Annonce de la préversion publique de Lakebase
Postgres entièrement géré pour les applications de données et les agents d'IA
par Jasraj Dange, Andrei Dragus, Dave Nettleton, Hans Norheim, Susan Pierce et Reynold Xin
- Les bases de données traditionnelles sont lentes et coûteuses à provisionner, ne s'adaptent pas bien, sont isolées des plateformes d'analyse et ne s'intègrent pas dans un flux de travail de développement moderne.
- Lakebase est une base de données Postgres entièrement gérée, intégrée au lakehouse et conçue pour l'IA.
- Les entreprises utilisent Lakebase pour servir des données et des fonctionnalités à partir du lakehouse, alimenter des applications intelligentes autonomes et analyser des données opérationnelles dans le lakehouse.
Lors du Data and AI Summit, nous avons présenté une nouvelle catégorie de bases de données opérationnelles appelée lakebases pour la création d'applications intelligentes. Aujourd'hui, nous sommes ravis d'annoncer la préversion publique de Databricks Lakebase, la première base de données Postgres entièrement gérée, conçue pour les applications de données et l'IA.
Les clients combinent leurs données opérationnelles et analytiques pour créer des applications intelligentes : servir des caractéristiques et des modèles, créer des applications autonomes ou analyser des données opérationnelles dans un lakehouse. Mais ils continuent de rencontrer des difficultés avec le provisionnement, la mise à l'échelle et le manque d'une expérience de développement moderne pour les données, car les bases de données n'ont pas connu beaucoup d'innovations ces dernières décennies.
Les Lakebases offrent une solution pour l'ère de l'IA. Dans ce blog, nous présenterons les principales fonctionnalités et avantages de Databricks Lakebase, et décrirons comment les clients utilisent déjà Lakebase aujourd'hui.
Présentation de Lakebase
Les bases de données OLTP n'ont pas fondamentalement changé depuis les années 90. Même lorsqu'elles sont déployées dans le cloud, ces bases de données héritées sont lentes et coûteuses à provisionner et à gérer. Les bases de données opérationnelles sont généralement déployées dans une pile distincte de la plateforme d'analyse, créant des silos entre les données transactionnelles et analytiques. De plus, ces bases de données ne s'intègrent pas non plus dans un flux de travail de développement moderne nécessaire au développement de l'IA. L'architecture traditionnelle implique généralement des bases de données distinctes pour les environnements de développement, de test, de préproduction et de production - chacune étant provisionnée, peuplée et maintenue séparément.
Databricks Lakebase est une base de données unique en son genre, construite sur des normes open source, avec une architecture hautement évolutive, basée sur la séparation du calcul et du stockage, spécifiquement conçue pour le développement d'applications modernes. Lakebase est profondément intégré au lakehouse pour faciliter la combinaison des piles opérationnelles, analytiques et IA.
Construit sur Postgres open source
Au cours des 7 dernières années, Postgres est devenue la base de données la plus populaire dans la communauté des développeurs et est le choix de base de données de facto pour les applications modernes. Il est open source, dispose d'un écosystème d'extensions dynamique et est pris en charge par une communauté robuste de bibliothèques, d'outils et de frameworks. Les ingénieurs savent déjà comment travailler avec, et tous les modèles fondamentaux sont entraînés sur de vastes quantités de données disponibles pour l'écosystème Postgres, ce qui le rend très accessible aux applications et agents intelligents.
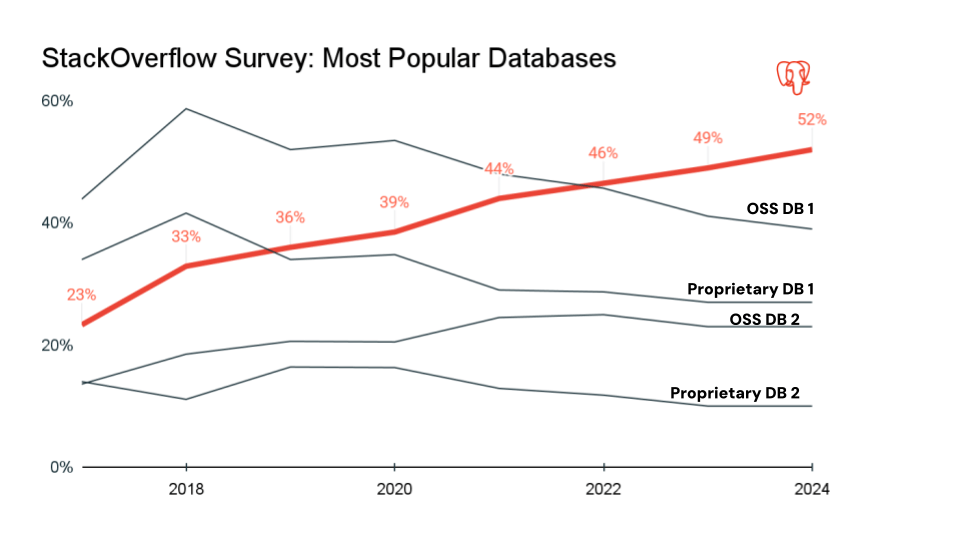
Avec la prise en charge d'extensions populaires telles que PostGIS et pgvector, et un large écosystème de pilotes et d'outils, Lakebase offre un riche ensemble de fonctionnalités qui seront familières aux équipes de développement.
