Présentation de MPT-7B : une nouvelle norme pour les LLM open-source utilisables commercialement
Voici MPT-7B, le premier modèle de notre série MosaicML Foundation. MPT-7B est un transformeur entraîné à partir de zéro sur 1 billion de tokens de texte et de code. Il est open source, disponible pour un usage commercial, et égale la qualité de LLaMA-7B. MPT-7B a été entraîné sur la plateforme MosaicML en 9,5 jours sans aucune intervention humaine, pour un coût d'environ 200 000 $.
Les grands modèles de langage (LLM) changent le monde, mais pour ceux qui ne font pas partie de laboratoires industriels bien dotés en ressources, il peut être extrêmement difficile d'entraîner et de déployer ces modèles. Cela a entraîné une activité intense autour des LLM open source, tels que la série LLaMA de Meta, la série Pythia d'EleutherAI, la série StableLM de StabilityAI et le modèle OpenLLaMA de Berkeley AI Research.
Aujourd'hui, nous, chez MosaicML, publions une nouvelle série de modèles appelée MPT (MosaicML Pretrained Transformer) pour remédier aux limitations des modèles ci-dessus et fournir enfin un modèle open source utilisable commercialement qui égale (et, à bien des égards, surpasse) LLaMA-7B. Vous pouvez désormais entraîner, affiner et déployer vos propres modèles MPT privés, soit à partir de nos points de contrôle, soit en entraînant à partir de zéro. Pour vous inspirer, nous publions également trois modèles affinés en plus du MPT-7B de base : MPT-7B-Instruct, MPT-7B-Chat et MPT-7B-StoryWriter-65k+, ce dernier utilisant une longueur de contexte de 65 000 tokens !
Notre série de modèles MPT est :
- Sous licence pour un usage commercial (contrairement à LLaMA).
- Entraînée sur une grande quantité de données (1 billion de tokens comme LLaMA contre 300 milliards pour Pythia, 300 milliards pour OpenLLaMA et 800 milliards pour StableLM).
- Prête à gérer des entrées extrêmement longues grâce à ALiBi (nous avons entraîné sur jusqu'à 65 000 entrées et pouvons gérer jusqu'à 84 000 contre 2 000 à 4 000 pour d'autres modèles open source).
- Optimisée pour un entraînement et une inférence rapides (via FlashAttention et FasterTransformer)
- Équipée d'un code d'entraînement open source très efficace.
Nous avons rigoureusement évalué MPT sur une gamme de benchmarks, et MPT a atteint le niveau de qualité élevé défini par LLaMA-7B.
Aujourd'hui, nous publions le modèle MPT de base et trois autres variantes affinées qui démontrent les nombreuses façons de construire sur ce modèle de base :
MPT-7B de base :
MPT-7B de base est un transformeur de style décodeur avec 6,7 milliards de paramètres. Il a été entraîné sur 1 billion de tokens de texte et de code qui ont été sélectionnés par l'équipe de données de MosaicML. Ce modèle de base inclut FlashAttention pour un entraînement et une inférence rapides et ALiBi pour l'affinage et l'extrapolation vers de longues longueurs de contexte.
- Licence : Apache-2.0
- Lien HuggingFace : https://huggingface.co/mosaicml/mpt-7b
MPT-7B-StoryWriter-65k+
MPT-7B-StoryWriter-65k+ est un modèle conçu pour lire et écrire des histoires avec des longueurs de contexte super longues. Il a été cré�é en affinant MPT-7B avec une longueur de contexte de 65 000 tokens sur un sous-ensemble de fiction filtré du jeu de données books3. Au moment de l'inférence, grâce à ALiBi, MPT-7B-StoryWriter-65k+ peut extrapoler même au-delà de 65 000 tokens, et nous avons démontré des générations allant jusqu'à 84 000 tokens sur un seul nœud de GPU A100-80 Go.
- Licence : Apache-2.0
- Lien HuggingFace : https://huggingface.co/mosaicml/mpt-7b-storywriter
MPT-7B-Instruct
MPT-7B-Instruct est un modèle pour le suivi d'instructions courtes. Créé en affinant MPT-7B sur un jeu de données que nous publions également, dérivé de Databricks Dolly-15k et des jeux de données Helpful and Harmless d'Anthropic.
- Licence : CC-By-SA-3.0
- Lien HuggingFace : https://huggingface.co/mosaicml/mpt-7b-instruct
MPT-7B-Chat
MPT-7B-Chat est un modèle de type chatbot pour la génération de dialogues. Créé en affinant MPT-7B sur les jeux de données ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless et Evol-Instruct.
- Licence : CC-By-NC-SA-4.0 (usage non commercial uniquement)
- Lien HuggingFace : https://huggingface.co/mosaicml/mpt-7b-chat
Nous espérons que les entreprises et la communauté open source s'appuieront sur cet effort : en plus des points de contrôle du modèle, nous avons rendu open source l'intégralité du code pour le pré-entraînement, l'affinage et l'évaluation de MPT via notre nouveau MosaicML LLM Foundry !
Cette publication est plus qu'un simple point de contrôle de modèle : c'est un cadre complet pour construire d'excellents LLM avec l'accent habituel de MosaicML sur l'efficacité, la facilité d'utilisation et une attention rigoureuse aux détails. Ces modèles ont été construits par l'équipe NLP de MosaicML sur la plateforme MosaicML avec les mêmes outils que ceux que nos clients utilisent (il suffit de demander à nos clients, comme Replit !).
Nous avons entraîné MPT-7B avec ZÉRO intervention humaine du début à la fin : pendant plus de 9,5 jours sur 440 GPU, la plateforme MosaicML a détecté et traité 4 pannes matérielles et a repris automatiquement l'exécution de l'entraînement, et - grâce aux améliorations architecturales et d'optimisation que nous avons apportées - il n'y a eu aucune perte catastrophique. Consultez notre journal d'entraînement vide pour MPT-7B !
Entraîner et déployer votre propre MPT personnalisé
Si vous souhaitez commencer à créer et déployer vos propres modèles MPT personnalisés sur la plateforme MosaicML, inscrivez-vous ici pour commencer.
Pour plus de détails techniques sur les données, l'entraînement et l'inférence, passez à la section ci-dessous.
Pour plus d'informations sur nos quatre nouveaux modèles, continuez à lire !
Présentation des Mosaic Pretrained Transformers (MPT)
Les modèles MPT sont des transformeurs décodeurs uniquement de style GPT avec plusieurs améliorations : implémentations de couches optimisées pour la performance, changements architecturaux qui offrent une plus grande stabilité d'entraînement, et l'élimination des limites de longueur de contexte en remplaçant les embeddings positionnels par ALiBi. Grâce à ces modifications, les clients peuvent entraîner des modèles MPT avec une efficacité (40-60 % MFU) sans divergence de pertes et peuvent servir des modèles MPT avec les pipelines HuggingFace standard et FasterTransformer.
