Plateforme de serving d'IA qui s'adapte à votre modèle
Une plateforme unique pour tous les modèles d'IA - ML classique, deep learning et agents - plus de 300K QPS, moins de 10 ms, sans configuration
par Anshul Gupta
- Ce que c'est : Une plateforme entièrement gérée qui exécute n'importe quel modèle en production, d'un classificateur scikit-learn de 2 Mo sur un seul cœur CPU à un LLM de 70B affiné sur huit GPU, sans aucun réglage.
- Le défi résolu : Les modèles personnalisés présentent des profils de ressources et des modèles de trafic extrêmement variés, de sorte qu'aucune configuration statique unique ne leur convient. La plateforme s'adapte à la place, maintenant une faible latence tout en garantissant l'efficacité de chaque nœud.
- Les résultats : Plus de 300K QPS avec une surcharge de latence p99 <10 ms et jusqu'à 90 % de réduction des coûts d'infrastructure pour les clients migrant depuis des architectures autogérées.
Défis liés à l'exécution d'inférences de modèles personnalisés
Lorsque vous déployez un modèle de machine learning en production, vous vous engagez sur un contrat : chaque requête s'exécute en quelques millisecondes, quels que soient les pics de trafic, et votre facture reste basse lorsque le trafic est faible. Le service de modèles (model serving) est l'infrastructure qui garantit ce contrat, et pendant la majeure partie de l'histoire de notre secteur, le respecter a été aussi difficile que de construire le modèle lui-même.
Les modèles personnalisés sont fondamentalement différents des modèles de fondation. Une plateforme hébergeant un modèle de fondation (Llama, Mistral, une variante de CLIP) sait exactement ce qu'elle exécute : l'architecture, l'empreinte mémoire, les caractéristiques d'inférence, et peut optimiser en profondeur pour ce modèle unique. Les plateformes de modèles personnalisés sont tout le contraire. La même plateforme doit servir un classificateur scikit-learn de 2 Mo sur un seul cœur CPU et un LLM de 70B affiné sur huit GPU ; un outil de classement à faible latence qui ne tolère pas la mise en file d'attente et un modèle d'embedding qui s'épanouit avec un traitement par lots (batching) agressif. Une plateforme capable de servir tous les types de modèles, sans que deux d'entre eux ne partagent le même profil de ressources, la même forme de trafic ou le même budget de latence.
Les plateformes traditionnelles rejettent cette complexité sur le client : nombre de réplicas, simultanéité par réplica, seuils d'autoscaling. C'est toujours du DIY, mais à un niveau d'abstraction plus élevé. Et cela ne s'arrête jamais : chaque nouveau modèle et chaque variation de trafic impliquent un nouveau profilage et de nouveaux ajustements. Vos meilleurs ingénieurs passent donc leur temps à éteindre des incendies en production avant et après le déploiement, et le serving devient le boulet qui ralentit chaque lancement. Le résultat est le coût le plus important : des modèles validés en dev restent bloqués pendant des semaines avant d'atteindre la production.
Notre mission : éliminer la taxe sur la pile ML
Réajuster manuellement l'infrastructure de serving est une taxe sur chaque modèle exécuté par une organisation ; à grande échelle, cela devient structurel, les équipes devant mettre en place des groupes de serving dédiés dont le seul rôle est de maintenir les modèles actifs et performants en production. C'est ce que nous appelons la taxe sur la pile ML.
Databricks Custom Model Serving est une plateforme d'inférence en temps réel entièrement gérée pour n'importe quel modèle packagé dans MLflow. Notre mission est d'effacer cette taxe à travers trois étapes de la vie d'un modèle, afin que les équipes de serving de nos clients puissent se concentrer sur une création de valeur plus sophistiquée :
- Simplifier la préproduction. Un modèle entraîné dans Databricks se déploie en un seul clic : nous reproduisons exactement l'environnement, sans surprise au moment de l'exécution (runtime), et optimisons le temps de déploiement pour que les itérations et les rollbacks restent rapides.
