Comment les ontologies aident le nucléaire à monter en charge pour répondre à la demande énergétique mondiale
Rendre les connaissances implicites des usines explicites et interrogeables pour une flotte qui se prépare à quadrupler.
par Dave Geyer, Mark Ghattas, Alex Hunt, Ben Mumma et Mark Gilbert
- Le parc nucléaire est en pleine expansion pour atteindre 400 GW, avec des délais d'autorisation resserrés. Le contexte de l'installation que possède le personnel expérimenté doit être capturé sous une forme qui évolue avec lui.
- Une ontologie encode l'identité des composants, les relations du système et les sources de contraintes dans une couche structurée qui persiste lors des pannes, des modifications et des transitions de personnel.
- Construite sur Databricks avec des standards ouverts, l'ontologie prend en charge le contrôle de configuration, les preuves de licence et l'analytique à partir de données régies, versionnées et auditables.
Les réacteurs nucléaires comptent parmi les systèmes d'ingénierie les plus complexes que nous exploitons en Monter en charge. Une Opération sûre et fiable dépend d'une physique étroitement couplée, de barrières techniques, d'équipements rotatifs, de systèmes de fluides et d'une logique de commande qui doit se comporter correctement en fonctionnement normal et face à une longue liste de défaillances crédibles.
Considérez le scénario suivant : Une vanne d'eau d'alimentation se ferme de manière inattendue. En quelques secondes, un ingénieur doit savoir quels systèmes en aval perdent leur marge en premier, quelles limites des spécifications techniques deviennent pertinentes et si la configuration actuelle de la centrale affecte ses options. Les données permettant de répondre à ces questions existent dans une douzaine de systèmes. Les relations qui donnent un sens aux données se trouvent dans la tête du personnel expérimenté.
Le fossé entre les données disponibles et les connaissances exploitables définit l'un des principaux défis actuels des opérations des centrales nucléaires. Une ontologie comble cette lacune en rendant les relations de l'installation explicites, interrogeables et défendables.
Les États-Unis entrent dans une « renaissance nucléaire » inédite depuis des décennies. À partir de 2024, une vague de lois et d'actions des dirigeants a créé des conditions favorables pour que l'énergie nucléaire alimente tout, des installations de sécurité nationale aux demandes énergétiques massives de la course à l'IA. La loi ADVANCE a modernisé le processus d'autorisation de la Commission de réglementation nucléaire américaine (NRC), a réduit les frais et a chargé la Commission d'évaluer les friches industrielles, telles que d'anciennes centrales à charbon, pour de nouvelles constructions. Le décret (EO) 14300 est allé plus loin, modifiant fondamentalement la mission de la NRC qui passe de la minimisation des risques à la prise en compte des avantages de l'énergie nucléaire pour la sécurité économique et nationale, et réduisant le processus d'autorisation actuel de 42 mois en moyenne à un délai contraignant de 18 mois pour les nouveaux réacteurs. Le décret 14302 a invoqué la loi sur la production de défense (DPA) pour redynamiser la base industrielle nucléaire nationale, en se concentrant sur les chaînes d'approvisionnement en combustible et le redémarrage des centrales fermées. Le décret 14299 a explicitement lié le déploiement du nucléaire avancé à la demande des centres de données d'IA, les désignant comme des installations de défense critiques devant être alimentées par des réacteurs sur site. Parallèlement, le ministère américain de l'Énergie (DOE) a financé à hauteur de milliards de dollars des entreprises nucléaires américaines pour accélérer les progrès des centrales existantes et aider au démarrage de nouveaux acteurs construisant des petits réacteurs modulaires (SMR).
