Plataforma Abierta, Pipelines Unificados: Por qué dbt en Databricks está Acelerando
Ejecuta dbt en un lakehouse abierto y unificado con gobernanza integrada y un rendimiento de precio sólido
- Las bases abiertas evitan el bloqueo de proveedores. Cree flujos de trabajo de dbt con formatos de tabla abiertos y gobernanza de Unity Catalog de código abierto.
- Una plataforma unificada elimina la proliferación de herramientas. Ejecute dbt junto con la ingesta y BI en un solo lugar con gobernanza y orquestación integradas.
- Obtenga un fuerte rendimiento/precio con una mínima optimización y sobrecarga operativa.
dbt aporta estructura a los flujos de trabajo de transformación de datos. Los equipos lo utilizan para convertir datos sin procesar en conjuntos de datos curados que potencian el consumo posterior, como paneles de BI, modelos de IA/ML y generación de informes interfuncionales.
Pero la realidad es esta: dbt solo es tan potente como la plataforma de datos sobre la que se ejecuta.
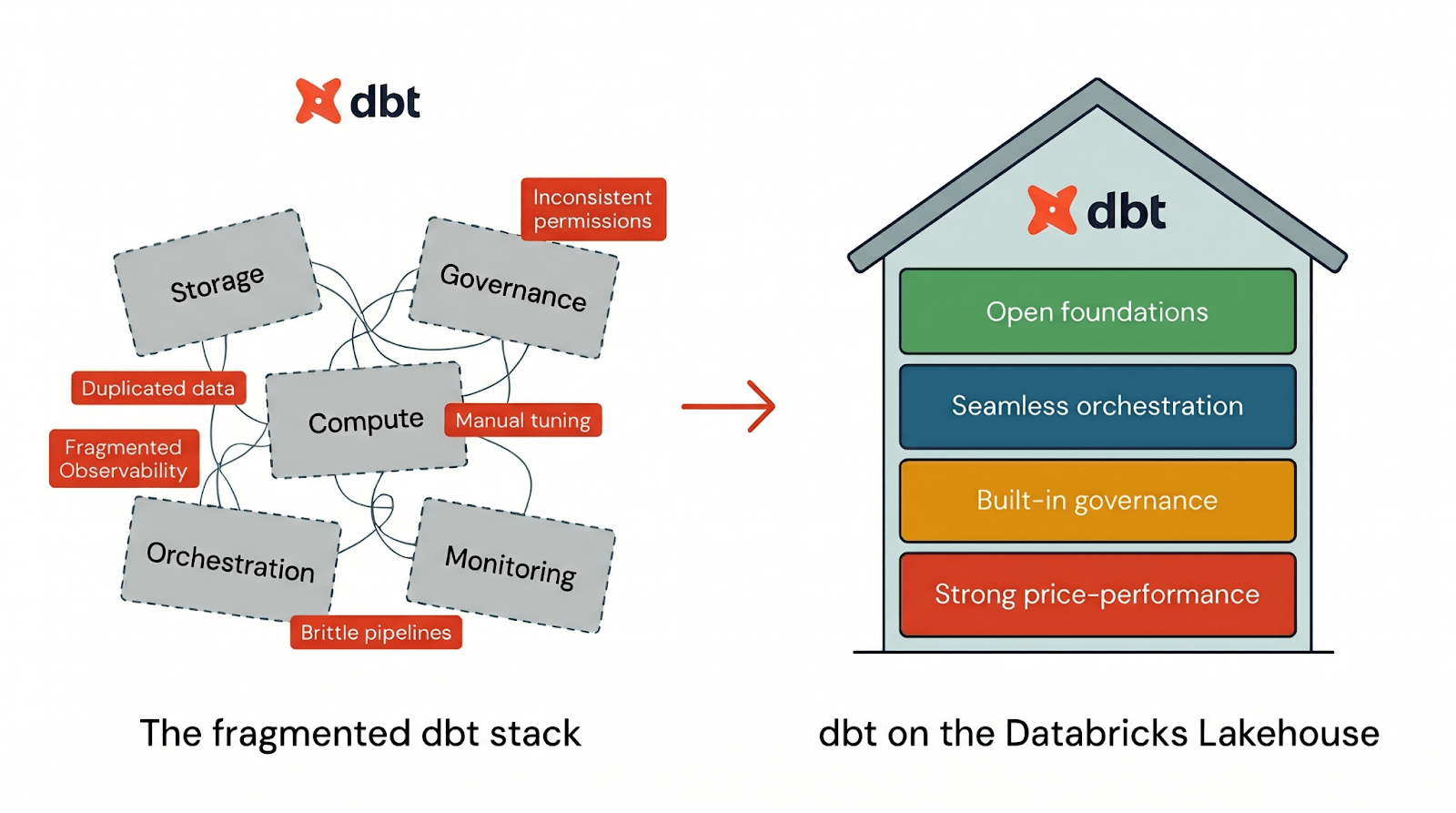
La mayoría de las pilas de datos le obligan a unir el almacenamiento, la computación, la gobernanza, la orquestación y la supervisión en varios sistemas. ¿El resultado? Datos duplicados, permisos inconsistentes, observabilidad fragmentada y optimización del rendimiento que se convierte en un trabajo a tiempo parcial. Por eso, un número creciente de equipos está consolidando sus flujos de trabajo de dbt en Databricks.
