Ingestion de la Voie lactée : à l'échelle du pétaoctet avec Zerobus Ingest
Une plongée au cœur de l'architecture permettant d'atteindre 12 GB/s par table — et des possibilités illimitées
par Aleksandar Tomić, Victoria Bukta, Nikola Obradović, Danilo Najkov, Branko Grbić et Milos Milovanovic
- Databricks Zerobus Ingest est une API de streaming serverless qui permet aux équipes de déployer instantanément des pipelines de données à l'échelle du pétaoctet sans gestion manuelle de l'infrastructure.
- L'architecture de Zerobus repose sur le partitionnement dynamique pour mettre à l'échelle automatiquement les ressources de calcul, gérant efficacement des volumes de données imprévisibles sans ajustement complexe.
- Ce framework sans configuration traite facilement des charges de travail massives, démontrant sa capacité à maintenir un débit de plus de 12 GB/s vers une seule table lors de benchmarks de 24 heures.
Les données de télémétrie sont partout. Des capteurs IoT dans les usines aux constellations de satellites qui scannent l'atmosphère, en passant par les véhicules autonomes qui enregistrent des milliers d'événements par seconde. Chacun de ces systèmes est confronté au même problème sous-jacent : un flux continu et massif d'observations de séries temporelles qui doit être stocké dans un espace interrogeable. Ce processus doit être rapide, fiable et ne pas nécessiter qu'une équipe d'ingénieurs passe des semaines à configurer et à maintenir l'infrastructure classique des charges de travail basées sur Kafka.
C'est précisément le problème que Zerobus Ingest a été conçu pour résoudre. Zerobus est le service d'ingestion de streaming serverless et entièrement géré de Databricks. Il s'agit d'une API basée sur le mode push qui accepte les données de n'importe quel producteur et les écrit directement dans des tables Delta, sous la gouvernance d'Unity Catalog.
- Aucune infrastructure à provisionner.
- Aucun pipeline de connecteurs à maintenir.
- Aucune partition ni prise de décision concernant les brokers.
À la place, il vous suffit de créer une table et d'y envoyer vos données. Elles arrivent dans votre lakehouse, prêtes à être interrogées en quelques secondes. Vous n'avez plus besoin d'utiliser Kafka comme pipeline lorsque votre destination finale est le lakehouse.
Nous avons utilisé le jeu de données NEOWISE de la NASA, qui représente 200 milliards de points de données sur 11 ans, pour évaluer les performances de Zerobus Ingest. Nous avons ainsi ingéré 1 pétaoctet en moins de 24 heures, avec une configuration initiale inexistante et une latence stable.
En ingérant 1 PB en 24 heures, nous démontrons la capacité de Zerobus à maintenir un débit continu de 12 GB/s vers une seule table ! 🚀
Désormais disponible à l'échelle du pétaoctet : diffusion en continu de la Voie lactée (12 GB/s/table)
Pour en savoir plus sur la façon d'exécuter vous-même ce benchmark, lisez ce blog complémentaire sur la communauté Databricks.
Cet article présente trois des choix de conception qui ont rendu cela possible.
- La conception d'un système qui s'adapte automatiquement grâce au partitionnement dynamique.
- La création de notre propre décodeur protobuf sans copie (zero-copy).
- L'implémentation d'un journal d'écriture anticipée (write-ahead log) optimisé pour la latence avant la publication des données dans le lakehouse.
Nos principaux choix de conception
Notre ambition était de concevoir un système de streaming capable de supporter l'échelle du pétaoctet et de s'adapter automatiquement pour gérer les fluctuations des flux d'ingestion.
Les architectures de streaming traditionnelles vous obligent à déterminer le nombre de brokers et de partitions nécessaires pour une charge de travail donnée. Cela implique de connaître la charge de pointe et les contraintes d'ingestion des consommateurs, ainsi que de réaliser des prévisions et de comprendre le pipeline de bout en bout.
