MemEx: un bloc de notas programable para agentes LLM
En 1945, Vannevar Bush imaginó una máquina del tamaño de un escritorio que ampliaría la memoria de un científico al almacenar cada documento, anotación y línea de pensamiento para recuperarlos cuando fuera necesario. La llamó MemEx. Bush estaba resolviendo un problema humano: mentes abrumadas por información que no podían tener a mano. Ocho décadas después, los agentes de LLM se enfrentan a una barrera notablemente similar.
En el paradigma actual de Agentic Tool Calling (llamada a herramientas por agentes), la ventana de contexto es el único sustrato persistente sobre el cual el modelo puede operar. Es un espacio compartido que contiene el prompt del sistema, la consulta del usuario, el razonamiento del modelo, las llamadas a herramientas y las salidas brutas de las herramientas. Las salidas de las herramientas son las peores infractoras: una sola consulta SQL puede devolver millones de filas y, en los entornos actuales, esas filas se arrastran en cada turno posterior, incluso si solo importaba una celda. El agente no tiene forma de segmentar, resumir o guardar el resultado antes de que sature la ventana.
Nos enfrentamos a esta barrera constantemente en Databricks. Nuestros agentes de producción, desde Genie hasta Agent Bricks, se topan con las mismas limitaciones de contexto en algún momento. Genie ofrece un ejemplo claro: una sola consulta busca en todo el espacio de trabajo de un cliente, llamando a muchas herramientas para extraer datos de tablas, índices vectoriales y paneles de control. Para solucionar esto, creamos nuestro propio MemEx y lo validamos en múltiples agentes internos y de producción.
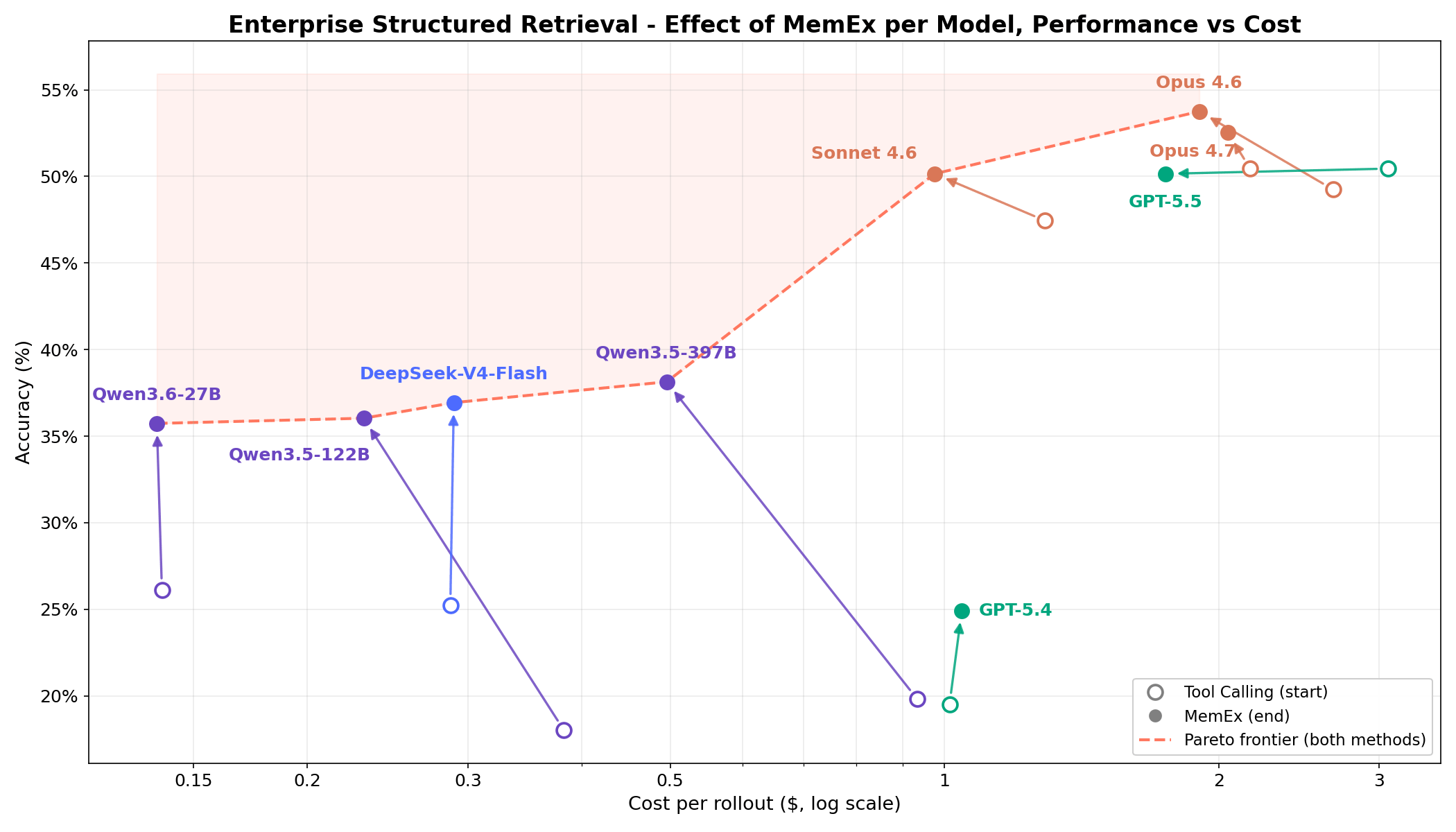
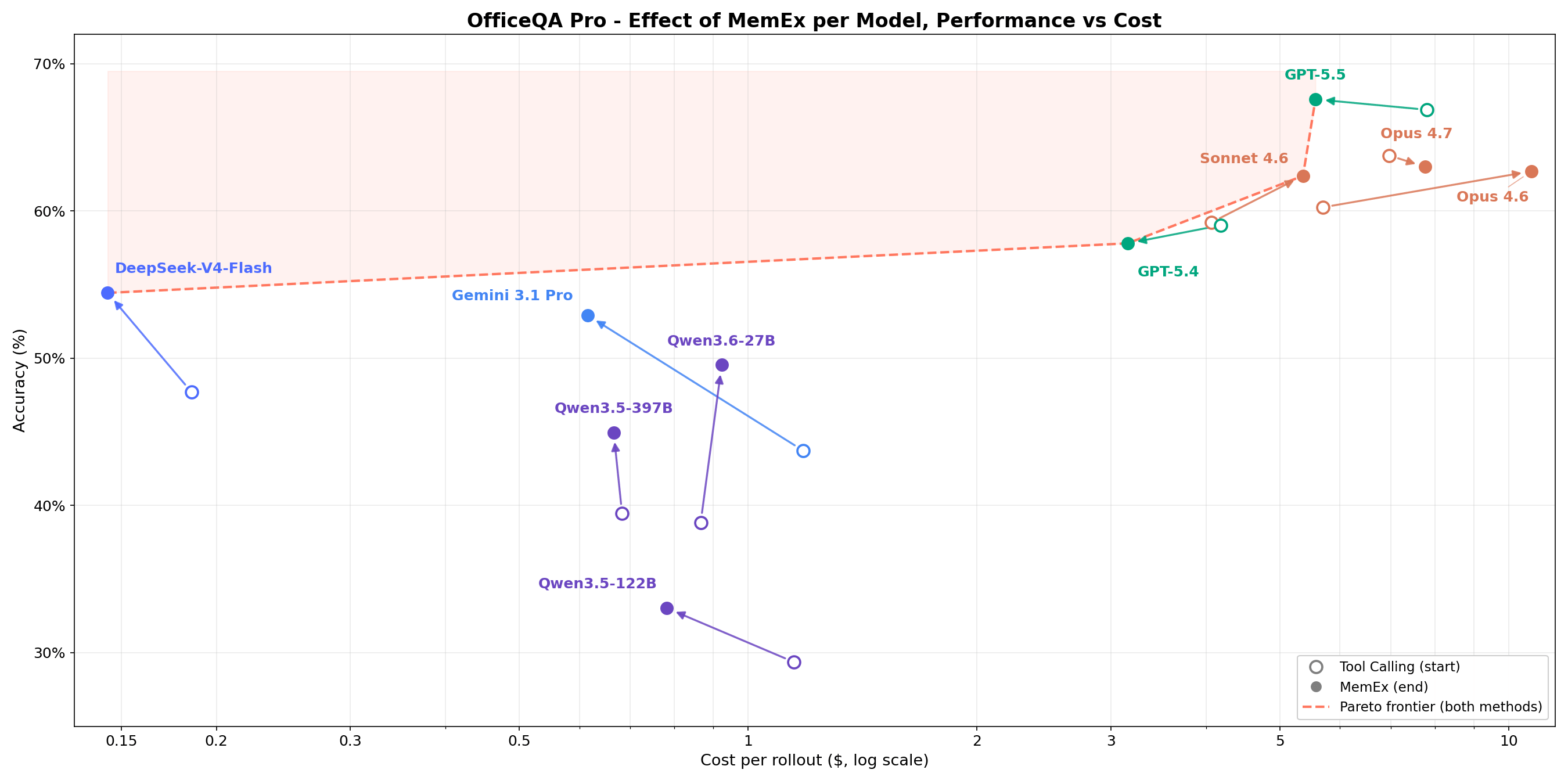
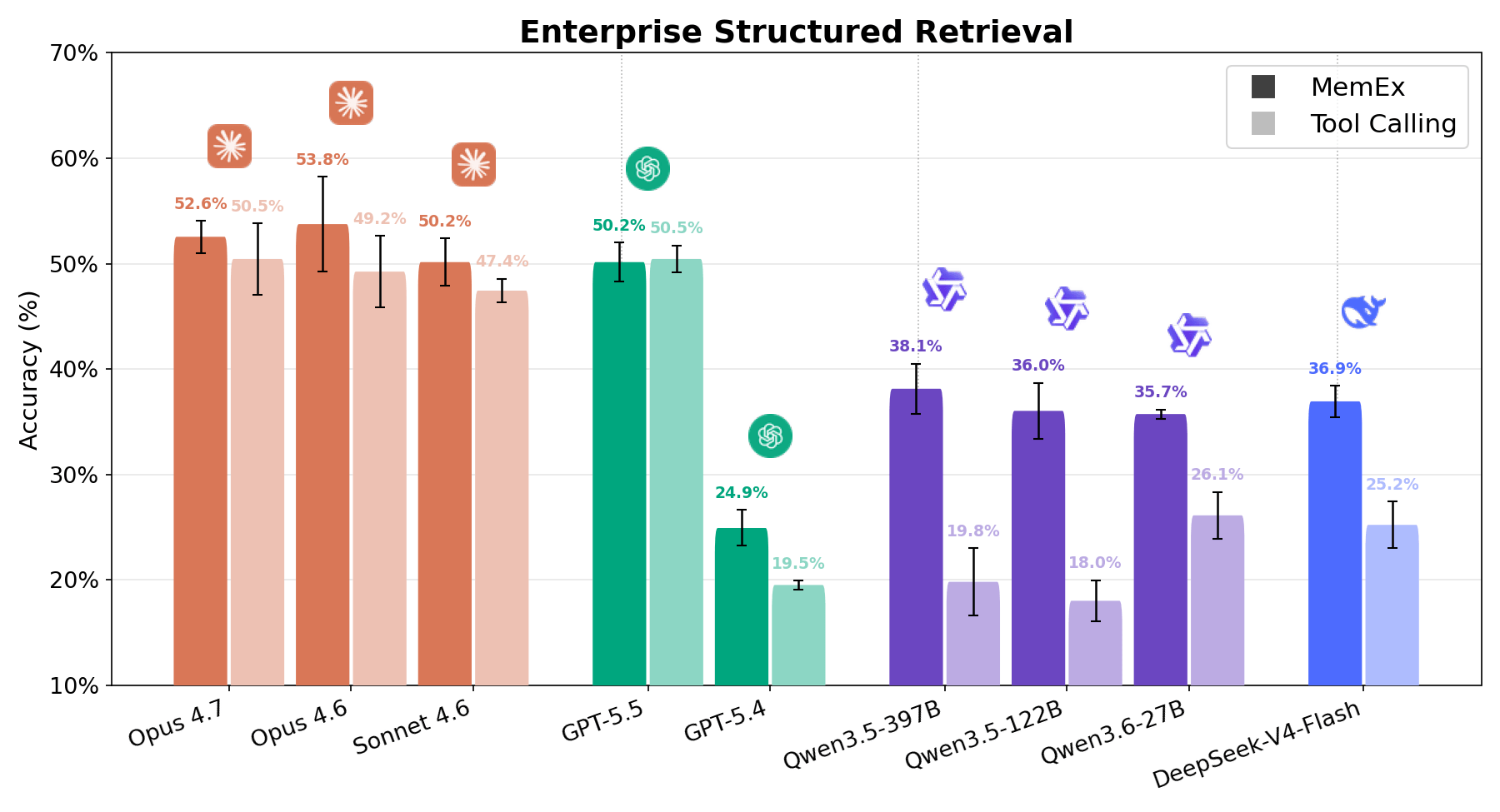
En tareas complejas de recuperación estructurada empresarial, la Figura 1 muestra que MemEx supera la frontera de costo-precisión para cada modelo. Los modelos de frontera como Opus 4.6 y Sonnet 4.6 ganan entre 2 y 5 puntos porcentuales con un costo de tokens entre un 25% y un 30% menor. Los modelos de pesos abiertos como Qwen3.5-122B (18% → 36%) y Qwen3.5-397B (20% → 38%) casi duplican su precisión con un costo de tokens entre un 40% y un 50% menor. Dado que MemEx puede operar sobre entradas arbitrariamente largas, también habilita otras dos aplicaciones: auditar las trayectorias de los agentes, incluida la del propio MemEx, que normalmente no cabrían en una sola ventana de contexto, y el pensamiento paralelo a través de múltiples trayectorias.
