Présentation de DBRX : un nouveau LLM open source de pointe
Aujourd'hui, nous sommes ravis de présenter DBRX, un LLM généraliste et ouvert créé par Databricks. Sur une gamme de benchmarks standard, DBRX établit un nouveau record pour les LLM ouverts existants. De plus, il offre à la communauté ouverte et aux entreprises qui développent leurs propres LLM des capacités qui étaient auparavant limitées aux API de modèles fermés ; selon nos mesures, il surpasse GPT-3.5 et est compétitif avec Gemini 1.0 Pro. C'est un modèle de code particulièrement performant, surpassant les modèles spécialisés comme CodeLLaMA-70B en programmation, en plus de sa force en tant que LLM généraliste.
Cette qualité de pointe s'accompagne d'améliorations notables en matière de performance d'entraînement et d'inférence. DBRX fait progresser l'état de l'art en matière d'efficacité parmi les modèles ouverts grâce à son architecture fine-grained mixture-of-experts (MoE). L'inférence est jusqu'à 2 fois plus rapide que LLaMA2-70B, et DBRX représente environ 40 % de la taille de Grok-1 en termes de nombre total et actif de paramètres. Lorsqu'il est hébergé sur Databricks Model Serving, DBRX peut générer du texte jusqu'à 150 tok/s/utilisateur. Nos clients constateront que l'entraînement des MoE est également environ 2 fois plus efficace en termes de FLOP que l'entraînement de modèles denses pour la même qualité finale du modèle. Globalement, notre recette complète pour DBRX (y compris les données de pré-entraînement, l'architecture du modèle et la stratégie d'optimisation) peut égaler la qualité de nos modèles MPT de génération précédente avec près de 4 fois moins de calcul.
Les poids du modèle de base (DBRX Base) et du modèle affiné (DBRX Instruct) sont disponibles sur Hugging Face sous une licence ouverte. À partir d'aujourd'hui, DBRX est disponible pour les clients Databricks via des API, et les clients Databricks peuvent pré-entraîner leurs propres modèles de classe DBRX à partir de zéro ou continuer l'entraînement sur l'un de nos checkpoints en utilisant les mêmes outils et la même science que nous avons utilisés pour le construire. DBRX est déjà intégré dans nos produits basés sur GenAI, où - dans des applications comme SQL - les déploiements précoces ont surpassé GPT-3.5 Turbo et défient GPT-4 Turbo. C'est également un modèle de premier plan parmi les modèles ouverts et GPT-3.5 Turbo sur les tâches RAG.
L'entraînement des modèles mixture-of-experts est difficile. Nous avons dû surmonter une variété de défis scientifiques et de performance pour construire un pipeline suffisamment robuste pour entraîner de manière répétable des modèles de classe DBRX de manière efficace. Maintenant que nous l'avons fait, nous avons une pile d'entraînement unique qui permet à toute entreprise d'entraîner des modèles fondamentaux MoE de classe mondiale à partir de zéro. Nous sommes impatients de partager cette capacité avec nos clients et de partager nos leçons apprises avec la communauté.
Téléchargez DBRX dès aujourd'hui depuis Hugging Face (DBRX Base, DBRX Instruct), ou essayez DBRX Instruct dans notre HF Space, ou consultez notre dépôt de modèles sur github : databricks/dbrx.
Qu'est-ce que DBRX ?
DBRX est un grand modèle linguistique (LLM) décodeur-seulement basé sur le transformer qui a été entraîné en utilisant la prédiction du prochain token. Il utilise une architecture fine-grained mixture-of-experts (MoE) avec 132 milliards de paramètres totaux, dont 36 milliards de paramètres sont actifs sur une entrée donnée. Il a été pré-entraîné sur 12 billions de tokens de données textuelles et de code. Comparé à d'autres modèles MoE ouverts comme Mixtral et Grok-1, DBRX est fine-grained, ce qui signifie qu'il utilise un plus grand nombre d'experts plus petits. DBRX a 16 experts et en choisit 4, tandis que Mixtral et Grok-1 ont 8 experts et en choisissent 2. Cela offre 65 fois plus de combinaisons possibles d'experts et nous avons constaté que cela améliore la qualité du modèle. DBRX utilise des encodages de position rotatifs (RoPE), des unités linéaires à portes (GLU) et une attention groupée par requêtes (GQA). Il utilise le tokenizer GPT-4 tel que fourni dans le dépôt tiktoken. Nous avons fait ces choix sur la base d'évaluations exhaustives et d'expériences de mise à l'échelle.