Para ejecutar dbt de manera eficaz, una plataforma necesita cuatro cosas:
- Cimientos abiertos para que sus flujos de trabajo de dbt no queden bloqueados en una pila propietaria
- Orquestación fluida para ejecutar canalizaciones de dbt de principio a fin en un solo lugar
- Gobernanza integrada que forma parte del flujo de trabajo predeterminado de dbt
- Fuerte relación precio-rendimiento para que dbt se ejecute rápidamente desde el primer día sin ajustes manuales
Databricks ofrece los cuatro pilares integrados de forma nativa en una sola plataforma. Cuando ejecuta dbt en Databricks, obtiene la experiencia del desarrollador de dbt sobre una arquitectura de lakehouse diseñada para la apertura, la gobernanza, el rendimiento y la simplicidad operativa desde el primer día. Veamos cómo funciona cada uno de estos en la práctica:
Ejecutar dbt en Databricks nos permitió consolidar un legado disperso de notebooks y más de 7 sistemas de origen en una única plataforma de datos gobernada. Con Unity Catalog, gestionamos 341 inquilinos, múltiples entornos y el intercambio de datos con socios externos a través del aislamiento a nivel de catálogo. Nuestra documentación de dbt fluye directamente a UC, por lo que los analistas pueden autoabastecerse sin cuellos de botella. Al publicar en formatos abiertos y Delta Sharing, los socios y los equipos posteriores pueden consumir fácilmente los conjuntos de datos generados por dbt en diversas herramientas y entornos. Es una plataforma para construir, pero una plataforma abierta para consumir. —Sohan Chatterjee, Head of Data and Analytics, iSolved
Ejecute dbt sobre cimientos abiertos sin dependencia de un proveedor
La dependencia de un proveedor es uno de los riesgos estratégicos más importantes para la estrategia de datos de una organización. dbt se basa en un marco de adaptadores abiertos, lo que significa que su lógica de transformación no está bloqueada en una sola plataforma. dbt es abierto por diseño, y Databricks proporciona una plataforma abierta para ejecutarlo. Muchas pilas de datos modernas se centran en una capa de almacenamiento propietaria que ofrece comodidad a corto plazo pero introduce fricción a largo plazo. Con el tiempo, esto conduce a datos duplicados y canalizaciones de exportación para servir a diferentes consumidores, formatos de almacenamiento que limitan la interoperabilidad y costes de cambio crecientes a medida que evolucionan los requisitos de la plataforma.
Databricks es un lakehouse abierto: una plataforma unificada donde sus datos residen en formatos de tabla abiertos y son accesibles a través de interfaces abiertas, lo que garantiza que el almacenamiento y la gobernanza no estén vinculados a un único motor de consulta. En Databricks, los modelos de dbt se convierten en tablas en formatos abiertos, Delta Lake y Apache Iceberg, lo que garantiza que sus datos transformados permanezcan accesibles en todo el panorama de datos sin necesidad de exportar o mantener copias paralelas. Esta apertura es importante específicamente para los flujos de trabajo de dbt. Sus tablas de plata y oro cuidadosamente modeladas se convierten en productos de datos reutilizables que los usuarios posteriores pueden consumir a través de cualquier motor de consulta, no solo a través de la plataforma donde se ejecuta dbt.
Esta apertura se extiende más allá del almacenamiento. Unity Catalog se basa en estándares abiertos de catálogo y acceso que admiten lecturas y escrituras gobernadas desde motores externos. Databricks SQL sigue los estándares ANSI, lo que garantiza que sus consultas sigan siendo portátiles entre plataformas para reducir las reescrituras específicas del proveedor. Eso significa que sus flujos de trabajo de dbt se ejecutan en una pila diseñada para la portabilidad, no para la dependencia.
Orqueste canalizaciones de dbt de principio a fin con Lakeflow Jobs
La orquestación es donde se acumula la complejidad operativa. Emparejar dbt con un orquestador externo junto con Databricks significa dos sistemas para operar, dos lugares para depurar y conexiones frágiles entre ellos.
