Prise en main de la personnalisation grâce au score de propension
par Tian Tan, Sam Steiny et Bryan Smith

Les consommateurs s'attendent de plus en plus à une approche personnalisée. Qu'il s'agisse d'un e-mail faisant la promotion de produits complémentaires à un achat récent, d'une bannière en ligne annonçant des soldes sur des articles d'une catégorie fréquemment consultée, ou d'un contenu adapté à leurs centres d'intérêt, les consommateurs ont l'embarras du choix pour dépenser leur argent. Ils préfèrent donc se tourner vers des enseignes qui reconnaissent leurs besoins et préférences uniques.
Une enquête récente de McKinsey montre que près des trois quarts des consommateurs s'attendent désormais à des interactions personnalisées lors de leur parcours d'achat. L'étude associée à cette enquête souligne que les entreprises qui réussissent dans ce domaine peuvent générer 40 % de revenus supplémentaires grâce à des engagements personnalisés, faisant de la personnalisation un facteur clé de différenciation pour les leaders de la vente au détail.
Pourtant, de nombreux détaillants éprouvent des difficultés à mettre en œuvre la personnalisation. Une enquête récente de Forrester révèle que seulement 30 % des consommateurs aux US et 26 % au UK estiment que les détaillants réussissent à leur proposer des expériences pertinentes. Dans une autre enquête menée par 3radical, seulement 18 % des personnes interrogées ont affirmé recevoir des recommandations personnalisées, tandis que 52 % ont exprimé leur frustration face à des communications et des offres non pertinentes. Alors que les consommateurs sont de plus en plus enclins à changer de marque ou d'enseigne, réussir sa stratégie de personnalisation est devenu une priorité pour un nombre croissant d'entreprises.
La personnalisation est un parcours
Pour une entreprise qui débute dans la personnalisation, l'idée de proposer des interactions individuelles (one-to-one) peut sembler intimidante. Comment surmonter les processus cloisonnés, une mauvaise gouvernance des données et les préoccupations liées à la confidentialité pour rassembler les données nécessaires à cette approche ? Comment concevoir des contenus et des messages véritablement personnalis�és avec des ressources marketing limitées ? Comment s'assurer que le contenu créé cible efficacement des personnes dont les besoins et les préférences évoluent constamment ?
Bien que la majeure partie de la littérature sur la personnalisation mette en avant des approches de pointe qui se distinguent par leur nouveauté (mais pas toujours par leur efficacité), la réalité est que la personnalisation est un parcours de longue haleine. Dans les premières phases, l'accent est mis sur l'exploitation des données de première partie (first-party), pour lesquelles la confidentialité et la confiance des clients sont plus faciles à préserver. Des techniques prédictives assez standards sont appliquées pour mettre en œuvre des capacités éprouvées. À mesure que la valeur est démontrée et que l'entreprise se familiarise avec ces nouvelles techniques ainsi qu'avec leurs différents modes d'intégration, des approches plus sophistiquées sont alors déployées.
Le scoring de propension est souvent une première étape vers la personnalisation
L'une des premières étapes de ce parcours consiste souvent à analyser les données de vente pour comprendre les préférences individuelles des clients. Grâce à un processus appelé scoring de propension, les entreprises peuvent estimer la réceptivité potentielle d'un client à une offre ou à un contenu lié à une sélection de produits. À l'aide de ces scores, les équipes marketing peuvent déterminer quel message, parmi tous ceux disponibles, doit être présenté à un client spécifique. De même, ces scores permettent d'identifier des segments de clients plus ou moins réceptifs à une forme d'engagement particulière.
Le point de départ de la plupart des exercices de scoring de propension est le calcul d'attributs numériques (caractéristiques) à partir des interactions passées. Ces caractéristiques peuvent inclure la fréquence d'achat d'un client, le pourcentage de dépenses associé à une catégorie de produits spécifique, le nombre de jours écoulés depuis le dernier achat, et bien d'autres indicateurs issus des données historiques. La période historique qui suit immédiatement celle ayant servi au calcul de ces caractéristiques est ensuite analysée pour y détecter des comportements d'intérêt, comme l'achat d'un produit dans une catégorie spécifique ou l'utilisation d'un bon de réduction. Si le comportement est observé, une étiquette (label) de valeur 1 est associée aux caractéristiques. Dans le cas contraire, une étiquette de valeur 0 est attribuée.
En utilisant ces caractéristiques comme variables prédictives des étiquettes, les data scientists peuvent entraîner un modèle pour estimer la probabilité que le comportement d'intérêt se produise. En appliquant ce modèle entraîné aux caractéristiques calculées pour la période la plus récente, les équipes marketing peuvent estimer la probabilité qu'un client adopte ce comportement dans un avenir proche.