DBRX a été pré-entraîné sur 12 billions de tokens de données soigneusement sélectionnées et une longueur de contexte maximale de 32k tokens. Nous estimons que ces données sont au moins 2 fois meilleures token par token que les données que nous avons utilisées pour pré-entraîner la famille de modèles MPT. Ce nouvel ensemble de données a été développé en utilisant la suite complète d'outils Databricks, y compris Apache Spark™ et les notebooks Databricks pour le traitement des données, Unity Catalog pour la gestion et la gouvernance des données, et MLflow pour le suivi des expériences. Nous avons utilisé l'apprentissage par curriculum pour le pré-entraînement, en modifiant le mélange de données pendant l'entraînement de manière à améliorer considérablement la qualité du modèle.
Qualité sur les Benchmarks par rapport aux Modèles Ouverts de Premier Plan
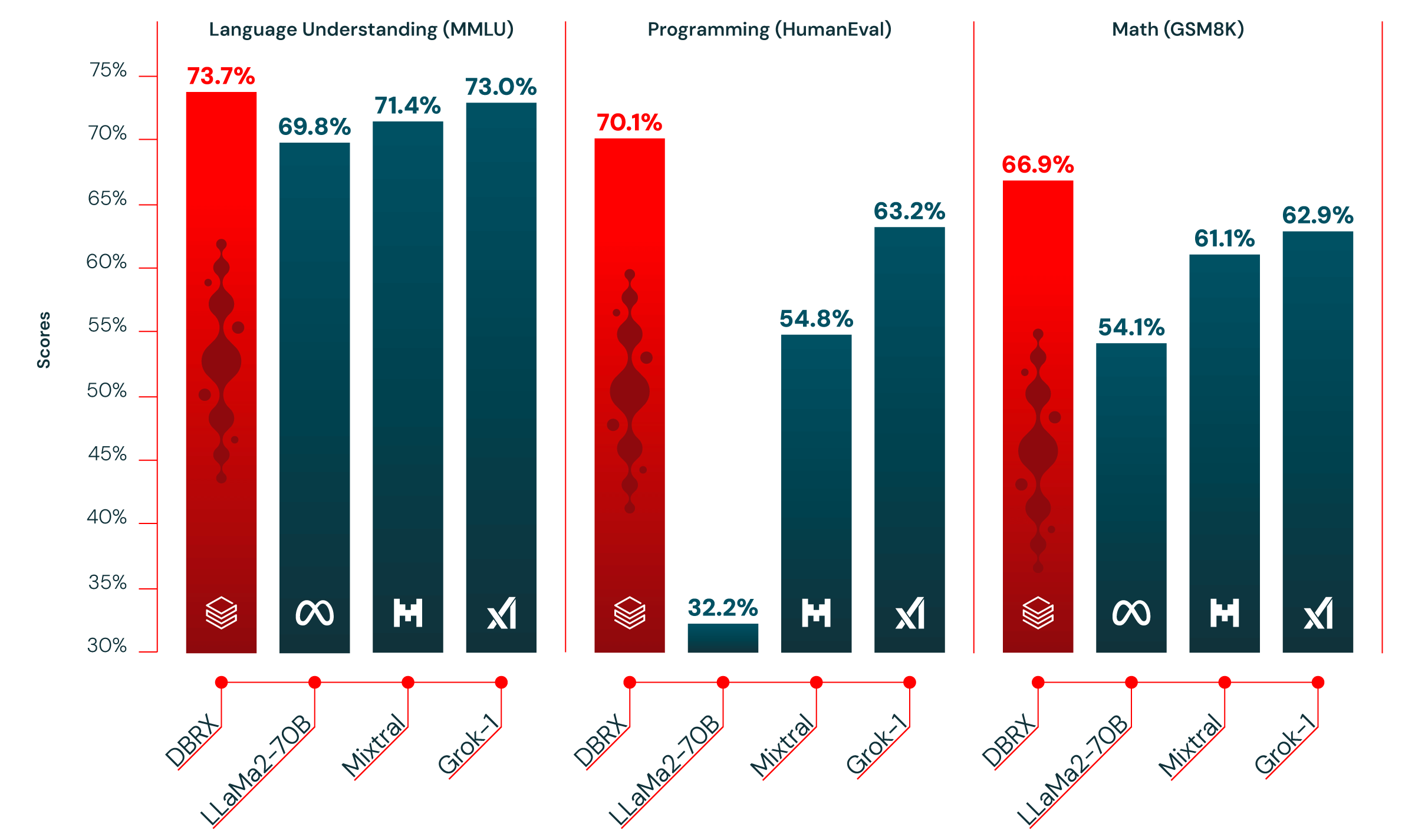
Le tableau 1 montre la qualité de DBRX Instruct et des modèles ouverts établis de premier plan. DBRX Instruct est le modèle de premier plan sur les benchmarks composites, les benchmarks de programmation et de mathématiques, et MMLU. Il surpasse tous les modèles de chat ou d'instruction affinés sur les benchmarks standard.
