Les types de nœuds flexibles sont désormais disponibles pour tous
Améliorez la fiabilité du lancement des clusters et réduisez les coûts de compute avec le fallback automatique des instances
par Kelsey Ge, Andrew Bagshaw, Tianyi Zhang, Vedaant Shah, Rishan Girish et Hugh March
- Protégez les charges de travail contre les erreurs de capacité : lorsque votre type de VM préféré n'est pas disponible, Databricks se replie automatiquement sur des alternatives compatibles afin que les clusters puissent toujours se lancer.
- Bénéficiez d'une flexibilité de type Fleet sur tous les clouds : les types de nœuds flexibles apportent le fallback automatique sur d'autres types d'instances à Azure, GCP et AWS. Profitez d'une activation plus simple en "1 clic" à l'échelle du workspace, avec une visibilité claire sur les Ressources acquises et un fallback ordering configurable en option.
- Réduisez les dépenses sans sacrifier la fiabilité : donnez la priorité aux instances Spot à prix réduit lorsqu'elles sont disponibles, et ne vous repliez qu'en cas de besoin pour garantir le succès du lancement.
Obtenir une capacité de compute spécifique peut être difficile, en particulier pendant les périodes de fort trafic (et de forte pression). Les ingénieurs de données et les administrateurs de plateforme ne connaissent que trop bien la frustration liée aux erreurs de capacité insuffisante, ou "stockout", qui se produisent lorsque le lancement d'un cluster échoue parce qu'un fournisseur de cloud ne peut pas satisfaire une demande pour un type d'instance spécifique.
Que ce soit :
AWS_INSUFFICIENT_INSTANCE_CAPACITY_FAILURECLOUD_PROVIDER_RESOURCE_STOCKOUTsur Azure, ouGCP_INSUFFICIENT_CAPACITY,
Ces erreurs perturbent les charges de travail critiques, en particulier pendant les périodes critiques pour l'activité où la disponibilité est la plus importante.
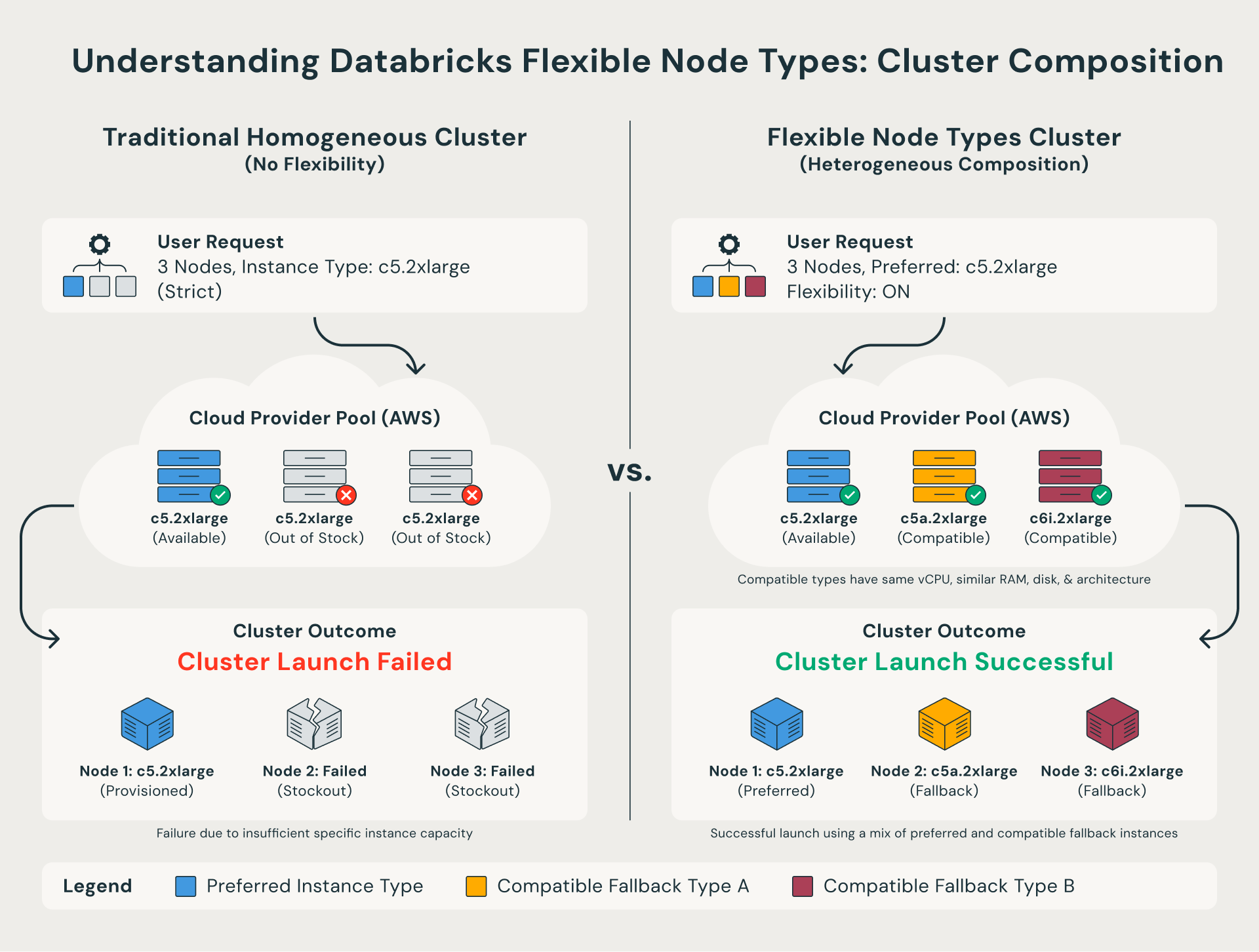
Que sont les types de nœuds flexibles ?
Traditionnellement, les clusters Databricks exigeaient que chaque nœud soit du type d'instance exact spécifié dans votre configuration. Si ce type spécifique n'était pas disponible, le lancement du cluster échouerait.