- Rendre la production fiable, évolutive et rentable. L'infrastructure s'adapte à chaque modèle et à son trafic au moment de l'exécution, maintenant une faible latence et des coûts réduits sans aucun paramètre à configurer. (Le sujet principal de cet article.)
- Simplifier la postproduction. Chaque point de terminaison (endpoint) émet nativement de la télémétrie dans Unity Catalog (métriques, journaux et traces natifs OTel, tables d'inférence instantanées capturant chaque requête vers Delta et MLflow Tracing). Genie Code chapeaute le tout pour offrir une observabilité opérationnelle agentique unique en genre. L'observabilité pour l'AI est un problème de contexte, et l'ensemble du contexte réside sur une seule et même plateforme.
Cela fonctionne parce que Custom Model Serving est intégré nativement dans Databricks : les données, les fonctionnalités (features), l'entraînement, le packaging MLflow, le serving et les agents forment une pile unique et gouvernée, et non des systèmes distincts assemblés tant bien que mal.
Cet article traite de la deuxième étape : comment nous atteignons plus de 300 000 QPS avec une faible latence sur une grande variété de modèles grâce à une approche sans configuration. C'est ce qui fait disparaître la taxe.
Architecture
Trois contraintes façonnent chaque décision de l'architecture : faible latence, grande échelle et rentabilité. Elles s'opposent les unes aux autres (le moyen le plus simple de réduire la latence est le surprovisionnement, le moyen le plus simple de réduire les coûts est le sous-provisionnement) et concilier les trois à la fois, pour chaque type de modèle, sans aucun gaspillage de ressources, constitue le véritable défi d'ingénierie.
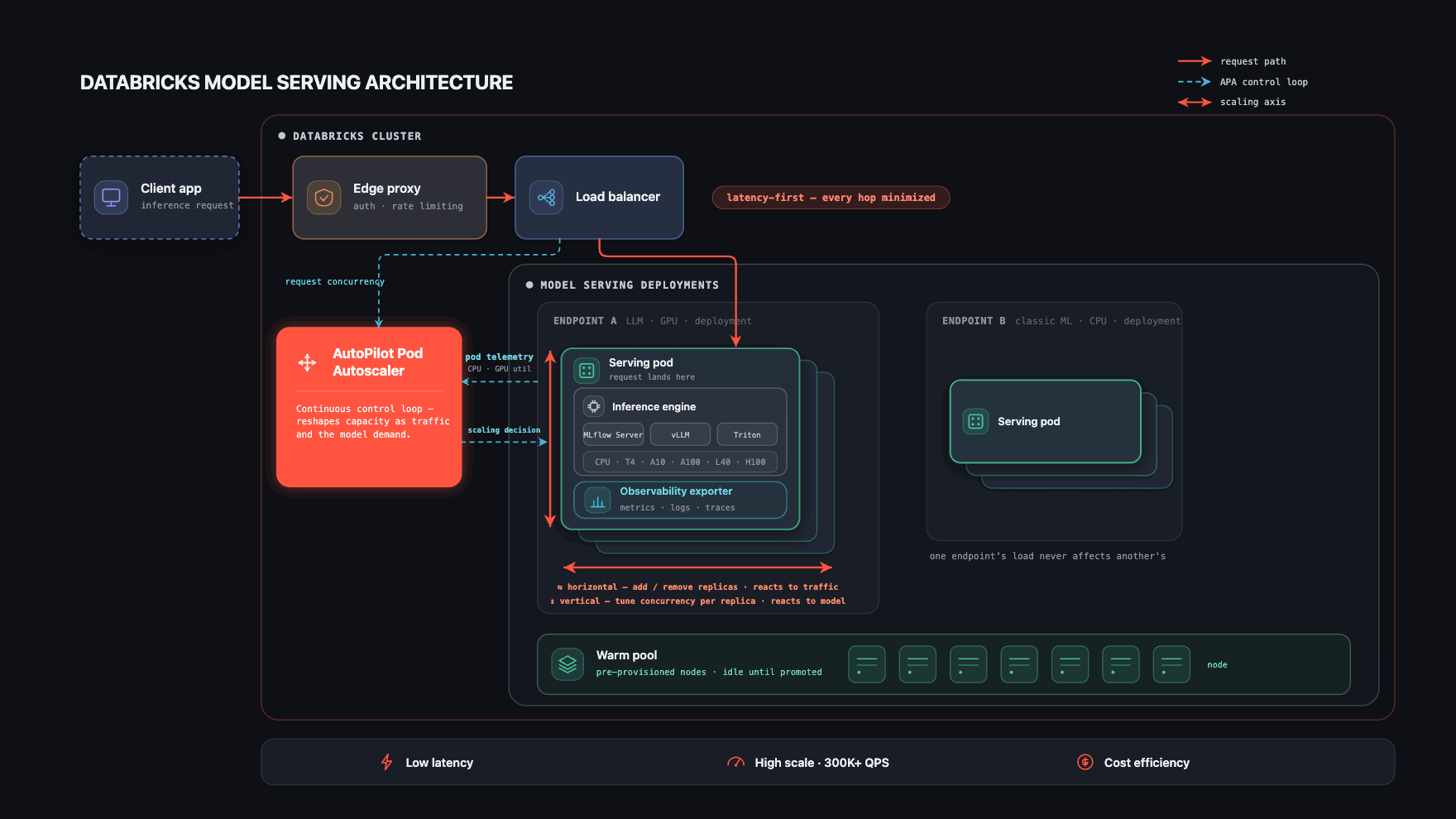