Benchmarks composites. Nous avons évalué DBRX Instruct et ses pairs sur deux benchmarks composites : le Hugging Face Open LLM Leaderboard (la moyenne de ARC-Challenge, HellaSwag, MMLU, TruthfulQA, WinoGrande et GSM8k) et le Databricks Model Gauntlet (une suite de plus de 30 tâches couvrant six catégories : connaissances générales, raisonnement de bon sens, compréhension du langage, compréhension de lecture, résolution de problèmes symboliques et programmation).
Parmi les modèles que nous avons évalués, DBRX Instruct obtient les meilleurs scores sur deux benchmarks composites : le Hugging Face Open LLM Leaderboard (74,5 % contre 72,7 % pour le modèle suivant le plus performant, Mixtral Instruct) et le Databricks Gauntlet (66,8 % contre 60,7 % pour le modèle suivant le plus performant, Mixtral Instruct).
Programmation et mathématiques. DBRX Instruct est particulièrement performant en programmation et en mathématiques. Il obtient des scores plus élevés que les autres modèles ouverts que nous avons évalués sur HumanEval (70,1 % contre 63,2 % pour Grok-1, 54,8 % pour Mixtral Instruct et 32,2 % pour la variante LLaMA2-70B la plus performante) et GSM8k (66,9 % contre 62,9 % pour Grok-1, 61,1 % pour Mixtral Instruct et 54,1 % pour la variante LLaMA2-70B la plus performante). DBRX surpasse Grok-1, le modèle suivant le plus performant sur ces benchmarks, bien que Grok-1 ait 2,4 fois plus de paramètres. Sur HumanEval, DBRX Instruct surpasse même CodeLLaMA-70B Instruct, un modèle conçu spécifiquement pour la programmation, bien que DBRX Instruct soit conçu pour un usage généraliste (70,1 % contre 67,8 % sur HumanEval, tel que rapporté par Meta dans le blog CodeLLaMA).
MMLU. DBRX Instruct obtient des scores plus élevés que tous les autres modèles que nous considérons sur MMLU, atteignant 73,7 %.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tableau 1. Qualité de DBRX Instruct et des principaux modèles ouverts. Voir les notes de bas de page pour les détails sur la collecte des chiffres. Le score le plus élevé est en gras et souligné.
Qualité sur les benchmarks par rapport aux modèles fermés de premier plan
Le Tableau 2 montre la qualité de DBRX Instruct et des principaux modèles fermés. Selon les scores rapportés par chaque créateur de modèle, DBRX Instruct surpasse GPT-3.5 (tel que décrit dans le papier GPT-4), et il est compétitif avec Gemini 1.0 Pro et Mistral Medium.