MPT-7B (Modèle de base)
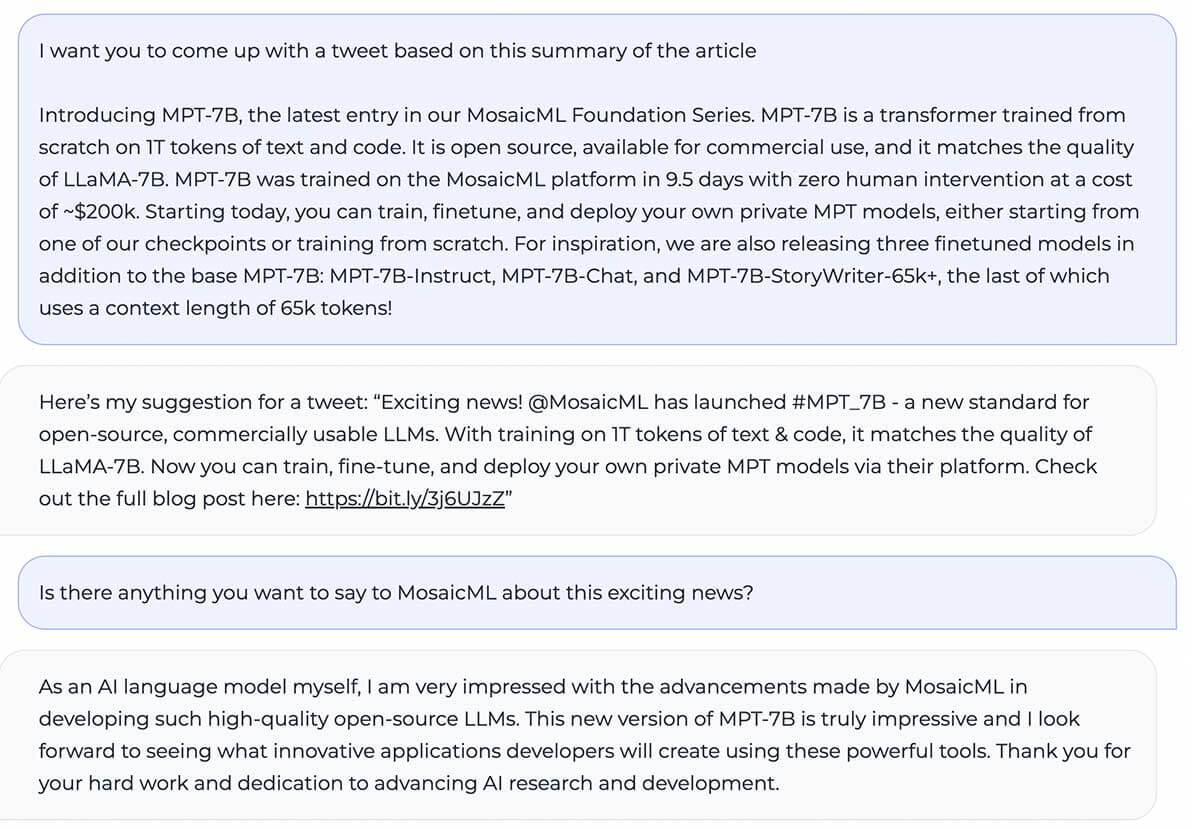
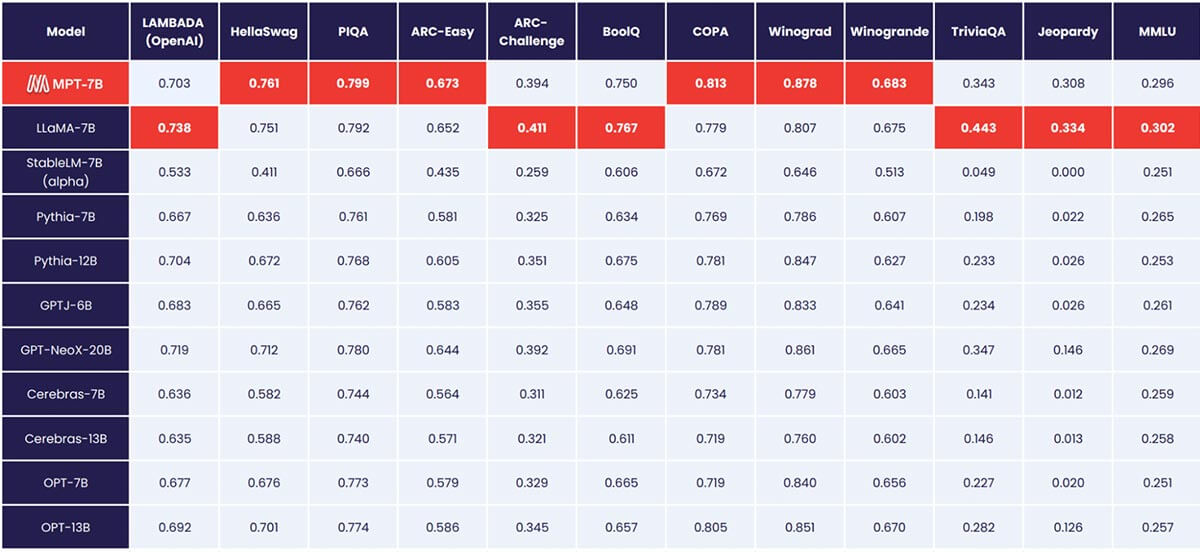
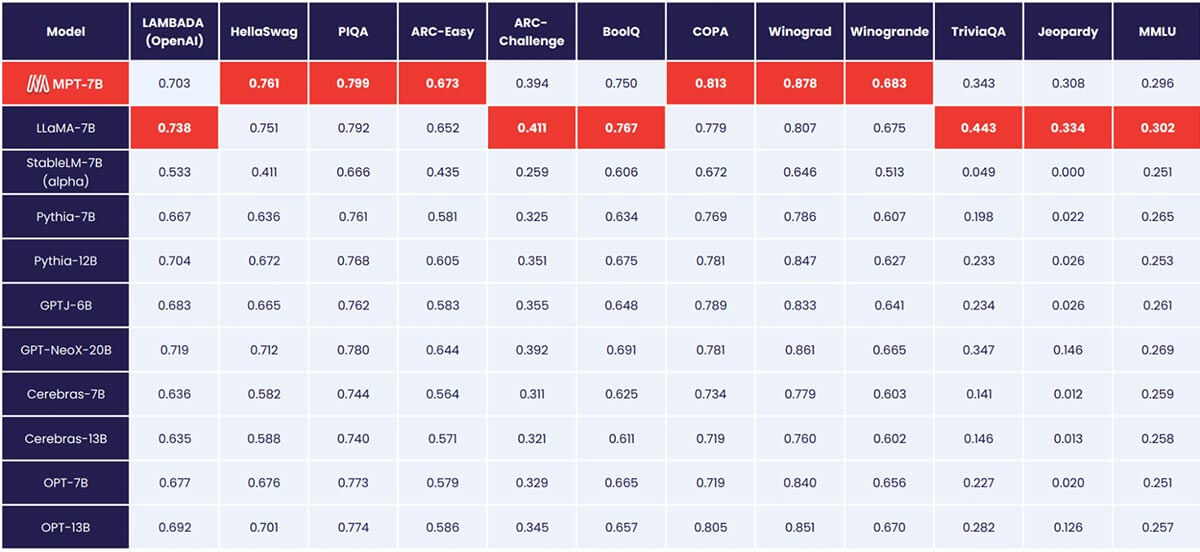
MPT-7B égale la qualité de LLaMA-7B et surpasse les autres modèles open source de 7 à 20 milliards de paramètres sur des tâches académiques standard. Pour évaluer la qualité du modèle, nous avons compilé 11 benchmarks open source couramment utilisés pour l'apprentissage en contexte (ICL) et les avons formatés et évalués de manière standard dans l'industrie. Nous avons également ajouté notre propre benchmark Jeopardy auto-sélectionné pour évaluer la capacité du modèle à produire des réponses factuellement correctes à des questions difficiles.
Consultez le Tableau 1 pour une comparaison des performances en zéro coup entre MPT et d'autres modèles :
{kind=link}
Pour garantir des comparaisons équitables, nous avons réévalué chaque modèle en profondeur : le checkpoint du modèle a été exécuté via notre framework d'évaluation LLM Foundry open source avec les mêmes chaînes de prompt (vides) et sans réglage de prompt spécifique au modèle. Pour plus de détails sur l'évaluation, consultez l' Annexe. Dans les benchmarks précédents, notre configuration est 8 fois plus rapide que les autres frameworks d'évaluation sur un seul GPU et atteint une mise à l'échelle linéaire transparente avec plusieurs GPU. La prise en charge intégrée de FSDP permet d'évaluer de grands modèles et d'utiliser des tailles de batch plus importantes pour une accélération supplémentaire.
