Escalado de memoria para agentes de IA
La escalabilidad de la inferencia ha llevado a los LLM a poder razonar sobre la mayoría de las situaciones prácticas, siempre que tengan el contexto adecuado. Para muchos agentes del mundo real, el cuello de botella ya no es la capacidad de razonamiento, sino la conexión del agente con la información correcta: darle al modelo lo que necesita para la tarea en cuestión.
Esto sugiere un nuevo eje para el diseño de agentes. En lugar de centrarse únicamente en modelos más potentes o mejores indicaciones, podemos preguntar: ¿mejora el agente a medida que acumula más información? Llamamos a esto escalabilidad de la memoria: la propiedad de que el rendimiento del agente mejora con la cantidad de conversaciones pasadas, comentarios de los usuarios, trayectorias de interacción (tanto exitosas como fallidas) y contexto empresarial almacenado en su memoria. El efecto es especialmente pronunciado en entornos empresariales, donde el conocimiento tribal es abundante y un solo agente atiende a muchos usuarios.
Pero esto no es obvio a priori. Más memoria no hace automáticamente que un agente sea mejor: los rastros de baja calidad pueden enseñar lecciones equivocadas y la recuperación se vuelve más difícil a medida que la tienda crece. La pregunta central es si los agentes pueden utilizar memorias más grandes de manera productiva en lugar de simplemente acumularlas.
Hemos dado los primeros pasos en esta dirección en Databricks a través de ALHF y MemAlign, que ajustan el comportamiento del agente en función de la retroalimentación humana, y el Instructed Retriever, que permite a los agentes de búsqueda traducir instrucciones complejas en lenguaje natural y esquemas de fuentes de conocimiento en consultas de búsqueda precisas y estructuradas. Juntos, estos sistemas demuestran que los agentes pueden ser más útiles a través de la memoria persistente. Esta publicación presenta resultados experimentales que demuestran el comportamiento de escalabilidad de la memoria, discute la infraestructura requerida para soportarla en producción y proporciona una visión prospectiva de los agentes basados en memoria.
¿Qué es la escalabilidad de la memoria?
La escalabilidad de la memoria es la propiedad de que el rendimiento de un agente mejora a medida que crece su memoria externa. Aquí, "memoria" se refiere a un almacén persistente de información con el que el agente puede interactuar en el momento de la inferencia, distinto de los pesos del modelo o de la ventana de contexto actual.
Esto hace que la escalabilidad de la memoria sea un eje distinto y complementario tanto a la escalabilidad paramétrica como a la escalabilidad en el momento de la inferencia, abordando lagunas en el conocimiento del dominio y la conexión que ni el tamaño del modelo ni la capacidad de razonamiento pueden cerrar por sí solos. Las mejoras debidas a la escalabilidad de la memoria no se limitan a la calidad de la respuesta. Cuando un agente ha memorizado los esquemas relevantes, las reglas del dominio o las acciones pasadas exitosas para un entorno, puede omitir la exploración redundante y resolver consultas más rápido. En nuestros experimentos, observamos escalabilidad tanto en precisión como en eficiencia.
Relación con el aprendizaje continuo
El aprendizaje continuo generalmente se enfoca en actualizar los parámetros del modelo con el tiempo, lo que funciona bien en entornos acotados, pero se vuelve computacionalmente costoso y frágil con muchos usuarios concurrentes, agentes y proyectos que cambian rápidamente. La escalabilidad de la memoria plantea una pregunta diferente: ¿un agente con miles de usuarios funciona mejor que uno con un solo usuario? Al expandir el estado externo compartido de un agente mientras se mantienen congelados los pesos del LLM, la respuesta puede ser sí: un patrón de flujo de trabajo aprendido de un usuario puede recuperarse y aplicarse a otro inmediatamente, sin ningún reentrenamiento. Esta es una propiedad que el aprendizaje continuo, centrado como está en las actualizaciones de los parámetros del modelo de un solo usuario, nunca fue diseñado para proporcionar.
Relación con el contexto largo
Las grandes ventanas de contexto pueden parecer un sustituto de la memoria, pero abordan problemas diferentes. Empaquetar millones de tokens sin procesar en una indicación aumenta la latencia, eleva los costos de cómputo y degrada la calidad del razonamiento a medida que los tokens irrelevantes compiten por la atención. La escalabilidad de la memoria se basa en la recuperación selectiva: decidir no solo cuánta información incluir, sino qué incluir, mostrando solo la información de alta señal relevante para la tarea actual.