Trois éléments permettent d'y parvenir.
- Un chemin de requête court et isolé qui maintient la surcharge de latence minimale à chaque étape.
- Sélection automatique du runtime - chaque modèle est servi sur le moteur d'inférence qui lui est le mieux adapté.
- Le cœur de la plateforme : un outil d'autoscaling qui s'adapte en temps réel à la fois au modèle et à son trafic, maintenant une faible latence et une grande évolutivité tout en réduisant les coûts.
Les deux premiers permettent de traiter rapidement une seule requête ; le troisième maintient l'ensemble du système rapide et rentable à mesure que les modèles et le trafic évoluent. La majeure partie de cette section est consacrée au troisième point.
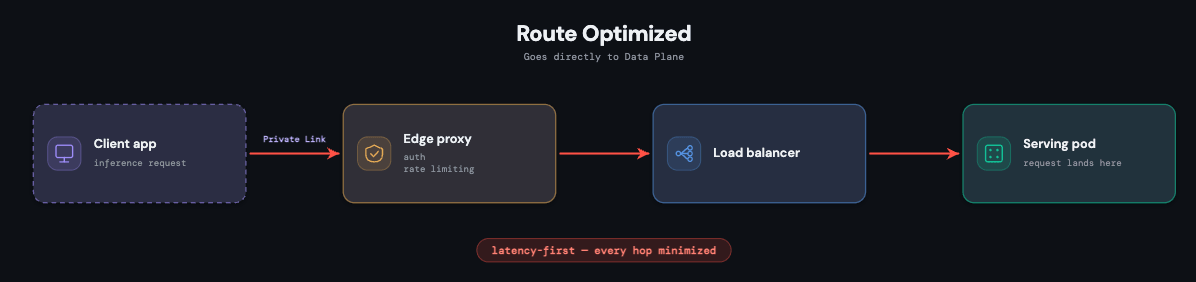
Chemin de requête court et isolé
Chaque point de terminaison (endpoint) de serving est un déploiement Kubernetes entièrement isolé avec ses propres pods et une image de conteneur spécifique à la version du modèle. Cette isolation est délibérée : le trafic, les pannes ou la pression sur les ressources d'un point de terminaison ne peuvent pas en affecter un autre, ce qui garantit la sécurité des charges de travail (workloads) personnalisées.
Le chemin lui-même est maintenu aussi court que possible, car la latence est une contrainte de premier ordre à chaque niveau. Une requête arrive via un proxy PoP ; une fois authentifiée, elle passe par un équilibreur de charge (load balancer) partagé pour la gestion des connexions et arrive immédiatement sur le pod qui la sert. Chaque pod exécute également un sidecar d'observabilité qui exporte les métriques, les journaux (logs), les journaux de charge utile (payload logs) et les traces, tant pour la surveillance de la plateforme que pour les tableaux de bord destinés aux clients.