Les types de nœuds flexibles suppriment cette contrainte. Lorsqu'un type d'instance préférentiel n'est pas disponible, Databricks bascule automatiquement vers une alternative compatible qui partage la même forme de compute. En d'autres termes, le cluster se lance avec succès en utilisant un mélange de types d'instances similaires au lieu d'échouer complètement.
Pour les équipes qui ont besoin d'un contrôle plus strict, elles peuvent également définir une liste de fallback personnalisée via l'API, indiquant les types d'instance à essayer et dans quel ordre.
Avantages clés
Moins d'échecs de lancement de clusters pendant les pics de demande
Les types de nœuds flexibles réduisent à la fois la fréquence et la gravité des échecs liés à la capacité. Lorsqu'un fournisseur de cloud ne peut pas satisfaire le type d'instance préféré, Databricks se rabat automatiquement sur des alternatives compatibles, ce qui permet aux clusters de se lancer au lieu de générer une erreur.
Utilisation optimisée des instances Spot
Pour les clusters configurés avec l'option Spot-with-fallback, les types de nœuds flexibles tentent d'acquérir de la capacité Spot sur l'ensemble de la liste de fallback avant de revenir aux instances à la demande. Cela augmente la part du cluster qui s'exécute sur Spot, ce qui contribue à réduire les coûts de calcul tout en donnant la priorité à la réussite des lancements.
Visibilité claire et contrôle précis
Les équipes peuvent inspecter exactement quels types de nœuds sont acquis à l'aide de la table système node_timeline. De plus, un ordre de fallback personnalisé peut être défini via l'API, permettant un contrôle précis des coûts et du comportement des performances.
DÉMARRAGE RAPIDE
Les administrateurs de Workspace peuvent facilement activer la fonctionnalité dans les paramètres d'administration (Docs : AWS, Azure, GCP). À partir de là, la fonctionnalité s'applique immédiatement à tous les nouveaux lancements de clusters. Les clusters à longue exécution adopteront la fonctionnalité lors de leur prochain redémarrage, et les futurs clusters de jobs créés pour les jobs existants utiliseront automatiquement la fonctionnalité.
