Databricks para la Fundación Good and Virtue: Asociándose para conectar voluntarios médicos con servicios de salud críticos en 72 países
por Priyanka Mehta y Shaunak Sen
- La Virtue Foundation se asoció con Databricks for Good para aprovechar la IA y mejorar los resultados de la atención médica mundial.
- El resultado ha permitido a la Virtue Foundation emparejar mejor las habilidades de los médicos con las oportunidades de voluntariado en países en desarrollo donde esas habilidades son más necesarias.
- Juntos, los equipos de Databricks y Virtue Foundation están proporcionando conjuntos de datos básicos actualizados en un formato fácilmente accesible y procesable.
Introducción
Virtue Foundation es una organización sin fines de lucro centrada en la prestación de servicios de salud a nivel mundial y la creación de un mercado eficiente para la atención médica filantrópica global. Hasta la fecha, han brindado atención a más de 50,000 pacientes con un enfoque especial en Ghana y Mongolia. La base de este mercado es la curación de datos de instalaciones de atención médica globales a través de VF Match, una plataforma que conecta a profesionales médicos con oportunidades de voluntariado en 72 países de ingresos bajos y bajos-medios. Databricks for Good se ha asociado estrechamente con Virtue Foundation desde 2024 para aprovechar la IA en la agregación de datos de estos países y hacerlos accionables.
Una prueba de concepto inicial demostró que los LLM podían extraer información estructurada de fuentes de datos web dispares para crear un mapa de la infraestructura de atención médica y, lo más importante, las brechas en los servicios en áreas con pocos recursos. Sin embargo, escalar esta funcionalidad y llevarla a producción planteó muchos desafíos. Desde esa primera iteración, hemos construido una plataforma basada en Databricks que ha transformado la prueba de concepto en un sistema de calidad de producción que agrega datos de miles de instalaciones de atención médica y organizaciones sin fines de lucro en todo el mundo.
En este artículo, detallamos cómo mejoramos nuestro trabajo anterior para permitir aún más a Virtue Foundation conectar a su comunidad de voluntarios médicos con necesidades críticas en estos países.
Construyendo la Base: 72 Países de Datos de Atención Médica
El núcleo de VF Match es el Foundational Data Refresh (FDR): un conjunto de datos integral de instalaciones de atención médica y organizaciones sin fines de lucro construido desde cero a partir de diversas fuentes basadas en la web. Ingerimos y actualizamos sistemáticamente datos de 72 países de ingresos bajos y bajos-medios de todo el mundo.
Dos fuentes de datos complementarias impulsan esta actualización:
- Overture Maps: Un conjunto de datos geoespaciales de código abierto de Meta y Microsoft, que proporciona ubicaciones autorizadas para instalaciones de atención médica.
- Bright Data: Infraestructura industrial de web scraping que captura información en tiempo real de toda Internet.
El corazón del FDR es un pipeline de extracción de información impulsado por los modelos GPT de OpenAI. Procesar más de 25 millones de páginas web a través de LLMs con garantías de producción requirió repensar los pipelines de inferencia de LLM tradicionales. En lugar de intentar la extracción en un solo paso, nuestro pipeline divide la tarea en pasos específicos: clasificar la relevancia médica, identificar el tipo de organización (ya sea una instalación médica o una ONG) y extraer especialidades, equipos y procedimientos.