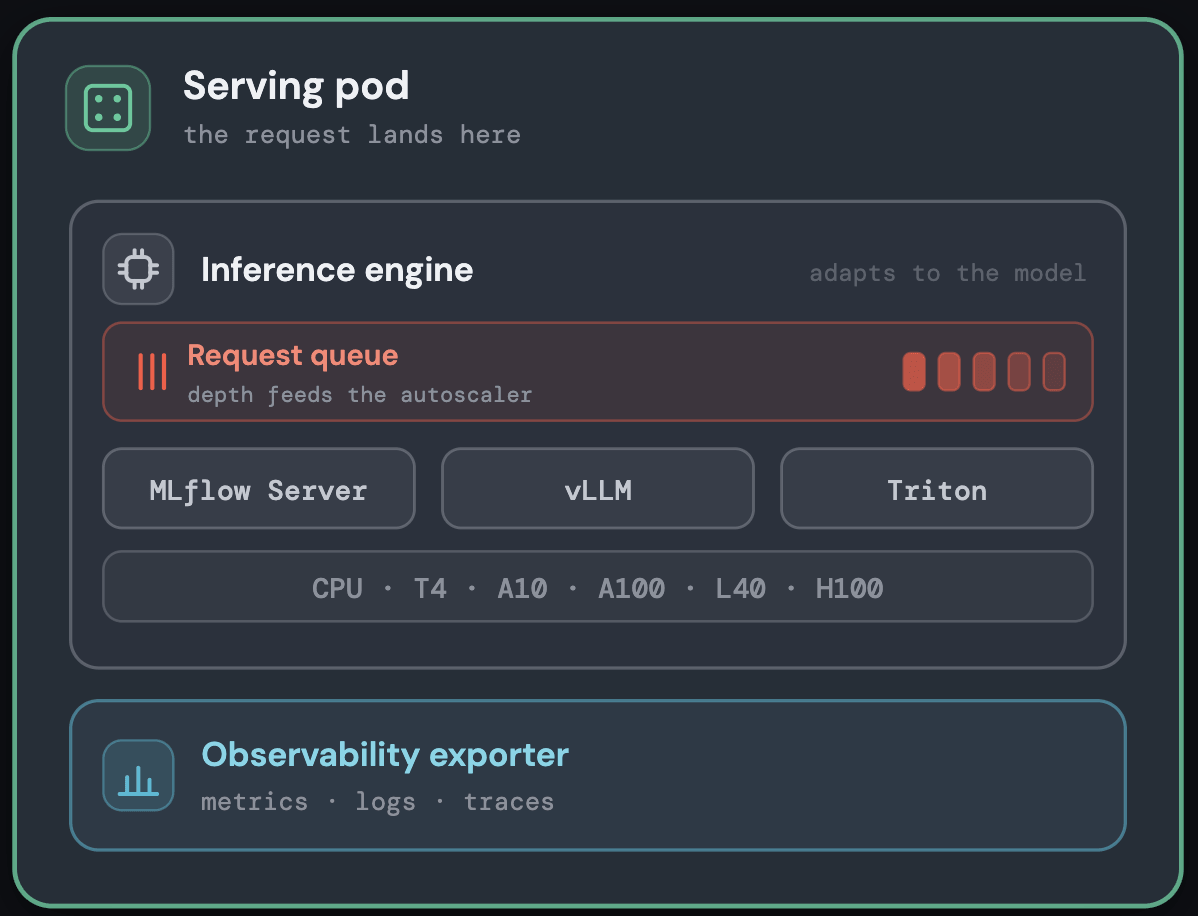
Sélection efficace du runtime de modèle
À l'intérieur de chaque pod, le modèle s'exécute sur le moteur d'inférence le mieux adapté à son type : un serveur MLflow Gunicorn asynchrone pour les modèles ML classiques, et des moteurs optimisés pour les GPU pour les grands modèles avec prise en charge de vLLM, Triton ou du propre runtime du client, le tout derrière une interface de serving uniforme.