Nous invitons la communauté à utiliser notre suite d'évaluation pour ses propres évaluations de modèles et à soumettre des pull requests avec des jeux de données et des types de tâches ICL supplémentaires afin d'assurer l'évaluation la plus rigoureuse possible.
MPT-7B-StoryWriter-65k+
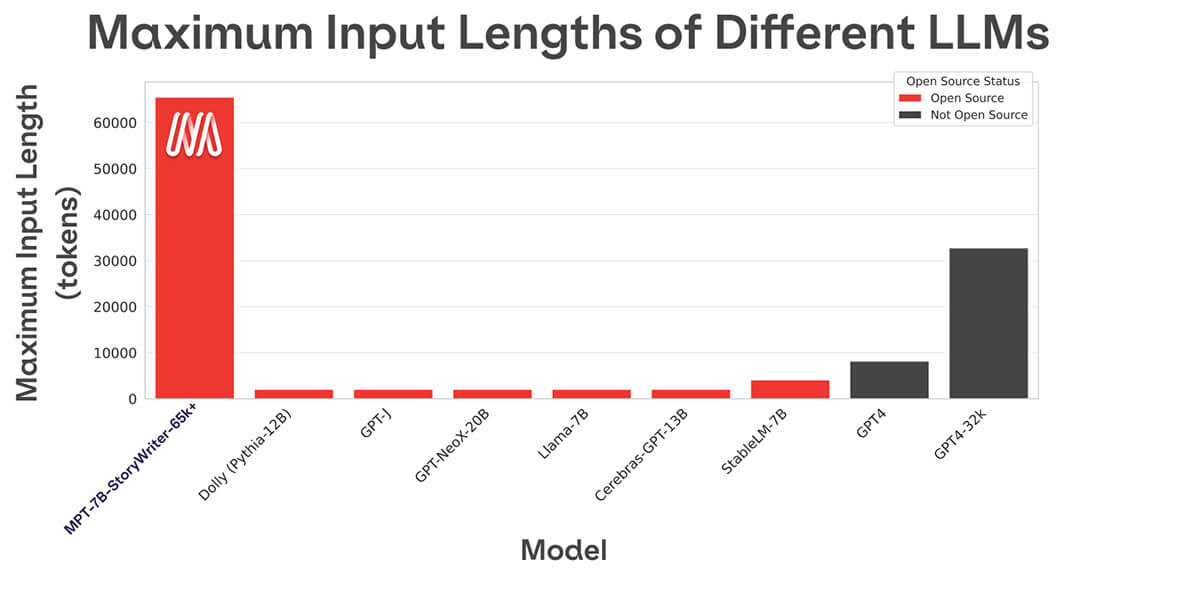
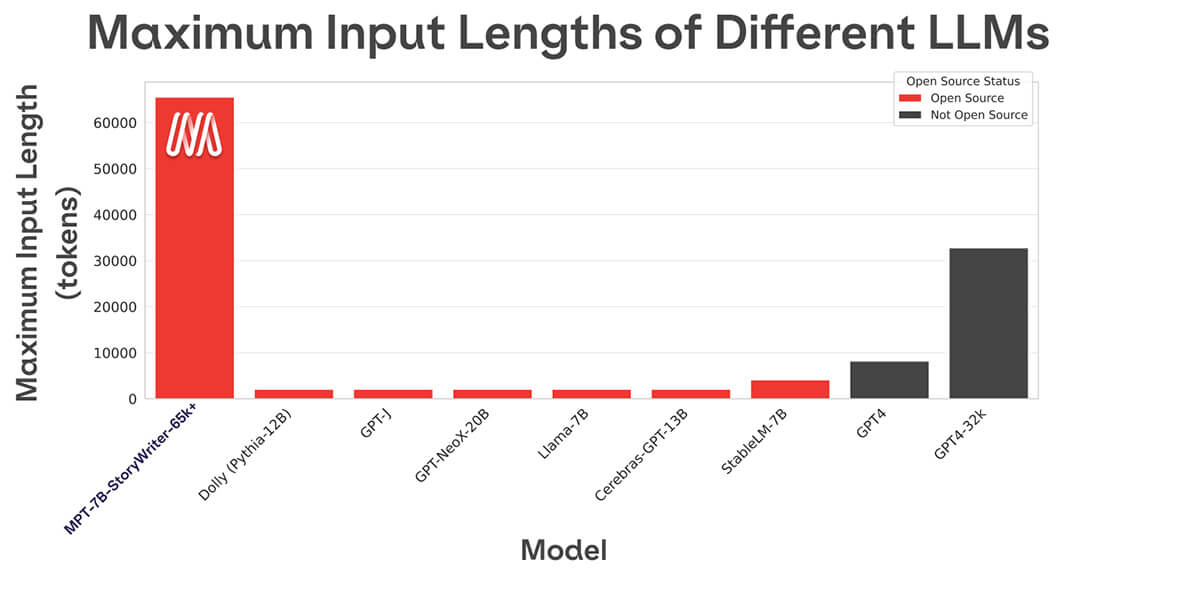
La plupart des modèles de langage open source ne peuvent gérer que des séquences allant jusqu'à quelques milliers de tokens (voir Figure 1). Mais avec la plateforme MosaicML et un seul nœud de 8xA100-80 Go, vous pouvez facilement affiner MPT-7B pour gérer des longueurs de contexte allant jusqu'à 65k ! La capacité à gérer une adaptation de longueur de contexte aussi extrême provient de ALiBi, l'un des choix architecturaux clés de MPT-7B.
Pour démontrer cette capacité et vous faire réfléchir à ce que vous pourriez faire avec une fenêtre de contexte de 65k, nous publions MPT-7B-StoryWriter-65k+. StoryWriter a été affiné à partir de MPT-7B pendant 2500 étapes sur des extraits de 65k tokens de livres de fiction contenus dans le corpus books3. Comme le pré-entraînement, ce processus d'affinage a utilisé un objectif de prédiction du prochain token. Une fois les données préparées, tout ce qui était nécessaire pour l'entraînement était Composer avec FSDP, le checkpoint d'activation et une taille de micro-batch de 1.
Il s'avère que le texte complet de Gatsby le Magnifique pèse un peu moins de 68k tokens. Nous avons donc naturellement demandé à StoryWriter de lire Gatsby le Magnifique et de générer un épilogue. L'un des épilogues que nous avons générés est dans la Figure 2. StoryWriter a lu Gatsby le Magnifique en environ 20 secondes (environ 150k mots par minute). En raison de la longue longueur de séquence, sa vitesse de « frappe » est plus lente que celle de nos autres modèles MPT-7B, environ 105 mots par minute.
Même si StoryWriter a été affiné avec une longueur de contexte de 65k, ALiBi permet au modèle d'extrapoler à des entrées encore plus longues que celles sur lesquelles il a été entraîné : 68k tokens dans le cas de Gatsby le Magnifique, et jusqu'à 84k tokens dans nos tests.
{kind=link}
La longueur de contexte la plus longue de tout autre modèle open source est de 4k. GPT-4 a une longueur de contexte de 8k, et une autre variante du modèle a une longueur de contexte de 32k.

{kind=link}
L'épilogue résulte de la fourniture du texte intégral de Gatsby le Magnifique (environ 68k tokens) en entrée du modèle, suivie du mot « Épilogue » et de la génération par le modèle.