Cómo funciona MemEx
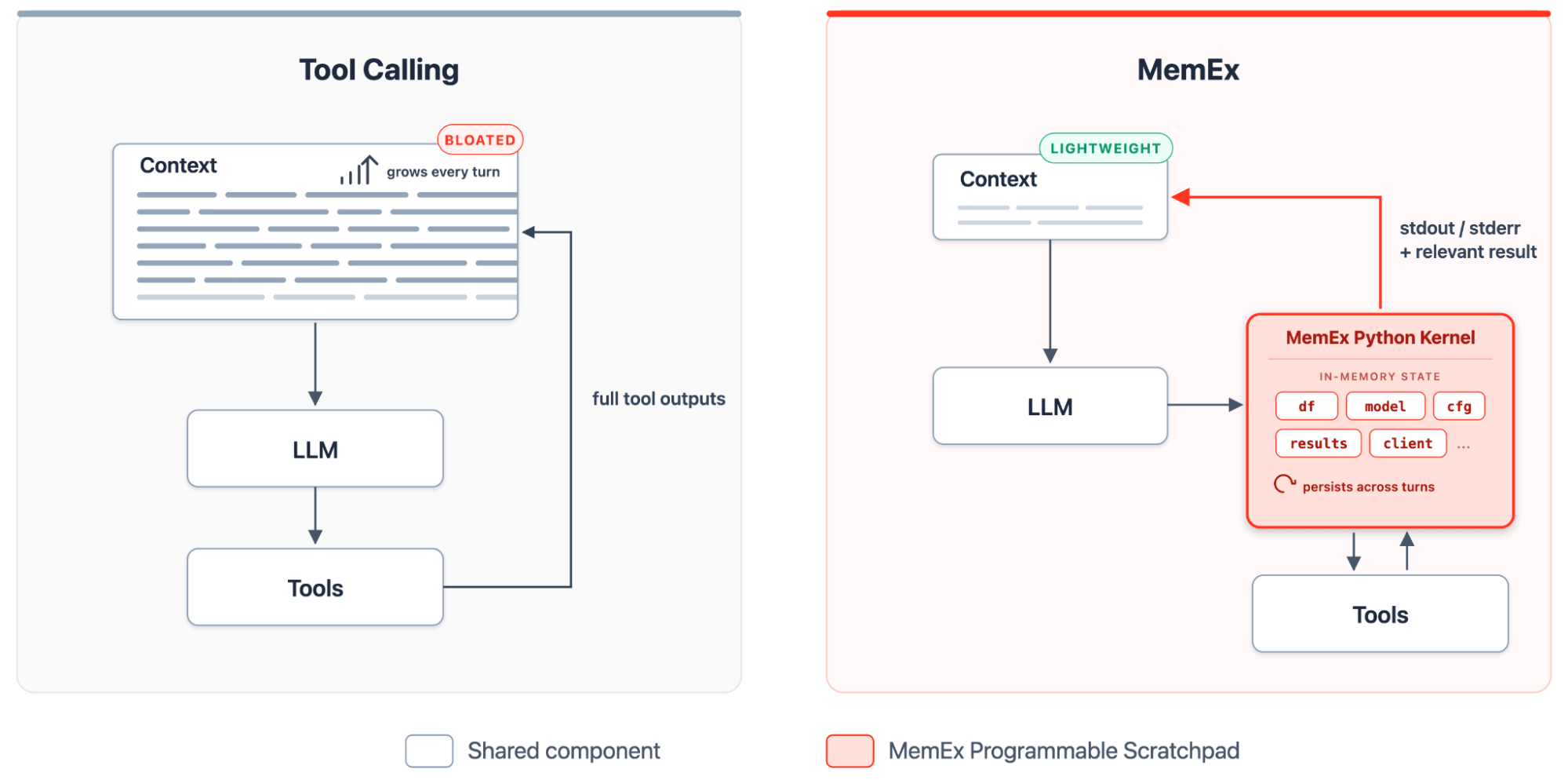
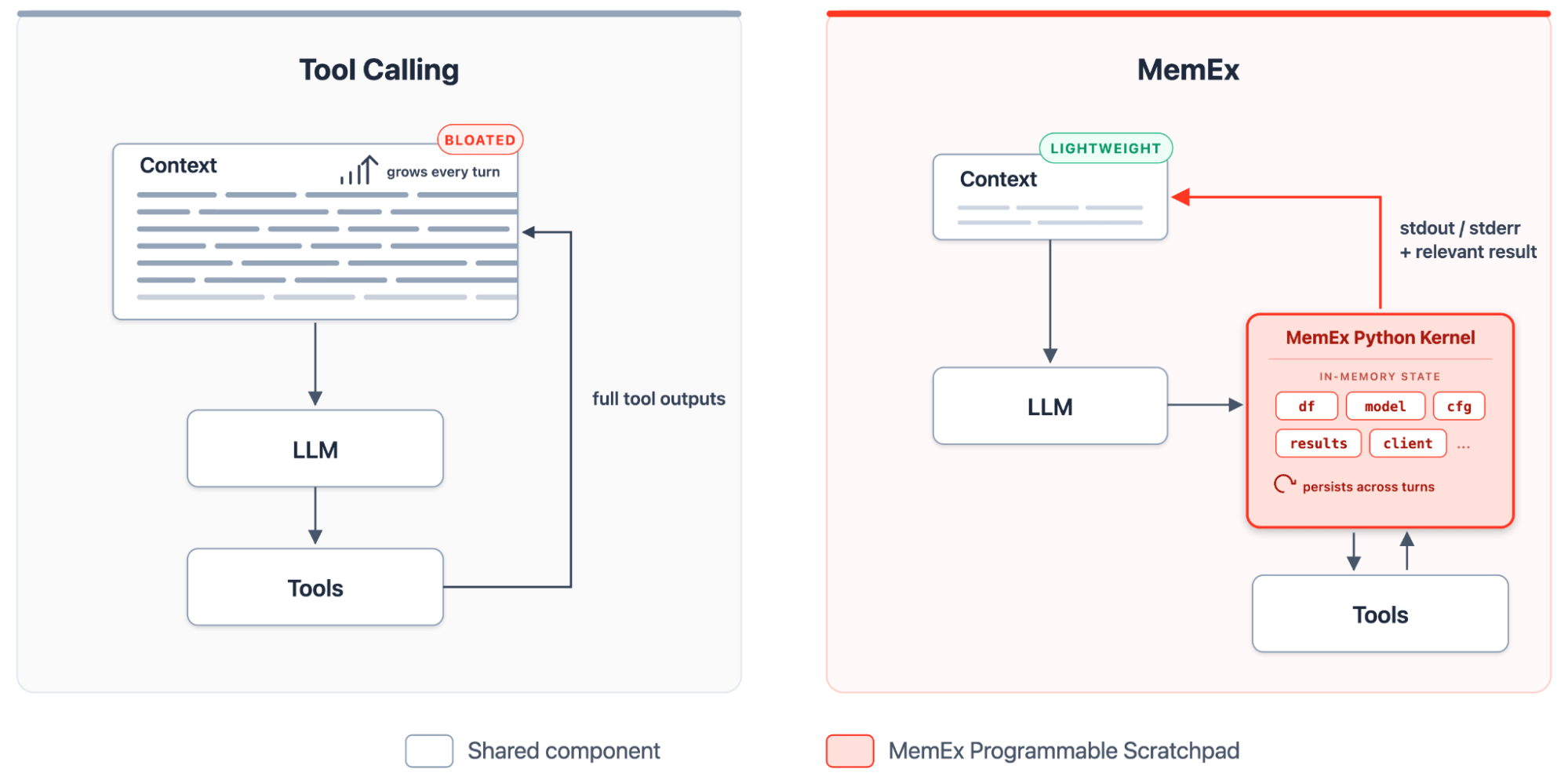{kind=link}
MemEx le da al LLM un bloc de notas programable: un kernel de Python tipado que contiene las salidas de las herramientas, las transforma con código y materializa únicamente las instrucciones de impresión (print) como tokens en el contexto. Dentro de este entorno, el despliegue (rollout) se convierte en un programa de Python autoextensible. Durante cada turno, el agente crea un nuevo bloque, el kernel mantiene el estado activo y el siguiente bloque se basa en el anterior. Las herramientas se exponen como funciones de Python tipadas con parámetros tipados y valores de retorno tipados. Las salidas de las herramientas se guardan como objetos de Python en el alcance (scope) de MemEx, donde persisten a lo largo de los turnos. El agente los compone con código, define funciones auxiliares cuando se repite un patrón y genera subagentes como llamadas a funciones asíncronas sobre el mismo alcance.
