Architecture de la collaboration globale sur les données avec Delta Sharing
Permettez à votre entreprise de passer à l'échelle en partageant vos données de manière sécurisée et efficace entre différents clouds, plateformes et régions.
par Matei Zaharia, Bilal Obeidat, Tianyi Huang et Giselle Goicochea
Delta Sharing a évolué pour devenir OpenSharing, le premier protocole ouvert et neutre vis-à-vis des fournisseurs pour partager en toute sécurité des actifs d'IA, y compris des compétences d'agent, des modèles d'IA et des données non structurées. Lisez l'annonce.
Dans le paysage numérique interconnecté d'aujourd'hui, le partage de données et la collaboration entre les organisations et les plateformes sont essentiels aux opérations commerciales modernes. Delta Sharing, un protocole ouvert et innovant de partage de données, permet aux organisations de partager et d'accéder en toute sécurité à des données sur diverses plateformes, en donnant la priorité à la sécurité et à l'évolutivité, sans contraintes de fournisseur ou de format de données.
Ce blog est dédié à la présentation des options de réplication des données au sein de Delta Sharing en explorant des conseils d'architecture adaptés à des scénarios spécifiques de partage de données. En nous appuyant sur nos expériences avec de nombreux clients de Delta Sharing, notre objectif est de réduire les coûts de transfert sortant et d'améliorer les performances en proposant des alternatives spécifiques de réplication des données. Bien que le partage en direct reste adapté à de nombreux scénarios de partage de données interrégionaux, il existe des cas où la réplication de l'ensemble du jeu de données et la mise en place d'un processus de rafraîchissement des données pour les répliques régionales locales s'avèrent plus rentables. Delta Sharing facilite cela grâce à l'utilisation du stockage Cloudflare R2, de Change Data Feed (CDF) Delta Sharing et des fonctionnalités de Delta Deep Cloning. Grâce à ces capacités, Delta Sharing est très apprécié par les clients pour l'autonomie qu'il offre aux utilisateurs et sa flexibilité exceptionnelle pour répondre à leurs besoins de partage de données.
Delta Sharing est ouvert, flexible et rentable
Databricks et la Linux Foundation ont développé Delta Sharing pour fournir la première approche open source du partage de données à travers les données, l'analytique et l'IA. Les clients peuvent partager des données en direct sur plusieurs plateformes, clouds et régions avec une sécurité et une gouvernance renforcées. Que vous utilisiez le projet open source en auto-hébergement ou la version entièrement gérée de Delta Sharing sur Databricks, les deux offrent une solution flexible, rentable et indépendante de la plateforme pour la distribution mondiale de données. Les clients de Databricks bénéficient d'avantages supplémentaires au sein d'un environnement géré qui minimise les frais administratifs et s'intègre nativement avec Databricks Unity Catalog. Cette intégration offre une expérience simplifiée pour le partage de données au sein des organisations et entre elles.
Delta Sharing sur Databricks a connu une adoption généralisée dans divers scénarios de collaboration depuis sa disponibilité générale en août 2022.
Dans ce blog, nous explorerons deux modèles d'architecture courants dans lesquels Delta Sharing a joué un rôle essentiel pour permettre et améliorer des scénarios commerciaux critiques :
- Partage de données interrégional intra-entreprise
- Modèle d'agrégateur de données (Hub and Spoke)
Dans le cadre de ce blog, nous démontrerons également que l'architecture de déploiement de Delta Sharing est flexible et peut être étendue de manière transparente pour répondre à de nouvelles exigences de partage de données.
Partage de données interrégional intra-entreprise
Dans ce cas d'utilisation, nous illustrerons un modèle de déploiement courant de Delta Sharing chez nos clients lorsqu'il existe un besoin commercial de partager certaines données entre les régions, comme le fait d'avoir une équipe QA dans des régions distinctes ou une équipe de reporting intéressée par les données d'activité commerciale à l'échelle mondiale. Généralement, le partage de tables intra-entreprise implique :
- Partage de grandes tables : Il est nécessaire de partager de grandes tables en temps réel avec les destinataires, dont les modèles d'accès varient. Les destinataires exécutent souvent des requêtes diverses avec différents prédicats. Un bon exemple est celui des données de parcours de navigation (clickstream) et d'activité des utilisateurs, pour lesquelles l'accès à distance est plus approprié.