En repartant des principes fondamentaux, nous avons conçu et développé un système qui s'adapte « comme par magie » pour gérer des charges de travail de l'ordre du pétaoctet pour les producteurs de données.
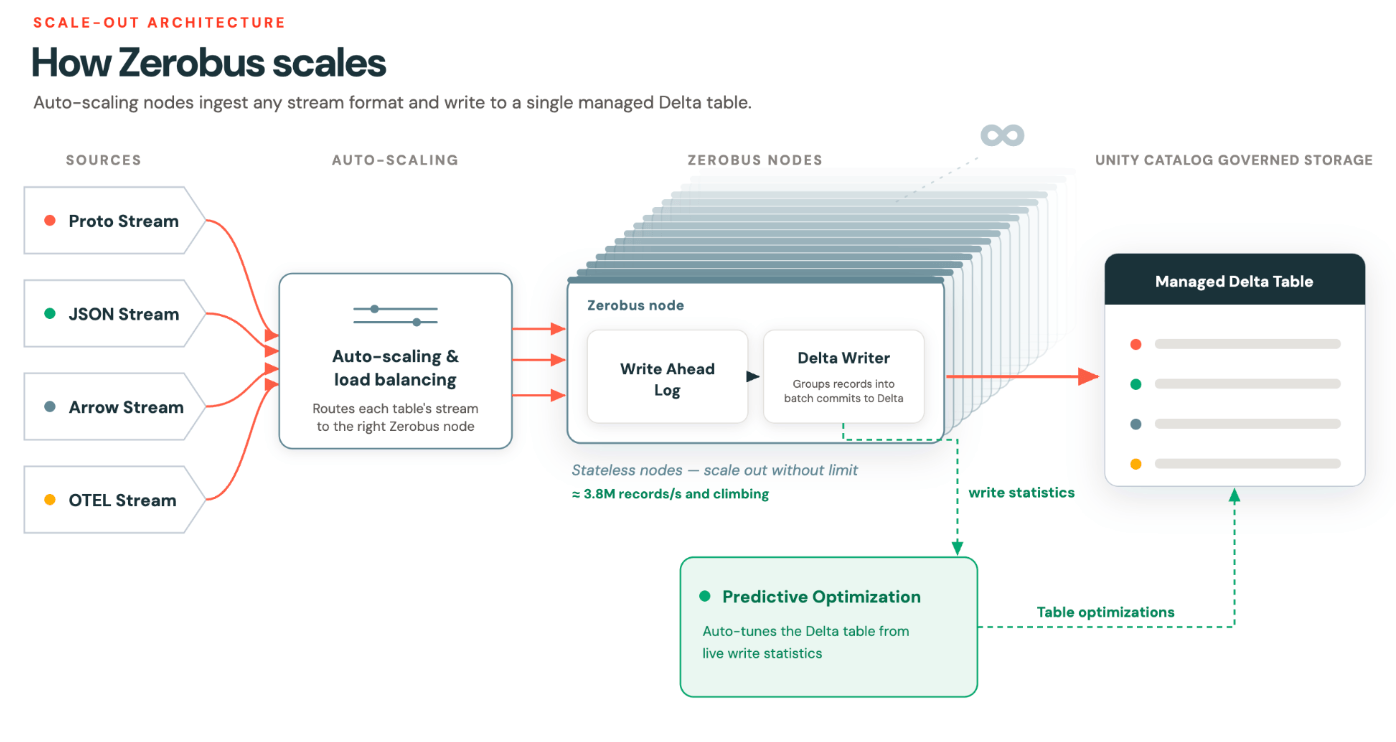
Une mise à l'échelle automatique grâce au partitionnement dynamique
Le problème que nous cherchions à résoudre était d'obtenir une mise à l'échelle automatique efficace afin de parvenir à une extensibilité élastique « sans limites ».
Notre hypothèse était qu'en abandonnant le partitionnement statique au profit de l'unité logique d'un flux/connexion, nous pourrions débloquer une véritable mise à l'échelle automatique et un rééquilibrage tout en maintenant les garanties d'ordre, essentielles pour les charges de travail de consommation.