Sur la quasi-totalité des benchmarks que nous avons considérés, DBRX Instruct surpasse ou, au pire, égale GPT-3.5. DBRX Instruct surpasse GPT-3.5 en connaissances générales mesurées par MMLU (73,7 % contre 70,0 %) et en raisonnement de bon sens mesurées par HellaSwag (89,0 % contre 85,5 %) et WinoGrande (81,8 % contre 81,6 %). DBRX Instruct excelle particulièrement en programmation et en raisonnement mathématique mesurés par HumanEval (70,1 % contre 48,1 %) et GSM8k (72,8 % contre 57,1 %).
DBRX Instruct est compétitif avec Gemini 1.0 Pro et Mistral Medium. Les scores de DBRX Instruct sont supérieurs à ceux de Gemini 1.0 Pro sur Inflection Corrected MTBench, MMLU, HellaSwag et HumanEval, tandis que Gemini 1.0 Pro est plus performant sur GSM8k. Les scores de DBRX Instruct et Mistral Medium sont similaires sur HellaSwag, tandis que Mistral Medium est plus performant sur Winogrande et MMLU, et DBRX Instruct est plus performant sur HumanEval, GSM8k et Inflection Corrected MTBench.
|
|
|
|
|
|
|
|
|
|
|
|
|
Inflection corrigé, n=5) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 2. Qualité de DBRX Instruct et des principaux modèles fermés. À l'exception de l'Inflection Corrected MTBench (que nous avons mesuré nous-mêmes sur les points de terminaison du modèle), les chiffres ont été rapportés par les créateurs de ces modèles dans leurs livres blancs respectifs. Voir les notes de bas de page pour plus de détails.
Qualité sur les tâches à contexte long et RAG
DBRX Instruct a été entraîné avec une fenêtre de contexte allant jusqu'à 32K tokens. Le Tableau 3 compare ses performances à celles de Mixtral Instruct et des dernières versions des API GPT-3.5 Turbo et GPT-4 Turbo sur une suite de benchmarks de contexte long (paires clé-valeur du papier Lost in the Middle et HotpotQAXL, une version modifiée de HotPotQA qui étend la tâche à des séquences plus longues). GPT-4 Turbo est généralement le meilleur modèle pour ces tâches. Cependant, à une exception près, DBRX Instruct surpasse GPT-3.5 Turbo à toutes les longueurs de contexte et dans toutes les parties de la séquence. Les performances globales de DBRX Instruct et Mixtral Instruct sont similaires.
|
|
|
|
|
|
|
|
|
|
|
% |
|
|
|
|
|
% |
|
|
|
|
|
% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tableau 3. Performance moyenne des modèles sur les benchmarks KV-Pairs et HotpotQAXL. Le gras indique le meilleur score. Le souligné indique le meilleur score autre que GPT-4 Turbo. GPT-3.5 Turbo prend en charge une longueur de contexte maximale de 16K, nous n'avons donc pas pu l'évaluer à 32K. *Les moyennes pour le début, le milieu et la fin de la séquence pour GPT-3.5 Turbo incluent uniquement les contextes jusqu'à 16K.
L'une des façons les plus populaires d'exploiter le contexte d'un modèle est la génération augmentée par récupération (RAG). En RAG, le contenu pertinent pour une invite est récupéré d'une base de données et présenté avec l'invite pour donner au modèle plus d'informations qu'il n'en aurait autrement. Le Tableau 4 montre la qualité de DBRX sur deux benchmarks RAG - Natural Questions et HotPotQA - lorsque le modèle reçoit également les 10 meilleurs passages récupérés d'un corpus d'articles Wikipedia à l'aide du modèle d'embedding bge-large-en-v1.5. DBRX Instruct est compétitif avec les modèles ouverts comme Mixtral Instruct et LLaMA2-70B Chat, ainsi qu'avec la version actuelle de GPT-3.5 Turbo.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tableau 4. Performances des modèles mesurées lorsque chaque modèle reçoit les 10 passages principaux récupérés d'un corpus Wikipedia à l'aide de bge-large-en-v1.5. La précision est mesurée en comparant la réponse du modèle. Le gras indique le score le plus élevé. Le souligné indique le score le plus élevé autre que GPT-4 Turbo.
Efficacité de l'entraînement
La qualité du modèle doit être mise en contexte de l'efficacité de son entraînement et de son utilisation. C'est particulièrement vrai chez Databricks, où nous créons des modèles comme DBRX pour établir un processus permettant à nos clients d'entraîner leurs propres modèles fondamentaux.