Tipos de memoria
No todas las memorias sirven para el mismo propósito. Dos distinciones son importantes en la práctica:
Episódica vs. semántica. Las memorias episódicas son registros sin procesar de interacciones pasadas: registros de conversaciones, trayectorias de llamadas a herramientas, comentarios de los usuarios. Las memorias semánticas son habilidades y hechos generalizados destilados de esas interacciones (por ejemplo, "los usuarios en este espacio siempre se refieren al trimestre fiscal cuando dicen 'trimestre'"). Cada tipo requiere diferentes estrategias de almacenamiento, procesamiento y recuperación: memorias episódicas para recuperación directa y memorias semánticas destiladas por un LLM para una coincidencia de patrones más amplia.
Personal vs. organizacional. Algunas memorias son específicas de las preferencias y flujos de trabajo de un solo usuario; otras representan conocimiento organizacional compartido: convenciones de nomenclatura, consultas comunes, reglas de negocio. El sistema de memoria debe delimitar adecuadamente la recuperación y las actualizaciones: mostrar el conocimiento organizacional de manera amplia mientras se mantiene privado el contexto individual, respetando los permisos y las ACL.
Experimentos: Almacén de Conocimiento Organizacional
MemAlign es nuestra exploración de cómo podría ser un marco de memoria simple para agentes de IA. Almacena interacciones pasadas como memorias episódicas, utiliza un LLM para destilarlas en reglas y patrones generalizados (memorias semánticas) y recupera las entradas más relevantes en el momento de la inferencia para guiar al agente. Para obtener detalles sobre el marco, consulte nuestra publicación anterior del blog.
Probamos MemAlign en Databricks Genie Spaces, una interfaz de lenguaje natural donde los usuarios de negocios hacen preguntas sobre datos en inglés simple y reciben respuestas basadas en SQL. A continuación se muestra un ejemplo de la consulta y la respuesta de la tarea