- Réplication locale : Pour améliorer les performances et mieux gérer les coûts de transfert sortant, certaines données doivent être répliquées afin de créer une copie locale, en particulier lorsque la région du destinataire compte un nombre important d'utilisateurs qui accèdent fréquemment à ces tables.
Dans ce scénario, les unités commerciales du fournisseur de données et du destinataire des données partagent le même compte Unity Catalog, mais elles disposent de metastores différents sur Databricks.
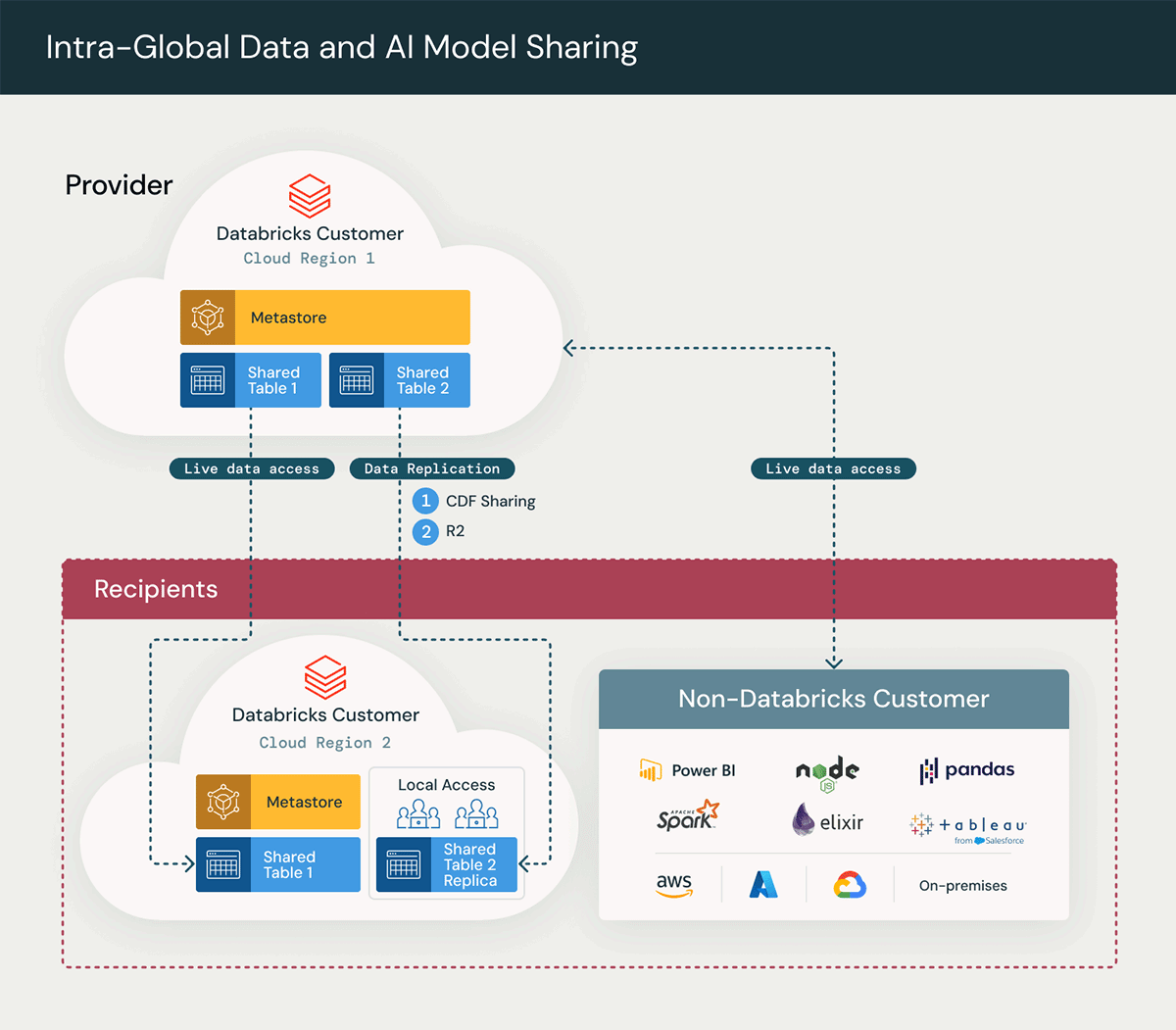
Le schéma ci-dessus illustre l'architecture globale de la solution Delta Sharing, en mettant en évidence les étapes clés du processus Delta Sharing :
- Création d'un partage : Les tables en direct sont partagées avec le destinataire, ce qui permet un accès immédiat aux données.