Séparation du calcul et du stockage
Lakebase exploite une architecture qui sépare le calcul et le stockage, ce qui permet une mise à l'échelle indépendante tout en prenant en charge des transactions à faible latence (<10 ms) et à haute concurrence (>10k qps).
Lakebase est entièrement géré par Databricks, ce qui signifie qu'il n'y a aucune infrastructure à provisionner ou à maintenir. Le résultat est un service de base de données qui élimine les frictions des processus d'infrastructure et de développement, permettant aux équipes de progresser plus rapidement sans compromettre le contrôle ou la fiabilité.
- Haute disponibilité avec des répliques lisibles : La haute disponibilité multi-zones protège contre les pannes de zone en provisionnant des ressources de calcul secondaires entre les zones. Les répliques peuvent être facultativement lisibles pour fournir une isolation et une mise à l'échelle horizontale des charges de travail de lecture.
- Stockage et récupération des données : Toutes les transactions sont persistées dans un stockage chiffré qui est durable au niveau régional et donc protégé contre toute panne de zone unique. La récupération à un instant T est disponible via une fenêtre de protection des données qui offre jusqu'à 35 jours de temps de récupération.
- Branching pour un environnement de test isolé ou une récupération à un instant T : Lakebase utilise le branching par copie sur écriture pour créer un clone instantané sans copie de la base de données, avec un calcul dédié pour opérer sur cette branche. La branche enfant est gérée indépendamment de la branche parente principale, et peut être créée en fonction des données de la branche parente au moment actuel, ou à un moment précédent, ou à un numéro de séquence de journal (LSN). Cela peut être utilisé pour créer un environnement de test isolé avec des données de production ou pour des opérations de récupération à un instant T.
DevEx moderne, conçu pour l'IA
Lakebase est construit sur la technologie Neon, qui fournit le branching par copie sur écriture et le calcul serverless à mise à l'échelle automatique. Le branching par copie sur écriture permet de créer instantanément une nouvelle base de données avec les mêmes données et le même schéma qu'une base de données existante, sans affecter l'originale. Cette nouvelle base de données est économiquement avantageuse car elle ne duplique pas les données sous-jacentes. Le calcul serverless à mise à l'échelle automatique offre des temps de démarrage inférieurs à la seconde et s'adapte en fonction de la demande, avec une mise à l'échelle à zéro permettant une utilisation rentable du calcul.
Combinées, la mise à l'échelle automatique serverless du calcul et les capacités de branching changent complètement le paradigme de développement des applications. Les développeurs peuvent créer instantanément une branche de base de données pour correspondre à chaque branche git et n'ont pas à se soucier de la mise en place de nouvelles instances de base de données, de l'échantillonnage de données pour les environnements de développement ou de test, ou de l'hydratation de plusieurs bases de données.
Pour les développeurs et les agents, cela signifie que les environnements de base de données éphémères peuvent être rapidement créés, utilisés et décommissionnés à un coût quasi nul, avec un effort quasi nul.
L'expérience développeur Neon complète dans Lakebase et de nombreuses autres fonctionnalités passionnantes seront bientôt disponibles.
Intégré au lakehouse
Lakebase intègre une couche de base de données transactionnelle au lakehouse et hérite de la maturité opérationnelle de la plateforme Databricks, y compris l'observabilité, la sécurité et les contrôles d'accès. Lakebase se synchronise avec les tables gérées par Unity Catalog, ce qui permet de combiner rapidement et facilement les charges de travail opérationnelles, analytiques et IA sans pipelines ETL personnalisés. En conséquence, vous pouvez créer des applications intelligentes qui consomment des caractéristiques ou des prédictions générées dans le lakehouse et mettre à jour la couche analytique avec des données opérationnelles fraîches, le tout au sein d'une plateforme unifiée.
- Synchronisation des données entièrement gérée : Des pipelines de synchronisation des données faciles à configurer offrent un moyen simple et évolutif de gérer les données entre les tables gérées par Unity Catalog et Lakebase. Les options de fréquence de synchronisation des données incluent le snapshot unique, déclenché ou continu.
- Service de caractéristiques et de modèles : Servez des caractéristiques et des modèles de machine learning pour les applications avec Lakebase comme magasin de caractéristiques en ligne, et le lakehouse comme magasin hors ligne pour l'entraînement et l'analyse.
