Annonce du flux de données de modification (CDF) de Lakebase
Ouvrir la base de données OLTP à d'autres moteurs
par Pranav Aurora, Cheng Chen et Hristo Stoyanov
- Le flux de données de modification (CDF) de Lakebase (aperçu public) élimine la prolifération des pipelines à partir des bases de données opérationnelles. Activez le CDF une fois par projet Lakebase pour exposer les modifications de chaque table via les tables gérées Unity Catalog pour un accès en lecture directe par n'importe quel moteur, modèle ou agent.
- CDC natif géré de bout en bout sans infrastructure secondaire : pas de connecteurs de base de données, de surveillance de l'état de réplication ou de travaux d'extraction séparés ; les consommateurs en aval tels que les pipelines de streaming SDP, les vues matérialisées DBSQL et les embeddings Agent Bricks s'abonnent tous au même flux isolé sans impacter la charge de travail principale.
- Les données opérationnelles fonctionnent désormais comme la couche Bronze native dans l'architecture médaillon. Les tables synchronisées de Lakebase servent déjà les données Gold aux applications ; Lakebase CDF boucle la boucle avec une gouvernance et une lignée complètes d'Unity Catalog sur le cycle de vie des données.
Le déplacement des données de votre base de données opérationnelle impliquait traditionnellement la configuration et la surveillance d'un pipeline pour chaque source vers chaque destination. Pour la plupart des équipes, cela représente un effort humain fragile, non géré et en O(n).