- Réplication des données à la demande : La mise en œuvre de la réplication des données à la demande implique la génération d'un doublon régional des données afin d'améliorer les performances, de réduire le besoin d'accès réseau interrégional et de minimiser les frais de transfert sortant associés. Ceci est réalisé grâce à l'utilisation des approches de réplication de données suivantes :
A. Change Data Feed sur une table partagée
Cette option nécessite de partager l'historique de la table et d'activer le Change Data Feed (CDF), qui doit être explicitement activé dans le code de configuration en définissant la propriété de table delta.enableChangeDataFeed = true à l'aide des commandes Create/Alter table.
De plus, lors de l'ajout de la table au partage, assurez-vous qu'elle est ajoutée avec l'option CDF, comme le montre l'exemple ci-dessous.
Une fois les données ajoutées ou mises à jour, les modifications peuvent être consultées comme dans cet exemple
Du côté du destinataire, les modifications peuvent être consultées et fusionnées dans une copie locale des données de la même manière que dans ce notebook. La propagation des modifications de la table partagée vers une réplique locale peut être orchestrée à l'aide d'un travail de workflow Databricks.
B. Cloudflare R2 avec Databricks
R2 est une excellente option pour tous les scénarios Delta Sharing, car les clients peuvent pleinement exploiter le potentiel du partage sans se soucier de frais de transfert sortant imprévisibles. Cela est abordé en détail plus loin dans ce blog.
C. Delta Deep Clone
Une autre option de cas particulier pour le partage intra-entreprise consiste à utiliser Delta Deep Clone lors du partage au sein du même compte cloud Databricks. Le clonage en profondeur (Deep Cloning) est une fonctionnalité Delta qui copie à la fois les données de la table source et les métadonnées de la table existante vers la cible du clone. De plus, la commande deep clone a la capacité d'identifier les nouvelles données et de se rafraîchir en conséquence. Voici la syntaxe :
La commande précédente s'exécute du côté du destinataire, où source_table_name est la table partagée et table_name est la copie locale des données à laquelle les utilisateurs peuvent accéder.
Un simple travail Databricks Workflows peut être planifié pour un rafraîchissement incrémentiel des données avec les mises à jour récentes à l'aide de la commande suivante :
Ce même cas d'utilisation peut facilement être étendu pour partager des données avec des partenaires et clients externes sur la plateforme Databricks ou sur toute autre plateforme. Il s'agit d'un autre modèle étendu courant dans lequel des partenaires et des clients externes, qui ne sont pas sur Databricks, souhaitent accéder à ces données via Excel, Power BI, Pandas et d'autres logiciels compatibles comme Oracle.
Modèle d'agrégateur de données (modèle Hub and Spoke)
Un autre modèle de scénario courant se présente lorsqu'une entreprise se concentre sur le partage de données avec des clients, en particulier dans les cas impliquant des entreprises d'agrégation de données ou lorsque la fonction commerciale principale consiste à collecter des données pour le compte de clients. Un agrégateur de données, en tant qu'entité, est spécialisé dans la collecte et la fusion de données provenant de diverses sources en un jeu de données unifié et cohérent. Ces partages de données sont essentiels pour répondre à divers besoins commerciaux tels que la prise de décision, l'analyse de marché, la recherche et le soutien aux opérations commerciales globales.