Associer à chaque modèle le bon runtime permet de maintenir une faible surcharge par requête sans ajustement manuel ; les détails sont présentés dans le schéma ci-dessous.
L'autoscaler : s'adapter au modèle et au trafic
Un contrôleur Kubernetes personnalisé que nous avons développé, l'AutoPilot Pod Autoscaler (APA), se trouve au cœur de la plateforme. Il collecte en continu des signaux provenant de l'équilibreur de charge (simultanéité active, profondeur de la file d'attente) et des pods eux-mêmes (utilisation du CPU, utilisation du GPU, mémoire GPU, entre autres), et les transforme en décisions de mise à l'échelle.
L'autoscaler existe pour absorber simultanément deux types d'imprévisibilité :
- Le modèle est imprévisible. Vous ne connaissez pas à l'avance le profil de ressources d'un modèle personnalisé. Un modèle xgboost gourmand en CPU peut ne servir qu'une seule requête par cœur, un agent peut exécuter des centaines de requêtes par cœur, tandis qu'un LLM 13B affiné tire parti du traitement par lots de plusieurs requêtes. APA apprend la limite de chaque modèle au moment de l'exécution et ajuste le nombre de requêtes que chaque réplica doit accepter : mise à l'échelle verticale prenant en compte le modèle.
- Le trafic est imprévisible. Il connaît des pics, des rafales et peut chuter à zéro sans avertissement. Un point de terminaison de détection des fraudes peut être multiplié par 10 en quelques secondes au début d'une vente ; un cas d'usage spécifique à une région peut être fortement sollicité pendant une heure puis rester inactif toute la nuit. APA réagit dès que la demande évolue : mise à l'échelle horizontale basée sur les requêtes.
C'est pourquoi l'autoscaler est le cœur du système : c'est le seul composant qui gère simultanément les trois contraintes (latence, échelle et coût) pour chaque modèle de la plateforme.
Deux axes d'élasticité
Les outils d'autoscaling traditionnels effectuent soit une mise à l'échelle basée sur les requêtes, soit sur les ressources, mais chacun présente une faiblesse. La mise à l'échelle basée sur les requêtes réagit rapidement mais s'avère inefficace : elle traite chaque requête de la même manière, quel que soit le niveau de charge de chaque réplica, ce qui conduit soit à un surprovisionnement, soit à des fluctuations incessantes du nombre de réplicas. La mise à l'échelle basée sur les ressources (utilisation du CPU, du GPU) est efficace mais présente un temps de retard : les métriques d'utilisation suivent le trafic avec un décalage, de sorte qu'au moment où l'autoscaler se déclenche, l'impact sur le p99 est déjà effectif.
APA utilise les deux signaux à la fois, chacun excellant dans son domaine, et c'est précisément ce que représentent ces deux axes.
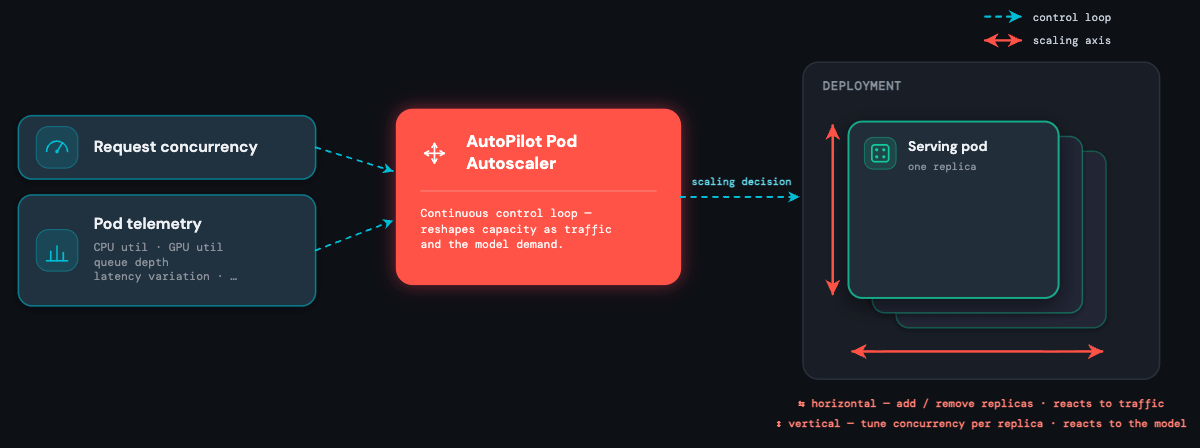
La mise à l'échelle horizontale réagit aux requêtes. Elle surveille les requêtes simultanées actives par point de terminaison et ajoute ou supprime des réplicas dès que la demande évolue. La formule suit celle du Kubernetes Horizontal Pod Autoscaler :