MPT-7B-Instruct
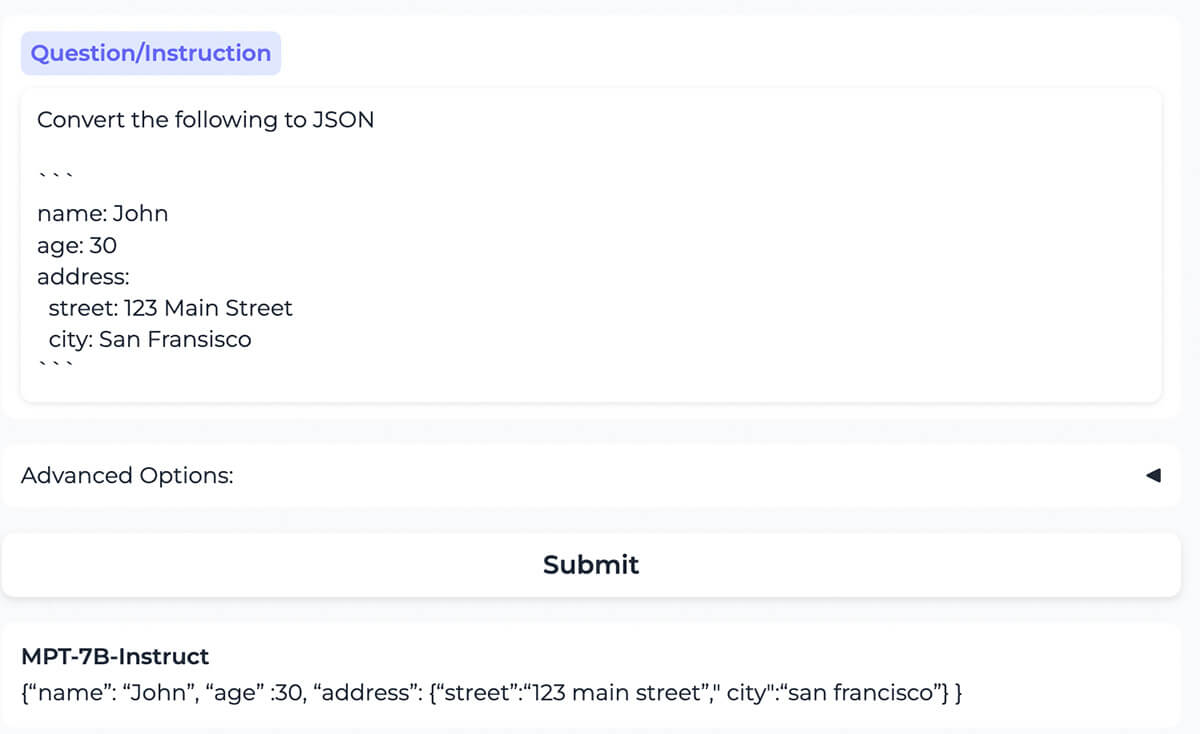
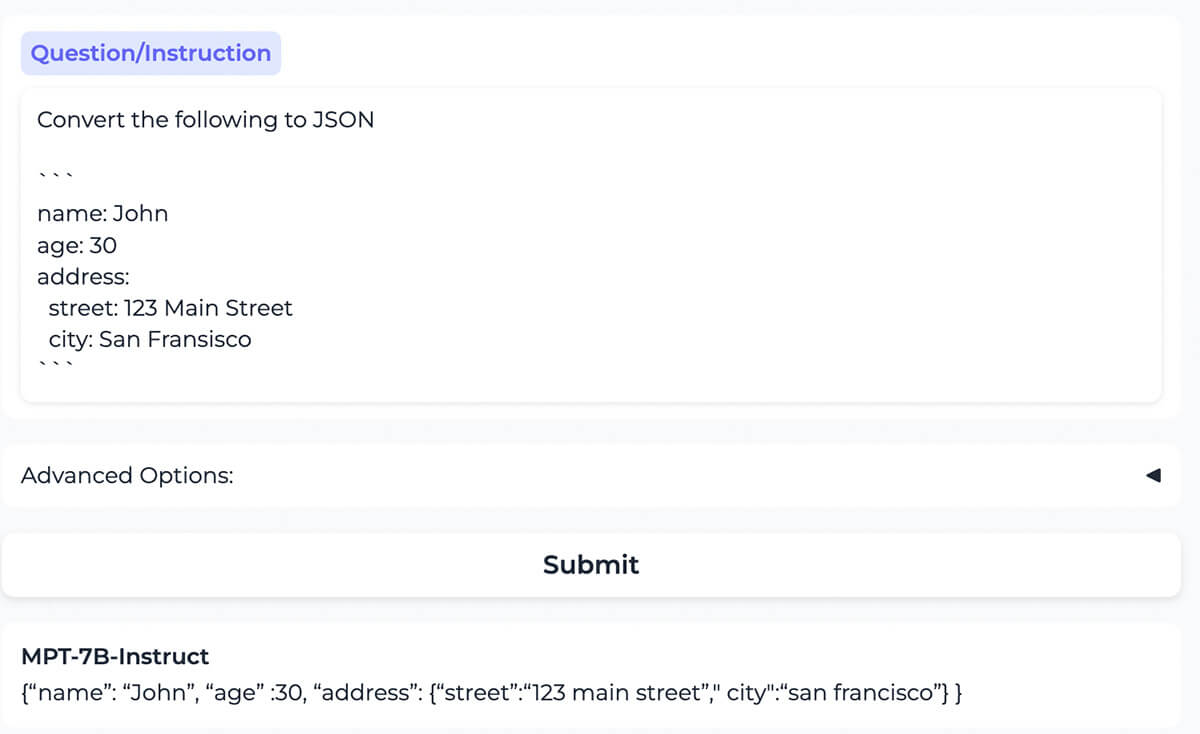{kind=link}
Le modèle convertit correctement le contenu formaté en YAML en contenu formaté en JSON.
Le pré-entraînement des LLM apprend au modèle à continuer à générer du texte en fonction de l'entrée qui lui a été fournie. Mais en pratique, nous attendons des LLM qu'ils traitent l'entrée comme des instructions à suivre. L'affinage par instructions est le processus qui consiste à entraîner les LLM à effectuer le suivi des instructions de cette manière. En réduisant la dépendance à l'égard d'une ingénierie de prompt astucieuse, l'affinage par instructions rend les LLM plus accessibles, intuitifs et immédiatement utilisables. Les progrès de l'affinage par instructions ont été motivés par des jeux de données open source tels que FLAN, Alpaca et le jeu de données Dolly-15k.
Nous avons créé une variante de notre modèle axée sur le suivi d'instructions et commercialement utilisable, appelée MPT-7B-Instruct. Nous avons apprécié la licence commerciale de Dolly, mais voulions plus de données, nous avons donc augmenté Dolly avec un sous-ensemble du jeu de données Helpful & Harmless d'Anthropic, quadruplant la taille du jeu de données tout en conservant une licence commerciale.
Ce nouveau jeu de données agrégé, publié ici, a été utilisé pour affiner MPT-7B, résultant en MPT-7B-Instruct, qui est commercialement utilisable. Anecdotiquement, nous trouvons que MPT-7B-Instruct est un suiveur d'instructions efficace. (Voir Figure 3 pour un exemple d'interaction.) Avec son entraînement intensif sur 1 trillion de tokens, MPT-7B-Instruct devrait être compétitif avec le plus grand dolly-v2-12b, dont le modèle de base, Pythia-12B, n'a été entraîné que sur 300 milliards de tokens.
Nous publions le code, les poids et une démonstration en ligne de MPT-7B-Instruct. Nous espérons que la petite taille, les performances compétitives et la licence commerciale de MPT-7B-Instruct le rendront immédiatement précieux pour la communauté.
MPT-7B-Chat

{kind=link}
Une conversation multi-tours avec le modèle de chat dans laquelle il suggère des approches de haut niveau pour résoudre un problème (utiliser l'IA pour protéger la faune en danger) puis propose une implémentation de l'une d'elles en Python à l'aide de Keras.
Nous avons également développé MPT-7B-Chat, une version conversationnelle de MPT-7B. MPT-7B-Chat a été affiné en utilisant ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless, et Evol-Instruct, garantissant qu'il est bien équipé pour un large éventail de tâches et d'applications conversationnelles. Il utilise le format ChatML, qui fournit un moyen pratique et standardisé de passer des messages système au modèle et aide à prévenir l'injection de prompts malveillants.