Le modèle de partage de données dans ce schéma effectue les actions suivantes :
- Connecte les destinataires répartis sur différents clouds, notamment AWS, Azure et GCP.
- Prend en charge la consommation de données sur diverses plateformes, dont la complexité varie du code Python aux feuilles de calcul Excel.
- Assure la scalabilité du nombre de destinataires, de la quantité de partages et des volumes de données.
En général, le fournisseur peut y parvenir en créant un espace de travail Databricks dans chaque cloud et en répliquant les données à l'aide de CDF sur une table partagée (comme indiqué ci-dessus) sur les trois clouds afin d'améliorer les performances et de réduire les coûts de transfert sortant (egress). Ensuite, au sein de chaque région cloud, les données peuvent être partagées avec les clients et partenaires concernés.
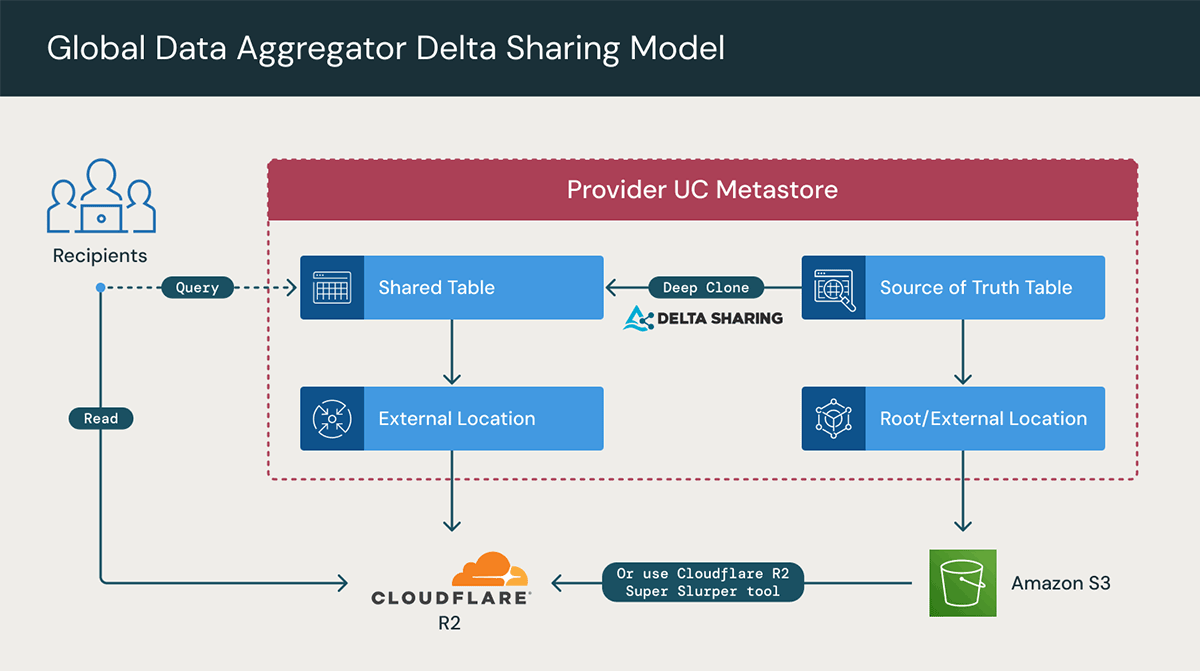
Cependant, une nouvelle approche plus simple et plus efficace consiste à utiliser R2 via Cloudflare avec Databricks, actuellement en version préliminaire privée.