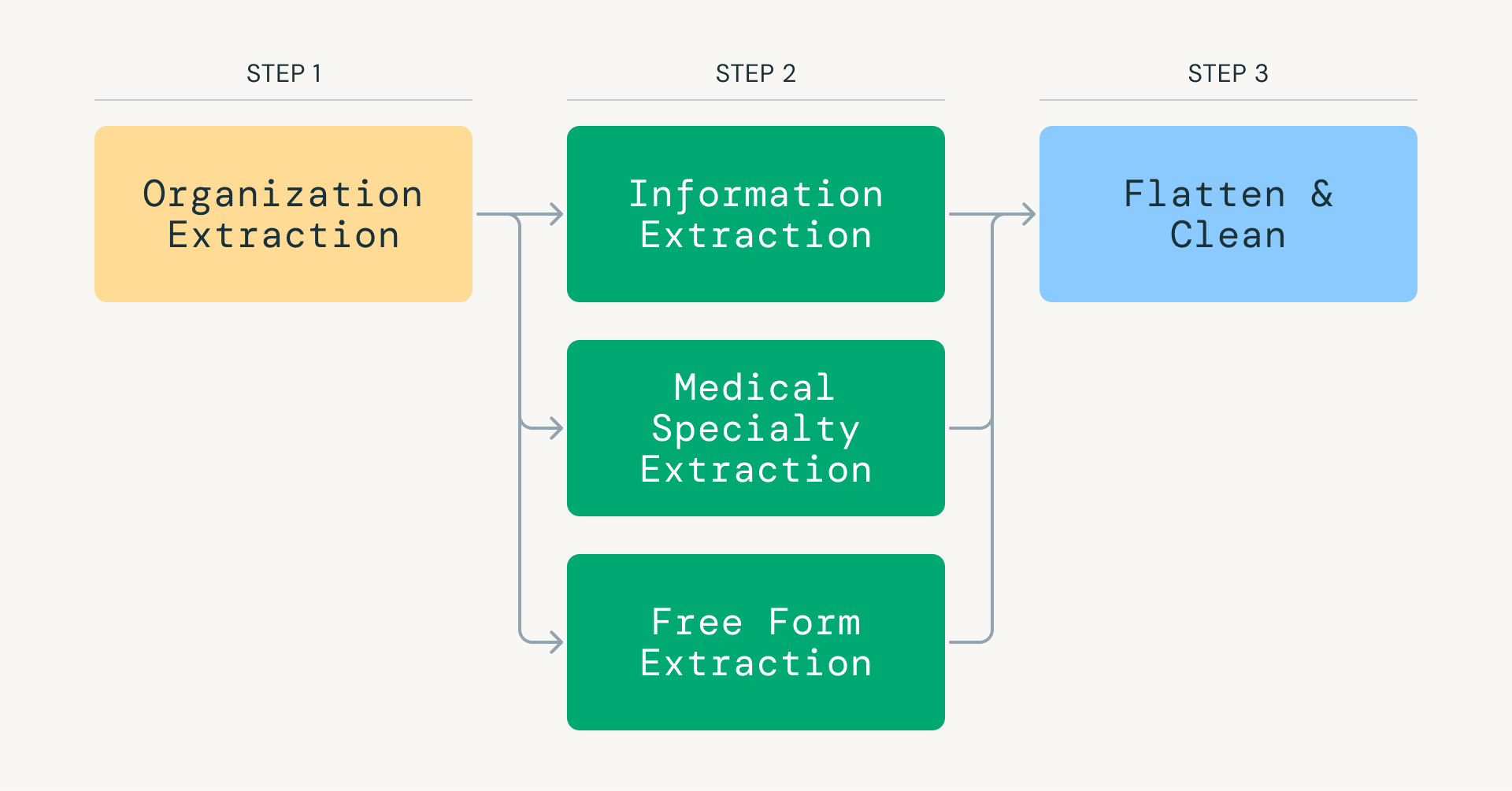 Fig 1: Pasos clave de Foundational Data Refresh (FDR).">
Fig 1: Pasos clave de Foundational Data Refresh (FDR).">Este enfoque reduce drásticamente el consumo de tokens mientras enfoca cada invocación del modelo en una tarea estrecha y de alta precisión. Databricks y Apache Spark se utilizan para orquestar y paralelizar eficientemente los datos extraídos, distribuyendo cargas de trabajo entre miles de ejecutores y permitiendo la inferencia de LLM de alto rendimiento.
Varias características críticas hacen que este pipeline sea escalable y esté listo para producción:
- Modelado de datos extensible: Los datos en cada paso se almacenan en un esquema de estrella, lo que simplifica el análisis posterior y mejora el rendimiento de las consultas.
- Puntos de control basados en el estado: Cada registro rastrea su estado de procesamiento, lo que permite que los pipelines se reanuden desde cualquier punto sin reprocesar filas con costosas llamadas a LLM.