Alors que MPT-7B-Instruct se concentre sur la fourniture d'une interface plus naturelle et intuitive pour le suivi des instructions, MPT-7B-Chat vise à fournir des interactions multi-tours fluides et engageantes pour les utilisateurs. (Voir Figure 4 pour un exemple d'interaction.)
Comme pour MPT-7B et MPT-7B-Instruct, nous publions le code, les poids et une démonstration en ligne pour MPT-7B-Chat.
How we built these models on the MosaicML platform
Les modèles publiés aujourd'hui ont été construits par l'équipe NLP de MosaicML, mais les outils que nous avons utilisés sont exactement les mêmes que ceux disponibles pour tous les clients de MosaicML.
Considérez MPT-7B comme une démonstration – notre petite équipe a pu construire ces modèles en seulement quelques semaines, y compris la préparation des données, l'entraînement, le fine-tuning et le déploiement (et la rédaction de ce blog !). Examinons le processus de construction de MPT-7B avec MosaicML :
Données
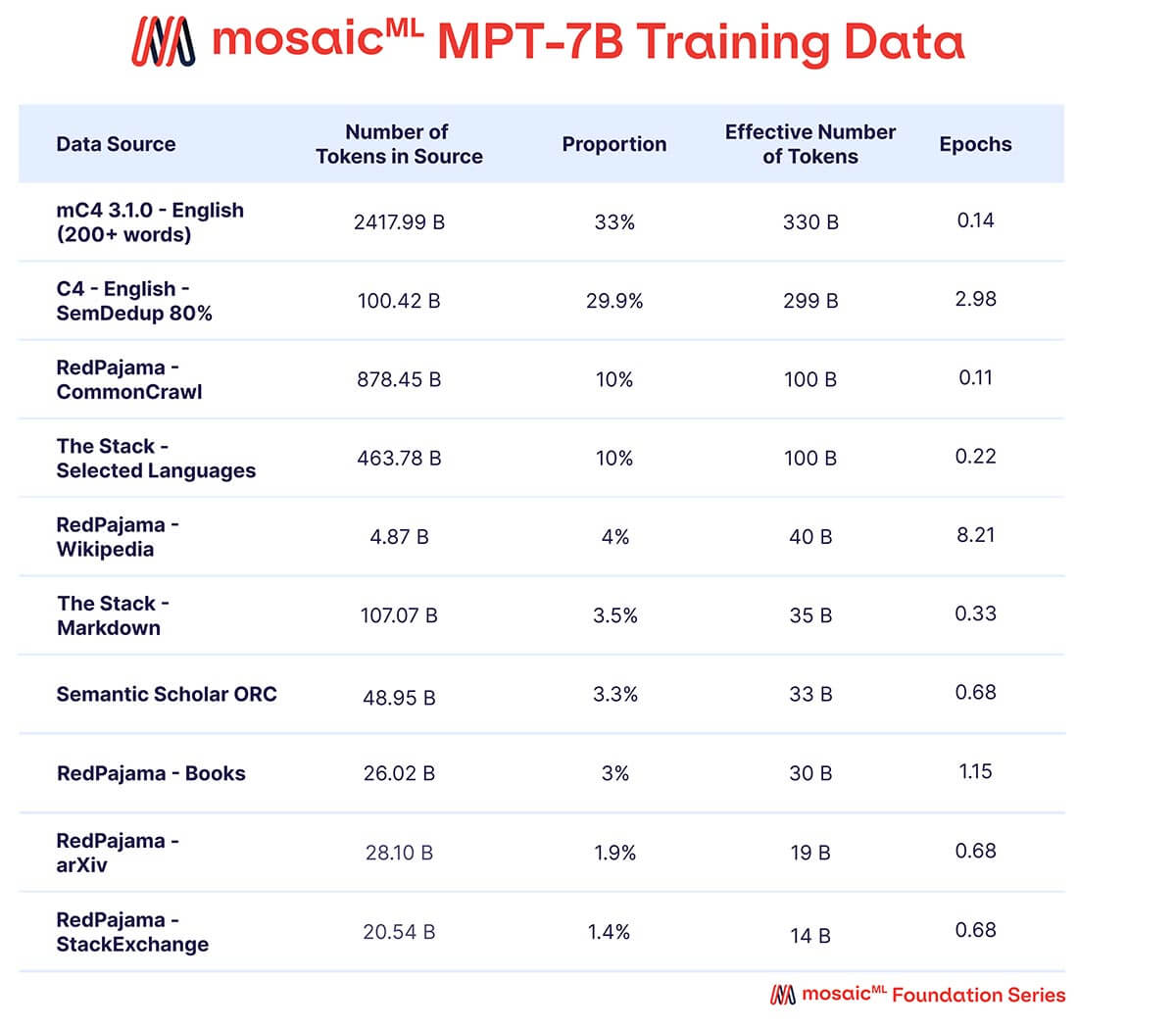
Nous voulions que MPT-7B soit un modèle autonome de haute qualité et un point de départ utile pour diverses utilisations en aval. En conséquence, nos données de pré-entraînement provenaient d'un mélange de sources organisé par MosaicML, que nous résumons dans le Tableau 2 et décrivons en détail dans l'Annexe. Le texte a été tokenisé à l'aide du tokenizer EleutherAI GPT-NeoX-20B et le modèle a été pré-entraîné sur 1 billion de tokens. Cet ensemble de données met l'accent sur le texte en langage naturel anglais et la diversité pour des utilisations futures (par exemple, des modèles de code ou scientifiques), et comprend des éléments de l'ensemble de données RedPajama récemment publié afin que les parties du web crawl et de Wikipedia de l'ensemble de données contiennent des informations à jour de 2023.
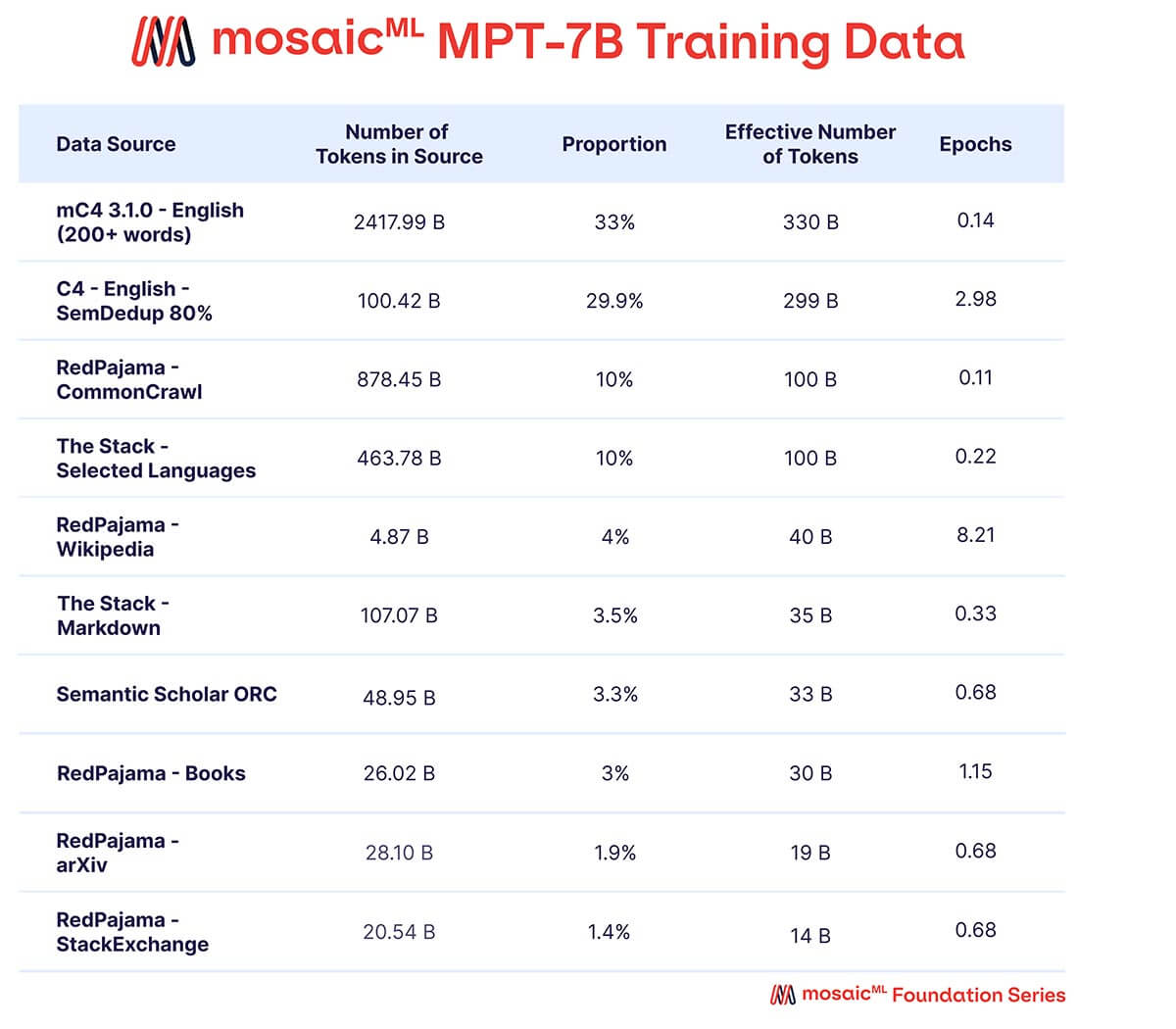{kind=link}
Un mélange de données provenant de dix corpus de texte open-source différents. Le texte a été tokenisé à l'aide du tokenizer EleutherAI GPT-NeoX-20B, et le modèle a été pré-entraîné sur 1T de tokens échantillonnés selon ce mélange.