Le problème du partitionnement statique
Dans les architectures de bus de messages, les partitions constituent à la fois l'unité de parallélisme et d'ordonnancement. Ce couplage crée une contrainte qui peut s'avérer complexe dès lors que des consommateurs en dépendent.
L'ordonnancement est généralement une garantie par partition, et non par producteur. Le nombre de partitions et la répartition des données entre elles affectent la capacité d'un consommateur à suivre le rythme de l'ingestion. Cela signifie que :
- Si le nombre de vos partitions change, la fonction de routage qui associe les messages d'un producteur à une partition peut désormais les envoyer vers une autre partition. Le consommateur doit alors gérer cette réconciliation.
- En pratique, la plupart des équipes considèrent la topologie des partitions comme immuable. Vous dimensionnez l'infrastructure pour la charge de pointe et la conservez indéfiniment. Vous pouvez ajouter des partitions, mais vous ne pouvez généralement pas les réduire en toute sécurité.
- La solution de contournement standard consiste à utiliser une clé de routage de partition dérivée d'un champ du message. Cela aide à maintenir la cohérence de l'ordonnancement, mais ne résout pas le problème de la réduction d'échelle.
Nous avons déplacé la garantie d'ordonnancement vers la connexion de flux
Dans les systèmes traditionnels, l'ordonnancement est une garantie au niveau de la partition. Dans Zerobus Ingest, l'ordonnancement est une garantie au niveau de la connexion de flux.
Lorsqu'un producteur ouvre un flux avec Zerobus (une connexion à notre serveur), il enregistre une identité logique auprès du service. Pendant toute la durée de cette connexion, ses données arrivent dans l'ordre, quel que soit le pod de « partition » qui les traite.
« Votre flux est ordonné », et non « votre partition est ordonnée ». Tel est le contrat.
Routage dynamique et véritable mise à l'échelle automatique
En interne, Zerobus Ingest répartit les flux sur un ensemble de pods. Le routage repose sur des heuristiques : si un pod est surchargé, les nouveaux flux entrants sont redirigés vers un autre pod. Le producteur ne s'en rend pas compte et sa garantie d'ordonnancement reste inchangée.
L'ordonnancement s'effectue au niveau du flux, ce qui signifie que des pods peuvent être ajoutés en cas de pic de demande et supprimés lorsque la demande diminue. Les flux existants se vident alors progressivement et les nouveaux flux cessent d'y être acheminés. Le pool se réduit ensuite, garantissant une utilisation efficace des ressources de calcul.
Il s'agit là d'une véritable mise à l'échelle automatique. L'unité de granularité est la connexion de flux, et non l'attribution de partitions.
Notre architecture de partitionnement dynamique permet à Zerobus de s'adapter automatiquement pour atteindre un débit supérieur à 12 GB par seconde pour une table, tout en restant rentable.
Gestion des données haute performance sans copie (zero-copy)
L'objectif principal de Zerobus est de permettre un transfert ligne par ligne efficace de flux de données de n'importe quel volume. Pour y parvenir, nous devions éviter toute copie inutile et toute allocation de mémoire superflue, qu'il s'agisse des formats d'entrée envoyés par les clients à Zerobus, ou des formats internes garantissant la durabilité et des formats Delta ouverts.
Zerobus prend actuellement en charge les formats de messages suivants.
Parmi les nombreuses optimisations que nous avons réalisées, nous illustrerons l'approche zero-copy à travers ZeroParser, notre décodeur protobuf personnalisé.
Les décodeurs protobuf standards vous obligent à choisir entre vitesse et flexibilité. Ils s'appuient généralement soit sur la génération de code au moment de la compilation (codegen), soit sur la réflexion au moment de l'exécution (runtime reflection).
- La génération de code est rapide, mais elle nécessite des descripteurs au moment de la compilation. Zerobus reçoit les descripteurs de manière dynamique au moment de l'exécution, à partir de schémas utilisateur arbitraires. La génération de code n'est donc pas une option.