Nuestro objetivo es medir cómo escala el rendimiento del agente a medida que le proporcionamos más memoria, utilizando dos fuentes de datos: ejemplos curados (etiquetados) y registros de conversaciones de usuarios sin procesar (sin etiquetar).
Escalando con datos etiquetados
Evaluamos MemAlign en preguntas no vistas distribuidas en 10 Genie spaces, agregando incrementalmente fragmentos de ejemplos de entrenamiento anotados a la memoria del agente. Nuestra línea de base es un agente que utiliza instrucciones de Genie curadas por expertos (esquemas de tablas escritos manualmente, reglas de dominio y ejemplos de pocos disparos).
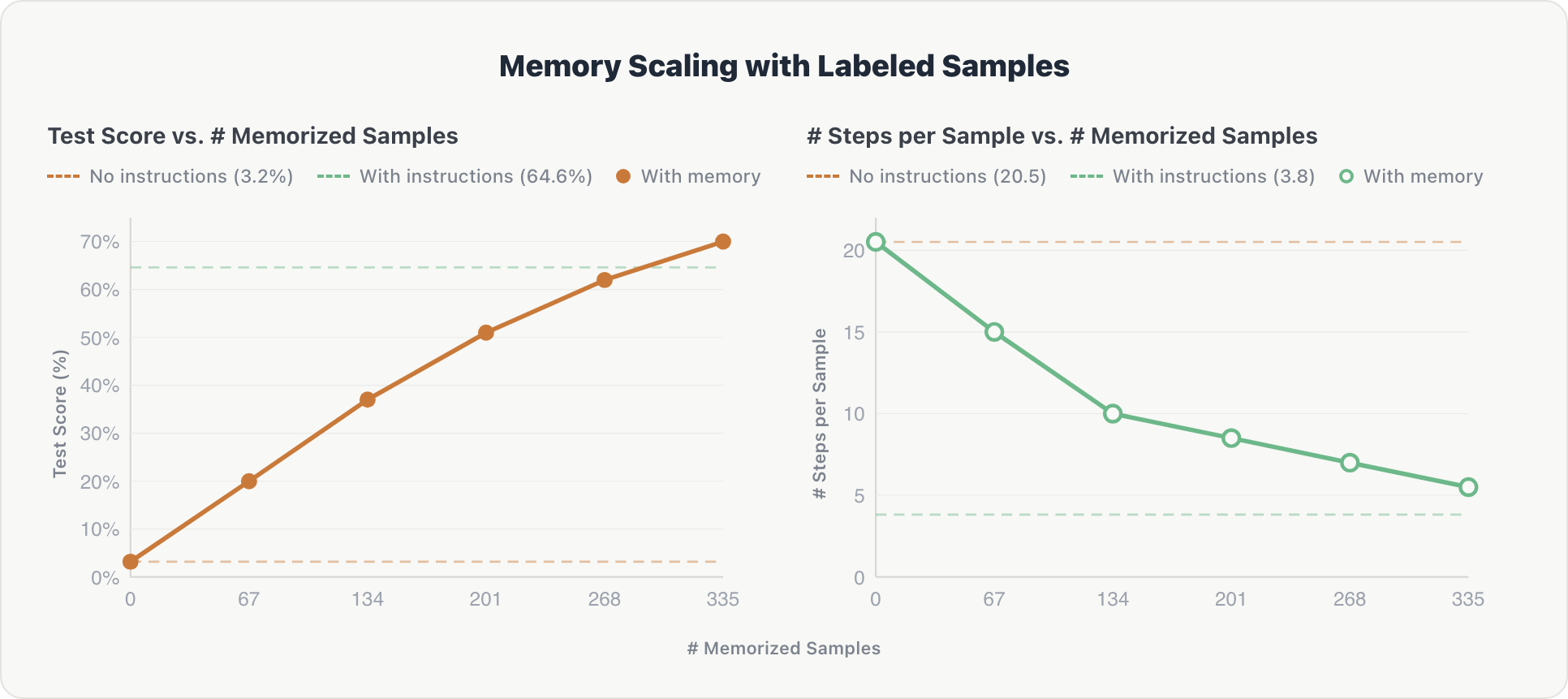
Los resultados muestran una escalabilidad constante en ambas dimensiones:
Precisión. Las puntuaciones de prueba aumentaron constantemente con cada fragmento de memoria adicional, aumentando de casi cero al 70%, superando finalmente la línea de base curada por expertos en ~5%. Tras la inspección, los datos etiquetados por humanos resultaron ser más completos y, por lo tanto, más útiles que los esquemas de tablas y las reglas de dominio escritos manualmente.
Eficiencia. El número promedio de pasos de razonamiento por ejemplo se redujo de ~20 a ~5 a medida que crecía la memoria. El agente aprendió a recuperar el contexto relevante directamente en lugar de explorar la base de datos desde cero, acercándose a la eficiencia de las instrucciones codificadas (~3.8 pasos).
El efecto es acumulativo: dado que las muestras memorizadas abarcan 10 Genie spaces diferentes, cada fragmento aporta información interdominio que se basa en el conocimiento previo.
Escalando con registros de usuarios sin etiquetar
¿Puede la memoria escalar con datos ruidosos del mundo real? Para averiguarlo, ejecutamos MemAlign en un Genie space en vivo y le proporcionamos registros de conversaciones de usuarios históricos sin respuestas de oro. Un juez LLM filtró estos registros para determinar su utilidad, y solo los de alta calidad se memorizaron.