Lakeflow Jobs elimina esa complejidad al tratar dbt como un tipo de tarea de primera clase dentro de una canalización unificada. En lugar de mantener una capa de orquestación separada, los equipos ejecutan dbt junto con la ingesta upstream y las acciones downstream en un solo flujo de trabajo. Por ejemplo, puede ingerir datos sin procesar con Auto Loader, transformar datos con modelos de dbt y luego activar actualizaciones de paneles o reentrenamiento de ML, todo en una sola canalización con lógica de reintento y gestión de dependencias unificadas. dbt en Databricks también permite la ingesta directamente a través de tablas de streaming. Para los usuarios de dbt Platform, la tarea dbt Platform (en Beta) permite a Lakeflow activar y gestionar flujos de trabajo de dbt que se ejecutan en dbt Platform.
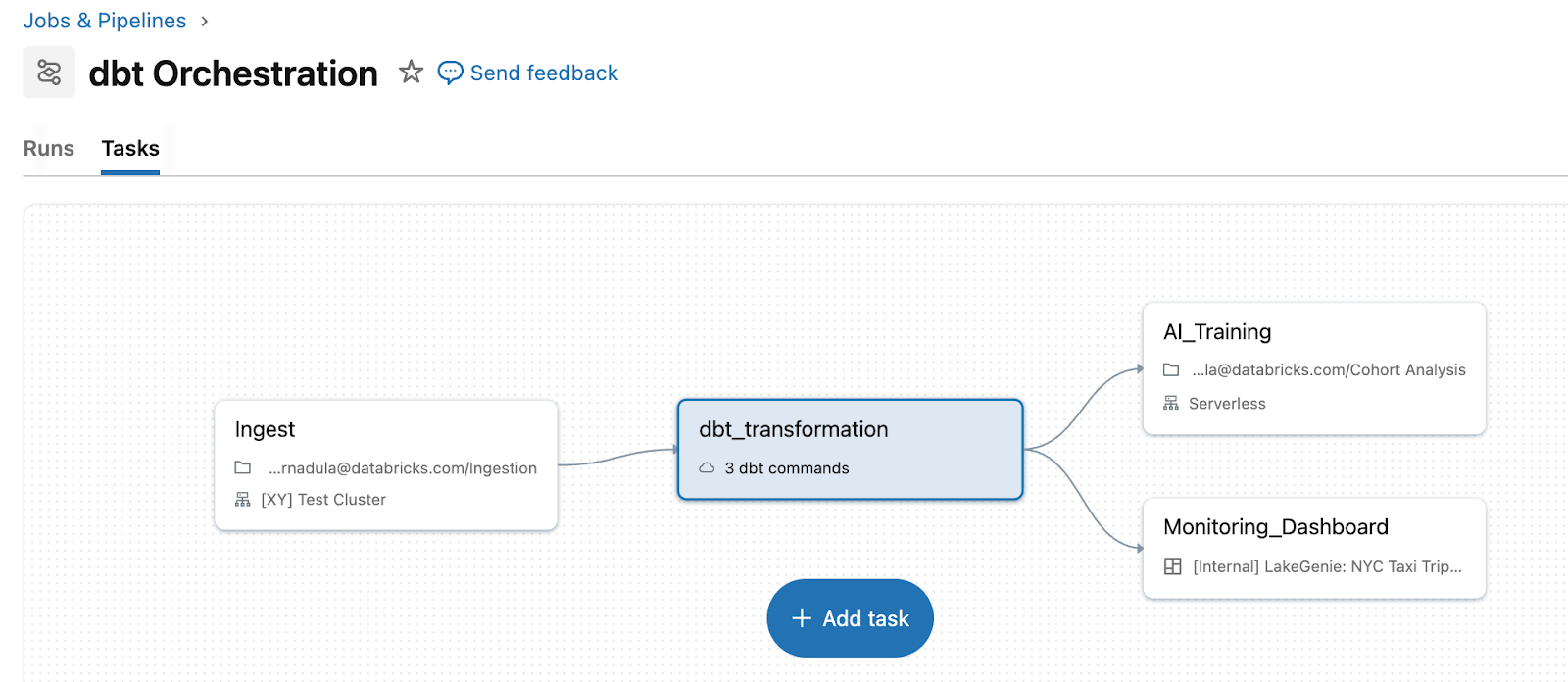
Cuando dbt se orquesta a través de Lakeflow, los fallos, reintentos y el contexto son visibles en un solo lugar. En lugar de cambiar entre un orquestador de dbt separado y los registros de Databricks, puede ver el fallo, las tareas posteriores afectadas y los paneles impactados directamente en la misma vista de ejecución del trabajo.