La mise à l'échelle verticale sensible au modèle réagit aux caractéristiques du modèle. Périodiquement, l'autoscaler examine un ensemble de métriques pour déterminer la charge qu'un seul réplica peut réellement supporter et ajuste target_concurrency dans la formule ci-dessus en conséquence. C'est fondamentalement différent de la mise à l'échelle verticale traditionnelle, qui modifie le type de matériel. Ici, le matériel reste le même : ce qui change, c'est le nombre de requêtes simultanées que chaque pod accepte, ajusté au profil de ressources du modèle qui s'y exécute.
Les métriques sur lesquelles nous nous appuyons incluent, sans s'y limiter :
- Métriques matérielles — utilisation CPU et GPU, utilisation de la mémoire, attente I/O
- Latence actuelle et profil de profondeur de file d'attente
- Métriques spécifiques aux GPU — bande passante mémoire, utilisation des FLOPS FP16/BF16
Garanties. Les modifications de la simultanéité par nœud sont sensibles, et des variations importantes ou fréquentes peuvent d�étériorer les performances du système. Les métriques des pods peuvent fluctuer lors de brèves variations de trafic ou lorsque le coût par requête est très différent d'un modèle à l'autre. Nous nous prémunissons contre ce bruit de métrique. Un pic soudain de CPU ne devrait pas réduire immédiatement la limite de simultanéité pour la réaugmenter quelques secondes plus tard. Nous prenons trois mesures pour cela :
La simultanéité n'est ajustée que lorsqu'une métrique franchit un seuil stable, et les seuils sont réglés par métrique.
- Nous plafonnons la variation maximale de simultanéité par cycle de décision
- We always enforce min/max concurrency limits for a workload
- Les changements de simultanéité se produisent à une cadence plus faible (toutes les 30 s) par rapport à la mise à l'échelle horizontale. C'est également important car ils s'appuient sur des métriques historiques, contrairement au trafic actuel comme le HPA.
Les deux axes sont couplés : le résultat de simultanéité de la mise à l'échelle verticale alimente le calcul de la mise à l'échelle horizontale via le dénominateur target_concurrency. La mise à l'échelle horizontale garantit la disponibilité et une faible latence dès que le trafic change. La mise à l'échelle verticale sensible au modèle garantit que chaque nœud est utilisé efficacement, en adaptant la simultanéité à mesure que le comportement du modèle évolue. Ensemble, ils évitent le faux choix entre rapide mais gaspilleur de ressources, et efficace mais lent.
Seuils de scale-up et de scale-down
La formule brute du HPA ne suffit pas à elle seule : elle n'est pas résiliente face aux pics de trafic. Un bref pic de 10× calcule une augmentation de 10× des réplicas ; une brève baisse de 95 % calcule une diminution de 95 %. Les deux sont dangereux, que ce soit pour les coûts ou pour la latence et la disponibilité.