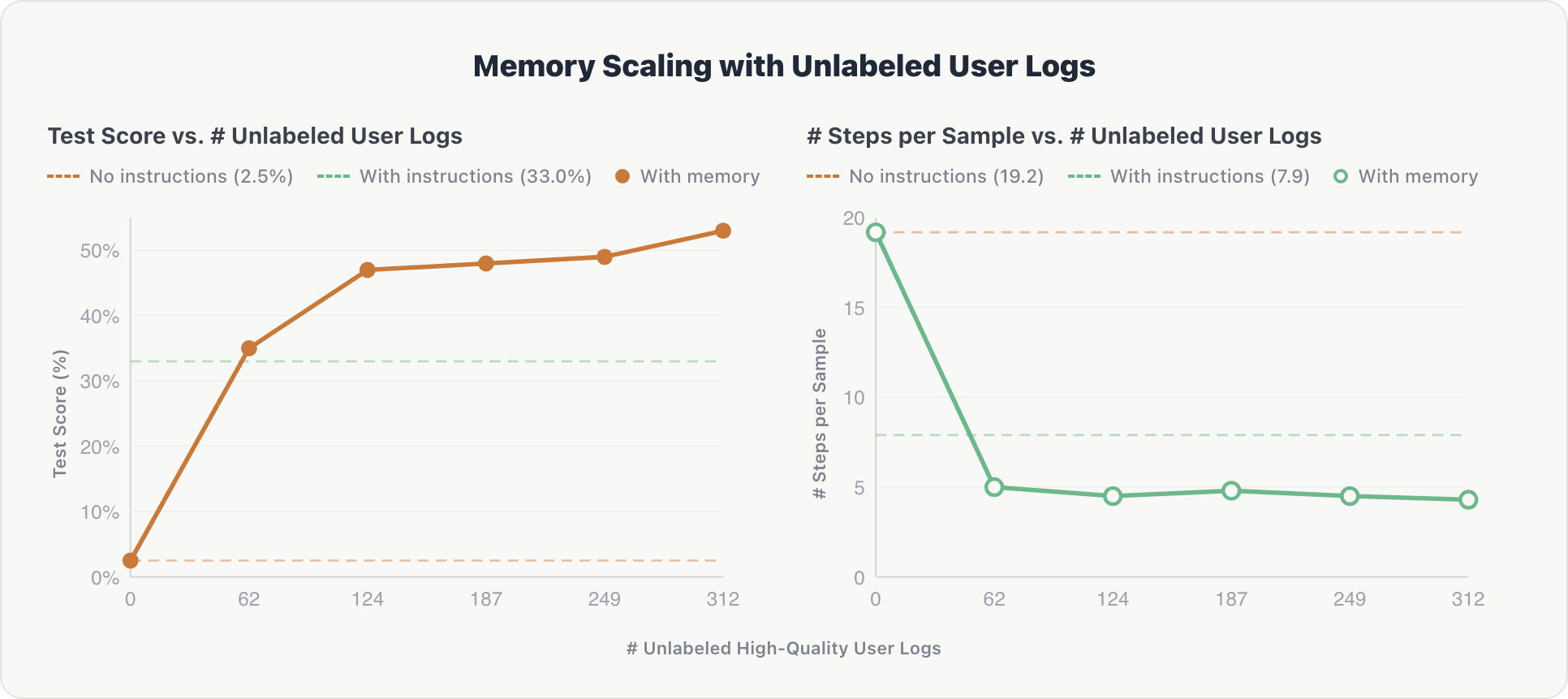
La curva de escalabilidad sigue un patrón similar y es más pronunciada al principio:
Precisión. El agente mostró una mejora inicial aguda. Después del primer fragmento de registro, extrajo información clave sobre tablas relevantes y preferencias implícitas del usuario. El rendimiento aumentó del 2.5% a más del 50%, superando la línea de base curada por expertos (33.0%) después de solo 62 registros.
Eficiencia. Los pasos de razonamiento se redujeron de ~19 a ~4.3 después del primer fragmento y se mantuvieron estables. El agente internalizó el esquema del espacio temprano y evitó la exploración redundante en consultas posteriores.
La conclusión: las interacciones de usuarios no curadas, filtradas solo por un juez automatizado y sin referencia, pueden sustituir a las costosas y lentas instrucciones de dominio diseñadas manualmente. Esto también apunta a agentes que mejoran continuamente con el uso normal y pueden escalar más allá de las limitaciones de la anotación humana.
Experimentos: Almacén de Conocimiento Organizacional
Los experimentos anteriores muestran cómo se escala la memoria con las interacciones del usuario. Pero las empresas también tienen conocimiento existente que precede a cualquier interacción del usuario: esquemas de tablas, consultas de paneles, glosarios de negocios y documentación interna. Probamos si la precomputación de este conocimiento organizacional en un almacén de memoria estructurado podría mejorar el rendimiento del agente.
Evaluamos este almacén de conocimiento en un punto de referencia de investigación de datos interno y en PMBench, que prueba la búsqueda exhaustiva de hechos sobre documentos internos mixtos como notas de reuniones de gerentes de producto y materiales de planificación.