- Gouvernance unifiée : Profitez de l'intégration native avec Unity Catalog et l'identité Databricks pour simplifier le contrôle d'accès sur la plateforme. Utilisez l'identité Databricks et OAuth pour maintenir une identité cohérente entre vos utilisateurs opérationnels et analytiques. Enregistrez une base de données Postgres dans Unity Catalog pour fournir une gouvernance unifiée et un contrôle d'accès pour les utilisateurs analytiques.
- Intégration Databricks Apps : Créez et déployez des applications full-stack sur Databricks avec Lakebase alimentant les interactions transactionnelles. Databricks Apps prend en charge Lakebase en tant que type de ressource natif.
- Environnement de développement unifié : Utilisez l'éditeur SQL Databricks pour interroger directement Lakebase ainsi que parcourir les données.
- Surveillance intégrée : Fournit des métriques clés de la base de données telles que les transactions par seconde, le nombre de connexions ouvertes et l'utilisation des ressources.
- Sécurité réseau : Lakebase est intégré aux fonctionnalités de sécurité réseau d'entreprise de Databricks, y compris PrivateLink et les ACL IP, pour fournir une sécurité réseau cohérente
- Multi-cloud : Lakebase est disponible sur différents fournisseurs de cloud sans replatformage. En préversion publique, Lakebase est disponible sur Azure et AWS, avec une prise en charge de Google Cloud Platform à ajouter à l'avenir.
Les clients utilisent Lakebase
Avec des centaines de clients dans le programme de préversion privée, il a été passionnant de constater la variété des cas d'utilisation, notamment :
- Service de données et/ou de caractéristiques à partir du lakehouse pour des applications telles que les recommandations personnalisées ou la segmentation client,
- Création d'applications et d'agents pour le traitement des commandes, la validation de flux de travail interactifs et les chatbots.
- Analyse des données opérationnelles dans le lakehouse en synchronisant les données vers le lakehouse pour l'analyse historique des commandes, ou l'historique des chatbots pour les données d'entraînement.

Chez Heineken, notre objectif est de devenir le brasseur le mieux connecté. Pour ce faire, nous avions besoin d'un moyen d'unifier toutes nos données afin d'accélérer le passage de la donnée à la valeur. Databricks est depuis longtemps notre fondation pour l'analytique, créant des insights tels que des recommandations de produits et des améliorations de la chaîne d'approvisionnement. Notre plateforme de données analytiques évolue désormais pour devenir une plateforme de données IA opérationnelle et doit fournir ces insights aux applications à faible latence. —Jelle Van Etten, Head of Global Data Platform, Heineken
Chez Tibber, permettre aux clients de contrôler leur consommation d'énergie nécessite une infrastructure de données flexible. L'intégration de Lakebase avec Databricks facilite la fourniture de données analytiques et transactionnelles, nous aidant à fournir des insights en temps réel à nos clients. —Niklas Nordansjö, Data Platform Lead, Tibber AS
Un solide réseau de partenaires aide les clients de Lakebase à travailler avec leurs partenaires technologiques et intégrateurs de systèmes existants pour l'intégration des données, la business intelligence et la gouvernance. Nous sommes ravis d'avoir un groupe incroyable de partenaires de lancement industriels pour Lakebase.

Chez dbt Labs, nous changeons la façon dont l'ingénierie des données est faite. Avec le nouveau Lakebase de Databricks, nos clients communs pourront désormais combiner des données transactionnelles à faible latence et des données analytiques dans une seule plateforme sur Databricks. Cela nous aidera tous les deux à fournir une IA à l'échelle de l'entreprise à nos clients. Nous sommes impatients d'inaugurer la nouvelle ère de l'analytique avec Databricks. —Ryan Segar, Chief Product Officer, dbt Labs
Résumé
Lakebase combine la familiarité et l'extensibilité de Postgres, la scalabilité d'une architecture serverless moderne, une expérience développeur moderne, avec l'expérience de données unifiée du lakehouse et la maturité opérationnelle de la Databricks Data Intelligence Platform. En combinant ces éléments dans une offre unique entièrement gérée, Lakebase permet aux équipes de construire des applications intelligentes et axées sur les données sans la complexité opérationnelle traditionnellement associée aux systèmes transactionnels.
Lakebase est disponible en préversion publique avec les tarifs disponibles ici. Si vous cherchez à construire des applications intégrant l'analytique et l'IA, c'est la pièce manquante de votre pile technologique, prête à accélérer le développement et à simplifier les opérations. Si vous êtes un administrateur d'espace de travail ou de compte, vous pouvez l'activer directement depuis votre espace de travail Databricks. Essayez-le dès aujourd'hui !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.