Aujourd'hui, nous changeons cette approche. Disponible dès maintenant en aperçu public, Lakebase propose un flux de données de modification (CDF) qui est stocké et géré dans les Tables gérées Unity Catalog. Activez le flux une fois et laissez tous les moteurs, modèles et agents en lire directement.
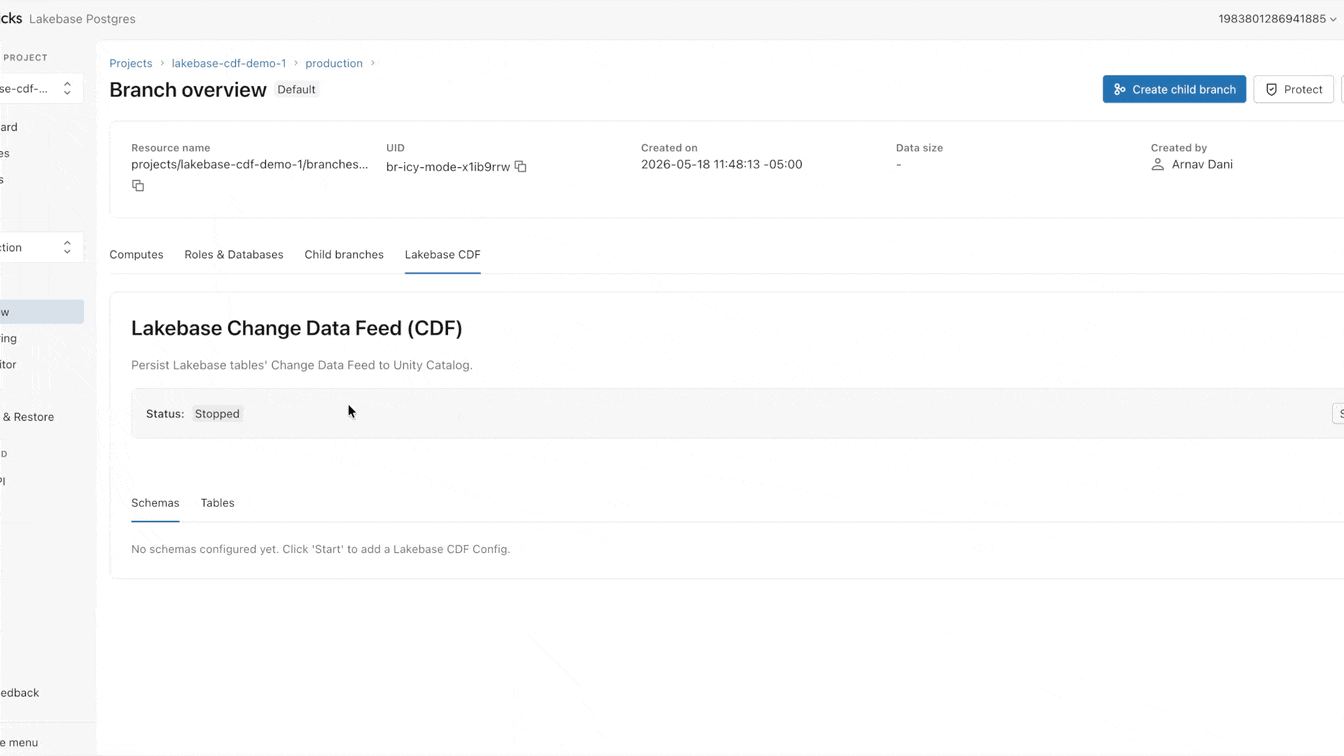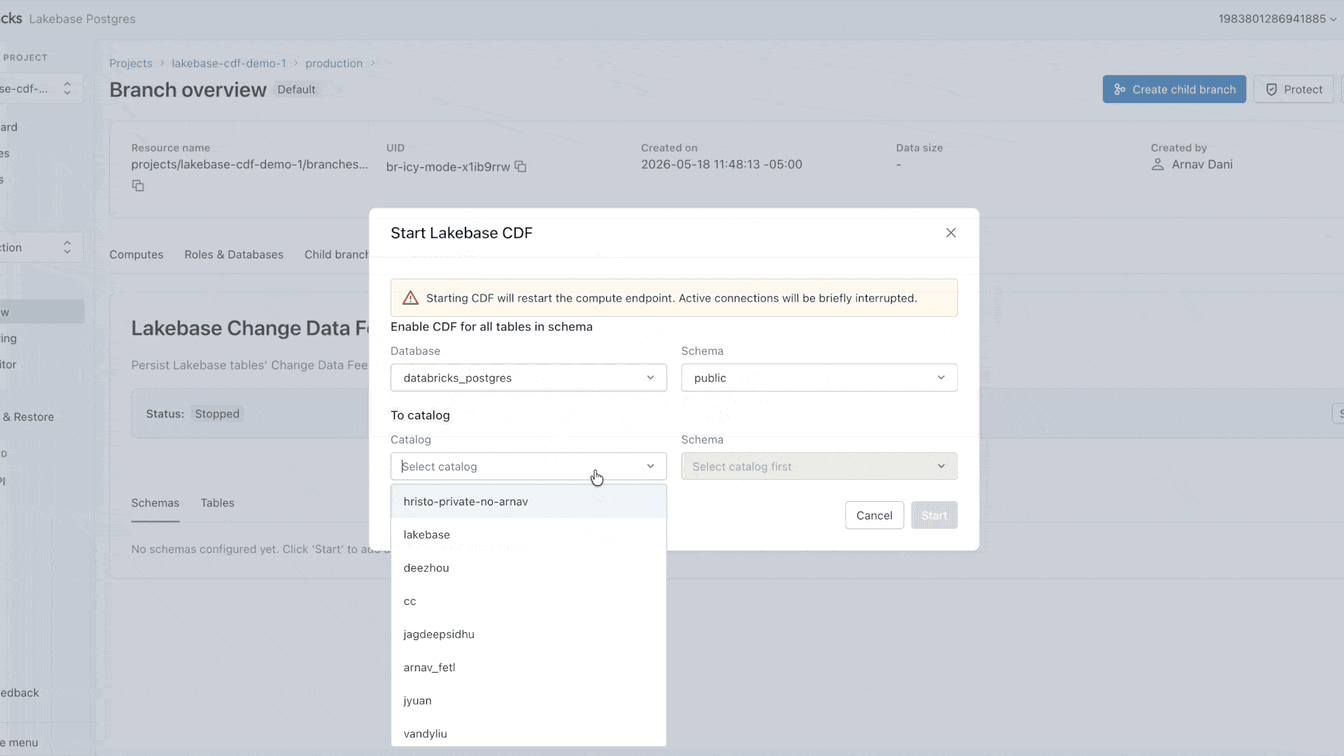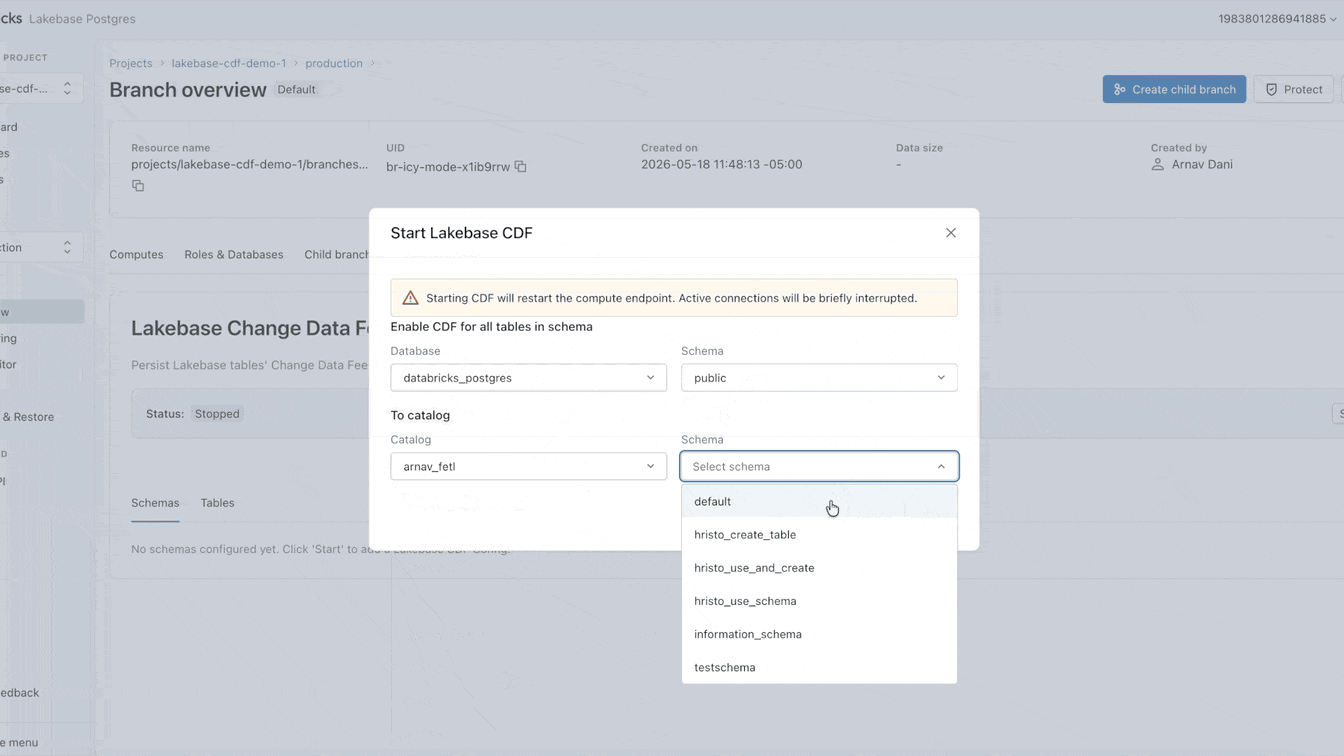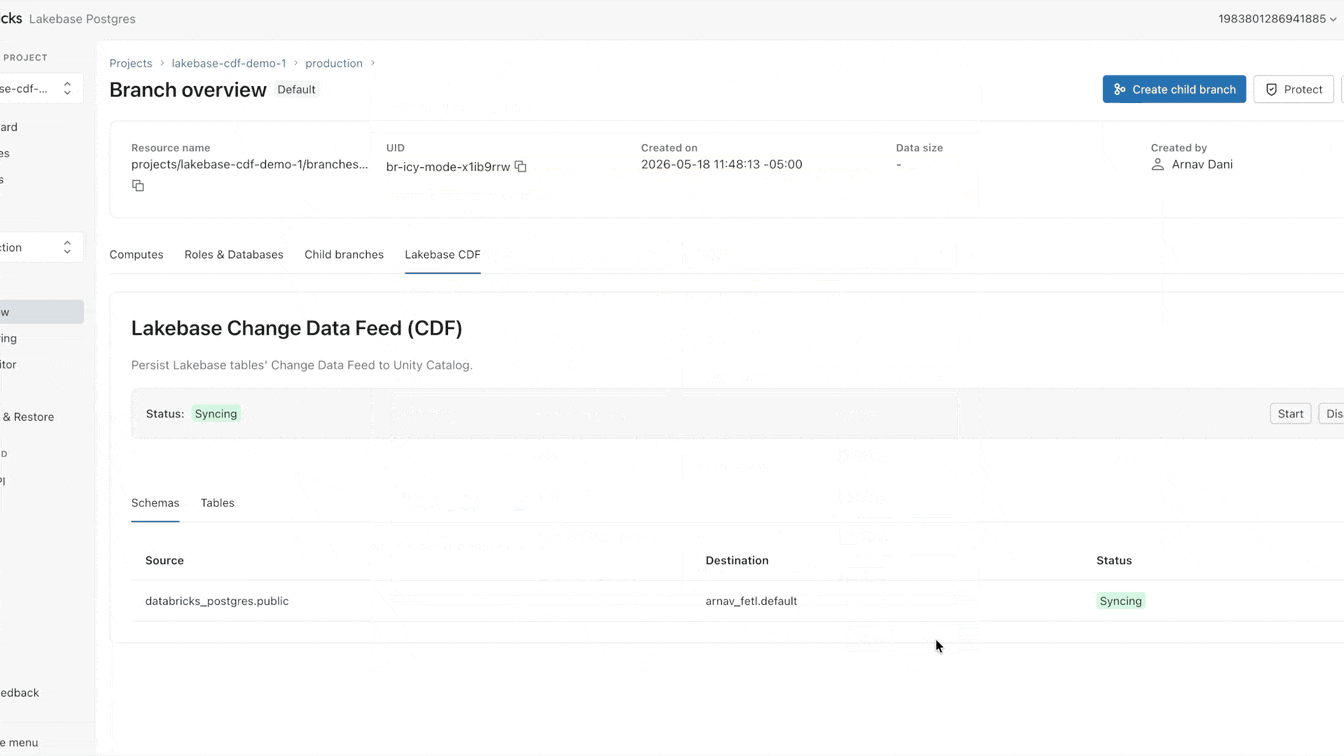
Pourquoi l'intégration des données opérationnelles dans le lac est-elle toujours si difficile ?
Bien que Lakeflow Connect ait rendu l'ingestion de données dans le Lakehouse triviale, l'extraction des données de la base de données OLTP reste un processus manuel et à forte friction. L'extraction de la capture des données de modification (CDC) oblige les équipes à configurer des connecteurs de base de données, à surveiller les états de réplication, à atténuer les impacts sur les performances et à suivre les erreurs à l'aide d'outils déconnectés. Ce modèle échoue dans le développement basé sur les agents qui repose sur la branche de données rapide. La maintenance de pipelines d'extraction complexes et non gérés pour chaque nouvelle branche vers chaque destination n'est pas durable.
Nous avons résolu ce problème dans le Lakehouse. Maintenant, nous l'apportons à Lakebase.
Le Lakehouse a éliminé les pipelines d'extraction pour l'analytique en stockant les données une fois dans des formats ouverts (Apache Iceberg™, Delta Lake). Il a établi le flux de données de modification (CDF) comme norme pour la réplication en aval, alimentant les flux ETL, de streaming et les journaux d'audit.
