Attribution granulaire de l'utilisation pour les pipelines dbt avec des balises de requête
Balisez, suivez et optimisez chaque modèle dbt — de l'attribution des coûts et du débogage des performances à la surveillance de l'environnement — avec une seule ligne de configuration ou Genie.
par Heeren Sharma, Lennart Reschke et JooHo Yeo
- Marquez chaque requête dbt avec l'équipe, le centre de coûts, le projet et l'environnement — sans aucune modification de code de vos modèles SQL
- Interrogez system.query.history pour voir exactement quels modèles dbt coûtent le plus cher et où le temps de calcul est consommé
- Déployez un projet de référence complet avec les Declarative Automation Bundles : pipeline dbt, tableau de bord analytique Query Tag et job planifié — le tout à partir d'un seul dépôt GitHub
Votre projet dbt exécute 80 modèles chaque nuit. La facture de l'entrepôt a doublé le trimestre dernier. Les performances des modèles varient considérablement, et les effets des optimisations les plus récentes ne sont pas clairs. Le service financier demande quelle équipe est responsable. Vous ouvrez l'historique des requêtes et vous voyez... 80 lignes identiques étiquetées 'Databricks Dbt.' Bonne chance.
Avec Query Tags (désormais en Public Preview), les équipes de données peuvent désormais bénéficier de balises injectées automatiquement et prêtes à l'emploi, telles que dbt_model_name, qui enrichissent chaque exécution. Vous pouvez également associer vos propres balises personnalisées — équipe, centre de coûts, environnement, etc. — à chaque requête générée par votre pipeline.
Les balises sont enregistrées dans system.query.history, ce qui permet d'attribuer les coûts, de déboguer les performances et de surveiller la charge de travail à l'aide d'une simple requête SQL (tous les détails dans la documentation).
Ce blog présente un projet dbt open source complet qui illustre l'utilisation des Query Tags de bout en bout : de la configuration aux tableaux de bord d'attribution des coûts. Tout ce qui est décrit ici est disponible sous la forme d'un dépôt GitHub que vous pouvez cloner et déployer dans votre propre espace de travail, ou simplement demander à Genie.
Comment dbt-databricks s'intègre aux Query Tags
L'adaptateur dbt-databricks (version 1.11+) prend en charge nativement les Query Tags. Les balises peuvent être appliquées à trois niveaux, chacun s'appuyant sur le précédent :
Balises injectées automatiquement
En plus de vos balises personnalisées, dbt-databricks injecte automatiquement des métadonnées sur chaque exécution de modèle :
Balise | Exemple de valeur | Description |
@@dbt_model_name | fct_daily_usage_by_sku | Le modèle dbt en cours d'exécution |
@@dbt_materialized | table | Stratégie de matérialisation (table, view, incremental, metric_view) |
@@dbt_core_version | 1.11.6 | version de dbt-core |
@@dbt_databricks_version | 1.12.0a1 | version de l'adaptateur dbt-databricks |
Ces balises automatiques vous permettent d'obtenir une visibilité par modèle sans aucune configuration — l'adaptateur s'en charge pour vous.
Balises au niveau du profil
L'approche la plus simple : ajoutez un champ query_tags à une cible spécifique dans votre profil dbt. Chaque requête du projet hérite automatiquement de ces balises.
Par exemple, cette seule ligne attribue à chaque requête quatre dimensions : son propriétaire (team), la destination des coûts (cost_center), le pipeline auquel elle appartient (project_name) et l'environnement dans lequel elle s'exécute (env).
Balises au niveau du modèle
Pour une attribution plus précise, vous pouvez fournir des balises sur des modèles spécifiques dans dbt_project.yml ou dans la configuration du modèle dans sa définition sql.
Les balises au niveau du modèle fusionnent avec les balises au niveau du profil. Si les deux définissent la même clé, la valeur au niveau du modèle est prioritaire.
Où apparaissent les balises – system.query.history
Après avoir exécuté dbt run, chaque instruction SQL apparaît dans system.query.history avec la colonne query_tags renseignée sous la forme d'un MAP. Vous pouvez l'interroger à l'aide de la syntaxe d'accès standard aux maps :
Cela renvoie toutes les requêtes balisées des 7 derniers jours, avec les balises personnalisées et injectées automatiquement extraites dans des colonnes individuelles — prêtes pour l'agrégation.
Vous pouvez également trouver les Query Tags pour la requête que vous avez exécutée dans l'UI Query History ou l'UI SQL Warehouse Monitoring.

En bas à droite du Query Profile, vous verrez les Query Tags que vous avez définis, vous fournissant toutes les informations nécessaires en un coup d'œil.

Attribution des coûts avec les Query Tags
Les Query Tags permettent de déterminer une attribution précise de l'utilisation directement via des requêtes SQL, éliminant ainsi le besoin d'analyser manuellement les journaux ou de diviser les ressources de l'entrepôt.
Quels modèles dbt consomment le plus de ressources d'entrepôt ?