Nous avons constaté que l'entraînement des modèles mixture-of-experts offre des améliorations substantielles en termes d'efficacité de calcul pour l'entraînement (Tableau 5). Par exemple, l'entraînement d'un membre plus petit de la famille DBRX, appelé DBRX MoE-B (23,5 milliards de paramètres totaux, 6,6 milliards de paramètres actifs), a nécessité 1,7 fois moins de FLOPs pour atteindre un score de 45,5 % sur le Databricks LLM Gauntlet que ce que LLaMA2-13B a nécessité pour atteindre 43,8 %. DBRX MoE-B contient également deux fois moins de paramètres actifs que LLaMA2-13B.
Dans l'ensemble, notre pipeline de pré-entraînement LLM de bout en bout est devenu près de 4 fois plus efficace en termes de calcul au cours des dix derniers mois. Le 5 mai 2023, nous avons publié MPT-7B, un modèle de 7 milliards de paramètres entraîné sur 1T tokens qui a atteint un score de 30,9 % sur le Databricks LLM Gauntlet. Un membre de la famille DBRX appelé DBRX MoE-A (7,7 milliards de paramètres totaux, 2,2 milliards de paramètres actifs) a atteint un score de 30,5 % sur le Databricks Gauntlet avec 3,7 fois moins de FLOPs. Cette efficacité est le résultat d'un certain nombre d'améliorations, notamment l'utilisation d'une architecture MoE, d'autres modifications architecturales du réseau, de meilleures stratégies d'optimisation, une meilleure tokenisation et, très important, de meilleures données de pré-entraînement.
Isolément, de meilleures données de pré-entraînement ont eu un impact substantiel sur la qualité du modèle. Nous avons entraîné un modèle de 7 milliards de paramètres (appelé DBRX Dense-A) sur 1 billion de tokens en utilisant les données de pré-entraînement DBRX. Il a atteint 39,0 % sur le Databricks Gauntlet contre 30,9 % pour MPT-7B. Nous estimons que nos nouvelles données de pré-entraînement sont au moins 2 fois meilleures par token que les données utilisées pour entraîner MPT-7B. En d'autres termes, nous estimons que la moitié de tokens sont nécessaires pour atteindre la même qualité de modèle. Nous avons déterminé cela en entraînant DBRX Dense-A sur 500 milliards de tokens ; il a surpassé MPT-7B sur le Databricks Gauntlet, atteignant 32,1 %. En plus de la meilleure qualité des données, un autre contributeur important à cette efficacité en tokens pourrait être le tokenizer GPT-4, qui possède un vocabulaire large et est considéré comme particulièrement efficace en tokens. Ces leçons sur l'amélioration de la qualité des données se traduisent directement par des pratiques et des outils que nos clients utilisent pour entraîner des modèles fondamentaux sur leurs propres données.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 5. Détails de plusieurs articles de test que nous avons utilisés pour valider l'efficacité de l'entraînement de l'architecture DBRX MoE et du pipeline d'entraînement de bout en bout
Efficacité de l'inférence
La Figure 2 montre l'efficacité de l'inférence de bout en bout pour servir DBRX et des modèles similaires à l'aide de NVIDIA TensorRT-LLM avec notre infrastructure de service optimisée et une précision de 16 bits. Nous visons à ce que ce benchmark reflète l'utilisation réelle aussi fidèlement que possible, y compris plusieurs utilisateurs frappant simultanément le même serveur d'inférence. Nous générons un nouvel utilisateur par seconde, chaque requête utilisateur contient une invite d'environ 2000 jetons, et chaque réponse comprend 256 jetons.
En général, les modèles MoE sont plus rapides à l'inférence que ce que leur nombre total de paramètres suggérerait. Cela est dû au fait qu'ils utilisent relativement peu de paramètres pour chaque entrée. Nous constatons que DBRX ne fait pas exception à cet égard. Le débit d'inférence de DBRX est 2 à 3 fois supérieur à celui d'un modèle non-MoE de 132 milliards de paramètres.