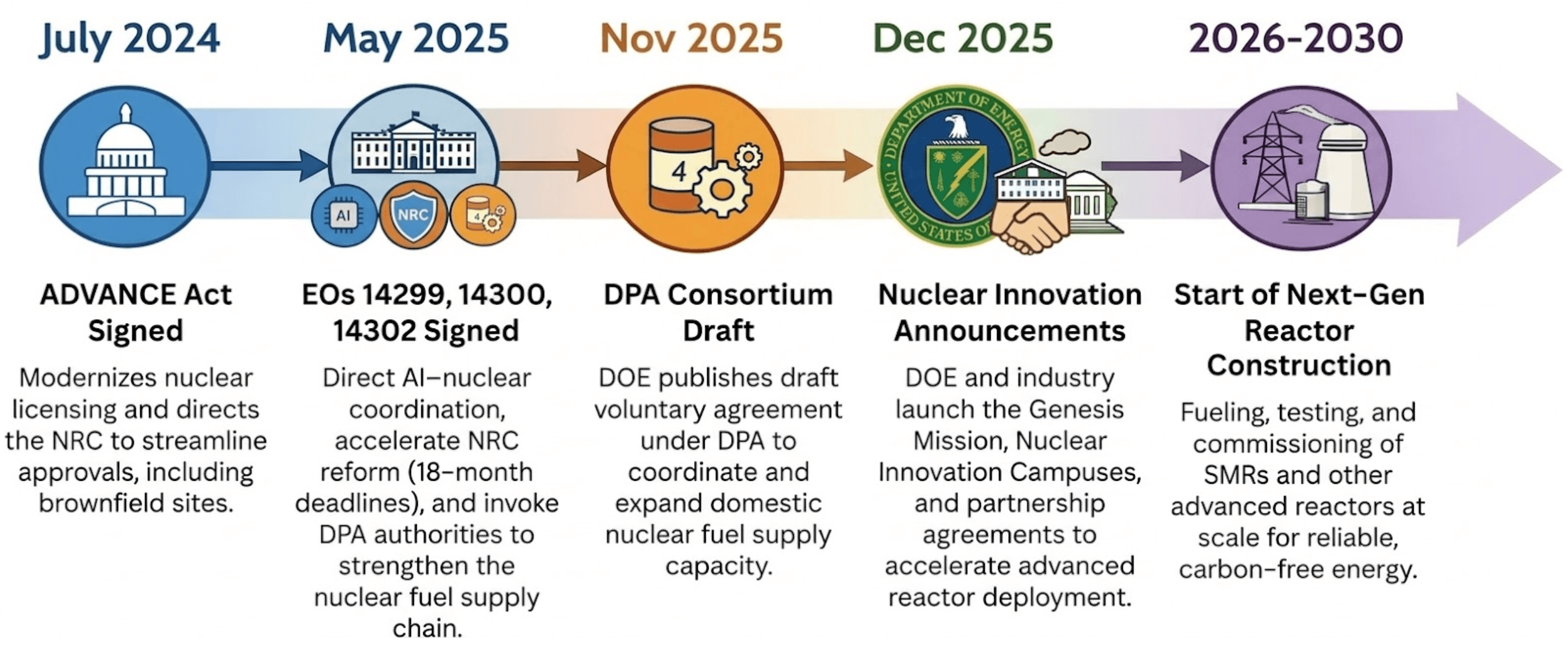
Cette expansion survient alors que les effectifs évoluent en sens inverse. Le nombre de personnes disponibles pour élaborer et défendre les dossiers de demande de licence diminue d'environ 10 % par an, et cette même pression s'étend bien au-delà de la procédure d'autorisation. Les nouvelles conceptions, les augmentations de puissance, les travaux de prolongation de la durée de vie et les mises à niveau digitales reposent tous sur la même chaîne de raisonnement : quel équipement est pris en compte, quelles contraintes s'appliquent dans la configuration actuelle et quelles sources contrôlées appuient la conclusion. Cette chaîne se retrouve dans chaque phase du cycle de vie de la centrale, de la conception aux opérations quotidiennes, en passant par la mise en service. Aujourd'hui, elle dépend encore en grande partie des personnes qui en sont responsables.
Le coût des connaissances implicites
Les opérateurs et ingénieurs expérimentés possèdent des modèles mentaux remarquables de leurs installations. Lorsqu'un opérateur de réacteur principal constate une augmentation des vibrations sur une pompe de circulation d'eau, il associe immédiatement ce signal au rôle de la pompe dans la configuration actuelle, aux modes de défaillance connus pour cette classe d'équipement, à l'historique des travaux récents et aux conséquences attendues si la situation s'aggrave. Il sait quelles indications concordantes sont importantes, lesquelles sont trompeuses et quelles questions poser ensuite.
Ce modèle mental représente des décennies de contexte accumulé. Il représente également une vulnérabilité.
L'Agence internationale de l'énergie atomique (AIEA) prévoit que la capacité nucléaire mondiale pourrait atteindre 992 GWe d'ici 2050, soit environ 2,6 fois les niveaux actuels. Qui dit nouvelles constructions dit nouvelles conceptions, plus d'instrumentation et plus d'états de configuration que les opérateurs et les ingénieurs doivent comprendre. Parallèlement, les données sur la main-d'œuvre du DOE montrent que le personnel expérimenté se concentre dans les tranches d'âge les plus élevées. Les personnes qui possèdent les connaissances les plus approfondies sur les centrales partent à la retraite, emportant avec elles leurs modèles mentaux.
Bien que le personnel plus récent apporte des aptitudes techniques, il manque souvent d'exposition aux signatures de défaillance spécifiques au site et aux configurations historiques. Pour optimiser les opérations d'une centrale, le personnel nouveau et existant a besoin d'un accès direct à des données empiriques précises et à jour. Cet accès permet au personnel de prendre des décisions éclairées. Assurer la disponibilité de ces données soutient les objectifs énergétiques du DOE en préparant le personnel à gérer des conceptions à haute instrumentation.
La manière dont les centrales nucléaires gèrent les connaissances aujourd'hui a fonctionné. Elle a permis au parc nucléaire américain de fonctionner en toute sécurité pendant des décennies. Les ingénieurs qui portent le contexte de la centrale dans leur tête ne sont pas le problème à résoudre, mais un asset à préserver et à développer. La préservation ne suffit pas lorsque le mandat passe du maintien de 100 GW à 400 GW. L'approche actuelle ne peut pas évoluer à la vitesse requise par le parc aujourd'hui. Non pas parce qu'elle est mauvaise, mais parce qu'elle a été conçue pour un rythme différent.