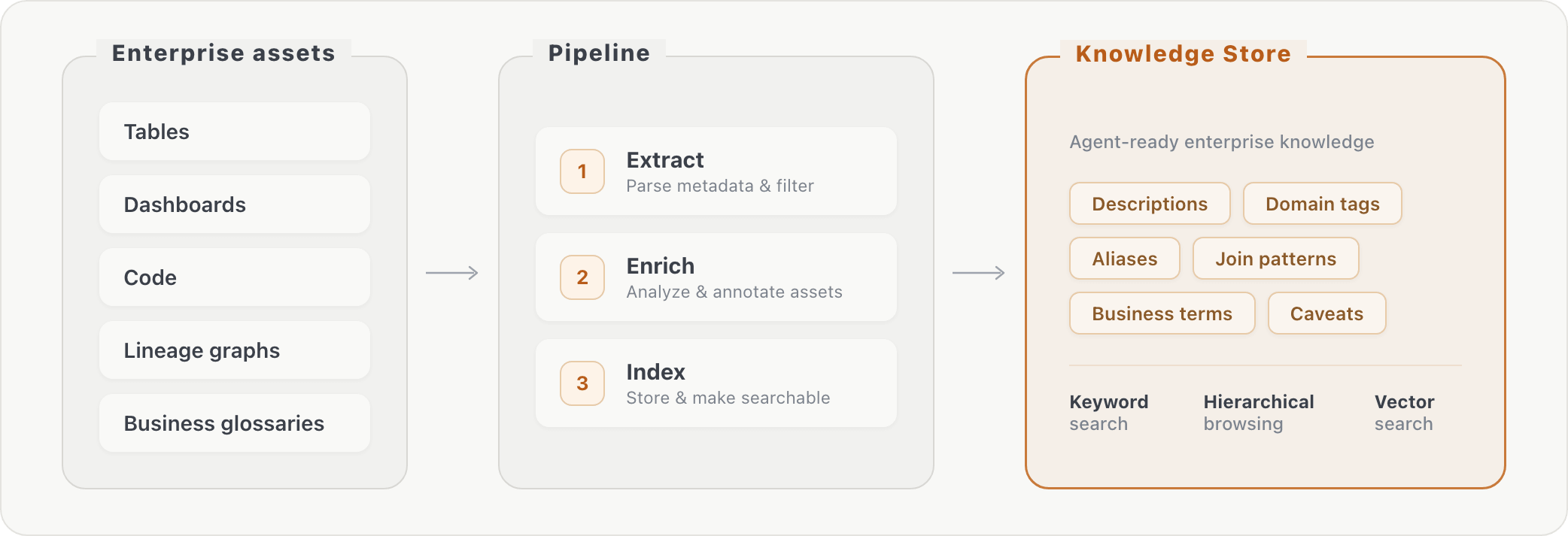
Nuestro pipeline procesa metadatos de bases de datos sin procesar en conocimiento recuperable en tres etapas: (1) extracción de información sobre activos, (2) enriquecimiento de activos a través de transformaciones adicionales y (3) indexación del contenido enriquecido. En el momento de la consulta, el agente puede buscar el contexto empresarial a través de búsqueda por palabras clave o navegación jerárquica. Esto cierra la brecha entre cómo los usuarios de negocios formulan preguntas ("consumo de IA") y cómo se almacenan realmente los datos (nombres de columnas específicos en tablas específicas).
La adición del almacén de conocimiento mejoró la precisión en aproximadamente un 10% en ambos puntos de referencia evaluados. Las ganancias se concentraron en preguntas que requerían correspondencia de vocabulario, uniones de tablas y conocimiento a nivel de columna, es decir, información que el agente no podría haber descubierto solo a través de la exploración del esquema.
Infraestructura para el Escalado de Memoria
El escalado de memoria en implementaciones empresariales requiere una infraestructura robusta más allá de un simple almacén vectorial. A continuación, discutiremos tres desafíos clave que esta infraestructura debe abordar: almacenamiento escalable, gestión de memoria y gobernanza.
Almacenamiento Escalable
El almacenamiento de memoria más simple es el sistema de archivos: archivos markdown en carpetas jerárquicas, navegados y buscados con herramientas de shell estándar. La memoria basada en archivos funciona bien a pequeña escala y para usuarios individuales, pero carece de indexación, consultas estructuradas y búsqueda de similitud eficiente. A medida que la memoria crece a miles de entradas entre muchos usuarios, la recuperación se degrada y la gobernanza se vuelve difícil de aplicar.
Los almacenes de datos dedicados son el siguiente paso natural. Las bases de datos vectoriales independientes manejan bien la búsqueda semántica, pero carecen de capacidades relacionales como uniones y filtrado. Los sistemas modernos basados en PostgreSQL ofrecen una alternativa más unificada: admiten de forma nativa consultas estructuradas, búsqueda de texto completo y búsqueda de similitud vectorial en un solo motor.