Disposant de nombreuses offres, promotions, messages et autres contenus, plusieurs modèles, prédisant chacun un comportement différent, sont entraînés et appliqués à ce même ensemble de caractéristiques. Un profil par client, composé des scores pour chacun des comportements d'intérêt, est compilé puis publié vers les systèmes en aval afin d'être utilisé par le marketing pour orchestrer les différentes campagnes.
Databricks offre des fonctionnalités essentielles pour le scoring de propension
Bien que le scoring de propension semble simple en apparence, il comporte son lot de défis. Lors de nos échanges avec des détaillants qui mettent en œuvre le scoring de propension, nous rencontrons souvent les trois mêmes questions :
- Comment gérer et maintenir les centaines, voire les milliers de caractéristiques que nous utilisons pour entraîner nos modèles de propension ?
- Comment entraîner rapidement des modèles adaptés aux nouvelles campagnes que l'équipe marketing souhaite lancer ?
- Comment redéployer rapidement dans le pipeline de scoring des modèles réentraînés à mesure que les comportements des clients évoluent ?
Chez Databricks, notre objectif est de donner les moyens à nos clients de réussir grâce à une plateforme d'analyse conçue pour répondre aux besoins de bout en bout de l'entreprise. À cette fin, nous avons intégré à notre plateforme des fonctionnalités telles que le Feature Store, AutoML et MLflow, qui peuvent toutes être utilisées pour relever ces défis dans le cadre d'un processus robuste de scoring de propension.
Feature Store
Le Databricks Feature Store est un référentiel centralisé qui permet de conserver, de découvrir et de partager des caractéristiques (features) à travers différents entraînements de modèles. À mesure que les caractéristiques sont enregistrées, leur traçabilité (lineage) et d'autres métadonnées sont capturées afin que les data scientists souhaitant réutiliser des caractéristiques créées par d'autres puissent le faire en toute confiance et simplicité. Des modèles de sécurité standards garantissent que seuls les utilisateurs et processus autorisés peuvent utiliser ces caractéristiques, permettant ainsi de gérer les processus de data science conformément aux politiques d'accès aux données de l'entreprise.
AutoML
Databricks AutoML vous permet de générer rapidement des modèles en vous appuyant sur les meilleures pratiques du secteur. En tant que solution transparente (glass box), AutoML génère d'abord un ensemble de notebooks représentant différentes variantes de modèles adaptées à votre scénario. Tout en entraînant de manière itérative les différents modèles pour déterminer celui qui fonctionne le mieux avec votre jeu de données, il vous permet d'accéder aux notebooks associés à chacun d'eux. Pour de nombreuses équipes de data science, ces notebooks deviennent un point de départ modifiable pour explorer d'autres variantes de modèles, ce qui leur permet d'aboutir à un modèle entraîné répondant parfaitement à leurs objectifs.
MLflow
MLflow est un registre de modèles de machine learning open source, géré au sein de la plateforme Databricks. Ce registre permet à l'équipe de data science de suivre et d'analyser les différentes itérations de modèles générées à la fois par AutoML et par des cycles d'entraînement personnalisés. Ses fonctionnalités de gestion des flux de travail permettent aux entreprises de passer rapidement des modèles entraînés du développement à la production, afin qu'ils puissent avoir un impact immédiat sur les opérations.
Lorsqu'ils sont utilisés en combinaison avec le Databricks Feature Store, les modèles conservés avec MLflow gardent en mémoire les caractéristiques utilisées lors de l'entraînement. Lors de la récupération des modèles pour l'inférence, cette même information permet au modèle de récupérer les caractéristiques pertinentes depuis le Feature Store, ce qui simplifie considérablement le flux de travail de scoring et permet un déploiement rapide.
Créer un flux de travail de scoring de propension
En combinant ces fonctionnalités, nous constatons que de nombreuses entreprises mettent en œuvre le scoring de propension dans le cadre d'un flux de travail en trois parties. Dans la première partie, les ingénieurs de données collaborent avec les data scientists pour définir les caractéristiques pertinentes pour l'exercice de scoring de propension et les enregistrer dans le Feature Store. Des processus d'ingénierie des caractéristiques (feature engineering) quotidiens ou en temps réel sont ensuite définis pour calculer des valeurs de caractéristiques à jour au fur et à mesure de l'arrivée de nouvelles données.