Vous pouvez y répondre de deux manières : demander à Genie en langage naturel pour une exploration ad hoc ou écrire vous-même le code SQL pour obtenir un résultat reproductible et prêt pour un tableau de bord. Les deux méthodes lisent les mêmes données system.query.history .
Option 1 : Genie

Genie écrit et exécute la requête équivalente, et vous pouvez continuer à approfondir avec des questions de suivi sans toucher au code SQL.
Option 2 : SQL
Les deux approches mènent au même résultat. Dans notre projet de référence, les quatre tables mart (matérialisées sous forme de table) dominent le temps de calcul, tandis que les vues de staging et les vues de métriques sont presque instantanées. Cela vous indique immédiatement où concentrer vos efforts d'optimisation.

Créer un tableau de bord d'autosurveillance
Notre projet de référence comprend un tableau de bord AI/BI qui interroge system.query.history filtré par les propres balises de requête du projet. Résultat : le pipeline qui analyse les données de facturation suit également ses propres coûts — utilisant ainsi ses propres Query Tags.
Le tableau de bord comprend :
- KPIs : Nombre total de requêtes balisées, total des secondes de calcul, modèles dbt distincts
- Activité quotidienne : Nombre de requêtes et temps de calcul par jour, répartis par environnement
- Répartition par modèle : Temps de calcul par modèle, coloré par type de matérialisation
- Répartition des matérialisations : Graphique en secteurs montrant comment le calcul se répartit entre table, view et metric_view
- Tableau de détail des requêtes : Chaque requête balisée avec le modèle, la durée, l'environnement et l'exécuteur
Dans notre projet de référence, les quatre modèles de mart représentaient 92 % du temps de calcul — sans les Query Tags, cette information était invisible.
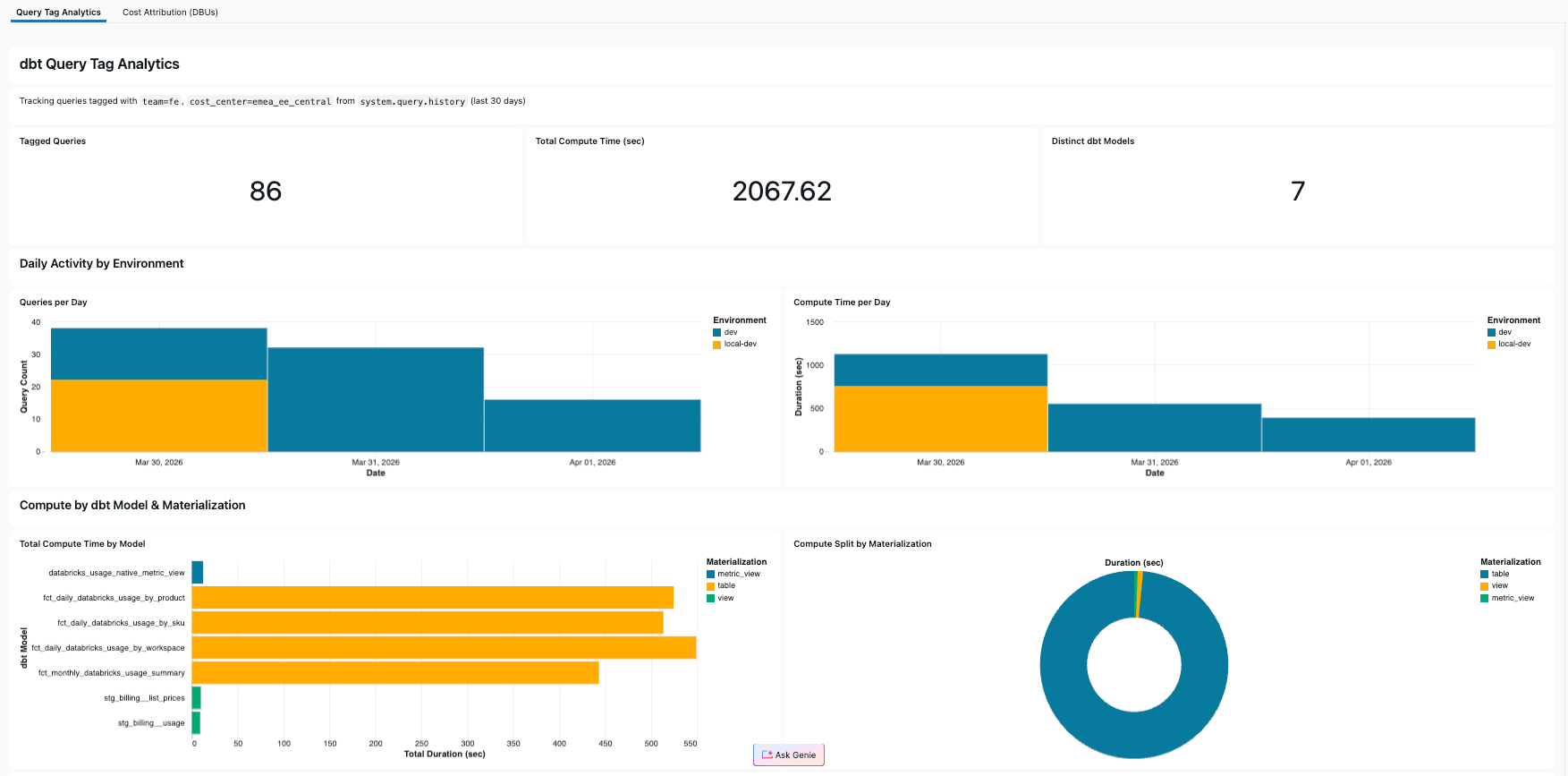
Créer vous-même ce tableau de bord ne prend que quelques minutes avec Genie Code : demandez-lui le temps de calcul par modèle dbt à partir de system.query.history filtré par vos balises de requête, et il rédigera le SQL et assemblera les visuels. Si vous préférez passer directement au résultat final, le tableau de bord est également inclus dans le projet de référence et se déploie avec une seule commande databricks bundle deploy aux côtés de la tâche dbt (voir le dépôt GitHub pour le guide détaillé).