- Registro de extracción configurable: Cada método de extracción se controla mediante un objeto estructurado que especifica el prompt del sistema, lo que hace que la lógica de extracción sea modular, reproducible y extensible.
- Procesamiento distribuido escalable: El sistema procesa cargas de trabajo sesgadas de varios terabytes utilizando Spark para el paralelismo, Photon para el rendimiento a escala y orquestación de calidad de producción.
Estas garantías se aplican a través de Lakeflow Jobs, que orquestan más de 15 tareas interdependientes con ramificación condicional, ejecución paralela y políticas de reintento inteligentes. El resultado es un sistema que procesa datos de instalaciones de atención médica a escala con la precisión de expertos médicos.
Resolución de Entidades a Escala
Una vez que los datos de instalaciones y organizaciones sin fines de lucro se extraen y procesan utilizando un LLM, surge un desafío clásico: la resolución de entidades. La misma instalación puede aparecer en múltiples fuentes de datos con variaciones en el nombre, direcciones inconsistentes o detalles de contacto faltantes. La deduplicación tradicional falla en estos escenarios debido a datos desordenados, por lo que utilizamos Splink, un marco de vinculación de registros probabilísticos de código abierto. Utilizando la información obtenida en nuestro paso de extracción de información, Splink evalúa pares coincidentes a través de comparaciones ponderadas en campos como número de teléfono, dirección postal y más. El resultado es una clave unificada por instalación, lo que garantiza que los usuarios finales vean un registro autoritativo para cada instalación médica y ONG.