Une ontologie qui comble le fossé
L'industrie nucléaire a reconnu ce problème, et plusieurs organisations y travaillent déjà. L'Idaho National Laboratory a développé DeepLynx, un framework d'intégration open source conçu pour connecter les outils de Data Engineering et préserver le contexte tout au long du cycle de vie. Leur initiative DIAMOND a développé des structures de données spécifiquement pour les données de conception et d'exploitation nucléaires. ISO 15926 et IEC 81346 ont établi des cadres communs pour les données du cycle de vie et l'identification de l'équipement. Les directives de la NRC sur les systèmes digitaux continuent de pousser vers la transparence, la traçabilité et les preuves basées sur la performance.
Ces efforts partagent une approche commune. L'approche commence par définir les objets sur lesquels une centrale raisonne (systèmes, composants, capteurs, documents, contraintes, engagements réglementaires), puis par définir comment ils se connectent. Une pompe appartient à un système. Un capteur mesure une variable sur un composant. Une vanne définit une partie d'un périmètre d'isolement. Un composant hérite des exigences de qualification de son emplacement d'installation. Un engagement réglementaire remonte aux hypothèses de configuration qui le soutiennent. Cette structure est une ontologie.
Pour en revenir à notre scénario susmentionné, le remplacement d'une seule vanne motorisée exige qu'un ingénieur consulte plus de 6 systèmes, rapproche 3 à 4 conventions de nommage et vérifie environ 12 révisions de documents, ce qui peut prendre entre 4 et 8 heures. Ce travail devient éphémère lorsque la question ou le problème suivant concernant le même composant refait surface. Les systèmes nucléaires reposent sur des relations et des dépendances. Une ontologie rend ces relations explicites, consultables et justifiables. Les relations dans une centrale nucléaire ne sont pas tabulaires. Une modification apportée à un composant affecte le périmètre qu'il prend en charge, le train auquel il appartient et les contraintes dont il hérite. Les structures de graphes correspondent naturellement à ce type de raisonnement, mais cela ne signifie pas que vous ayez besoin d'une base de données de graphes distincte. Les ontologies encodent ces relations sous forme de triplets, des unités atomiques qui relient deux entités par une relation spécifique. Elles encodent également les règles métier directement dans les normes de structure, telles que RDF (Resource Description Framework) et SHACL (Shape Constraint Language). Des critères concrets définissent ce qui constitue des données valides, comme les contraintes de sécurité, les règles de configuration et les exigences de qualification. Ces règles font partie intégrante du modèle de données lui-même, de sorte que les violations apparaissent structurellement plutôt que de dépendre de quelqu'un qui les détecterait lors d'un examen.
L'ontologie et ses triplets organisés constituent l'asset durable. Elles persistent au-delà de toute application ou interface utilisateur spécifique. Des standards ouverts comme RDF et OWL (Web Ontology Language) garantissent que les données restent portables, afin qu'elles s'alignent sur les ontologies existantes des secteurs d'activité et créent des formats d'échange clairs pour les données des fournisseurs et les soumissions de licences. Rien n'est verrouillé. Mais les données ont toujours besoin d'un endroit pour être gouvernées, versionnées et query à Monter en charge.
Pour les applications nucléaires, l'ontologie doit remplir trois conditions pour que sa construction en vaille la peine.
- Identité canonique au fil du temps. La même pompe peut apparaître sous les noms "P-123" dans la gestion du travail, "P123_DIS_PRES" dans l'historien et "P-123A" dans les schémas. L'ontologie résout ces éléments en une seule entité et suit l'évolution de cette entité à travers les remplacements, les modifications et les pannes. Vous pouvez répondre aux questions "qu'est-ce qui est installé maintenant" et "qu'est-ce qui était installé au moment de la prise de décision" à partir de la même structure.
- Relations explicites. Pas seulement « ce composant existe », mais « ce composant appartient à la voie A, définit une partie de la limite d'isolement du confinement, est mesuré par ces capteurs et hérite des contraintes de qualification environnementale (QE) de son emplacement ». Les relations que les ingénieurs expérimentés ont en tête deviennent visibles et explorables.
- Sourçage explicite des contraintes d'actifs. Lorsque nous avons une vanne avec une limite de fuite spécifique, il est essentiel de comprendre d'où vient cette contrainte et pourquoi. Une ontologie établit un lien explicite avec les spécifications techniques spécifiques qui sous-tendent cette contrainte.