MemEx pertenece a la familia de código como acción (code-as-action) introducida por CodeAct (Wang et al., 2024), con variantes de producción en Programmatic Tool Calling de Anthropic y Cloudflare Code Mode. MemEx se destaca al integrarse en un marco de agentes existente de estilo ReAct (Yao et al., 2022), con alcance persistente, primitivas de subagentes y retornos tipados incorporados. Juntos, estos habilitan capacidades de las que carece el paradigma de llamada a herramientas JSON/XML:
- Manejo de entradas arbitrariamente grandes: Los documentos, conjuntos de datos y otros objetos grandes se pueden mantener en el alcance de Python como variables.
- Retorno de objetos tipados: Las salidas de las herramientas son objetos de Python tipados que se mantienen en memoria, no cadenas que el modelo tiene que materializar o volver a analizar (parsear) en cada turno.
- Composición de llamadas a herramientas: La salida de una llamada fluye directamente hacia los argumentos de la siguiente llamada dentro de una sola línea de código. Las salidas intermedias no necesitan materializarse en el contexto del agente.
- Segmentación de las salidas de las herramientas: Las salidas se pueden preprocesar, filtrar o resumir en el código antes de que el modelo las vea.
- Generación de subagentes asíncronos: Los agentes pueden generar subagentes mediante programación que se ejecutan junto al agente principal y agregar sus resultados sin necesidad de realizar un viaje de ida y vuelta a través del modelo principal.
Ejemplo de agente de LLM con MemEx
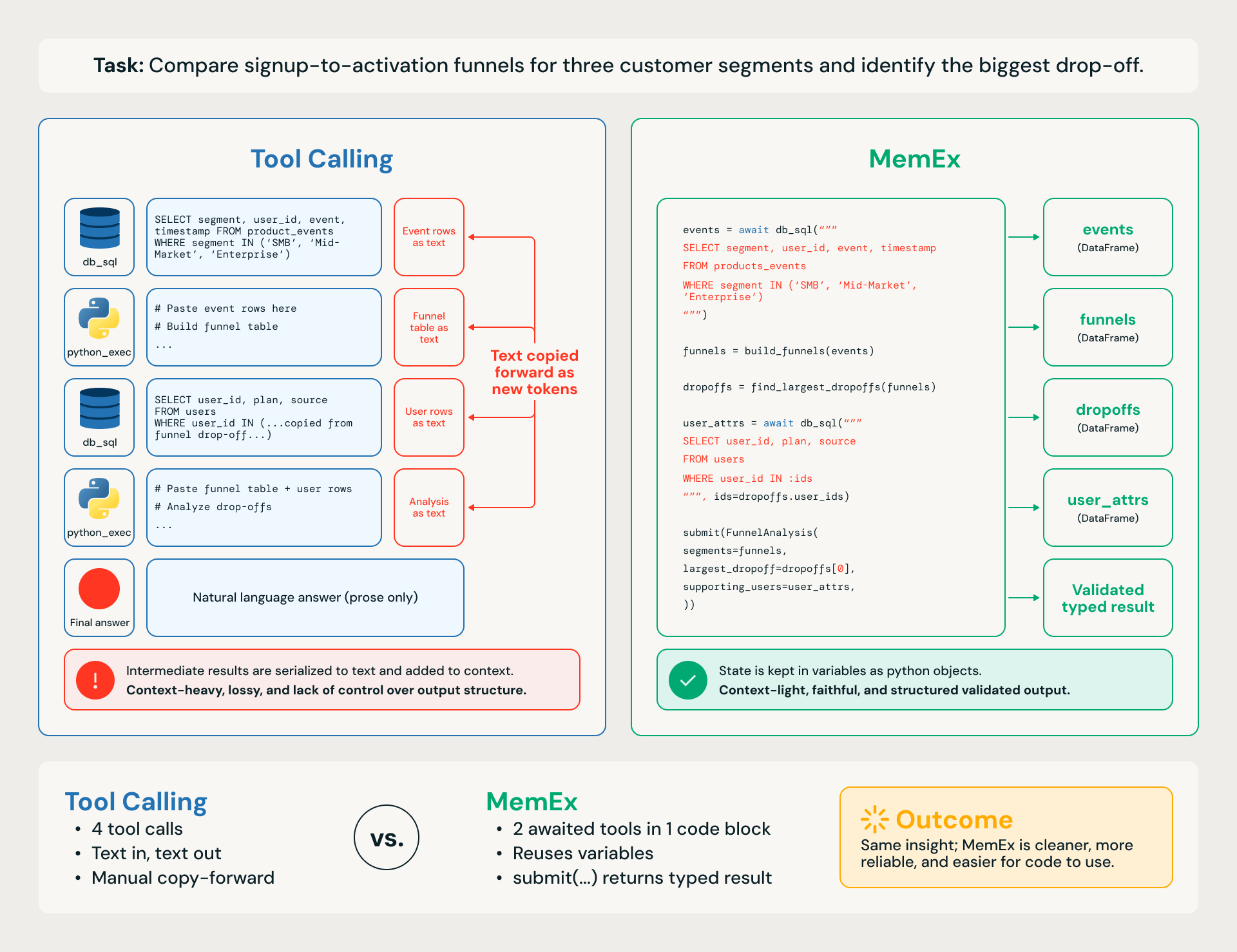
Tomemos una tarea empresarial concreta, como comparar los embudos de registro a activación para tres segmentos de clientes e identificar la mayor caída (Figura 1). El flujo de trabajo tiene cuatro pasos:
- recuperar los eventos de registro y activación del almacén de datos (data warehouse)
- unirlos por usuario
- calcular las tasas de conversión por segmento en cada etapa
- clasificar las caídas entre los segmentos.
Un agente de Tool Calling equipado con python_exec trabaja un paso a la vez. Cada consulta SQL y cada cálculo programático es una llamada a una herramienta independiente, con DataFrames intermedios serializados a texto y vueltos a pegar en los turnos posteriores. La traza consume muchos tokens, lo que la hace propensa a pérdidas, lenta, costosa y susceptible a pequeños errores en cascada en la tarea posterior.
