Contact partenaires
Découvrez et intégrez facilement des solutions de données, d'analytique et d'IA avec votre lakehouse.
Grâce à Partner Connect, découvrez facilement les données, l'analytique et l'IA directement au sein de la plateforme Databricks et intégrez rapidement les outils que vous utilisez déjà actuellement. Avec Partner Connect, vous pouvez simplifier l'intégration des outils en quelques clics et étendre rapidement les capacités de votre lakehouse.
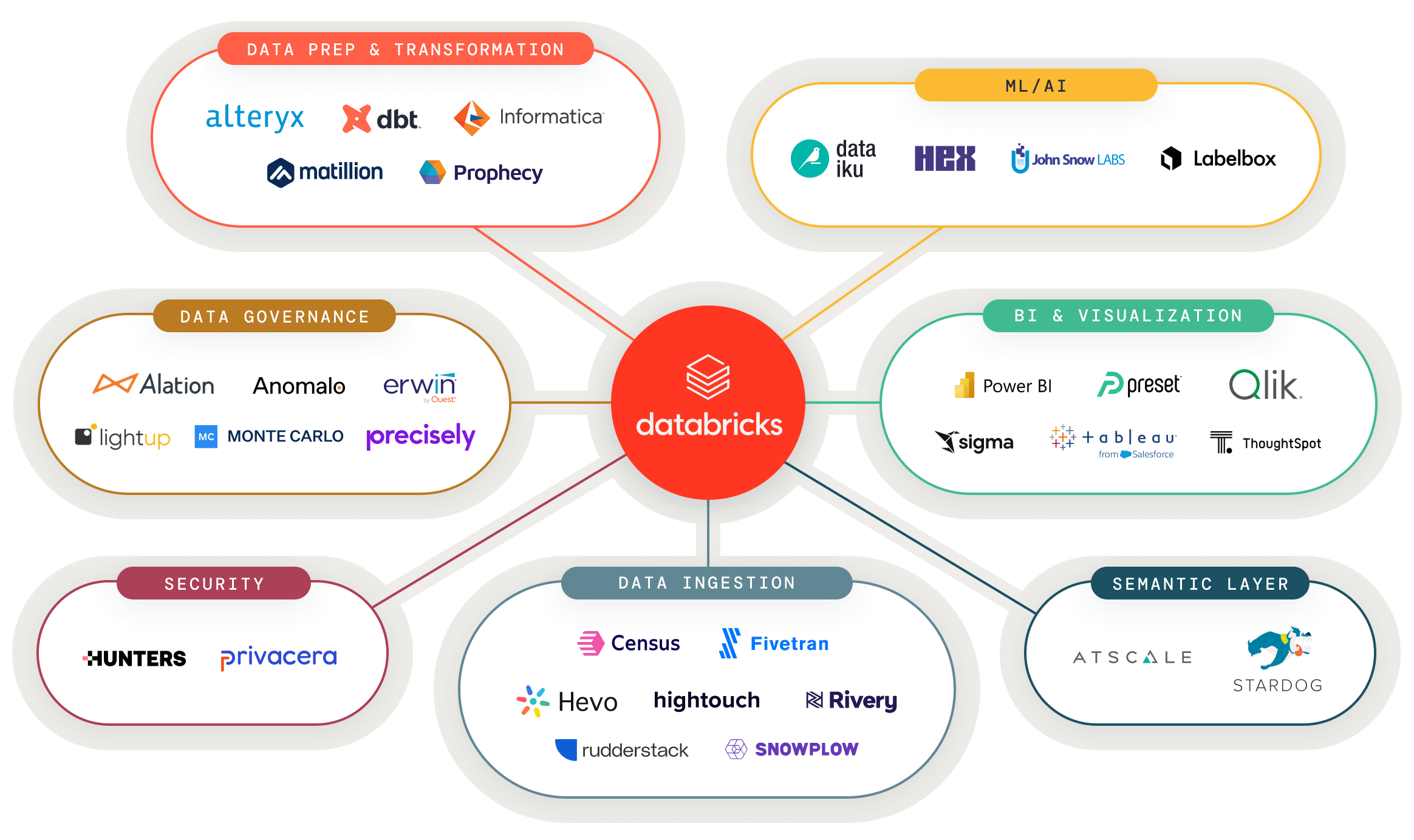
Connectez vos données et vos outils d'IA au lakehouse
Connectez facilement vos données et outils d'IA préférés au lakehouse et alimentez n'importe quel cas d'usage analytique

Découvrez des solutions de données et d'IA validées pour de nouveaux cas d'usage
Un portail unique pour les solutions partenaires validées afin que vous puissiez créer votre prochaine application de données plus rapidement.