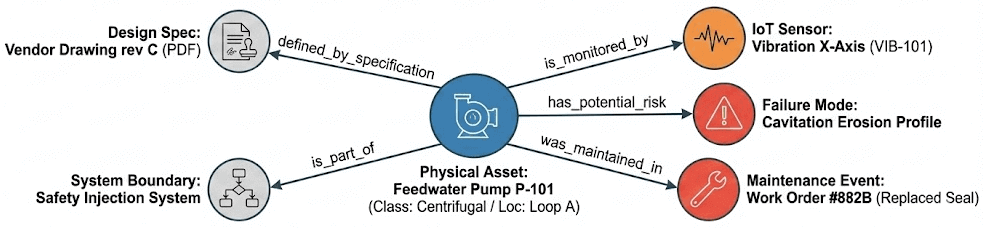
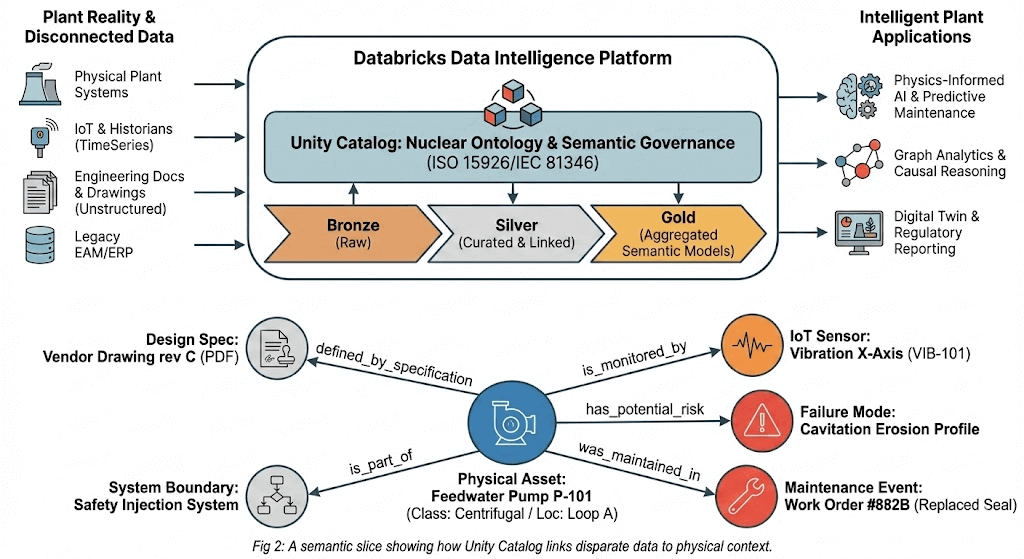{kind=link}
Travailler dans le cadre réglementaire du nucléaire
Le Secteurs d'activité nucléaire est l'un des secteurs les plus réglementés au monde, et à juste titre. Divers cadres réglementaires peuvent s'appliquer, y compris les règles de contrôle des exportations telles que les réglementations sur l'administration des exportations (EAR) et le Titre 10 du Code des règlements fédéraux, Partie 810 (10 CFR Part 810), ainsi que les exigences en matière de protection des données et les exigences émergentes en matière de gouvernance de l'IA, telles que le GDPR et la loi de l'UE sur l'IA. Ces obligations peuvent affecter l'endroit où les analyses sont effectuées, la manière dont les preuves sont stockées, les informations qui peuvent être partagées au-delà des frontières ou en dehors de limites définies, et qui peut y accéder. Ensemble, ces réglementations façonnent directement la manière dont l'infrastructure digital dans le secteur nucléaire est conçue, déployée et gouvernée.
Une ontologie offre un moyen de séparer la structure du contenu sensible. Les relations, les contraintes et la logique de configuration de la centrale peuvent être définies et maintenues comme une couche distincte, séparée des données opérationnelles sous-jacentes. Les ingénieurs peuvent travailler avec le contexte relationnel complet de la centrale, en interrogeant la manière dont les composants se connectent, les contraintes qui s'appliquent et l'origine de ces contraintes, sans que les données opérationnelles sous-jacentes ne quittent les environnements contrôlés. Les bibliothèques de scénarios construites sur la structure de l'ontologie peuvent être versionnées, examinées et partagées en tant qu'actifs gouvernés, basés sur la physique réelle de la centrale sans exposer d'informations protégées.
Ceci est particulièrement pertinent pour les nouvelles constructions. La vérification de la conception, la collaboration avec les fournisseurs et l'analyse des licences impliquent toutes de multiples organisations échangeant des informations techniques sous le contrôle des exportations. Une ontologie vous permet de partager la structure et les relations qui soutiennent les décisions de Data Engineering sans distribuer de données opérationnelles sensibles ou de détails de conception propriétaires. Les fournisseurs, les constructeurs et les opérateurs peuvent travailler à partir d'un cadre commun tandis que chaque organisation conserve le contrôle de ses propres informations protégées. Cela réduit les frictions qui ralentissent généralement les programmes nucléaires multipartites et aide à maintenir les conceptions inédites dans les délais.
Pour les installations d'exploitation, le même principe s'applique. Vous pouvez développer et valider des cadres de raisonnement, former le nouveau personnel au contexte de l'usine et préparer des packages de conformité sans déplacer les données sensibles en dehors des limites appropriées.
Une façon pratique de comprendre ce que fait une ontologie est de parcourir un seul flux de travail.
Cas d'utilisation : validation de la conception et contrôle de la configuration
La validation de la conception et le contrôle de la configuration soulèvent sans cesse la même question : compte tenu de la configuration actuelle de la centrale, ce changement est-il acceptable et pouvons-nous le prouver à partir de sources contrôlées ? Chaque fois que vous touchez un composant lié à la sécurité, mettez à jour une donnée d'entrée de conception, remplacez une pièce ou révisez un calcul, vous devez rétablir le contexte à travers les systèmes. Quel est exactement ce composant dans cette centrale ? Où est-il installé ? Quelle fonction de sécurité ou quelle barrière assure-t-il ? Quelles exigences hérite-t-il de cet emplacement ? Quels documents régissent la fenêtre de travail ? Les données permettant de répondre à ces questions existent. Ce n'est généralement pas le cas pour les liens entre les données.
