Fournir du contenu marketing génératif aux clients
Associer les données clients et l'IA générative pour mieux créer du lien avec les clients, partie 2
par Camden Clark, Joyce Gordon, Ally Hepp, Alex Rees, Tristen Wentling et Bryan Smith
- Personnalisation à grande échelle : l'IA générative automatise la création de contenus marketing personnalisés à l'aide des données clients de Databricks et d'Amperity.
- Intégration transparente : Amperity synchronise les données d'audience avec Braze, permettant une diffusion précise du contenu via Cloud Data Ingestion.
- Envoi dynamique d'e-mails : le templating Liquid dans Braze personnalise les objets et le corps des e-mails, améliorant ainsi l'engagement et les conversions.

Les spécialistes du marketing rêvent depuis longtemps d'un engagement client personnalisé et individuel, mais concevoir le volume de messages requis pour un tel niveau de personnalisation a toujours été un défi majeur. Bien que de nombreuses entreprises visent un marketing plus personnalisé, elles ciblent souvent de grands groupes de milliers ou de millions de clients au sein desquels il existe encore une grande diversité. Bien que cela soit préférable à une approche générique et uniforme, les entreprises préféreraient être plus précises, si seulement elles disposaient de la bande passante nécessaire pour s'engager à un niveau plus granulaire.
Comme mentionné dans notre blog précédent, l'IA générative peut aider à simplifier la création de contenus marketing hautement personnalisés. Bien qu'il soit encore difficile d'atteindre un véritable engagement individuel en raison de certaines limites de la technologie dans son état actuel, combiner les détails des clients avec des exemples de contenu et une ingénierie de prompt intelligente permet de créer de manière rentable un volume gérable de variantes adaptées. L'application de modèles indépendants pour évaluer le contenu généré avant qu'il ne soit soumis à une révision finale par un spécialiste du marketing peut grandement contribuer à garantir que ce contenu plus granulaire respecte les normes de l'entreprise tout en s'alignant plus précisément sur les besoins et les préférences d'un sous-segment spécifique.
But comment transformer cela en un workflow fiable ? Et surtout, comment acheminer concrètement toutes ces variantes de contenu vers les clients ciblés à l'aide de nos technologies marketing existantes ? Dans cet article, nous continuons à développer le scénario du guide de cadeaux de Noël présenté dans le blog précédent et démontrons un workflow de bout en bout pour la diffusion de contenu par e-mail avec Amperity et Braze, deux plateformes largement adoptées dans la suite MarTech des entreprises.
Générer le contenu
Dans notre blog précédent, nous avons vu comment concevoir un prompt capable d'inciter un modèle d'IA générative à créer un e-mail marketing adapté aux intérêts d'un sous-segment d'audience. Le prompt utilisait un exemple d'e-mail comme guide, puis demandait au modèle de modifier le contenu pour qu'il résonne mieux auprès d'une audience ayant des sensibilités aux prix et des préférences d'activité spécifiques (Figure 1).
Figure 1. Le prompt développé pour la création d'un guide de cadeaux de Noël personnalisé
Pour appliquer ce prompt à grande échelle, nous devons supprimer les éléments spécifiques au client (comme la sous-catégorie de produits et les préférences de prix dans cet exemple) et insérer des espaces réservés (placeholders) là où ces éléments peuvent être injectés au besoin, créant ainsi un modèle de prompt. Les détails spécifiques au client peuvent ensuite être insérés dans le modèle de prompt (hébergé dans l'environnement Databricks) à l'aide des données clients stockées dans la plateforme de données clients (CDP).
Comme nous utilisons Amperity pour notre démonstration de CDP, l'intégration est un processus assez simple. Grâce à la fonctionnalité Amperity Bridge, construite à l'aide du protocole open source Delta Sharing pris en charge par l'environnement Databricks, nous créons simplement une connexion entre les deux plateformes et partageons les informations appropriées (Figure 2). (Les étapes détaillées de configuration de la connexion Bridge se trouvent ici.)