Balisage des metric views
Les metric views Databricks (disponibles avec dbt-databricks 1.12+) sont un nouveau type de matérialisation qui définit des sémantiques métier réutilisables sous forme de dimensions et de mesures directement dans Unity Catalog (voir la documentation complète). Elles peuvent porter des Query Tags comme n'importe quel autre modèle, en utilisant le paramètre de configuration query_tags :
Notez la distinction : query_tags sont associés aux requêtes SQL qui créent ou actualisent la metric view (suivies dans system.query.history), tandis que databricks_tags sont des balises Unity Catalog sur l' objet lui-même (pour la gouvernance et la découverte). Le premier sert au suivi au niveau de la requête, tandis que le second se situe au niveau de l'objet Unity Catalog pour la découvrabilité globale des données.
Bonnes pratiques pour le balisage des projets dbt
Dans cet article, nous avons abordé le processus global pour mettre en place une pratique FinOps solide où les Query Tags sont fondamentaux pour l'attribution des coûts. Voici ce que nous avons appris en développant le projet de référence et en échangeant avec des utilisateurs expérimentés de dbt :
- Utilisez une hiérarchie de balises cohérente. Définissez des balises à l'échelle de l'organisation au niveau du profil (team, cost_center, project_name, env) et réservez les balises au niveau du modèle pour les cas exceptionnels. Cela permet de garder les balises prévisibles et d'éviter la prolifération des configurations par modèle.
- Balisez toujours l'environnement. Utilisez différentes valeurs env pour le développement local (local-dev) et les tâches déployées (dev, staging, prod). Cela vous permet de séparer les requêtes de développement ad hoc des exécutions de production planifiées dans vos analyses. Dans notre projet de référence, le profil local définit "env": "local-dev" tandis que le profil déployé définit "env": "dev".
- Utilisez `project_name` pour distinguer les pipelines. Lorsque plusieurs projets dbt partagent un entrepôt, project_name vous permet d'attribuer les coûts par pipeline sans diviser les entrepôts. Associé à l'injection automatique de @@dbt_model_name, vous bénéficiez d'une traçabilité complète : projet → modèle → matérialisation.
- Ne surchargez pas de balises. Les balises injectées automatiquement couvrent déjà le nom du modèle, le type de matérialisation et les versions de l'adaptateur. Vous avez rarement besoin de dupliquer ces informations dans des balises personnalisées. Concentrez les balises personnalisées sur le contexte métier que dbt ne peut pas déduire : l'équipe propriétaire, le centre de coûts, l'identité du projet.
- Balisez explicitement les metric views. Puisque les metric views sont une matérialisation plus récente, il est utile de les baliser avec une clé de fonctionnalité (par exemple, "feature": "metric_view") afin de pouvoir facilement filtrer les requêtes de création de metric views dans votre analyse des coûts.
Essayez par vous-même
Le projet de référence complet est disponible sur GitHub : github.com/databricks-solutions/dbt-query-tags
Pour commencer :
- Clonez le dépôt
- Créez un environnement virtuel Python 3.12 et installez les dépendances : pip install dbt-databricks>=1.12.0a1
- Mettez à jour profiles.yml avec l'hôte de votre espace de travail, le chemin HTTP du SQL warehouse, le catalogue et les balises de requête personnalisées
- Exécutez dbt deps && dbt run --profiles-dir . pour lancer le pipeline
- Interrogez system.query.history pour voir vos balises en action
- Mettez à jour dbt_profiles/profiles.yml et databricks.yml pour pointer vers la configuration correcte.
- Déployez avec databricks bundle deploy pour les exécutions planifiées et le tableau de bord d'analyse
Remplacez ces valeurs par celles de votre propre équipe et centre de coûts. Ce modèle fonctionne pour n'importe quel projet dbt sur Databricks.
Clonez le dépôt dès aujourd'hui ! Une seule ligne dans votre profil suffit pour débloquer la visibilité sur l'attribution de l'utilisation au niveau du modèle dans l'ensemble de votre entrepôt.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.