Les pannes mettent cela à rude épreuve. Le matériel est remplacé sous la pression des délais. Les travaux sur le terrain, l'approvisionnement et Data Engineering sont menés en parallèle. Les erreurs qui causent de réels problèmes sont rarement spectaculaires. Ce sont des inadéquations discrètes qui apparaissent tardivement : une base de qualification qui ne correspond pas au lieu d'installation, une révision de plan qui n'était pas à jour, une affectation de filière incorrecte, une hypothèse de limite qui a changé, ou une limite d'enveloppe de fonctionnement provenant de la mauvaise source.
Un exemple courant est le remplacement d'une vanne motorisée sur une conduite liée à la sûreté. Avant qu'un ingénieur puisse même évaluer le remplacement, il doit reconstituer le contexte : à quel système et à quelle filière il appartient, quelle limite ou fonction créditée il soutient, quelles exigences EQ et sismiques s'appliquent à cet endroit, quelles limites de fonctionnement régissent le composant, et quels documents contrôlés établissent ces limites.
Aujourd'hui, chaque étape de ce processus est manuelle. L'ingénieur ouvre l'ordre de travail pour un numéro d'identification. Il navigue séparément vers l'ensemble de plans pour le contexte des limites. Il extrait les fichiers de qualification et sismiques d'un autre système. Il recherche les calculs de contrôle pour les limites de fonctionnement et vérifie l'état de la révision. Chaque consultation est un système distinct, une recherche distincte, une décision distincte quant à savoir si l'information est à jour. Ensuite, l'ingénieur synthétise toutes ces informations dans sa tête pour déterminer si le remplacement est acceptable. Si quelqu'un d'autre, un inspecteur, un évaluateur ou une autre équipe, pose la même question plus tard, le processus start à nouveau.