Figure 2. Une démonstration vidéo de la connexion à Databricks via Amperity Bridge
Notre étape suivante consiste à interroger les données stockées dans la CDP, accessibles dans Databricks, afin de recueillir les détails de chaque sous-segment. Une fois ceux-ci définis, nous pouvons transmettre les informations associées à chacun dans notre prompt pour générer des messages personnalisés. Une fois ces données persistées, nous pouvons itérer sur les résultats, en évaluant chaque message généré par rapport à différents critères avant que ce contenu et les résultats de l'évaluation ne soient présentés à un spécialiste du marketing pour révision finale et approbation (Figure 3).
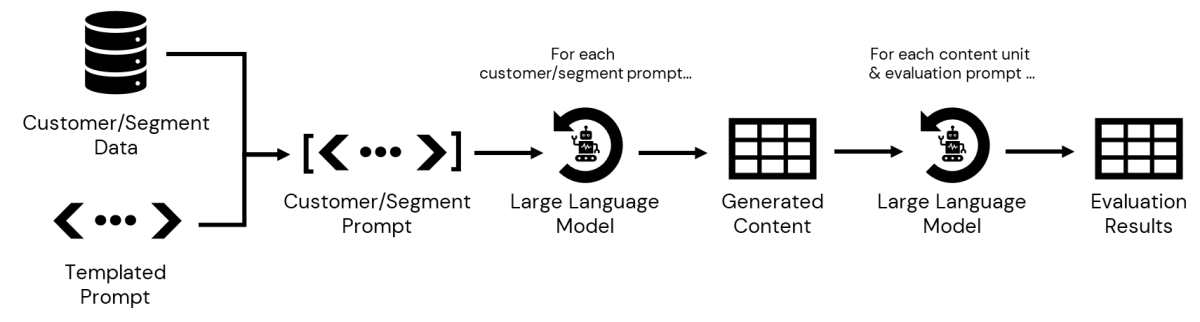
{kind=link}
Le résultat final de ce processus est un tableau de variantes de contenu, une pour chaque combinaison de niveau de prix préféré et de sous-catégorie de produits, ainsi qu'un tableau des résultats d'évaluation pour chaque étape d'évaluation. Les données sont maintenant prêtes à être examinées par le spécialiste du marketing.
REMARQUE Pour une implémentation technique détaillée du workflow de la Figure 3, veuillez consulter ce notebook.
Diffuser le contenu
Une fois nos variantes de contenu créées, nous pouvons nous intéresser à leur diffusion. Les détails exacts de cette étape dépendent de la plateforme de diffusion spécifique que vous utilisez. Pour notre démonstration, nous allons voir comment ce contenu peut être diffusé à l'aide de Braze, une plateforme d'engagement client de premier plan largement adoptée par les équipes marketing.
Dans les grandes lignes, les étapes de diffusion de ce contenu via Braze sont les suivantes :
- Envoyer les variantes de contenu vers Braze
- Identifier les membres de l'audience devant recevoir le contenu
- Associer les membres de l'audience à des variantes de contenu spécifiques
Envoyer les variantes de contenu vers Braze
Dans Braze, le contenu utilisé dans le cadre d'une campagne est défini comme un catalogue Braze. Grâce à la fonctionnalité Cloud Data Ingestion de Braze, ce contenu peut être lu depuis Databricks à condition qu'il soit présenté dans une table ou une vue contenant un identifiant unique (ID), un champ datetime indiquant la date de dernière mise à jour du contenu (UPDATED_AT) et un payload JSON (PAYLOAD) contenant les éléments de titre et de corps qui serviront à construire le contenu diffusé.
Pour illustrer la manière dont nous pourrions construire ce jeu de données, supposons que le résultat de notre workflow de génération de contenu (tel qu'illustré à la Figure 4) ait produit une table de contenu avec la structure suivante, où preferred_price_point et holiday_preferred_subcategory représentent les détails de sous-segment uniques à chaque enregistrement de la table :
Nous pouvons définir une vue sur cette table afin de la structurer pour un déploiement en tant que catalogue Braze comme suit :
Dans Braze, nous pouvons maintenant définir un catalogue pour ce contenu (Figure 3).