Haga de la gobernanza parte del flujo de trabajo predeterminado de dbt
A medida que escalan los flujos de trabajo de dbt, la gobernanza se convierte en el cuello de botella. Los equipos necesitan respuestas claras sobre el contenido de las tablas, la propiedad y los permisos de acceso. En las pilas tradicionales, este contexto está fragmentado en herramientas de catálogo separadas, sistemas de permisos y vistas de linaje incompletas que no se conectan de principio a fin.
Databricks resuelve esto con Unity Catalog, que unifica el control de acceso, el descubrimiento y el linaje para todo su lakehouse, no solo dentro de dbt, sino también en la ingesta, BI, ML/AI y más allá. Con Unity Catalog, no necesita volver a ejecutar sentencias de concesión cada vez que dbt recrea una tabla. Los permisos se gestionan a nivel de esquema y persisten en las reconstrucciones de tablas. Los controles granulares como filtros a nivel de fila, máscaras de columna y control de acceso basado en atributos se aplican de manera consistente en dbt, herramientas de BI y notebooks.
Por ejemplo, cuando persiste la documentación de dbt en Unity Catalog utilizando la funcionalidad persist_docs de dbt, las descripciones de columnas y el contexto redactados en dbt se vuelven descubribles donde se consultan y consumen los datos. Unity Catalog proporciona linaje de datos a nivel de columna que rastrea el flujo de datos desde la ingesta sin procesar a través de las transformaciones de dbt hasta el uso posterior. Cuando cambia un esquema de origen, puede ver instantáneamente qué modelos de dbt y activos posteriores se ven afectados. Este nivel de visibilidad es imposible cuando las canalizaciones de datos abarcan sistemas desconectados.
La gobernanza de costos es tan importante como la gobernanza de datos. Con las etiquetas de consulta, puedes adjuntar contexto de negocio a las ejecuciones de dbt y rastrear el gasto por equipo, proyecto o entorno a través de las Tablas del Sistema. Los equipos finalmente pueden responder "¿cuánto cuestan nuestros pipelines de dbt de análisis de marketing?" con datos reales en lugar de estimaciones. Además, DBSQL Granular Cost Monitoring (en Vista Previa Privada) también proporciona monitoreo de costos agregado en todas las cargas de trabajo de dbt.
Ejecuta dbt con un sólido rendimiento de precio desde el primer día
Optimizar un almacén de datos para el rendimiento generalmente requiere trabajo manual continuo. Los equipos a menudo terminan sacrificando la velocidad de desarrollo por la higiene del rendimiento.
Databricks abstrae esta complejidad al combinar un motor de ejecución de alto rendimiento con características que funcionan de forma nativa con dbt,ofreciendo mejoras de velocidad sin sobrecarga manual.
Rendimiento integrado
- Photon el motor acelera las cargas de trabajo SQL a través de la ejecución vectorizada, ofreciendo hasta12 veces mejor rendimiento de precio en comparación con los almacenes de datos en la nube. Los almacenes SQL sin servidor incluyen Photon por defecto, por lo que los equipos obtienen un rendimiento acelerado sin costo adicional.
- Optimización Predictiva utiliza IA para monitorear tablas y automatizar el mantenimiento, logrando hasta20 veces consultas más rápidas. Esto reduce la necesidad de post-hooks OPTIMIZE manuales en los que los ingenieros de dbt se basaban históricamente.
Características de rendimiento desbloqueadas a través de la configuración de dbt
- La integración de dbt conLiquid Clustering que reemplaza las estrategias de partición rígidas con un enfoque flexible que se ajusta dinámicamente a medida que crece el volumen de datos, lo que resulta en hasta 10 veces velocidades más rápidas sin ajuste manual
- Vistas Materializadas en dbt, impulsadas por pipelines declarativos de Spark de código abierto, manejan el procesamiento incremental automáticamente. Databricks gestiona la complejidad de determinar qué necesita actualizarse y solo procesa registros nuevos o modificados, en lugar de recalcular conjuntos de datos completos. Esto ofrece menores costos de cómputo en comparación con las ineficientes actualizaciones por lotes programadas.
Con estas características, los usuarios dedican menos tiempo a la optimización y más tiempo a la creación de pipelines que se mantienen eficientes a medida que crecen los conjuntos de datos. Solo en 2025, Databricks SQL logró unamejora de rendimiento del 10% en cargas de trabajo ETL (consultas con escrituras) sin necesidad de configuraciones adicionales.
Comienza hoy
Databricks reúne almacenamiento abierto, gobernanza unificada, sólido rendimiento de precio y operaciones integradas en un solo lugar para flujos de trabajo de dbt. Únete a los más de 2900 clientes que ya ejecutan dbt en Databricks. Comienza siguiendo laguía de inicio rápido.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.