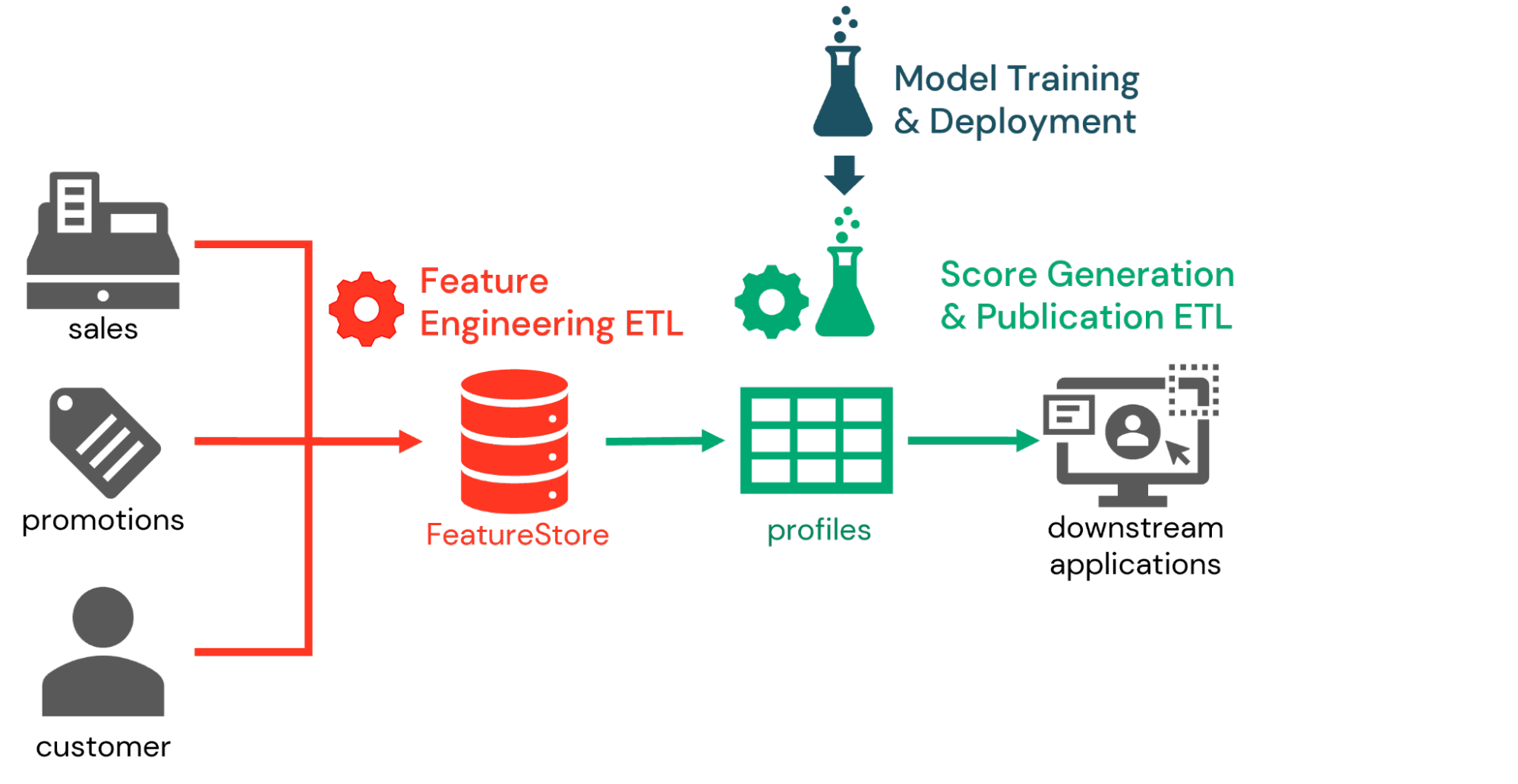
Ensuite, dans le cadre du workflow d'inférence, les identifiants des clients sont soumis à des modèles préalablement entraînés afin de générer des scores de propension basés sur les dernières caractéristiques (features) disponibles. Les informations du Feature Store capturées avec le modèle permettent aux ingénieurs de données de récupérer ces features et de générer facilement les scores souhaités. Ces scores peuvent être conservés pour analyse au sein de la plateforme Databricks, mais ils sont plus généralement publiés vers des systèmes marketing en aval.
Enfin, dans le workflow d'entraînement des modèles, les data scientists réentraînent périodiquement les modèles de scoring de propension pour capturer les changements de comportement des clients. Comme ces modèles sont conservés dans MLflow, des processus de gestion du changement sont utilisés pour évaluer les modèles et promouvoir vers l'état de production ceux qui répondent aux critères de l'organisation. Lors de la prochaine itération du workflow d'inférence, la dernière version en production de chaque modèle est récupérée pour générer les scores des clients.
Pour démontrer comment ces fonctionnalités s'articulent, nous avons conçu un workflow de scoring de propension de bout en bout basé sur un ensemble de données public. Ce workflow illustre les trois étapes du processus décrit ci-dessus et montre comment utiliser les fonctionnalités clés de Databricks pour concevoir un pipeline de scoring de propension efficace.
Téléchargez les ressources ici et utilisez-les comme point de départ pour poser les bases de votre propre stratégie de personnalisation à l'aide de la plateforme Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.