Figure 3. Le catalogue Braze destiné à héberger notre contenu généré
Nous configurons ensuite une synchronisation Cloud Data Ingestion (CDI), reliant la vue Databricks à la structure du catalogue Braze, et nous la configurons pour la synchronisation afin de garantir qu'elle reste à jour (Figure 4).
Figure 4. La synchronisation Cloud Data Ingestion (CDI) associant le catalogue Braze à la vue de contenu Databricks
Identifier les membres de l'audience
Nous avons maintenant besoin des détails concernant les personnes auxquelles nous prévoyons de diffuser ce contenu. Notre objectif étant de diffuser ce contenu par e-mail, nous aurons besoin des adresses e-mail des personnes ciblées. Des éléments tels que le prénom et le nom de famille peuvent également être nécessaires afin de s'adresser au destinataire de manière plus personnalisée. Nous aurons également besoin de détails sur la façon dont les individus s'alignent sur les sous-catégories de produits et les préférences de prix. Ce dernier élément sera essentiel pour associer les membres de l'audience aux variations de contenu spécifiques hébergées dans le catalogue Braze.
Puisque nous utilisons Amperity comme CDP, l'envoi de ces informations vers Braze consiste simplement à définir le groupe de destinataires en tant qu'audience et à utiliser le connecteur Amperity pour transférer ces détails (Figure 5).
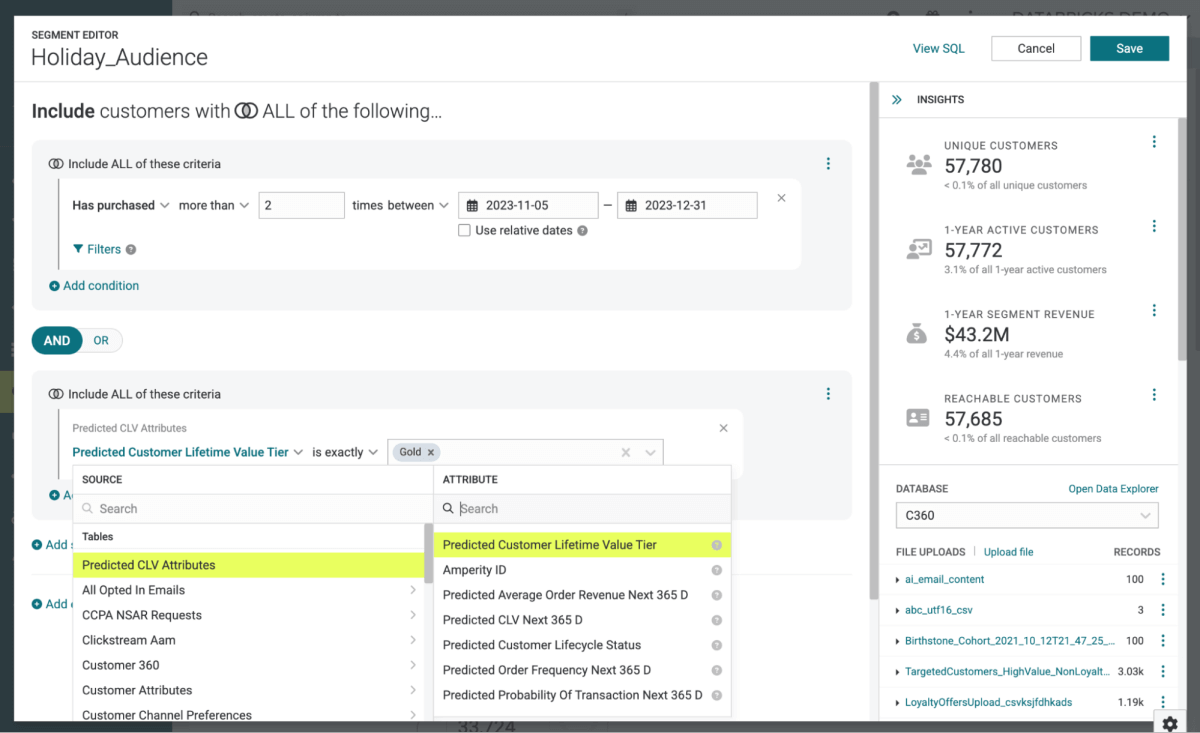
{kind=link}
Associer les membres de l'audience aux variantes de contenu
Une fois tous les éléments en place dans Braze, nous pouvons désormais associer les membres de l'audience à des variantes de contenu spécifiques et planifier la diffusion. Cela se fait dans Braze à l'aide de la création de modèles Liquid, un langage de gabarit open source développé par Shopify et écrit en Ruby. Ce langage est très accessible pour les marketeurs et leur permet de définir du contenu personnalisable pour une diffusion à grande échelle.