Le scale-up horizontal est agressif En production, une latence élevée peut avoir un impact commercial négatif massif. De nombreux cas d'usage présentent naturellement des profils de trafic très irréguliers qu'il est crucial de prendre en charge. Pour gérer les pics, nous analysons les requêtes entrantes toutes les secondes et l'APA prend une décision de mise à l'échelle ascendante toutes les 5 secondes en fonction du trafic des 20 dernières secondes. Cela réduit considérablement la mise en file d'attente et les erreurs 429 lors des pics — de nombreux clients ont constaté une différence allant jusqu'à 5x. Nous limitons également la mesure dans laquelle nous pouvons effectuer un scale-up en un seul cycle par rapport à la charge actuelle. Globalement, nous pouvons passer de 10 à 10 000 QPS en moins de 60 secondes (selon le temps de chargement du modèle)
Le scale-down est conservateur. Un pic signale souvent l'arrivée de plus de trafic. Pour le scale-down, l'APA prend toujours une décision toutes les 5 secondes, mais prend en compte le trafic des dernières ~5 minutes avant de supprimer des réplicas.
L'asymétrie est intentionnelle. Les pics sont soudains ; les baisses sont souvent temporaires. Le coût d'un scale-down prématuré (un démarrage à froid au pire moment possible) l'emporte sur le coût du maintien temporaire de quelques réplicas inactifs.
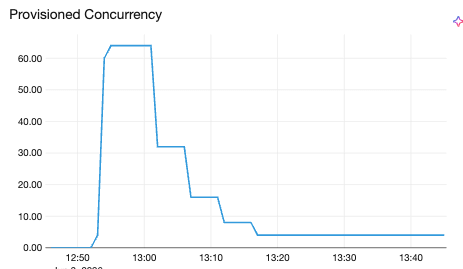
Scale-up et scale-down de la simultanéité verticale. La même philosophie asymétrique s'applique à la mise à l'échelle verticale : être rapide pour réduire la simultanéité lorsqu'un pod montre des signes de surcharge (acheminer moins de requêtes vers un réplica déjà chargé protège la latence), mais jamais en dessous d'un minimum. Ces décisions s'exécutent sur un intervalle de 30 secondes, plus lent que la boucle horizontale de 5 secondes. C'est intentionnel : la mise à l'échelle verticale est une optimisation en régime permanent qui s'adapte au profil de ressources d'un modèle au fil du temps, et non une réaction en temps réel aux pics.
Minimiser le temps de démarrage à froid
Un démarrage à froid est le pire événement de latence dans un système de serving ; vous ne pouvez pas y remédier par l'optimisation une fois qu'il se produit. Nous l'attaquons sur deux fronts : garder autant d'éléments préchauffés que possible, et rendre les étapes inévitables aussi rapides que possible.
Pools de nœuds préchauffés (warm pools). Un algorithme prédictif maintient un pool de nœuds pré-provisionnés par cluster Databricks, préchargés avec l'image d'exécution de base. Lorsque l'autoscaler ajoute un réplica, il le choisit dans ce pool : le nœud est déjà actif, l'image de base est déjà récupérée, et le seul travail restant est le téléchargement du modèle. Nous ne facturons pas les clients pour la capacité du warm pool ; c'est une valeur directe qu'ils obtiennent de Databricks.
Téléchargement rapide des modèles. Les images de conteneur de modèle sont stockées dans une couche de cache chaud dans le stockage cloud et récupérées par blocs parallèles au démarrage du pod, ce qui réduit considérablement le temps de récupération de l'image pour les grands conteneurs de modèles. Les modifications de configuration qui n'affectent pas le modèle ou ses dépendances (mises à jour des métadonnées du point de terminaison, modifications des règles de routage) sont appliquées sans redémarrer le pod du tout, car un redémarrage évité est le démarrage le plus chaud qui soit.
Simultanéité provisionnée. Pour les points de terminaison critiques en matière de latence qui ne peuvent tolérer aucun démarrage à froid, les utilisateurs configurent un seuil de simultanéité minimal. Cela maintient une base de pods entièrement prêts avec le modèle chargé et prêt à répondre immédiatement, sans file d'attente lors de la première requête.
Mises à jour et maintenance sans interruption. Les mises à jour et la maintenance se font totalement sans interruption de service. Tous pods dotés de la nouvelle version du modèle sont actifs et prêts avant que le trafic ne soit redirigé depuis les anciens pods.
Ce que nous avons appris en production
Les clients ont constaté des avantages dans toutes les dimensions :
- Coût : certains de nos clients ont réalisé plus de 90 % d'économies par rapport à leurs charges de travail DIY.