Un agente de MemEx escribe el mismo flujo de trabajo como un único bloque de código: las consultas devuelven DataFrames nativos en el alcance, las funciones auxiliares los componen y la respuesta final se devuelve como un objeto validado y tipado a través de submit(). Mismo pensamiento, diferente espacio de acción.
Para tareas que se descomponen en subproblemas, el agente puede generar subagentes desde el interior de un bloque. Al generar subagentes, el agente principal puede pasar acceso compartido a cualquier objeto. Los subagentes se ejecutan de forma activa (eagerly) en paralelo con el principal y pueden devolver resultados al agente principal al finalizar. Por ejemplo:
La descomposición recursiva se convierte en otra expresión dentro del mismo programa de Python.
MemEx se desarrolla sobre aroll, el marco de despliegues de agentes (agentic rollouts) de Databricks. Aroll ya impulsa sistemas de producción como Genie, el Supervisor Agent de Agent Bricks y esfuerzos de investigación como KARL. MemEx se conecta al mismo bucle de agentes y herramientas que aroll ya utiliza para Tool Calling.
¿Cómo se desempeña MemEx en tareas de agentes empresariales?
Realizamos evaluaciones comparativas directas en 9 modelos de frontera donde comparamos llamadas a herramientas estructuradas en paralelo (Tool Calling) frente a bloques de código de Python (MemEx). Sin ajuste de prompts (prompt tuning) ni adaptación por tarea. Comparamos dos formas de trabajo de agentes empresariales: lectura fundamentada sobre un gran corpus de texto (OfficeQA) y recuperación estructurada sobre un gran espacio de trabajo de datos relacionales diversos (Enterprise Structured Retrieval).
En ambas tareas, ¡el agente MemEx es mejor y más económico que el agente de llamada a herramientas!
{kind=link}
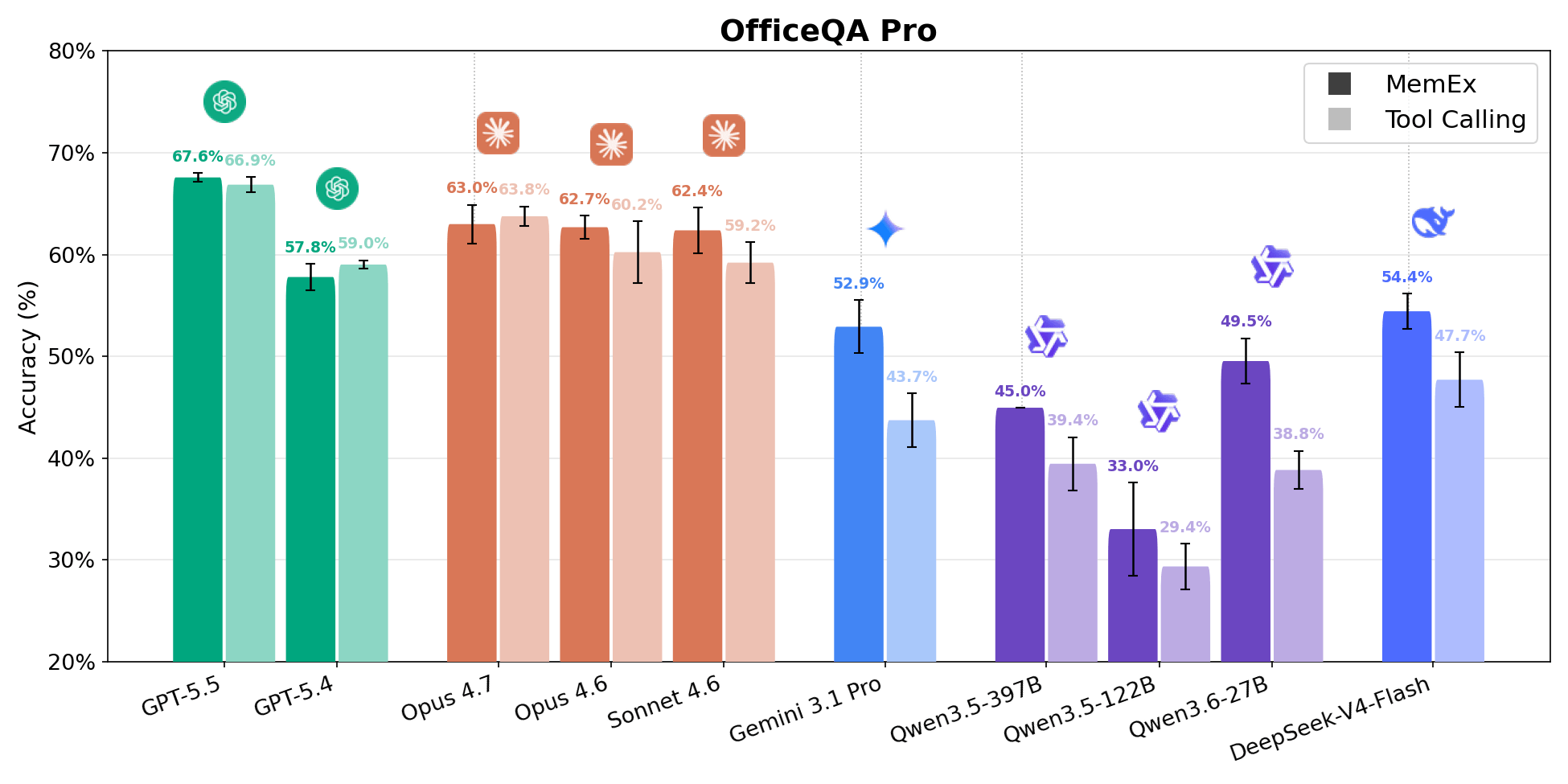
OfficeQA Pro solicita al agente responder preguntas de razonamiento fundamentado sobre el corpus de Boletines del Tesoro de EE. UU., aproximadamente 89 000 páginas que abarcan desde 1939 hasta el presente. Una pregunta típica requiere localizar evidencia en múltiples documentos, navegar por tablas con jerarquías anidadas y celdas combinadas, y realizar cálculos sobre los datos recuperados. Las respuestas se evalúan mediante coincidencia estricta. Cuatro de los cinco puntos en la frontera de Pareto de costo frente a precisión son configuraciones de MemEx. Gemini 3.1 Pro MemEx es el punto de la frontera más económico a $0.62 por ejecución (52.9% de precisión), y Sonnet 4.6 MemEx se aproxima a la precisión de llamada a herramientas de GPT-5.5 a aproximadamente el 70% del costo. En los nueve modelos, MemEx empata o gana en cada uno de ellos. El grupo intermedio es el que más se mueve, con Qwen 3.6 27B y Gemini 3.1 Pro ganando alrededor de 10 puntos porcentuales.