Prise en main
Databricks est de plus en plus utilisé au sein des entreprises comme le hub central pour les capacités de données et d'analytique. Grâce à des capacités d'IA générative intégrées et hautement extensibles, ainsi qu'à une intégration étroite avec diverses plateformes complémentaires telles que la CDP Amperity et la plateforme d'engagement client Braze, les organisations créent une large gamme d'applications, comme celle présentée dans ce blog, avec Databricks au centre.
Si vous souhaitez en savoir plus sur la façon dont Databricks peut aider vos équipes marketing à créer et à diffuser du contenu plus personnalisé à vos clients, contactez-nous pour discuter des nombreuses options disponibles pour développer des solutions à l'aide de la plateforme.
Ce processus s'appuie sur plusieurs composants clés et utilise le flux de travail suivant :
- Structure et ingestion du contenu
- Une vue est créée à partir de la table des variantes de contenu, structurée pour être utilisée par Braze Cloud Data Ingestion
- Un catalogue Braze est créé en tant que référentiel pour les variantes de contenu
- Une synchronisation Cloud Data Ingestion est configurée, et Braze synchronise les variantes de contenu de la vue vers le catalogue
- Activation de l'audience Amperity - Amperity synchronise l'audience des utilisateurs pour lesquels le contenu a été créé vers Braze pour un ciblage précis.
- Construction de campagne et création de modèles Liquid
- Le langage de création de modèles Liquid est utilisé pour référencer la ligne correspondante dans le catalogue des variantes de contenu.
- Liquid remplit dynamiquement l'objet et le corps de l'e-mail, personnalisés pour chaque utilisateur.
Étape 3 : Construction de campagne et création de modèles Liquid
La dernière étape consiste à créer la campagne Braze.
La création de modèles Liquid joue ici un rôle central, permettant l'insertion dynamique du contenu généré en fonction des attributs utilisateur stockés dans les profils Braze. Ces attributs, synchronisés via l'activation Amperity, sont référencés pour créer un ID de ligne de catalogue correspondant. Cet ID est ensuite utilisé pour récupérer et insérer l'objet et le corps de l'e-mail générés.
3a. Email Subject LineUsing Liquid filters, we combine the `preferred_price_point` and `holiday_preferred_subcategory` attributes, separated by an underscore, to create a local `identifier` variable:
Cet `identifier` généré dynamiquement est ensuite utilisé pour référencer l'ID correspondant dans le catalogue HolidayGenAI :
Figure 5. Capture d'écran des paramètres d'envoi avec Liquid
Pour un utilisateur ayant un `preferred_price_point` de type « high » et une `holiday_preferred_subcategory` de type « Hiking », le résultat Liquid obtenu dans l'objet de l'e-mail sera dérivé du titre de l'article de catalogue correspondant :
Figure 6. Article de catalogue montrant la ligne correspondante
3b. Corps de l'e-mail
Nous pouvons suivre la même approche pour intégrer le contenu généré dans le corps de l'e-mail.
Le résultat final est un e-mail qui extrait dynamiquement le contenu génératif, personnalisé selon le point de prix et la sous-catégorie préférés de chaque utilisateur, ce qui favorise un meilleur engagement et des taux de conversion plus élevés.
Figure 7. Capture d'écran de l'e-mail
Ce cas d'usage pourrait être étendu pour inclure l'ajout d'images génératives ou même l'utilisation de Connected Content pour interroger directement un endpoint Databricks au moment de l'envoi.
Pour une implémentation technique détaillée du flux de travail de la Figure 3, veuillez consulter ce notebook.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.