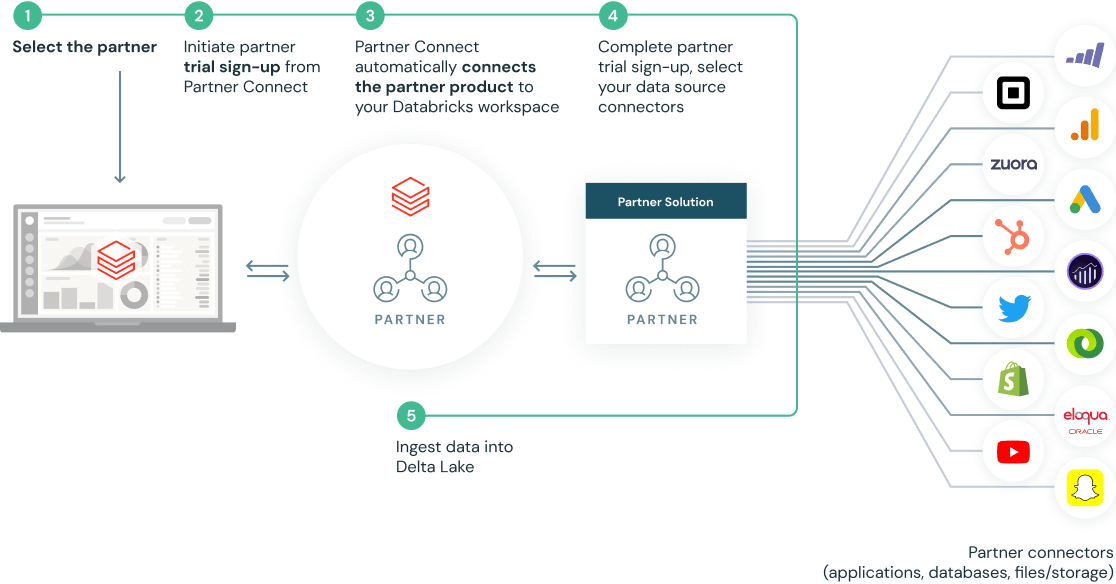
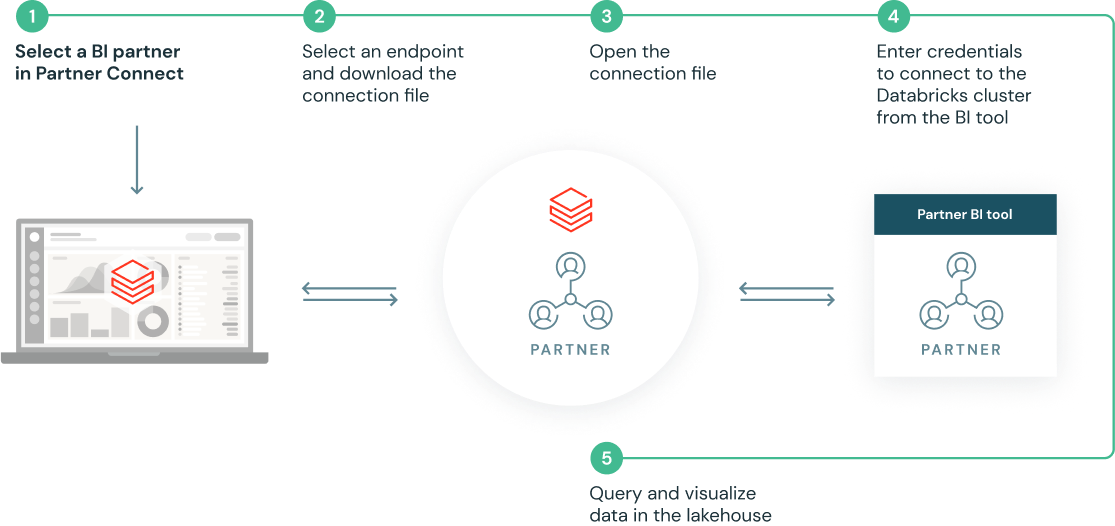
Configuration en quelques clics grâce à des intégrations prédéfinies
Partner Connect simplifie vos intégrations en configurant automatiquement les ressources (y compris les clusters, les jetons et les fichiers de connexion) pour vous connecter aux solutions partenaires
Commencez en tant que partenaire
Les partenaires de Databricks sont idéalement positionnés pour fournir des insights d'analytique plus rapides aux clients. Tirez parti du développement et des ressources partenaires de Databricks pour développer votre activité aux côtés de notre plateforme ouverte et basée dans le cloud.
Démos
Ressources
Blog
Documentation
Vous voulez en savoir plus ?
Tirez parti du développement et des ressources partenaires de Databricks pour développer votre activité aux côtés de notre plateforme ouverte et basée dans le cloud