L'intégration de Cloudflare R2 avec Databricks permettra aux entreprises de collaborer et de partager des données en direct de manière sécurisée, simple et abordable. Grâce à Cloudflare et Databricks, nos clients communs peuvent éliminer la complexité et les coûts dynamiques qui freinent le plein potentiel des initiatives d'analyse multi-cloud et d'AI. Plus précisément, il n'y aura aucun frais de transfert sortant (egress) et aucun besoin de transferts de données complexes ou de réplication coûteuse de jeux de données entre les régions.
L'utilisation de cette option nécessite les étapes suivantes :
- Ajouter Cloudflare R2 en tant qu'emplacement de stockage externe (tout en conservant la source de vérité des données dans S3/ADLS/etc.)
- Créer de nouvelles tables dans Cloudflare R2 et synchroniser les données de manière incrémentielle
- Delta deep clone
- R2 Super Slurper
- Créer un Delta Share, comme d'habitude, sur la table R2
Comme expliqué ci-dessus, ces approches illustrent différentes méthodes de réplication des données à la demande, chacune présentant des avantages distincts et des exigences spécifiques, ce qui les rend adaptées à divers cas d'usage.
Comparaison des méthodes de réplication de données pour le partage interrégional
Les trois mécanismes précédents permettent aux utilisateurs de Delta Sharing de créer une copie locale afin de minimiser les frais de transfert sortant (egress), en particulier entre différents clouds et régions. Le tableau ci-dessous fournit un résumé rapide pour différencier ces options.
| Outil de réplication des données | Points clés | Recommandation |
|---|---|---|
| Change data feed sur une table partagée |
| À utiliser pour le partage externe avec des partenaires/clients dans différentes régions |
| Cloudflare R2 avec Databricks |
| Fortement recommandé pour le Delta Sharing à grande échelle en termes de nombre de partages et pour plus de 2 régions |
| Delta Deep Clone |
| Recommandé pour le partage interne entre régions |
Delta Sharing est ouvert, flexible et rentable. Sur Databricks, il prend en charge un large éventail d'actifs de données, notamment des notebooks, des volumes et des modèles d'AI. De plus, plusieurs optimisations ont considérablement amélioré les performances des protocoles Delta Sharing. L'investissement continu de Databricks dans les fonctionnalités de Delta Sharing, notamment l'amélioration de la surveillance, de la scalabilité, de la facilité d'utilisation et de l'observabilité, souligne son engagement à améliorer l'expérience utilisateur et à garantir que Delta Sharing reste à la pointe de la collaboration de données pour l'avenir.
Étapes suivantes
Tout au long de ce blog, nous avons fourni des conseils d'architecture basés sur notre expérience avec de nombreux clients Delta Sharing. Notre priorité absolue est la gestion des coûts et les performances. Bien que le partage en direct convienne à de nombreux scénarios de partage de données interrégionaux, nous avons exploré des cas où la réplication de l'intégralité du jeu de données et la mise en place d'un processus de rafraîchissement des données pour les répliques régionales locales s'avèrent plus rentables. Delta Sharing facilite cela grâce à l'utilisation des fonctionnalités Delta Sharing de R2 et CDF, offrant ainsi aux utilisateurs une plus grande flexibilité.
Dans le cas d'usage du partage de données interrégional au sein de l'entreprise, Delta Sharing excelle dans le partage de grandes tables avec des modèles d'accès variés. La réplication locale, facilitée par le partage CDF, garantit des performances et une gestion des coûts optimales. De plus, R2 via Cloudflare avec Databricks offre une option efficace pour le Delta Sharing à grande échelle sur plusieurs régions et clouds.
Pour en savoir plus sur la manière d'intégrer Delta Sharing dans votre stratégie de collaboration de données, consultez les dernières ressources :
- Lisez le guide technique d'O'Reilly, Data Sharing and Collaboration with Delta Sharing (accès anticipé)
- Plongez au cœur de la documentation Databricks sur Delta Sharing.
- En savoir plus sur Delta Sharing : un standard ouvert pour le partage sécurisé de données
- Regardez la vidéo d'annonce de Delta Sharing avec Matei Zaharia (Keynote Data + AI Summit 2021)
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.