{kind=link}
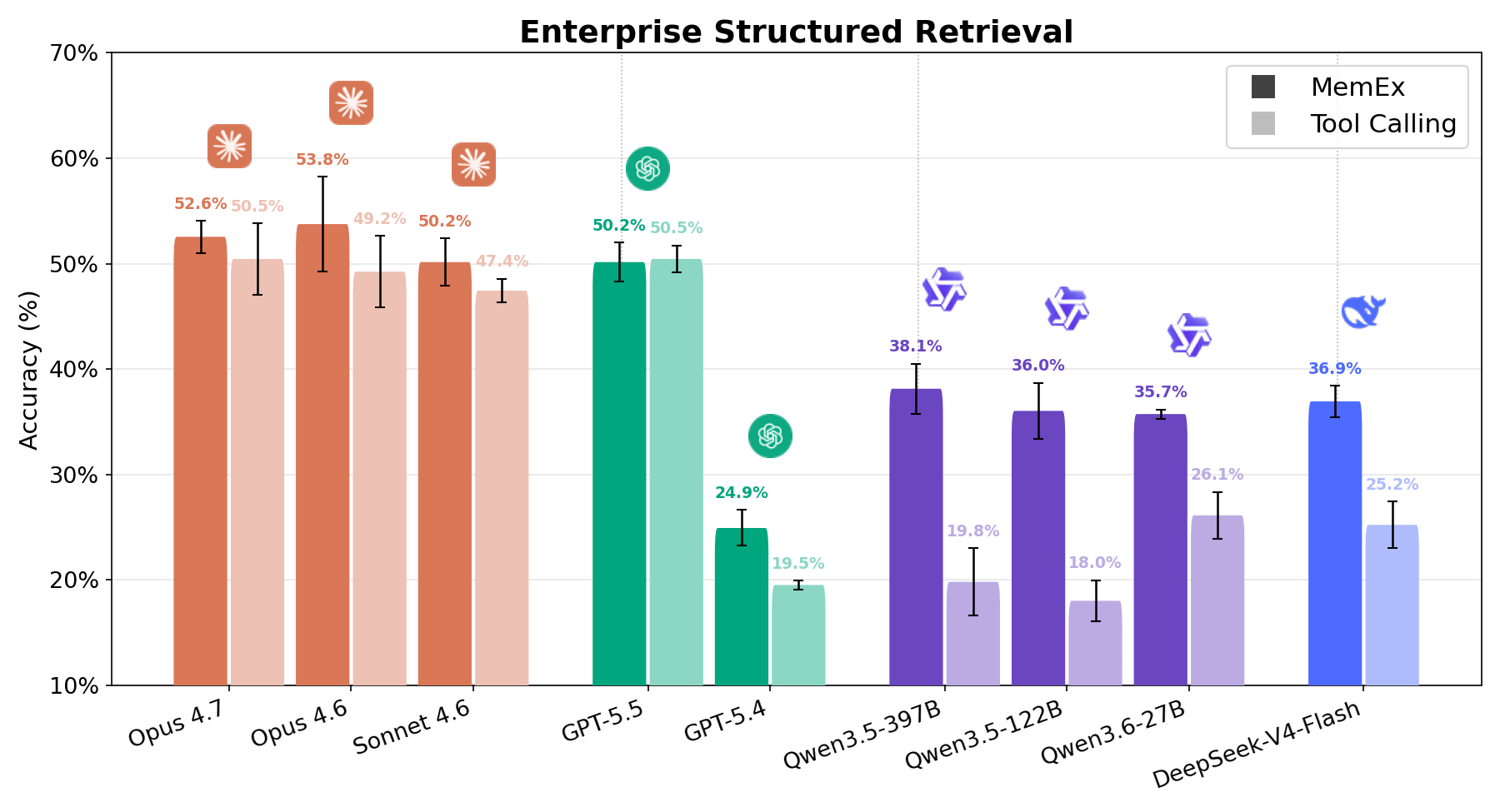
Enterprise Structured Retrieval solicita al agente responder preguntas en lenguaje natural sobre datos relacionales de la empresa. El agente dispone de herramientas relacionadas con el descubrimiento de esquemas y la ejecución de consultas SQL, y debe utilizarlas para realizar la tarea de análisis de datos solicitada por el usuario, generalmente con poca información sobre dónde encontrar la información relevante en el diverso espacio de trabajo. Las respuestas del agente se evalúan en comparación con las respuestas de referencia (ground truth) utilizando tanto la validación de datos determinista como un LLM como juez. Como se observa en las Figuras 1 y 6, todos los modelos muestran una sólida mejora con MemEx, a excepción de GPT 5.5, que muestra un rendimiento equivalente. En cuanto a los costos, el panorama es igual de favorable. Qwen 122B disminuye de 56 a 28 llamadas a herramientas por ejecución mientras duplica su puntuación; Sonnet pasa de 28 a 17; Opus de 33 a 21.1 Esto se traduce en reducir el costo aproximadamente a la mitad en la mayoría de los modelos. El patrón coincide con el de OfficeQA Pro: cuanto más difícil es la tarea, más demuestran su valor los objetos nativos y el estado persistente.
Cada comparación se ejecutó sin ajuste de instrucciones (prompt tuning), sin adaptación por tarea y sin modificaciones específicas para cada modelo. El bucle del agente, las instrucciones del sistema (system prompts) y las herramientas son idénticos en ambos entornos de prueba. La única diferencia es el espacio de acciones: llamadas a herramientas estructuradas en JSON/XML frente a los bloques de código Python de MemEx.
MemEx operando en trazas de agentes
Las trayectorias de los agentes son, en sí mismas, objetos voluminosos. En el paradigma de llamada a herramientas, analizar las trayectorias generalmente requiere aplanarlas en texto, lo que genera pérdida de información y consume mucho contexto, por lo que analizar varias a la vez suele ser inviable. Las trayectorias pueden incluso abarcar múltiples ventanas de contexto, con compresión intermedia; ¿cómo puede un LLM analizar una traza que, por definición, no cabe en su contexto? Pero una trayectoria es simplemente otro objeto de Python, por lo que MemEx puede cargarla directamente en el alcance (scope) y razonar sobre ella. Mostramos dos aplicaciones: primero, un agente de auditoría basado en MemEx que analiza las trayectorias de Qwen 3.6-27B en OfficeQA-Pro para explicar por qué MemEx supera a la llamada a herramientas; segundo, el escalado en tiempo de prueba (test-time scaling) en OfficeQA-Pro, con un agente MemEx que supera a un agente equivalente de llamada a herramientas.
MemEx audita a MemEx: análisis de trazas de agentes
Para analizar por qué el cambio a MemEx generó un aumento de rendimiento en los modelos de código abierto, como Qwen 3.6-27B, recurrimos a MemEx para obtener una explicación. En particular, instanciamos un agente de auditoría que recibe una pregunta de OfficeQA, su respuesta de referencia (ground-truth) y seis trayectorias de resolución (3 de un agente MemEx y 3 de un agente de llamada a herramientas) directamente en su alcance de Python, y le pide a un agente Sonnet 4.6 basado en MemEx que clasifique cada trayectoria incorrecta según una taxonomía de cuatro ejes de modos de fallo.
| Eje de fallo | Definición | Errores de MemEx | Errores de llamada a herramientas |
|---|---|---|---|
Source Selection | El modelo se dirige al documento o tabla incorrectos | 32 | 45 |
Interpretation | El modelo recupera los datos correctos pero extrae el significado incorrecto | 28 | 38 |
Search Strategy | El modelo se detiene demasiado pronto o se desvía más allá de la respuesta | 6 | 15 |
Execution | Errores en el cálculo intermedio o en el formato de salida final | 3 | 6 |
Total | - | 69 | 104 |
Nuestro análisis se centra en 66 preguntas de OfficeQA Pro en las que no todos los seis intentos fueron correctos o incorrectos, lo que generó 173 trayectorias. Los cuatro ejes se dividen en dos grandes grupos:
- Errores de fundamentación (~83%): Casos en los que el modelo recupera un valor preliminar en lugar de una cifra revisada, interpreta erróneamente terminología ambigua (por ejemplo, varianza muestral frente a poblacional, o precisión de redondeo para las "centésimas") o extrae la columna incorrecta de una tabla válida.