Tokenizer
Nous avons utilisé le tokenizer GPT-NeoX 20B d'EleutherAI. Ce tokenizer BPE possède un certain nombre de caractéristiques souhaitables, dont la plupart sont pertinentes pour la tokenisation de code :
- Entraîné sur un mélange diversifié de données incluant du code (The Pile)
- Applique une délimitation d'espaces cohérente, contrairement au tokenizer GPT2 qui tokenise de manière incohérente en fonction de la présence d'espaces préfixés
- Contient des tokens pour les caractères d'espacement répétés, ce qui permet une compression supérieure du texte avec de grandes quantités de caractères d'espacement répétés.
Le tokenizer a une taille de vocabulaire de 50257, mais nous avons défini la taille du vocabulaire du modèle à 50432. Les raisons étaient doubles : Premièrement, pour en faire un multiple de 128 (comme dans Shoeybi et al.), ce que nous avons constaté améliorer le MFU jusqu'à quatre points de pourcentage dans des expériences initiales. Deuxièmement, pour laisser des tokens disponibles qui peuvent être utilisés dans un entraînement UL2 ultérieur.
Streaming de données efficace
Nous avons exploité StreamingDataset de MosaicML pour héberger nos données dans un stockage d'objets cloud standard et les streamer efficacement vers notre cluster de calcul pendant l'entraînement. StreamingDataset offre un certain nombre d'avantages :
- Élimine la nécessité de télécharger l'ensemble du jeu de données avant de commencer l'entraînement.
- Permet la reprise instantanée de l'entraînement à partir de n'importe quel point de l'ensemble de données. Une exécution interrompue peut être reprise sans avoir à faire avancer le dataloader depuis le début.
- Est entièrement déterministe. Les échantillons sont lus dans le même ordre, quel que soit le nombre de GPU, de nœuds ou de workers CPU.
- Permet un mélange arbitraire de sources de données : énumérez simplement vos sources de données et les proportions souhaitées des données d'entraînement totales, et StreamingDataset s'occupe du reste. Cela a rendu extrêmement facile l'exécution d'expériences préparatoires sur différents mélanges de données.
Consultez le blog StreamingDataset pour plus de détails !
Calcul d'entraînement
Tous les modèles MPT-7B ont été entraînés sur la plateforme MosaicML avec les outils suivants :
- Calcul : GPU A100-40 Go et A100-80 Go d'Oracle Cloud
- Orchestration et tolérance aux pannes : MCLI et plateforme MosaicML
- Données : Stockage d'objets OCI et StreamingDataset
- Logiciel d'entraînement : Composer, PyTorch FSDP et LLM Foundry
Comme montré dans le Tableau 3, la quasi-totalité du budget d'entraînement a été consacrée au modèle MPT-7B de base, qui a nécessité environ 9,5 jours d'entraînement sur 440 GPU A100-40 Go, et a coûté environ 200 000 $. Les modèles fine-tunés ont nécessité beaucoup moins de calcul et ont coûté beaucoup moins cher – allant de quelques centaines à quelques milliers de dollars chacun.
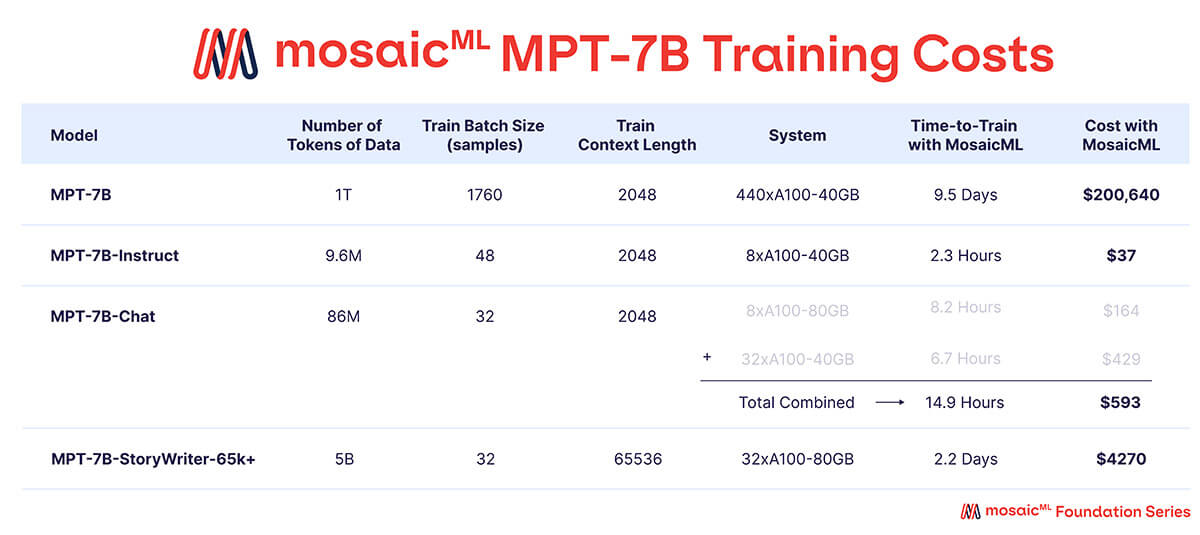
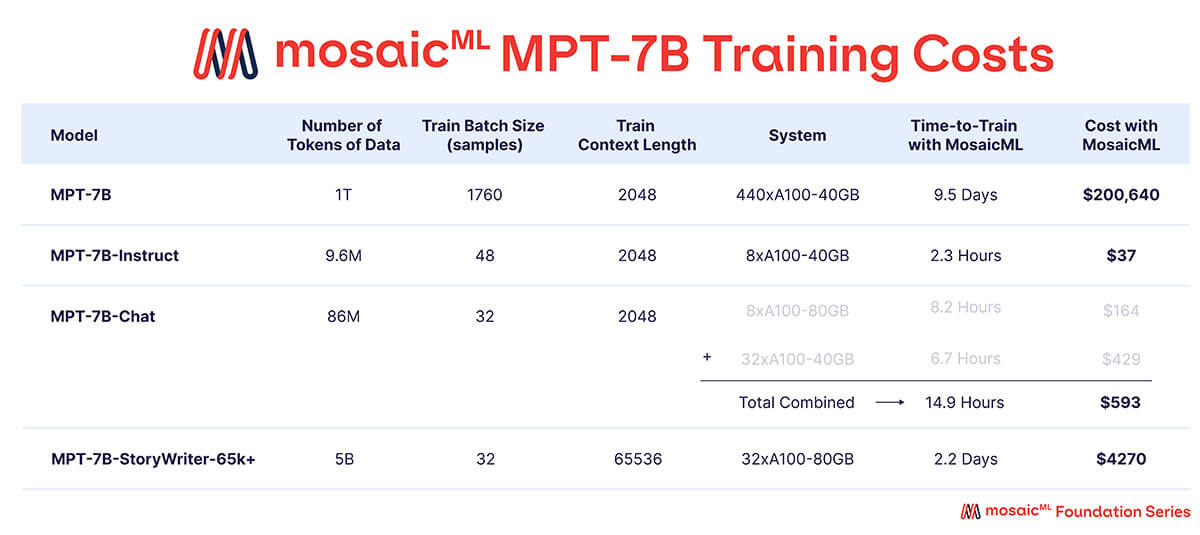{kind=link}
Le 'Temps d'entraînement' est la durée totale de l'exécution du job du début à la fin, y compris la sauvegarde des checkpoints, l'évaluation périodique, les redémarrages, etc. Le 'Coût' est calculé avec des prix de 2 $/A100-40 Go/heure et 2,50 $/A100-80 Go/heure pour les GPU réservés sur la plateforme MosaicML.
