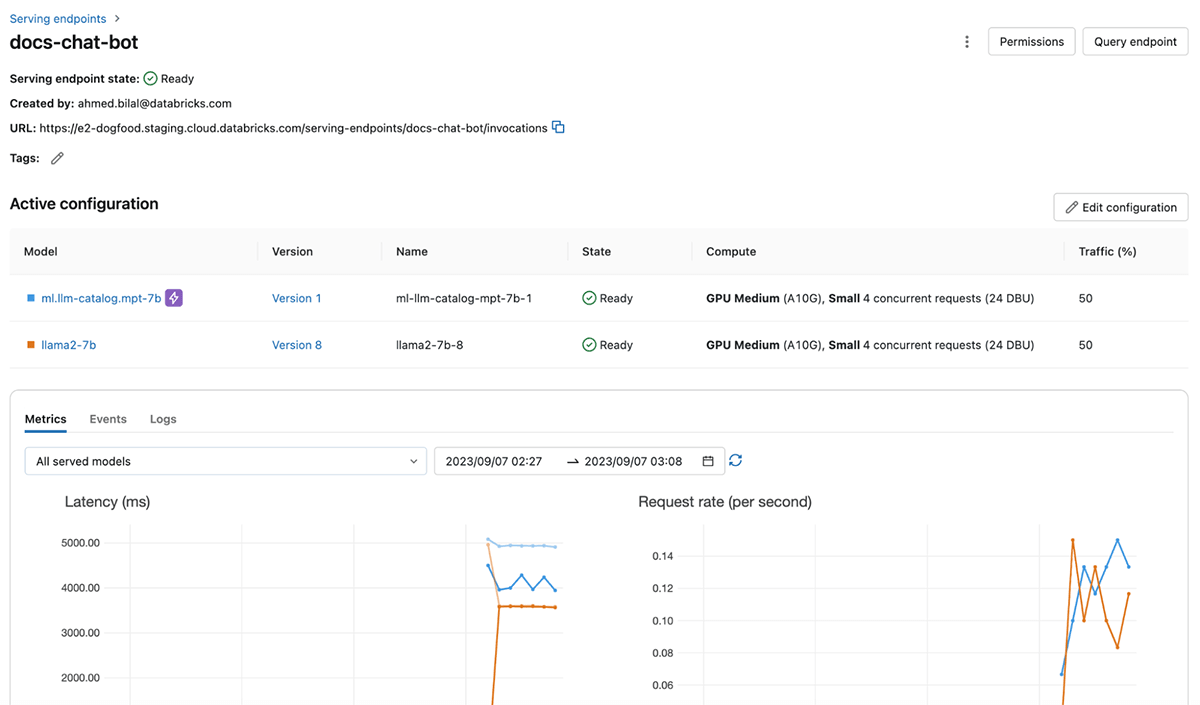
Brinde confiabilidad y seguridad al servicio de LLM
Model Serving de Databricks proporciona recursos de computación dedicados que permiten la inferencia a escala, con control total sobre los datos, el modelo y la configuración de la implementación. Al obtener capacidad dedicada en la región de la nube que elija, se beneficia de una baja latencia de sobrecarga, un rendimiento predecible y garantías respaldadas por SLA. Además, tus cargas de trabajo de servicio están protegidas por múltiples capas de seguridad, lo que garantiza un entorno seguro y confiable incluso para las tareas más sensibles. Hemos implementado varios controles para satisfacer las necesidades de cumplimiento únicas de los sectores altamente regulados. Para obtener más detalles, visite esta página o póngase en contacto con el equipo de su cuenta de Databricks.
Primeros pasos con el servicio de GPU y LLM
- ¡Pruébelo! Implementa tu primer LLM en Model Serving de Databricks leyendo el tutorial de introducción (AWS | Azure).
- Profundiza en la documentación de Databricks Model Serving.
- Conozca más sobre el enfoque de Databricks para la IA generativa aquí.
- Ruta de aprendizaje para ingenieros de IA generativa: toma cursos a tu propio ritmo, a pedido y dirigidos por un instructor sobre IA generativa
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.