Une ontologie de centrale change cela en intégrant la chaîne de preuves à la structure. Le composant possède une identité canonique. Cette identité est un Link vers son emplacement d'installation et son état de configuration, et de là vers les exigences qui en découlent : affectation à une voie, rôle de limite, contraintes QE et sismiques, limites de l'enveloppe de fonctionnement et sources faisant autorité qui les définissent. L'ingénieur start du composant, et les relations sont déjà présentes. L'enregistrement complet du cycle de vie (vérification de la conception, approvisionnement, fabrication, tests et expédition) est accessible à partir de cette identité unique. Les documents de qualité justificatifs, tels que les rapports CND, les tests d'acceptation en usine et les références traçables, sont directement liés au composant au lieu de se trouver dans des systèmes distincts en attente d'être trouvés.
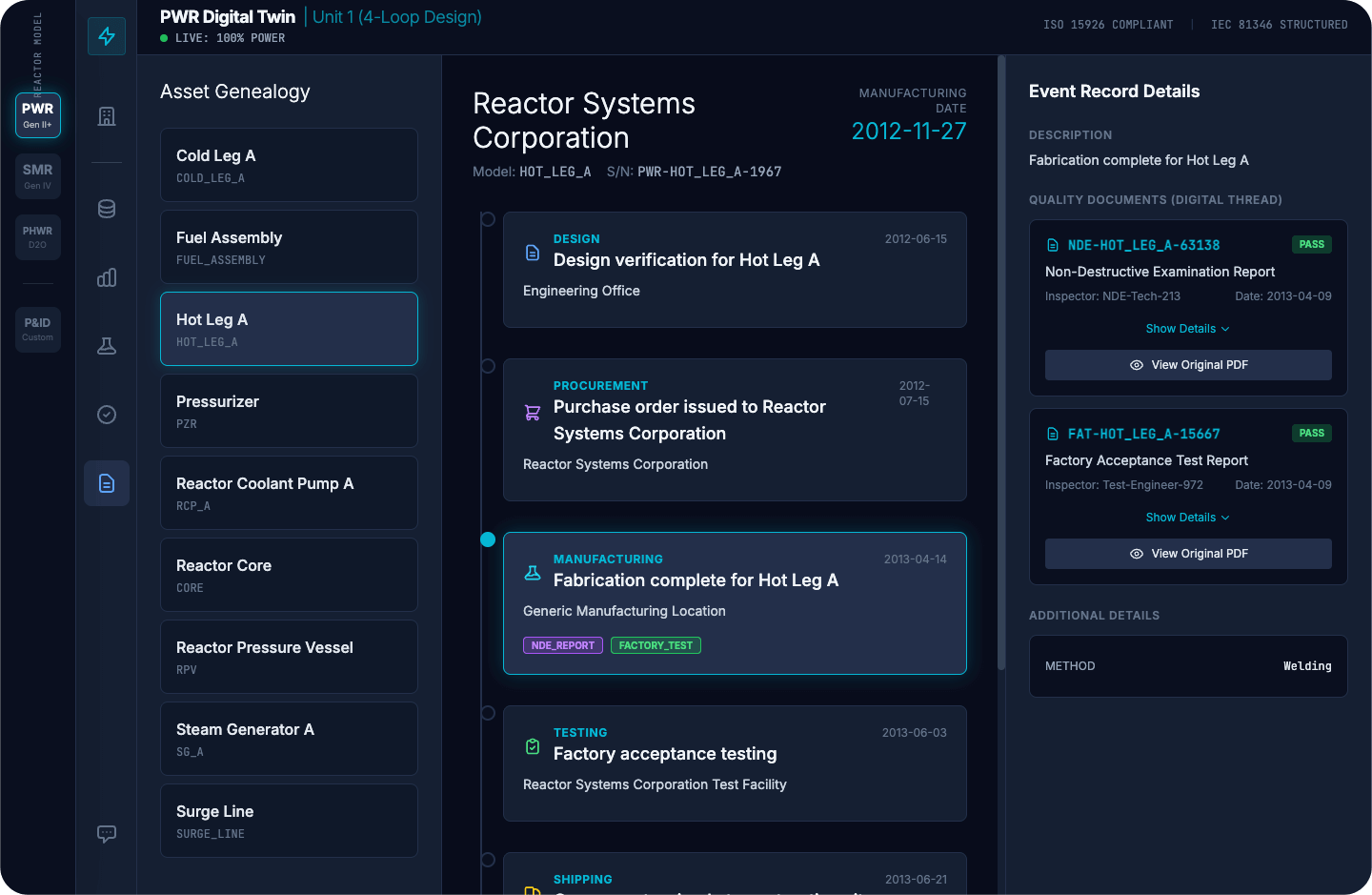
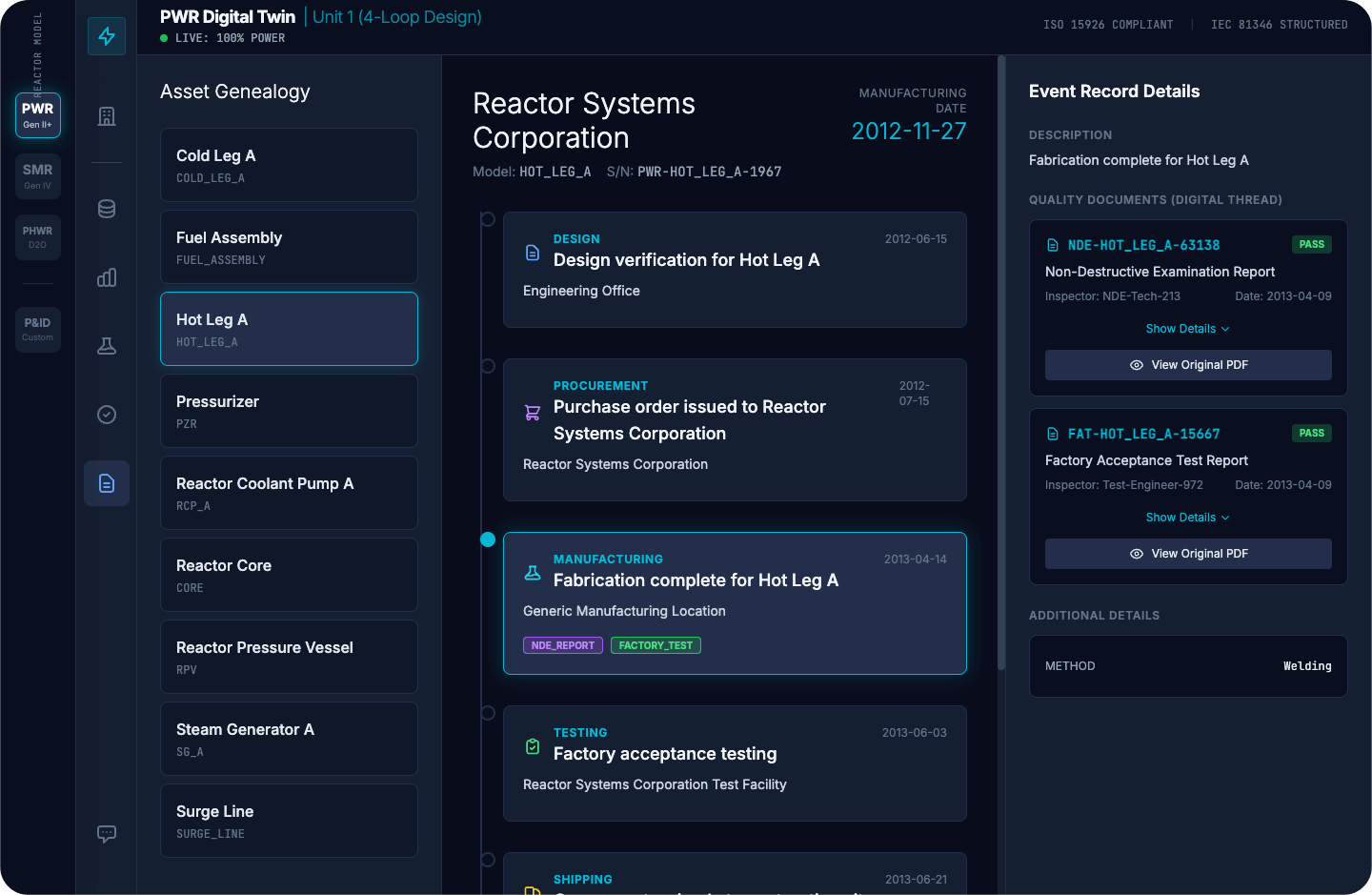{kind=link}
Parce que les contraintes et leurs sources sont codées dans la structure, des outils peuvent être créés pour signaler les incohérences, telles qu'une base EQ incorrecte, une révision obsolète ou une affectation de train incompatible. L'ingénieur a toujours le dernier mot. L'infrastructure leur permet d'y parvenir plus rapidement et fournit une vue d'ensemble complète, plutôt qu'une vue partielle assemblée sous la pression du temps.