Las variantes sin servidor de esta arquitectura que separan el almacenamiento de la computación y proporcionan almacenamiento duradero y de bajo costo son una opción natural. Hemos estado utilizando Lakebase, construido sobre el motor PostgreSQL sin servidor de Neon, gracias a su costo escalable a 0 y su compatibilidad con la búsqueda vectorial y exacta. La ramificación de base de datos integrada también simplifica el ciclo de desarrollo: los ingenieros pueden bifurcar el estado de memoria del agente para pruebas sin afectar la producción.
Gestión de Memoria
El almacenamiento escalable por sí solo no es suficiente. Un sistema de memoria también debe gestionar su contenido:
- Arranque en frío. Los agentes nuevos conocidos sufren problemas de arranque en frío. La ingesta de activos empresariales existentes (wikis, documentación, guías internas) a través del análisis y extracción de documentos proporciona una base de memoria inicial que puede aliviar algunos de estos problemas, como lo demuestran nuestros experimentos de almacén de conocimiento organizacional.
- Destilación. Las memorias episódicas sin procesar son útiles para la recuperación directa, pero se vuelven costosas de almacenar y buscar a escala. Destilarlas periódicamente en memorias semánticas (reglas y patrones comprimidos) mantiene el almacén de memoria manejable y proporciona información generalizable al agente, que puede no ser evidente solo a partir de la memoria episódica.
- Consolidación. A medida que la memoria crece, es importante mantener el sistema consistente, compacto y actualizado. Esto requiere pipelines que eliminen duplicados, eliminen información obsoleta y resuelvan conflictos entre entradas antiguas y nuevas.
Seguridad
La memoria introduce requisitos de gobernanza que no existen para los agentes sin estado. A medida que los agentes acumulan conocimiento profundamente contextual, incluidas preferencias del usuario, flujos de trabajo propietarios y patrones de datos internos, los mismos principios de gobernanza que se aplican a los datos empresariales deben extenderse a la memoria del agente.
Los controles de acceso deben ser conscientes de la identidad: las memorias individuales deben permanecer privadas, mientras que el conocimiento organizacional puede compartirse dentro de límites controlados por acceso. Esto se mapea naturalmente al tipo de permisos granulares que plataformas como Unity Catalog ya imponen para los activos de datos, como la seguridad a nivel de fila, el enmascaramiento de columnas y el control de acceso basado en atributos.
Extender estos controles a las entradas de memoria significa que un agente que recupera contexto para un usuario no puede mostrar inadvertidamente las interacciones privadas de otro usuario.
Más allá del control de acceso, el linaje de datos y la auditabilidad son importantes. Cuando el comportamiento de un agente está determinado por su memoria, los equipos necesitan rastrear qué memorias influyeron en una respuesta determinada y cuándo se crearon o actualizaron esas memorias. Los requisitos de cumplimiento y regulatorios, particularmente en industrias reguladas, exigen que los almacenes de memoria admitan las mismas garantías de observabilidad que los datos subyacentes: seguimiento completo del linaje, políticas de retención y la capacidad de purgar entradas específicas a pedido.
Asegurar que la memoria correcta llegue al usuario correcto, y solo a ese usuario, es un problema central de diseño a escala.
Lo que se interpone en el camino
Cada eje de escalado eventualmente se encuentra con su propio cuello de botella. El escalado paramétrico está limitado por el suministro de datos de entrenamiento de alta calidad. El escalado en tiempo de inferencia puede degenerar en un exceso de pensamiento, donde cadenas de razonamiento más largas agregan costo sin agregar señal, degradando en última instancia el rendimiento a medida que aumenta la longitud de la secuencia. El escalado de memoria tiene límites análogos: problemas de calidad, alcance y acceso.
La calidad de la memoria es difícil de mantener. Algunas memorias son incorrectas desde el principio; otras se vuelven incorrectas con el tiempo. Un agente sin estado comete errores aislados, pero un agente con memoria puede convertir un error en uno recurrente al almacenarlo y recuperarlo más tarde como evidencia. Hemos visto agentes citar notebooks de ejecuciones anteriores que eran incorrectos, y luego reutilizar esos resultados con aún más confianza. La obsolescencia es más sutil: un agente que aprendió el esquema del trimestre pasado puede seguir consultando tablas que desde entonces han sido renombradas o eliminadas. El filtrado en la ingesta ayuda, pero los sistemas de producción necesitan más que filtrado. Necesitan procedencia, estimaciones de confianza, señales de frescura y revalidación periódica.