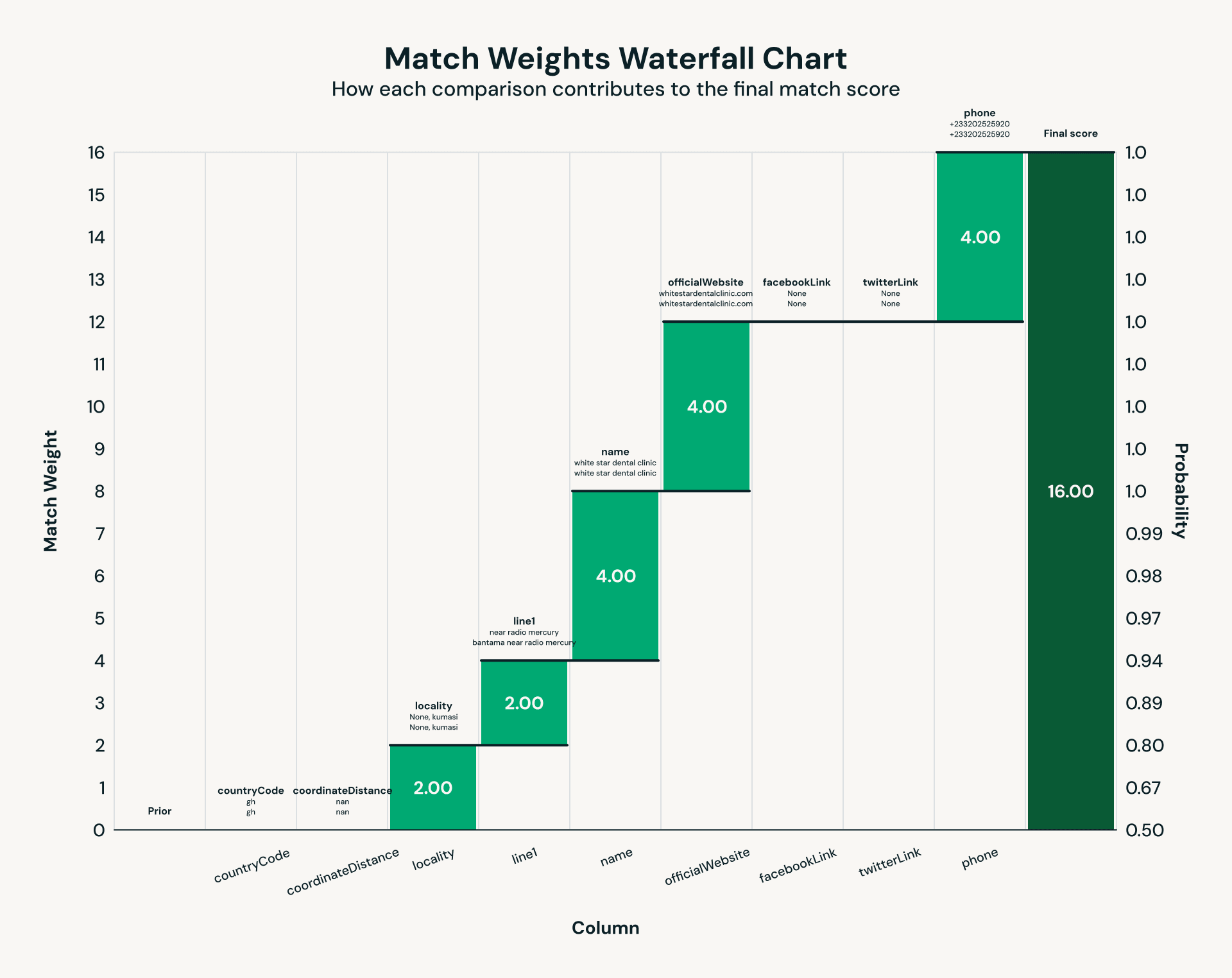 Fig 2: Ejemplo de conjunto de reglas para la resolución de entidades a través de Splink.">
Fig 2: Ejemplo de conjunto de reglas para la resolución de entidades a través de Splink.">La ejecución de la coincidencia probabilística en miles de instalaciones de atención médica y organizaciones sin fines de lucro reveló cuellos de botella de rendimiento clásicos que surgen a escala de terabytes. El núcleo de la vinculación de registros es la comparación por pares, que crea cargas de trabajo inherentemente sesgadas: las comparaciones comunes producen particiones masivas, mientras que la mayoría de las otras permanecen mucho más pequeñas. Las primeras ejecuciones lo dejaron dolorosamente claro, con una partición de Spark ejecutándose durante 30 minutos mientras que la mediana se completaba en 52 segundos, un caso de libro de texto de rezagados (la "maldición del último reductor") que degrada el rendimiento del trabajo. Habilitar Photon, el motor de consultas vectorizadas de Databricks, redujo las particiones de datos en el peor de los casos de 30 minutos a aproximadamente 2 minutos: una mejora de 15 veces.
Agente VF: Lenguaje Natural se une a Datos de Salud
Mirando hacia el futuro, hemos desarrollado un prototipo de un agente que permite a los expertos analizar datos utilizando lenguaje natural. Utilizamos una arquitectura multiagente construida en LangGraph y aprovechamos Databricks Model Serving, AI Search y Genie.