- Errores de estrategia de búsqueda y ejecución: Error en la planificación de la secuencia de recuperación o fallo al integrar correctamente los datos recuperados en los cálculos finales.
Para los errores de estrategia de búsqueda y ejecución, MemEx encuentra que el agente MemEx tuvo una reducción de errores de 2 veces en comparación con la llamada a herramientas. Esto se debe a que, con MemEx, la recuperación puede almacenarse directamente en variables de Python, por lo que el modelo evita copiar valores de la salida de una herramienta a la siguiente llamada de herramienta, y se pueden procesar múltiples llamadas a herramientas en un solo turno. La llamada a herramientas no tiene ese atajo y siempre debe transcribir los valores entre llamadas, lo que a veces provoca errores. Por ejemplo, en una trayectoria, un valor de 3,501 de un documento recuperado se volvió a escribir en la siguiente llamada como 3531.
Pensamiento paralelo de agentes con MemEx
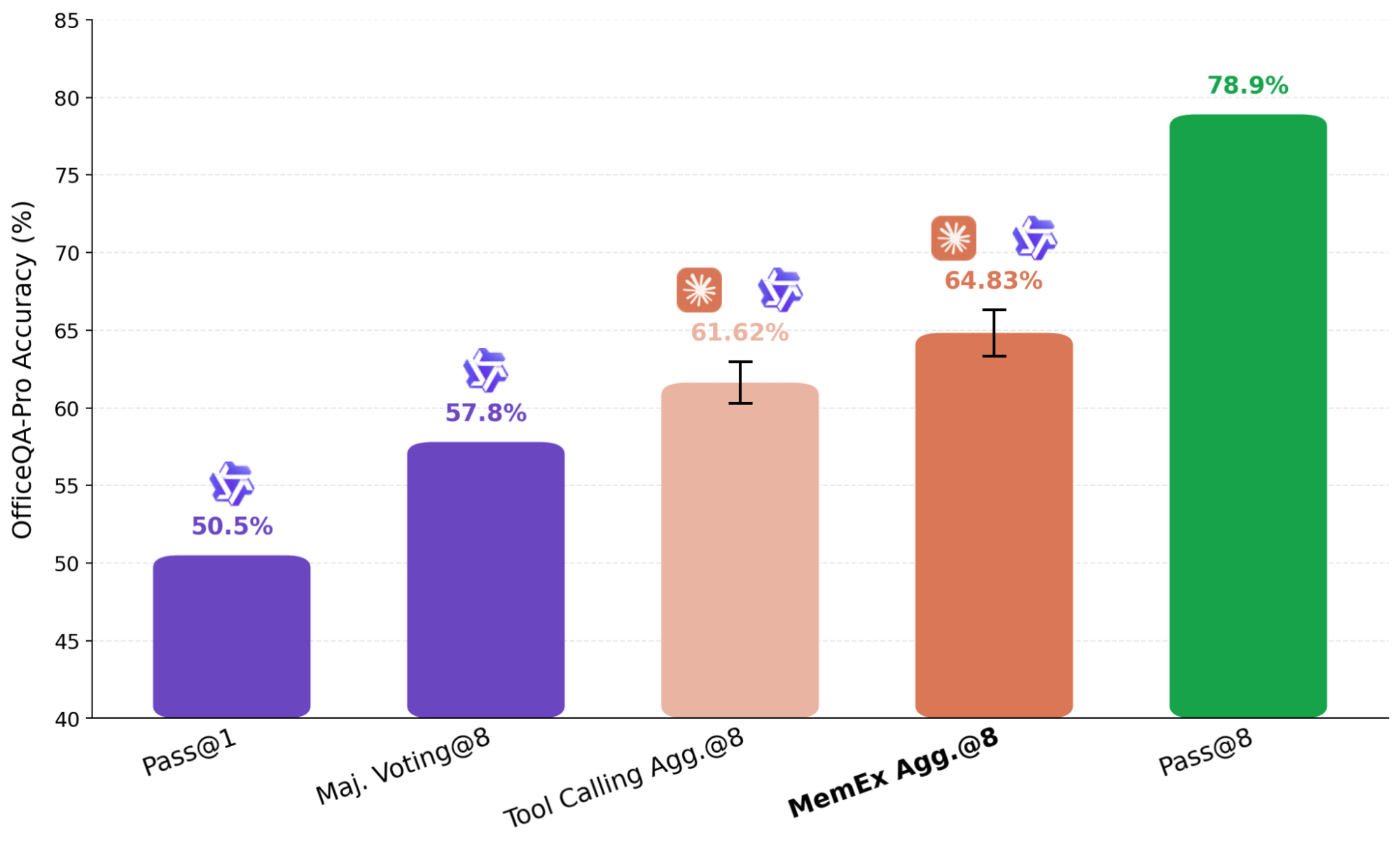
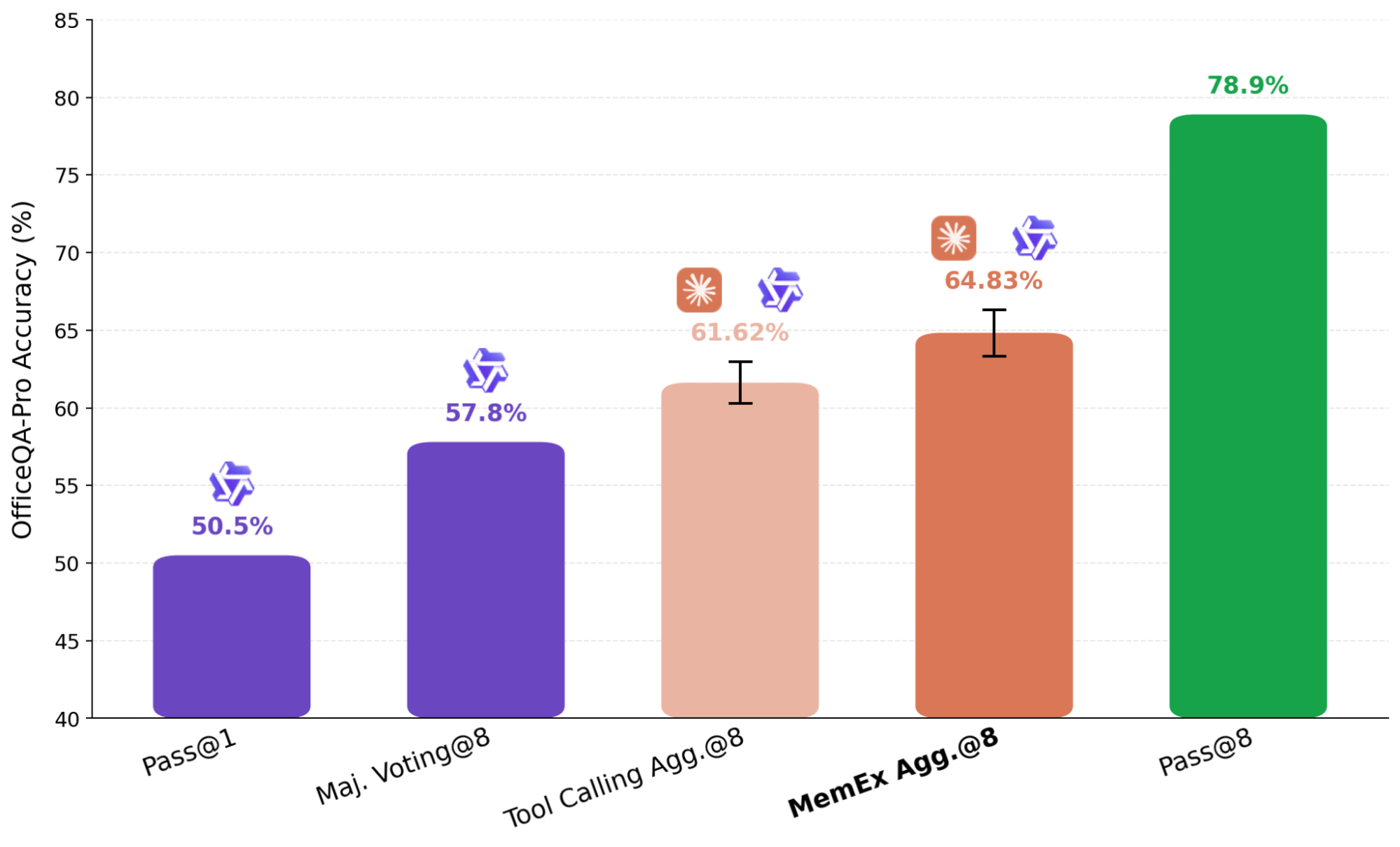
Un enfoque común para escalar el cómputo en tiempo de prueba (test-time computation) es el pensamiento paralelo, donde múltiples ejecuciones independientes de una tarea se agregan en una respuesta final. En el pensamiento paralelo de agentes, como el enfoque utilizado en KARL, los resúmenes de los intentos independientes se pasan a un agente agregador. Este paso de resumen conlleva pérdida de información, pero es inevitable en la configuración estándar, ya que incluir múltiples trayectorias completas en la ventana de contexto de un modelo resulta poco práctico. Con MemEx, en su lugar podemos cargar estas trayectorias como variables de alcance (scope), evitando por completo la representación con pérdida de información.
{kind=link}
En el resultado que se muestra en la Figura 7, utilizamos Claude Sonnet 4.6 como agregador sobre ocho trayectorias de Qwen-3.6-27B generadas de forma independiente. Para garantizar que el agregador no esté simplemente resolviendo el problema de nuevo por su cuenta, eliminamos sus herramientas de búsqueda de archivos, limitándolo a la verificación y selección. El agente basado en MemEx, que recibe las trayectorias completas como entrada, supera al agente equivalente de Tool Calling que solo recibe sus resúmenes. En un caso, el agregador de trayectorias detectó un error de duplicación en un boletín anterior al leer las salidas de herramientas sin procesar de las trayectorias de entrada; el agregador de Tool Calling no pudo verificar la reclamación de datos duplicados debido a que su entrada estaba limitada a los resúmenes, y recurrió al voto por mayoría en la fuente corrupta.
Arquitectura de MemEx
Los agentes de Tool Calling emiten una o más llamadas a herramientas estructuradas por turno (JSON o XML), cada una de las cuales se ajusta a un esquema de herramientas predefinido, en el bucle de acción-observación introducido por ReAct (Yao et al., 2022). CodeAct (Wang et al., 2024) reemplazó ese formato con un kernel de Python persistente: el agente emite código Python arbitrario, y las variables y definiciones de funciones se mantienen a lo largo de los turnos. Las variantes de producción del mismo paradigma incluyen Programmatic Tool Calling (PTC) de Anthropic y Cloudflare Code Mode; PTC también mantiene el estado a través de las solicitudes al reutilizar el mismo contenedor, mientras que Code Mode no lo hace. MemEx extiende este paradigma con cuatro adiciones adicionales:
- Integración directa de herramientas (drop-in) conservando los esquemas de parámetros.
- Ámbito (scope) de Python activo al inicio del despliegue (rollout).
- Typed
submit()para retornos estructurados. - Non-blocking
spawn_agent()para subagentes paralelos, generalizando los Modelos de Lenguaje Recursivos (Zhang et al., 2025).
La implementación se basa en tres decisiones de diseño:
El código como acción, en un REPL persistente
La acción del agente es un bloque de código Python arbitrario, ejecutado en un espacio de nombres (namespace) que persiste a lo largo de los turnos. Las herramientas, los objetos de ámbito (scope) y los resultados anteriores residen en ese espacio de nombres. El agente lee las observaciones (stdout, valores de retorno, errores) y luego escribe más código. El mismo bucle de observar-actuar que ejecuta Tool Calling ejecuta MemEx; solo cambia el espacio de acción.
Integración directa (drop-in) para Tool Calling
Las herramientas de Tool Calling existentes se inyectan automáticamente como funciones de Python, incluidos los esquemas de parámetros y los metadatos de tipo de retorno. Cambiar un agente existente de Tool Calling a MemEx es solo un cambio de configuración.
Ejecución independiente del backend
El mismo código de agente se ejecuta en tres backends, seleccionados en el momento de la configuración:
- En el mismo proceso (in-process) para una iteración rápida durante la investigación.
- Subproceso (subprocess) para el aislamiento durante la evaluación.
- Pool para la generación por lotes de alto rendimiento (datos de entrenamiento, despliegues a gran escala).
Para despliegues en producción, el kernel se puede sustituir por un entorno aislado (sandbox) alojado como Managed Agents de Anthropic. El mismo código de agente, con aislamiento del sistema de archivos, controles de salida de red y límites de recursos gestionados por el host.
¿Qué sigue?
MemEx está llegando a las manos de sus agentes. Lo estamos implementando en los agentes nativos de Databricks y en Agent Bricks: si hoy en día desarrolla sobre agentes de Databricks, pronto podrá utilizar MemEx.
Estamos realizando el post-entrenamiento de nuestros modelos para el espacio de acción de MemEx. MemEx en sí es el sustrato: genera datos sintéticos, ejecuta verificadores agénticos y alimenta el bucle de entrenamiento.
Autores: Ashutosh Baheti, Shubham Toshniwal, Arnav Singhvi, Krista Opsahl-Ong, Sean Kulinski, Sam Havens, Jonathan Li, Marco Cusumano-Towner, Jonathan Chang, Wen Sun, Alexander Trott, Jonathan Frankle, Xing Chen, Matei Zaharia
1 En MemEx, las llamadas a herramientas son bloques de código Python que pueden tener análisis de datos u otras herramientas llamadas como funciones asíncronas (async).
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.