L'efficacité de l'inférence et la qualité du modèle sont généralement en tension : les modèles plus grands atteignent généralement une meilleure qualité, mais les modèles plus petits sont plus efficaces pour l'inférence. L'utilisation d'une architecture MoE permet d'obtenir de meilleurs compromis entre la qualité du modèle et l'efficacité de l'inférence que ce que les modèles denses atteignent généralement. Par exemple, DBRX est de meilleure qualité que LLaMA2-70B et - grâce à environ la moitié de paramètres actifs - le débit d'inférence de DBRX est jusqu'à 2 fois plus rapide (Figure 2). Mixtral est un autre point sur la frontière de Pareto améliorée atteinte par les modèles MoE : il est plus petit que DBRX, et il est donc inférieur en termes de qualité mais atteint un débit d'inférence plus élevé. Les utilisateurs des API Databricks Foundation Model peuvent s'attendre à voir jusqu'à 150 jetons par seconde pour DBRX sur notre plateforme de service de modèles optimisée avec une quantification de 8 bits.

Comment nous avons construit DBRX
DBRX a été entraîné sur 3072 NVIDIA H100 connectés par 3.2Tbps Infiniband. Le processus principal de construction de DBRX - y compris le pré-entraînement, le post-entraînement, l'évaluation, le red-teaming et le raffinement - s'est déroulé sur trois mois. Il a fait suite à des mois de recherche scientifique, de recherche sur les jeux de données et d'expériences de mise à l'échelle, sans oublier des années de développement LLM chez Databricks qui incluent les projets MPT et Dolly et les milliers de modèles que nous avons construits et mis en production avec nos clients.
Pour construire DBRX, nous avons utilisé la même suite d'outils Databricks qui est disponible pour nos clients. Nous avons géré et gouverné nos données d'entraînement à l'aide d'Unity Catalog. Nous avons exploré ces données à l'aide du tout nouveau Lilac AI. Nous avons traité et nettoyé ces données à l'aide d'Apache Spark™ et de notebooks Databricks. Nous avons entraîné DBRX à l'aide de versions optimisées de nos bibliothèques d'entraînement open-source : MegaBlocks, LLM Foundry, Composer, et Streaming. Nous avons géré l'entraînement et le réglage fin des modèles à grande échelle sur des milliers de GPU à l'aide de notre service Databricks Training. Nous avons enregistré nos résultats à l'aide de MLflow. Nous avons collecté des retours humains pour des améliorations de qualité et de sécurité via Databricks Model Serving et Inference Tables. Nous avons expérimenté manuellement le modèle à l'aide du Databricks Playground. Nous avons trouvé que les outils Databricks étaient de premier ordre pour chacun de leurs objectifs, et nous avons bénéficié du fait qu'ils faisaient tous partie d'une expérience produit unifiée.
Commencer avec DBRX sur Databricks
Si vous cherchez à commencer à travailler avec DBRX immédiatement, c'est facile avec les API Databricks Foundation Model APIs. Vous pouvez rapidement commencer avec notre tarification à l'utilisation et interroger le modèle depuis notre interface de chat AI Playground. Pour les applications de production, nous proposons une option de débit provisionné pour fournir des garanties de performance, un support pour les modèles affinés, ainsi qu'une sécurité et une conformité supplémentaires. Pour héberger DBRX en privé, vous pouvez télécharger le modèle depuis le Databricks Marketplace et déployer le modèle sur Model Serving.
Conclusions
Chez Databricks, nous pensons que chaque entreprise devrait avoir la capacité de contrôler ses données et son destin dans le monde émergent de la GenAI. DBRX est un pilier central de notre prochaine génération de produits GenAI, et nous attendons avec impatience le voyage passionnant qui attend nos clients alors qu'ils exploitent les capacités de DBRX et les outils que nous avons utilisés pour le construire. Au cours de la dernière année, nous avons entraîné des milliers de LLM avec nos clients. DBRX n'est qu'un exemple des modèles puissants et efficaces construits chez Databricks pour un large éventail d'applications, des fonctionnalités internes aux cas d'utilisation ambitieux pour nos clients.
Comme pour tout nouveau modèle, le voyage avec DBRX ne fait que commencer, et le meilleur travail sera fait par ceux qui construiront dessus : les entreprises et la communauté ouverte. Ce n'est également que le début de notre travail sur DBRX, et vous devriez vous attendre à beaucoup plus à venir.