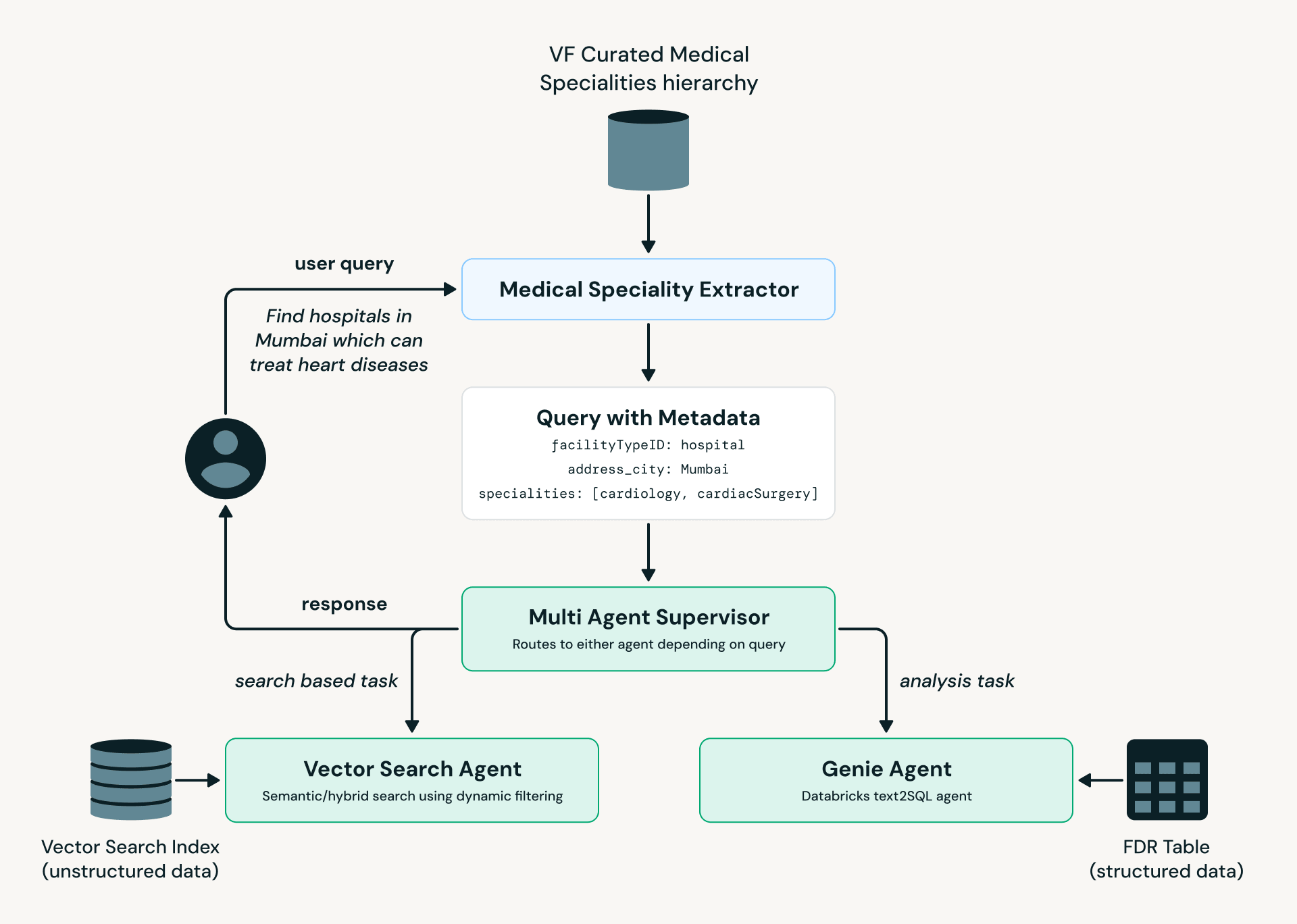 Fig 3: Agente VF: Diagrama de Flujo del Proceso">
Fig 3: Agente VF: Diagrama de Flujo del Proceso">Como se ilustra en el diagrama anterior, el Extractor de Especialidades Médicas convierte el lenguaje del usuario en terminología médica estandarizada, que luego se pasa al Supervisor Multiagente. Según la intención y la complejidad de la consulta, se dirige al Agente de Búsqueda Vectorial (descubrimiento y búsqueda de instalaciones) o al Agente Genie (consultas analíticas contra datos estructurados).
Resumen
Los profesionales de la salud ahora pueden descubrir oportunidades actualizadas más rápido, encontrar coincidencias con sus especialidades médicas y acceder a datos globales sobre miles de instalaciones en todo el mundo. El viaje de Virtue Foundation desde la prueba de concepto hasta la producción demuestra lo que es posible cuando los sistemas avanzados de IA se combinan con una plataforma de datos unificada.
El resultado final es una visión global de la infraestructura de atención médica, que revela dónde se necesitan más los voluntarios médicos.
Si desea obtener más información sobre este proyecto, consulte:
- Descripción general del proyecto Databricks x Virtue Foundation - YouTube
- Entrevista UN Bloomberg (YouTube) - alrededor del minuto 38:00
- Video testimonio: Bright Initiative x Virtue Foundation x Databricks
Lee más sobre otros proyectos de Databricks for Good a continuación:
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.