La gobernanza debe extenderse a la destilación. Escalar la memoria en una organización requiere destilar interacciones repetidas en memorias semánticas reutilizables. Pero la abstracción no elimina la sensibilidad. Una memoria como "para la empresa Y, unir las tablas CRM, inteligencia de mercado y asociaciones" puede parecer inofensiva y, sin embargo, revelar un interés de adquisición confidencial. El desafío es hacer que la memoria sea ampliamente útil sin convertir patrones privados en conocimiento compartido. Los controles de acceso y las etiquetas de sensibilidad deben sobrevivir a la destilación, no solo a la ingesta.
Las memorias útiles pueden permanecer inalcanzables. Incluso si la memoria es precisa y actual, el agente aún tiene que descubrir que existe. La recuperación es inherentemente metacognitiva: el agente debe decidir qué preguntar a su almacén de memoria antes de saber qué hay en él. Cuando no anticipa que una memoria relevante podría ayudar, nunca emite la consulta correcta y recurre a una exploración lenta y redundante. En la práctica, la brecha entre el conocimiento almacenado y el conocimiento accesible puede ser el principal limitador del escalado de memoria.
Estos no son argumentos en contra del escalado de memoria. Son los problemas de investigación que aún deben resolverse para que el escalado de memoria sea robusto. El problema central no es solo almacenar más historial; es enseñar al agente cómo encontrar la memoria correcta, cómo usarla apropiadamente y cómo mantenerla actualizada y con el alcance adecuado.
Mirando hacia el futuro: El Agente como Memoria
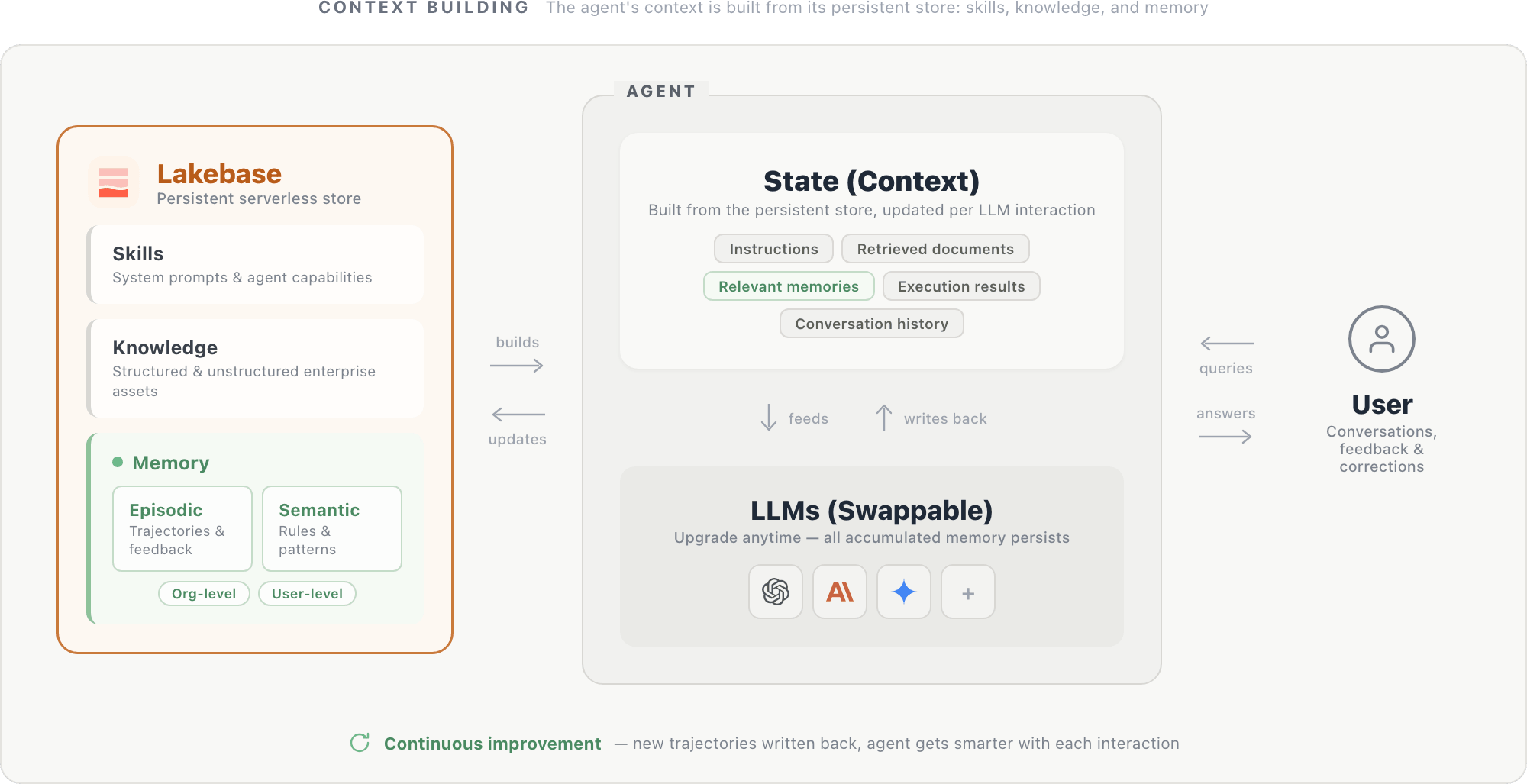
Los experimentos y la infraestructura anteriores apuntan a un patrón de diseño natural: un agente cuya identidad reside en su memoria, no en los pesos de su modelo.
En este diseño, el contexto de un agente se construye a partir de un almacén persistente alojado en una base de datos sin servidor como Lakebase. El almacén contiene tres componentes: prompts del sistema y capacidades del agente (habilidades), activos empresariales estructurados y no estructurados (conocimiento), y memorias episódicas y semánticas con alcance a nivel de organización y usuario. Juntos, estos componentes forman el estado del agente: instrucciones, documentos recuperados, memorias relevantes, resultados de ejecución (de consultas SQL, llamadas API y otras herramientas), y historial de conversación. Este estado se alimenta al LLM en cada paso y se actualiza después de cada interacción.