Exploiter l'ontologie en Monter en charge
L'utilité d'une ontologie dépend de la plateforme qui l'exécute. Les relations, les identités et les contraintes doivent être régies, versionnées et interrogeables en Monter en charge. La plateforme doit rester alignée sur l'état réel de la centrale pendant les arrêts, les modifications, les altérations temporaires et les mises à jour des documents, avec une auditabilité qui résiste aux inspections. Si elle ne peut pas le faire, l'ontologie drift et les utilisateurs cessent de lui faire confiance.
L'ontologie encode les relations, les contraintes et la logique de configuration de la centrale dans des standards ouverts. La plateforme qui la régit doit correspondre à cette ouverture. Si la couche de gouvernance est propriétaire, peu importe la portabilité de l'ontologie sur le papier. Dans un Secteur d'activité où le dossier du cycle de vie d'un composant doit être auditable par un opérateur, examinable par la NRC et traçable par un OEM sur plusieurs décennies, la capacité à partager clairement les données entre les organisations et les outils est un prérequis.
Databricks est basé sur des formats et des interfaces ouverts. Les triplets d'ontologie, les registres de composants, les tables de relations et les enregistrements de contraintes se trouvent tous sur Delta Lake et sont accessibles depuis d'autres outils. Si vous devez partager des sous-ensembles avec un partenaire ou un organisme de réglementation, les formats sont normalisés. Rien n'est verrouillé.
Sur cette base, quatre capacités reviennent sans cesse dans le secteur nucléaire :
- Gouvernance unifiée Lorsque l'assurance qualité (QA) ou la NRC demande comment un asset spécifique a été contrôlé, la réponse doit être cohérente sur l'identité des composants, le contrôle des documents, les relations et les références de base de licence. Cela ne tient plus lorsque chacun de ces éléments est soumis à un modèle d'autorisations distinct. Unity Catalog fournit une couche de gouvernance unique sur l'ensemble de l'ontologie. Les autorisations, le suivi des modifications et l'audit s'appliquent uniformément à chaque asset, de sorte qu'il existe une seule réponse défendable plutôt que quatre réponses partielles.
- Configuration indexée sur le temps. Les décisions de Data Engineering et d'octroi de licences dépendent de l'état de l'installation à un moment précis. En vertu de la réglementation 10 CFR 50.59, les centrales évaluent si un changement proposé nécessite l'approbation préalable de la NRC en évaluant son impact par rapport à la base d'autorisation existante. La fiabilité de cette évaluation dépend des données de configuration qui la sous-tendent, et il en va de même pour les déterminations d'opérabilité, les questions de base sur les points de consigne, la validation post-modification et les examens de routine des pannes. Toutes ces opérations nécessitent de savoir ce qui était installé et les révisions de contrôle au moment de la prise de décision. La fonctionnalité de time travel de Delta Lake prend en charge les vues « tel que conçu », « tel que construit », « tel qu'installé » et « tel que maintenu » à partir des mêmes données sous-jacentes, sans nécessiter d'instantanés manuels distincts. Chaque version de table est conservée et interrogeable, de sorte que la reconstruction de l'état de la centrale à n'importe quel point de décision antérieur relève d'une query plutôt que d'un projet d'archéologie.
- Chaînes de preuves reproductibles. 10 CFR 50 Appendix B établit les exigences d'assurance qualité pour les systèmes, structures et composants liés à la sécurité. Avoir la bonne conclusion n'est pas suffisant si vous ne pouvez pas reproduire sa justification à partir de sources contrôlées. Le suivi automatisé de la lignée de données d'Unity Catalog capture les révisions de documents, les enregistrements de contraintes et les versions de relations qui ont été utilisés dans un workflow spécifique. Les Logs d'audit de Delta Lake enregistrent chaque mutation des données sous-jacentes. Ensemble, lorsqu'un examinateur ou un inspecteur a besoin de voir ce qui a étayé une décision, la plateforme fournit une réponse complète et Timestamp au lieu d'exiger que quelqu'un la reconstitue après coup.
- Analytique sur des données gouvernées. La gouvernance, le versionnage et le lignage garantissent que les données sont dans un état de confiance. La question suivante est de savoir ce que vous pouvez en faire une fois qu'elles y sont. Les Databricks Lakeflow Jobs fournissent la couche d'orchestration pour les pipelines analytiques qui opèrent directement sur les assets gouvernés de l'ontologie. MLflow assure le suivi des versions de modèles, des données d'entraînement, des parameter et des sorties avec la même rigueur que celle que Unity Catalog applique aux données elles-mêmes. Les modèles de Condition monitoring peuvent suivre les modèles de dégradation sur une classe entière de vannes en extrayant l'historique de maintenance, les tendances des capteurs et les limites de conception de la structure gouvernée. Les modifications proposées peuvent être vérifiées automatiquement par rapport au référentiel réglementaire, car les contraintes et leurs sources sont déjà encodées. Les modèles et leurs sorties remontent à des sources contrôlées via le même lignage que celui que la plateforme fournit pour tout le reste. Cette traçabilité est ce qui distingue l'analytique qui éclaire les décisions de l'analytique qui peut réellement être prise en compte dans un environnement réglementé.