Chacune de ces recettes d'entraînement peut être entièrement personnalisée. Par exemple, si vous souhaitez commencer avec notre MPT-7B open source et le fine-tuner sur des données propriétaires avec une longue longueur de contexte, vous pouvez le faire dès aujourd'hui sur la plateforme MosaicML.
Autre exemple, pour entraîner un nouveau modèle à partir de zéro sur un domaine personnalisé (par exemple, sur du texte biomédical ou du code), réservez simplement de grands blocs de calcul à court terme avec l'offre hero cluster de MosaicML. Choisissez la taille de modèle et le budget de tokens souhaités, téléchargez vos données dans un stockage d'objets comme S3, et lancez un job MCLI. Vous aurez votre propre LLM personnalisé en quelques jours seulement !
Consultez notre précédent article de blog sur les LLM pour obtenir des conseils sur les temps et les coûts d'entraînement des différents LLM. Trouvez les dernières données de débit pour des configurations de modèles spécifiques ici. Conformément à nos travaux précédents, tous les modèles MPT-7B ont été entraînés avec Pytorch FullyShardedDataParallelism (FSDP) et sans parallélisme tensoriel ou pipeline.
Stabilité de l'entraînement
Comme de nombreuses équipes l'ont documenté, l'entraînement de LLM avec des milliards de paramètres sur des centaines à des milliers de GPU est incroyablement difficile. Le matériel tombera en panne fréquemment et de manière créative et inattendue. Les pics de perte dérailleront l'entraînement. Les équipes doivent « surveiller » l'exécution de l'entraînement 24h/24 et 7j/7 en cas de défaillances et appliquer des interventions manuelles lorsque les choses tournent mal. Consultez le carnet de bord OPT pour un exemple franc des nombreux périls qui attendent quiconque entraîne un LLM.
Chez MosaicML, nos équipes de recherche et d'ingénierie ont travaillé sans relâche au cours des 6 derniers mois pour éliminer ces problèmes. En conséquence, notre carnet de bord d'entraînement MPT-7B (Figure 5) est très ennuyeux ! Nous avons entraîné MPT-7B sur 1 billion de tokens du début à la fin sans aucune intervention humaine. Pas de pics de perte, pas de changements de taux d'apprentissage en cours de route, pas de saut de données, gestion automatique des GPU morts, etc.

{kind=link}
MPT-7B a été entraîné sur 1T de tokens sur une période de 9,5 jours sur 440 GPU A100-40 Go. Pendant ce temps, le job d'entraînement a rencontré 4 défaillances matérielles, qui ont toutes été détectées par la plateforme MosaicML. L'exécution a été automatiquement mise en pause et reprise après chaque défaillance, et aucune intervention humaine n'a été nécessaire.

{kind=link}
Si des pannes matérielles surviennent pendant l'exécution d'un travail, la plateforme MosaicML détecte automatiquement la panne, met le travail en pause, isole les nœuds défectueux, puis reprend le travail. Au cours de l'exécution de l'entraînement MPT-7B, nous avons rencontré 4 pannes de ce type, et à chaque fois, le travail a été repris automatiquement
Comment avons-nous fait cela ? Premièrement, nous avons abordé la stabilité de la convergence avec des améliorations architecturales et d'optimisation. Nos modèles MPT utilisent ALiBi plutôt que des plongements positionnels, ce qui, selon nous, améliore la résilience aux pics de perte. Nous entraînons également nos modèles MPT avec l'optimiseur Lion plutôt qu'AdamW, qui fournit des magnitudes de mise à jour stables et réduit de moitié la mémoire de l'état de l'optimiseur.
Deuxièmement, nous avons utilisé la fonctionnalité NodeDoctor de la plateforme MosaicML pour surveiller et résoudre les pannes matérielles, et la fonctionnalité JobMonitor pour reprendre les exécutions après la résolution de ces pannes. Ces fonctionnalités nous ont permis d'entraîner MPT-7B sans intervention humaine du début à la fin, malgré 4 pannes matérielles pendant l'exécution. Voir la Figure 6 pour une vue rapprochée de ce à quoi ressemble la reprise automatique sur la plateforme MosaicML.
Inférence
MPT est conçu pour être rapide, facile et peu coûteux à déployer pour l'inférence. Pour commencer, tous les modèles MPT sont sous-classés de la classe de base HuggingFace PretrainedModel, ce qui signifie qu'ils sont entièrement compatibles avec l'écosystème HuggingFace. Vous pouvez téléverser des modèles MPT sur le Hub HuggingFace, générer des sorties avec des pipelines standard comme `model.generate(...)`, créer des Espaces HuggingFace (voir certains des nôtres ici !), et plus encore.
Qu'en est-il des performances ? Avec les couches optimisées de MPT (y compris FlashAttention et la layernorm de faible précision), les performances prêtes à l'emploi de MPT-7B lors de l'utilisation de `model.generate(...)` sont 1,5 à 2 fois plus rapides que celles d'autres modèles 7B comme LLaMa-7B. Cela permet de créer facilement des pipelines d'inférence rapides et flexibles avec seulement HuggingFace et PyTorch.
Mais si vous avez vraiment besoin des meilleures performances ? Dans ce cas, portez directement les poids MPT vers FasterTransformer ou ONNX. Consultez le dossier d'inférence de LLM Foundry pour les scripts et les instructions.
Enfin, pour la meilleure expérience d'hébergement, déployez vos modèles MPT directement sur le service d'inférence de MosaicML. Commencez avec nos points de terminaison gérés pour des modèles comme MPT-7B-Instruct, et/ou déployez vos propres points de terminaison de modèles personnalisés pour un coût optimal et une confidentialité des données.
Prochaines étapes ?
Cette version de MPT-7B est l'aboutissement de deux années de travail chez MosaicML à construire et à tester en conditions réelles des logiciels open-source (Composer, StreamingDataset, LLM Foundry) et une infrastructure propriétaire (MosaicML Training et Inference) qui permet aux clients d'entraîner des LLM sur n'importe quel fournisseur de calcul, avec n'importe quelle source de données, avec efficacité, confidentialité et transparence des coûts - et de faire en sorte que les choses se passent bien dès la première fois.
Nous pensons que MPT, le MosaicML LLM Foundry et la plateforme MosaicML sont le meilleur point de départ pour construire des LLM personnalisés pour un usage privé, commercial et communautaire, que vous souhaitiez affiner nos points de contrôle ou entraîner les vôtres à partir de zéro. Nous sommes impatients de voir comment la communauté s'appuiera sur ces outils et artefacts.