El propio LLM es un motor de razonamiento intercambiable: actualizar a un modelo más nuevo es sencillo, ya que el nuevo modelo lee del mismo almacén persistente y se beneficia inmediatamente de todo el contexto acumulado.
A medida que los modelos fundacionales convergen en capacidad, el diferenciador para los agentes empresariales será cada vez más la memoria que han acumulado en lugar del modelo que llaman. Hipotéticamente, un modelo más pequeño con un rico almacén de memoria puede superar a un modelo más grande con menos memoria; si es así, invertir en infraestructura de memoria podría generar mayores rendimientos que escalar los parámetros del modelo. El conocimiento del dominio, las preferencias del usuario y los patrones operativos específicos de su organización no se encuentran en ningún modelo fundacional. Solo se pueden construir a través del uso y, a diferencia de las capacidades del modelo, son únicos para cada implementación.
Conclusión
Proponemos la Escalada de Memoria, donde el rendimiento de un agente mejora a medida que acumula más experiencia a través de la interacción del usuario y el contexto empresarial en la memoria. Nuestros experimentos iniciales muestran que tanto la precisión como la eficiencia escalan con la cantidad de información almacenada en memoria externa.
La implementación de esto en producción requiere sistemas de almacenamiento que unifiquen la búsqueda estructurada y no estructurada, pipelines de gestión que mantengan la memoria consistente y controles de gobernanza que delimiten el acceso de manera apropiada. Estos son problemas solucionables con la tecnología actual. La recompensa son agentes que realmente mejoran con el uso continuo.
El trabajo restante es sustancial: la memoria debe permanecer precisa, actualizada y accesible a medida que crece. Pero eso es exactamente lo que hace interesante la escalada de memoria. Abre una agenda concreta de sistemas e investigación para construir agentes que mejoran con el uso continuo de maneras que son específicas para cada organización y problema.
Autores: Wenhao Zhan, Veronica Lyu, Jialu Liu, Michael Bendersky, Matei Zaharia, Xing Chen
Nos gustaría agradecer a Kenneth Choi, Sam Havens, Andy Zhang, Ziyi Yang, Ashutosh Baheti, Sean Kulinski, Alexander Trott, Will Tipton, Gavin Peng, Rishabh Singh y Patrick Wendell por sus valiosos comentarios a lo largo del proyecto.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.