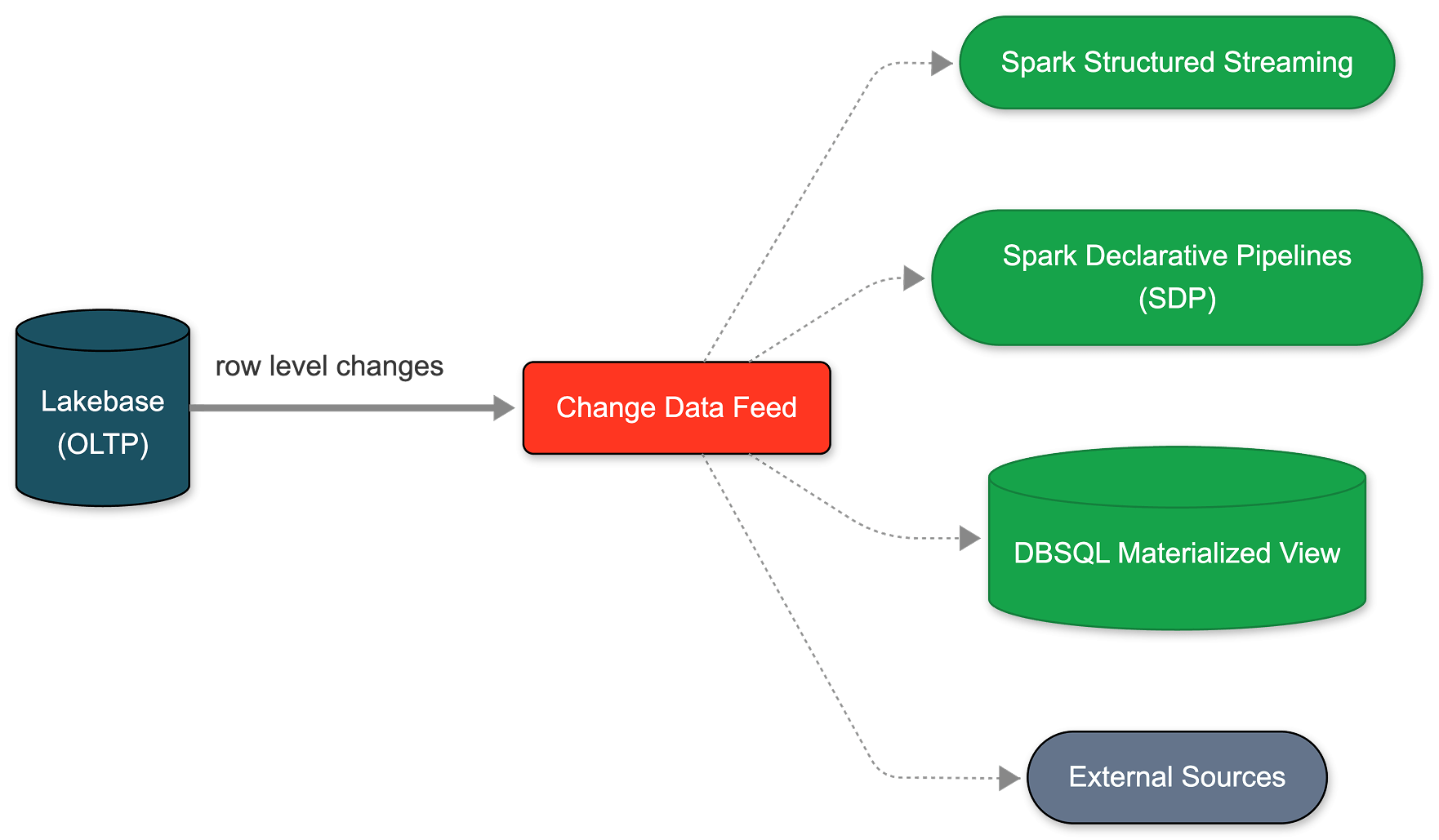
Vous pouvez maintenant configurer ce CDF nativement sur Lakebase. L'activation prend moins d'une minute et s'applique à toutes les tables d'un projet. À partir de ce flux unique, vous pouvez créer des pipelines de streaming avec SDP, générer des vues matérialisées avec DBSQL ou calculer et stocker des embeddings avec Agent Bricks. Chaque consommateur en aval s'abonne au même flux exact, complètement isolé de votre charge de travail opérationnelle principale.
Les bases de données opérationnelles appartiennent à l'architecture médaillon
Avec Lakebase, vos données opérationnelles ne sont plus isolées du Lakehouse. Lakebase propose déjà des Tables synchronisées, établissant le modèle de service des jeux de données Gold directement aux applications. Lakebase CDF complète l'architecture. Votre base de données opérationnelle est maintenant votre couche Bronze native, éliminant le besoin de pipelines séparés ou de travaux d'extraction pour intégrer les données dans le Lakehouse. Au lieu de cela, vous bénéficiez d'une gouvernance et d'une lignée complètes sur le cycle de vie des données via Unity Catalog.
Ce n'est que le début. Nous apportons l'ouverture que vous aimez du Lakehouse directement à Lakebase. Restez à l'écoute pour le Data and AI Summit, et rejoignez notre session de présentation sur cette architecture.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.