- Latence : la latence p99 et p50 a été améliorée jusqu'à 2x pour de nombreux clients.
- Échelle : les clients sont passés à plus de 100 000 QPS en production avec peu ou pas de maintenance.
- Nous maintenons une disponibilité de 99,99 % en production.
L'autoscaling sur deux axes se généralise à tous les types de modèles. Nous n'étions pas sûrs que l'approche horizontale + verticale fonctionnerait pour tout, des classificateurs CPU aux LLM sur GPU. C'est le cas : l'axe horizontal gère le trafic de la même manière pour chaque modèle, tandis que l'axe vertical s'établit sur une simultanéité plus élevée pour les modèles légers et plus faible pour ceux qui sollicitent fortement les GPU. Même contrôleur, même logique, le bon comportement pour chacun.
La plupart des modèles sont homogènes. Nous pensions que les limites de simultanéité dériveraient constamment avec le trafic ; en pratique, le profil de ressources d'un modèle sous une même charge reste globalement similaire. L'axe vertical prouve son utilité lors de la phase d'intégration, puis se stabilise.
On ne peut pas éliminer complètement les démarrages à froid par l'optimisation. Nous nous attendions à ce que les warm pools, les récupérations d'images en parallèle et la réutilisation des déploiements réduisent les démarrages à froid à presque zéro. Ils aident énormément — mais la physique a ses limites : démarrer un pod prend un temps qui augmente avec la taille du modèle, atteignant plusieurs minutes pour les grands modèles GPU. Au-delà de cette limite, la seule solution consiste à maintenir une capacité minimale entièrement prête, ce qui est précisément la raison d'être de la simultanéité provisionnée minimale.
Le trafic est plus prévisible qu'il n'y paraît. Le bon minimum n'est pas statique : les applications B2C se calment pendant la nuit, les pipelines de traitement par lots se déclenchent selon des calendriers. Ces schémas peuvent être appris, et nous développons des prévisions de trafic pour augmenter la simultanéité minimale avant la demande au lieu de la subir. Restez à l'écoute.
Conclusion
Nous nous sommes donné pour objectif de supprimer la taxe sur la pile ML : les réajustements incessants et l'équipe de serving dédiée que cela exige. Pour toute la diversité des modèles s'exécutant aujourd'hui sur Custom Model Serving, l'autoscaler sur deux axes, les warm pools et les déploiements sans interruption font exactement cela. L'infrastructure s'adapte au modèle et non l'inverse. Vous apportez un modèle, définissez une plage de simultanéité, et la plateforme s'occupe du reste.
Le serving de modèles n'est cependant pas un domaine entièrement résolu. Des modèles plus grands, de nouveaux matériels et des charges de travail agentiques continuent de pousser l'échelle et la complexité au-delà de ce pour quoi l'infrastructure de serving traditionnelle a été conçue. Les problèmes ouverts sont réels et l'ambition est grande : des temps de démarrage à froid plus courts, des prévisions de trafic pour une mise à l'échelle prédictive, plus de 1M de QPS par point de terminaison et plus de 10M de QPS par cluster, un bin-packing plus intelligent des charges de travail GPU hétérogènes, et une réduction de la latence p99 sous la barre des 5 ms.
Et c'est un problème que Databricks est idéalement positionné pour résoudre. Adapter l'infrastructure à un modèle implique de connaître ce modèle : comment il a été entraîné, de quoi il dépend et comment il se comporte en charge. Sur Databricks, tout cela repose sur une plateforme gouvernée unique : les données et les features, l'entraînement, le packaging MLflow, le serving, les agents et la télémétrie qui les surveille. Une couche de serving autonome ne voit qu'un conteneur ; nous voyons l'intégralité du cycle de vie. C'est ce contexte qui permet à la plateforme de s'adapter à chaque modèle, et c'est pourquoi aucun produit de serving d'appoint ne peut éliminer aussi efficacement la taxe sur la pile ML.
Si ce type de problème d'infrastructure vous intéresse, nous recrutons.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.