Contributions
Le développement de DBRX a été mené par l'équipe Mosaic qui a précédemment construit la famille de modèles MPT, en collaboration avec des dizaines d'ingénieurs, juristes, spécialistes des achats et de la finance, chefs de projet, marketeurs, designers et autres contributeurs de Databricks. Nous sommes reconnaissants envers nos collègues, amis, famille et la communauté pour leur patience et leur soutien au cours des derniers mois.
En créant DBRX, nous nous appuyons sur les géants de la communauté ouverte et académique. En rendant DBRX disponible ouvertement, nous avons l'intention de réinvestir dans la communauté dans l'espoir de construire ensemble une technologie encore plus performante à l'avenir. Dans cette optique, nous reconnaissons avec gratitude le travail et la collaboration de Trevor Gale et de son projet MegaBlocks (le directeur de thèse de Trevor est le CTO de Databricks, Matei Zaharia), l'équipe PyTorch et le projet FSDP,� NVIDIA et le projet TensorRT-LLM, l'équipe et le projet vLLM, EleutherAI et leur projet d'évaluation des LLM LLM evaluation, Daniel Smilkov et Nikhil Thorat chez Lilac AI, et nos amis de l'Allen Institute for Artificial Intelligence (AI2).
À propos de Databricks
Databricks est la société de données et d'IA. Plus de 10 000 organisations dans le monde — y compris Comcast, Condé Nast, Grammarly, et plus de 50 % des entreprises du Fortune 500 — s'appuient sur la plateforme d'intelligence de données Databricks pour unifier et démocratiser les données, l'analytique et l'IA. Databricks a son siège à San Francisco, avec des bureaux dans le monde entier, et a été fondée par les créateurs originaux de Lakehouse, Apache Spark™, Delta Lake et MLflow. Pour en savoir plus, suivez Databricks sur LinkedIn, X, et Facebook.
1 Chiffres rapportés par xAI. En raison d'un manque de checkpoint compatible Hugging Face au moment de la publication, nous n'avons pas pu évaluer Grok-1 nous-mêmes sur notre suite complète de benchmarks.
2 DBRX a été mesuré par nous en utilisant l'EleutherAI Harness. Tous les autres chiffres ont été rapportés sur le classement Hugging Face Open LLM Leaderboard.
3 DBRX a été mesuré par nous en utilisant l'EleutherAI Harness avec le même ancien commit qui est utilisé par le classement Hugging Face Open LLM Leaderboard. Tous les autres chiffres ont été rapportés sur le classement Hugging Face Open LLM Leaderboard. Notez qu'en utilisant le dernier commit de l'EleutherAI Harness, qui inclut plusieurs corrections d'analyse, le score 5-shot de DBRX sur GSM8k monte à 72,8 % comme indiqué dans le tableau 2. LLaMA2-70B Chat monte également à 48,4 %.
4 Mesuré par Databricks en utilisant Gauntlet v0.3.0 dans LLM Foundry.
5 Sauf indication contraire, mesuré par Databricks.
6 Ce chiffre provient du papier Arxiv de Mixtral. Nous rapportons ce chiffre car il est supérieur à ce que nous avons mesuré lors de l'évaluation du modèle nous-mêmes (36,7 %)
7 Tous les scores tels que rapportés dans le papier GPT-4. Nous n'avons pas pu collecter Inflection Corrected MTBench car cette version de GPT-3.5 n'est pas disponible. Nous avons constaté que la version actuelle de GPT-3.5 Turbo obtient un score de 8,58 ± 0,04 sur Inflection Corrected MTBench par rapport à 8,39 +/- 0,08 pour DBRX Instruct.
8 Tous les scores tels que rapportés dans le papier GPT-4. Nous n'avons pas pu collecter Inflection Corrected MTBench car cette version de GPT-4 n'est pas disponible. Nous avons constaté que la version actuelle de GPT-4 Turbo obtient un score de 9,27 ± 0,10 sur Inflection Corrected MTBench par rapport à 8,39 +/- 0,08 pour DBRX Instruct.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.