Cela est directement lié à la direction que prennent les investissements du DOE. La Genesis Mission du DOE développe la nouvelle génération d'outils digitaux pour le secteur de l'énergie, couvrant la simulation avancée, les jumeaux digitaux, la conception assistée par l'IA et l'analytique opérationnelle. L'ontologie et les données gouvernées que vous mettez en place aujourd'hui pour le contrôle de la configuration et la conformité sont les mêmes actifs sur lesquels ces programmes s'appuieront. L'infrastructure qui réduit le temps de cycle et les remaniements actuels devient la base de ce qui va suivre. Une plateforme ouverte signifie que l'investissement est pérennisé plutôt que de nécessiter une réécriture lorsque les exigences évoluent.
Implications commerciales et stratégiques
La valeur d'une ontologie est cumulative. Comme la structure persiste, le travail effectué pour résoudre le contexte d'un composant pour une décision est reporté sur la suivante.
Pour le parc existant, les centrales prolongent leurs Opérations, entreprennent des modifications plus complexes, et ce, avec un pool plus restreint de personnel expérimenté et des délais réglementaires plus serrés. Ce qui prenait autrefois des jours d'extraction de données de systèmes distincts pour assembler un package de conformité peut maintenant être condensé en une query structurée sur des relations qui existent déjà. Des ensembles de preuves prêtes pour l'inspection, qui nécessitaient auparavant de reconstituer la base de mémoire, peuvent être assemblés à partir de la structure déjà en place. Le pourcentage d'actifs avec une identité canonique résolue à travers les sources de données augmente régulièrement à mesure que l'ontologie mûrit.
Pour les nouvelles constructions, les avantages commencent dès la phase de conception et se poursuivent jusqu'à l'obtention des licences. Si l'ontologie est mise en place tôt, les relations entre l'intention de conception, les fonctions créditées et les engagements en matière de licence sont structurées avant même l'expédition du premier composant. Les incohérences de contraintes sont signalées lors de la revue de conception, car les contraintes et leurs sources sont encodées dans la structure. Sans cela, ils sont généralement découverts lors de l'installation sur site, lorsque le coût de la correction est de plusieurs ordres de grandeur plus élevé. Les preuves pour l'homologation se constituent au fur et à mesure que la conception mûrit, plutôt que d'être reconstituées a posteriori. Il en résulte moins de cycles de reprise, une coordination plus rapide entre les fournisseurs et les constructeurs, et des coûts réduits pour démontrer la sécurité. La norme de sécurité ne change pas. Le travail requis pour prouver qu'elle est respectée, en revanche, change.
Une fois que l'ontologie est fonctionnelle pour le contrôle de la configuration, son utilité ne s'arrête pas là. Les mêmes relations qui prennent en charge le remplacement d'une vanne prennent également en charge le programme de monitoring qui suit la dégradation de cette classe de vannes. La même lignée de contraintes qui alimente un package de conformité alimente l'analyse des licences pour la prochaine augmentation de puissance. Parce que l'ontologie est construite sur une identité et une lignée de contraintes alignées sur les normes, elle fournit aux OEM, aux entreprises de Data Engineering et aux régulateurs un point de référence commun plutôt qu'un autre système avec lequel s'intégrer.
Cela change la façon dont les nouveaux ingénieurs montent en compétence. Au lieu de se forger un contexte en trouvant la bonne personne à qui demander, ils peuvent query un composant et voir l'affectation de sa file, son rôle de limite, ses sources de contraintes et son historique de maintenance en un seul endroit. Les connaissances institutionnelles deviennent une infrastructure plutôt que quelque chose qui s'en va à la retraite. Le personnel expérimenté passe moins de temps à répondre aux mêmes questions contextuelles et plus de temps sur les décisions qui nécessitent réellement son expertise.
Si le parc doit quadrupler sa capacité et se moderniser en même temps, c'est le type d'infrastructure qui doit être planifié tôt et poursuivi.
Construire les fondations de la Transformation digitale du nucléaire
Prêt à découvrir comment les ontologies peuvent renforcer la gestion des connaissances et la prise de décision pour les secteurs d'activité nucléaires ? Download l'accélérateur de solution Databricks pour les jumeaux numériques dans l'industrie, accélérez votre implémentation à l'aide d'Ontos de Databricks Labs ou lisez l'article Comment créer des jumeaux numériques pour l'efficacité opérationnelle sur le blog Databricks pour voir l'architecture de référence en pratique.
Si vous souhaitez appliquer ces concepts à vos propres systèmes, workflows et contraintes de gouvernance, contactez votre équipe de compte Databricks pour discuter d'un point de départ délimit�é.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.