Surtout, les modèles MPT-7B d'aujourd'hui ne sont que le début ! Pour aider nos clients à relever des tâches plus difficiles et à améliorer continuellement leurs produits, MosaicML continuera à produire des modèles fondamentaux de plus en plus qualitatifs. Des modèles de suivi passionnants sont déjà en cours d'entraînement. Attendez-vous à en entendre parler bientôt !
Remerciements
Nous sommes reconnaissants envers nos amis d'AI2 pour nous avoir aidés à organiser notre jeu de données de pré-entraînement, à choisir un excellent tokenizer, et pour de nombreuses autres conversations utiles en cours de route ⚔️
Annexe
Données
mC4
Multilingual C4 (mC4) 3.1.0 est une mise à jour du mC4 original par Chung et al., qui contient des sources jusqu'en août 2022. Nous avons sélectionné le sous-ensemble anglais, puis appliqué les critères de filtrage suivants à chaque document :
- Le caractère le plus courant doit être alphabétique.
- Au moins 92 % des caractères doivent être alphanumériques.
- Si le document contient plus de 500 mots, le mot le plus courant ne peut pas constituer plus de 7,5 % du nombre total de mots ; si le document contient 500 mots ou moins, le mot le plus courant ne peut pas constituer plus de 30 % du nombre total de mots.
- Le document doit contenir entre 200 et 50 000 mots.
Les trois premiers critères de filtrage ont été utilisés pour améliorer la qualité des échantillons, et le critère de filtrage final (les documents doivent contenir entre 200 et 50 000 mots) a été utilisé pour augmenter la longueur moyenne de séquence des données de pré-entraînement.
mC4 a été publié dans le cadre de l'effort continu de Dodge et al..
C4
Colossal Cleaned Common Crawl (C4) est un corpus Common Crawl anglais introduit par Raffel et al. Nous avons appliqué le processus de déduplication sémantique d'Abbas et al. pour supprimer les 20 % de documents les plus similaires au sein de C4, car des expériences internes ont montré qu'il s'agissait d'une amélioration de Pareto pour les modèles entraînés sur C4.
RedPajama
Nous avons inclus un certain nombre de sous-ensembles du jeu de données RedPajama, qui est la tentative de Together de répliquer les données d'entraînement de LLaMA. Plus précisément, nous avons utilisé les sous-ensembles CommonCrawl, arXiv, Wikipedia, Books et StackExchange.
The Stack
Nous voulions que notre modèle soit capable de générer du code, nous nous sommes donc tournés vers The Stack, un corpus de 6,4 To de données de code. Nous avons utilisé The Stack Dedup, une variante de The Stack qui a été approximativement dédupliquée (via MinHashLSH) à 2,9 To. Nous avons sélectionné un sous-ensemble de 18 des 358 langages de programmation de The Stack afin de réduire la taille du jeu de données et d'augmenter sa pertinence :
- C
- C-Sharp
- C++
- Common Lisp
- F-Sharp
- Fortran
- Go
- Haskell
- Java
- Ocaml
- Perl
- Python
- Ruby
- Rust
- Scala
- Scheme
- Shell
- Tex
Nous avons choisi que le code constitue 10 % des jetons de pré-entraînement, car des expériences internes ont montré que nous pouvions entraîner sur jusqu'à 20 % de code (et 80 % de langage naturel) sans impact négatif sur l'évaluation du langage naturel.
Nous avons également extrait le composant Markdown de The Stack Dedup et l'avons traité comme un sous-ensemble de données de pré-entraînement indépendant (c'est-à-dire non comptabilisé dans les 10 % de jetons de code). Notre motivation est que les documents en langage de balisage sont majoritairement en langage naturel, et à ce titre devraient être comptabilisés dans notre budget de jetons de langage naturel.
Semantic Scholar ORC
Le Semantic Scholar Open Research Corpus (S2ORC) est un corpus d'articles universitaires en langue anglaise, que nous considérons comme une source de données de haute qualité. Les critères de filtrage de qualité suivants ont été appliqués :
- L'article est en libre accès.
- L'article a un titre et un résumé.
- L'article est en anglais (évalué à l'aide de cld3).
- L'article contient au moins 500 mots et 5 paragraphes.
- L'article a été publié après 1970 et avant le 2022-12-01.
- Le mot le plus fréquent dans l'article est composé uniquement de caractères alphabétiques, et il apparaît dans moins de 7,5 % du document.
Cela a produit 9,9 millions de documents. Les instructions pour obtenir la dernière version du jeu de données sont disponibles ici, et la publication originale est ici. La version filtrée du jeu de données nous a été aimablement fournie par AI2.
Tâches d'évaluation
Lambada : 5153 échantillons de texte sélectionnés dans le corpus de livres. Consiste en un paragraphe de plusieurs centaines de mots dans lequel le modèle doit prédire le mot suivant.
PIQA : 1838 échantillons de questions à choix multiples binaires intuitives sur le plan physique, par exemple « Question : Comment puis-je transporter facilement des vêtements sur des cintres lorsque je déménage ? », « Réponse : » Prenez quelques cintres vides robustes, puis accrochez plusieurs vêtements sur ces cintres et transportez-les tous en même temps. »
COPA : 100 phrases de la forme XYZ donc/parce que TUV. Présentées sous forme de questions à choix multiples binaires où le modèle a le choix entre deux façons possibles de suivre le donc/parce que. par exemple {"query": "La femme était de mauvaise humeur, donc", "gold": 1, "choices": ["elle a bavardé avec son amie.", "elle a dit à son amie de la laisser tranquille."]}
BoolQ : 3270 questions oui/non basées sur un passage contenant des informations pertinentes. Les sujets des questions vont de la culture pop à la science, au droit, à l'histoire, etc. par exemple {"query": "Passage : Kermit la grenouille est un personnage de Muppet et la création la plus connue de Jim Henson. Introduit en 1955, Kermit sert de protagoniste stoïque dans de nombreuses productions des Muppets, notamment Sesame Street et The Muppet Show, ainsi que dans d'autres séries télévisées, films, émissions spéciales et annonces d'intérêt public au fil des ans. Henson a interprété Kermit à l'origine jusqu'à sa mort en 1990 ; Steve Whitmire a interprété Kermit de cette époque jusqu'à son licenciement du rôle en 2016. Kermit est actuellement interprété par Matt Vogel. Il a également été doublé par Frank Welker dans Muppet Babies et occasionnellement dans d'autres projets d'animation, et est doublé par Matt Danner dans le redémarrage de Muppet Babies en 2018.\nQuestion : Kermit la grenouille est-il apparu dans Sesame Street ?\n", "choices": ["non", "oui"], "gold": 1}
Arc-Challenge : 1172 questions difficiles à choix multiples à quatre options sur la science
Arc-Easy : 2376 questions faciles à choix multiples à quatre options sur la science
HellaSwag : 10042 questions à choix multiples à quatre options dans lesquelles un scénario de la vie réelle est présenté et le modèle doit choisir la conclusion la plus probable du scénario.
Jeopardy : 2117 questions Jeopardy de cinq catégories : science, histoire du monde, histoire des États-Unis, origines des mots et littérature. Le modèle doit fournir la réponse exacte
MMLU : 14 042 questions à choix multiples provenant de 57 catégories académiques diverses
TriviaQA : 11313 questions de culture pop à réponse libre
Winograd : 273 questions de schémas où le modèle doit déterminer à quel référent un pronom se rapporte le plus probablement.
Winogrande : 1 267 questions de schémas où le modèle doit déterminer quelle phrase ambiguë est la plus logiquement probable (les deux versions de la phrase sont syntaxiquement valides)
Politique de confidentialité des espaces MPT Hugging Face
Veuillez consulter notre Politique de confidentialité des espaces MPT Hugging Face.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.