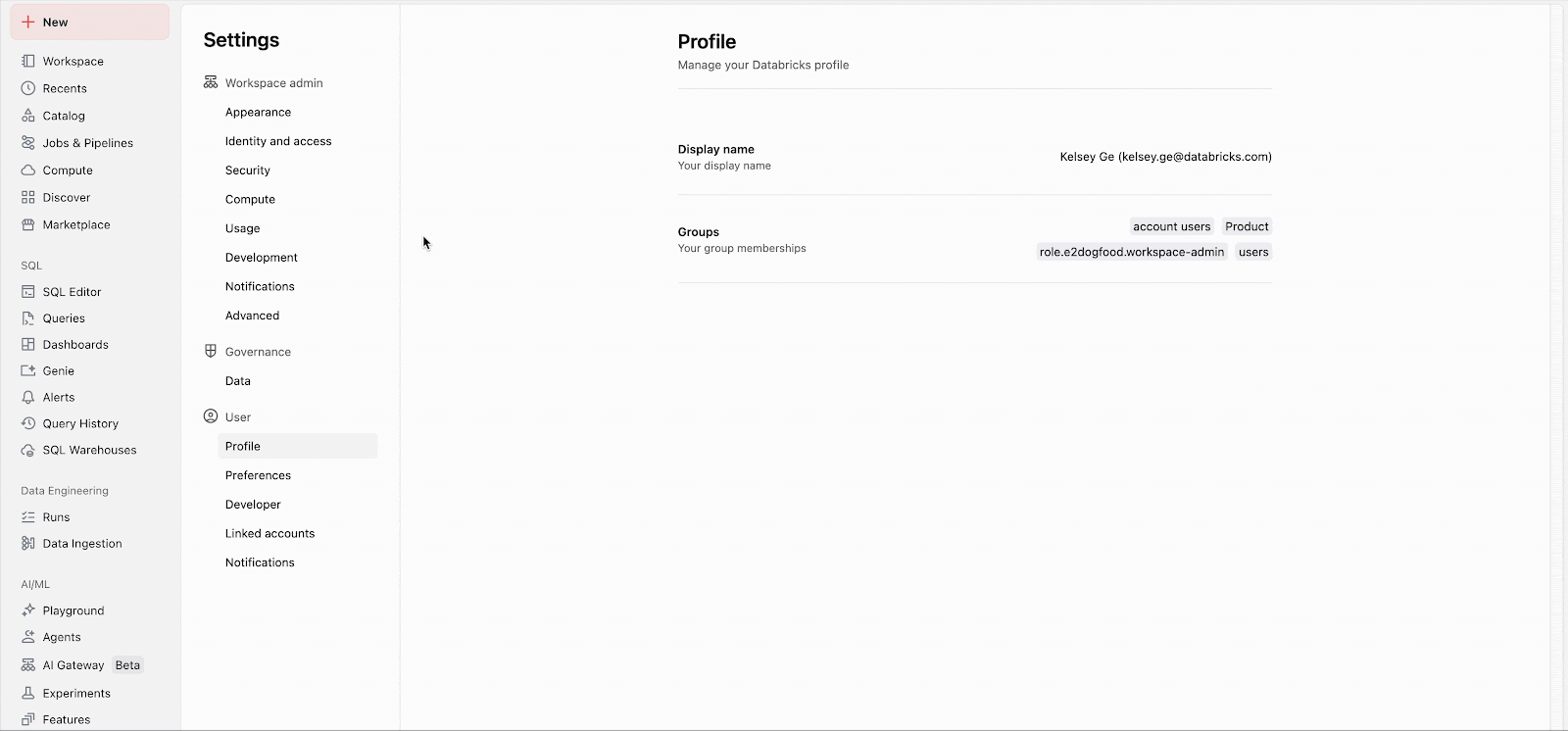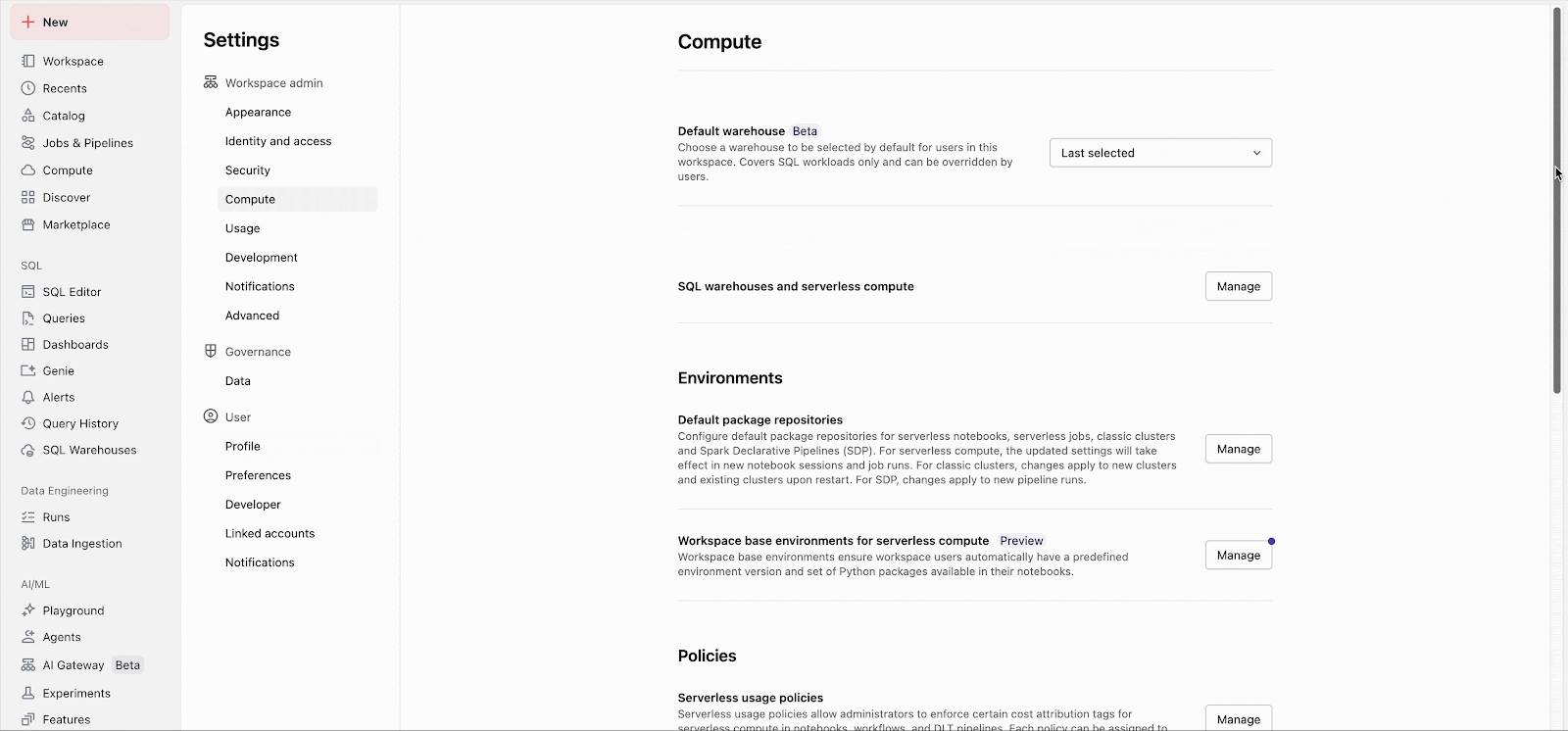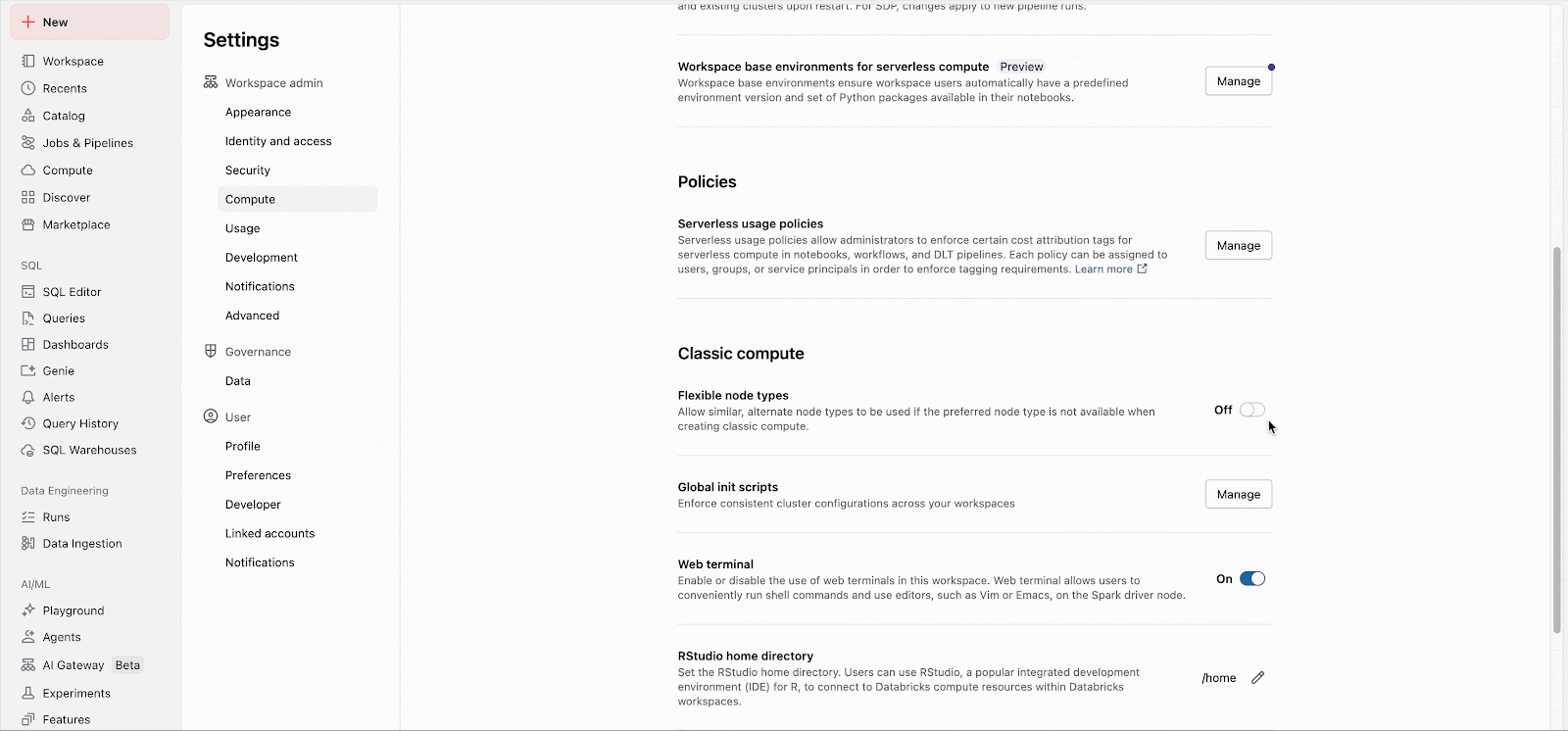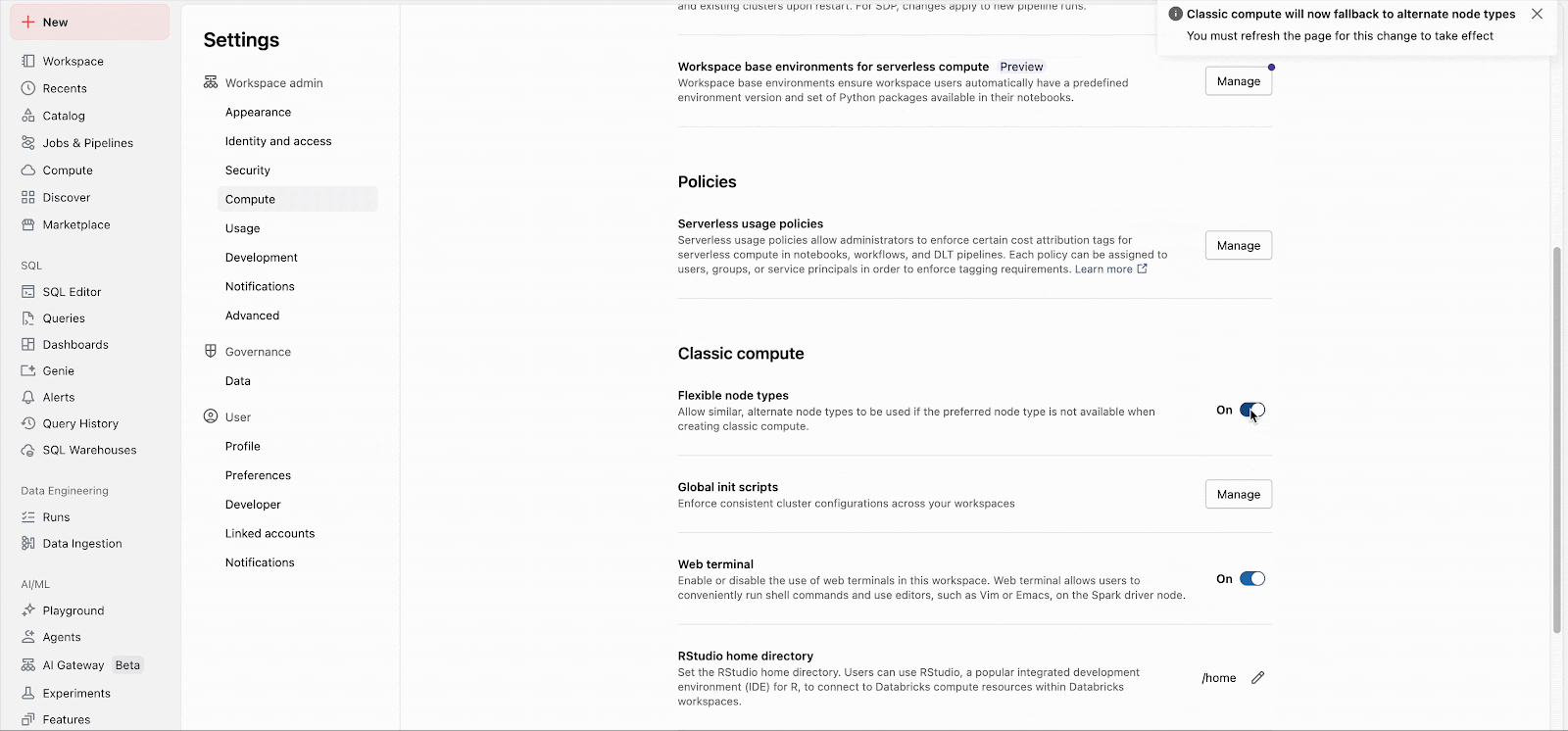
Des listes de fallback personnalisées peuvent être configurées via l'API, indépendamment du paramètre du workspace.
Détails supplémentaires
Veuillez consulter la documentation pour plus de détails sur la configuration des types de nœuds flexibles avec les pools d'instances, la facturation, les quotas de type de nœud et l'activation/désactivation sélective (Docs : AWS, Azure, GCP).
Les types de nœuds flexibles sont conçus pour rendre votre plateforme de données plus résiliente et plus rentable. Les administrateurs peuvent activer cette fonctionnalité en 1 clic dès aujourd'hui dans les paramètres d'administration du workspace en suivant les instructions de la documentation.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.