- La réflexion au moment de l'exécution résout le problème de flexibilité, mais en crée un autre lié aux performances. Les décodeurs protobuf dynamiques sont lents et nécessitent la construction d'un graphe d'objets en mémoire lors de l'exécution, ce qui entraîne de nombreuses petites allocations de mémoire.
Aucune de ces approches n'était acceptable. Nous avions besoin d'une prise en charge dynamique des descripteurs avec le profil de performance de la génération de code.
C'est pourquoi nous avons développé zeroparser : il comble cette lacune en utilisant une analyse en une seule passe avec zéro allocation de mémoire, ce qui lui permet de maintenir des débits d'analyse protobuf de ~1 Go/s par cœur CPU, même avec des descripteurs dynamiques et des schémas complexes.
Zeroparser permet une analyse directe au format réseau (wire format) sans déconstruction des objets entrants, ce qui évite les copies et allocations de mémoire. Grâce à cette approche, Zerobus peut atteindre de meilleures performances que les solutions existantes d'analyse protobuf basées sur la génération de code, tout en conservant la flexibilité totale de la fourniture dynamique de descripteurs protobuf.
Le système de durée de vie (lifetimes) de Rust a été au cœur de la conception de Zeroparser : il garantit la sécurité au moment de la compilation lors de l'analyse du protocole tout en maintenant les octets bruts du réseau sous la propriété exclusive de la couche réseau, éliminant ainsi les copies de données inutiles.
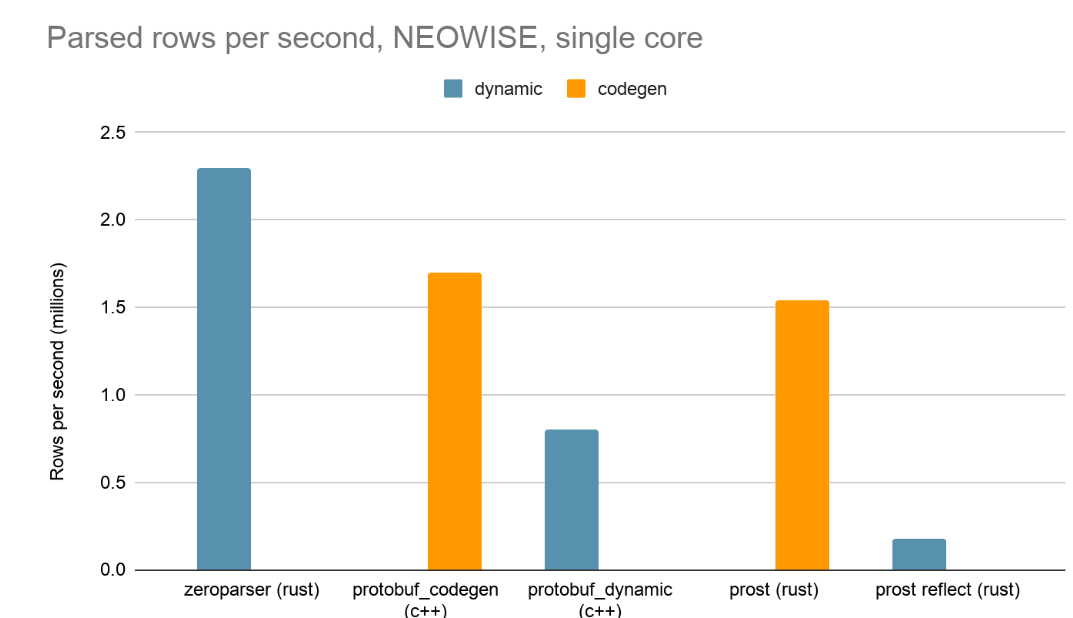
Les résultats montrent que Zeroparser, bien qu'appartenant au groupe dynamique, a surpassé deux implémentations basées sur la génération de code qui sont des standards de l'industrie.
Zeroparser est disponible en open source dans le cadre du SDK Zerobus accessible ici.
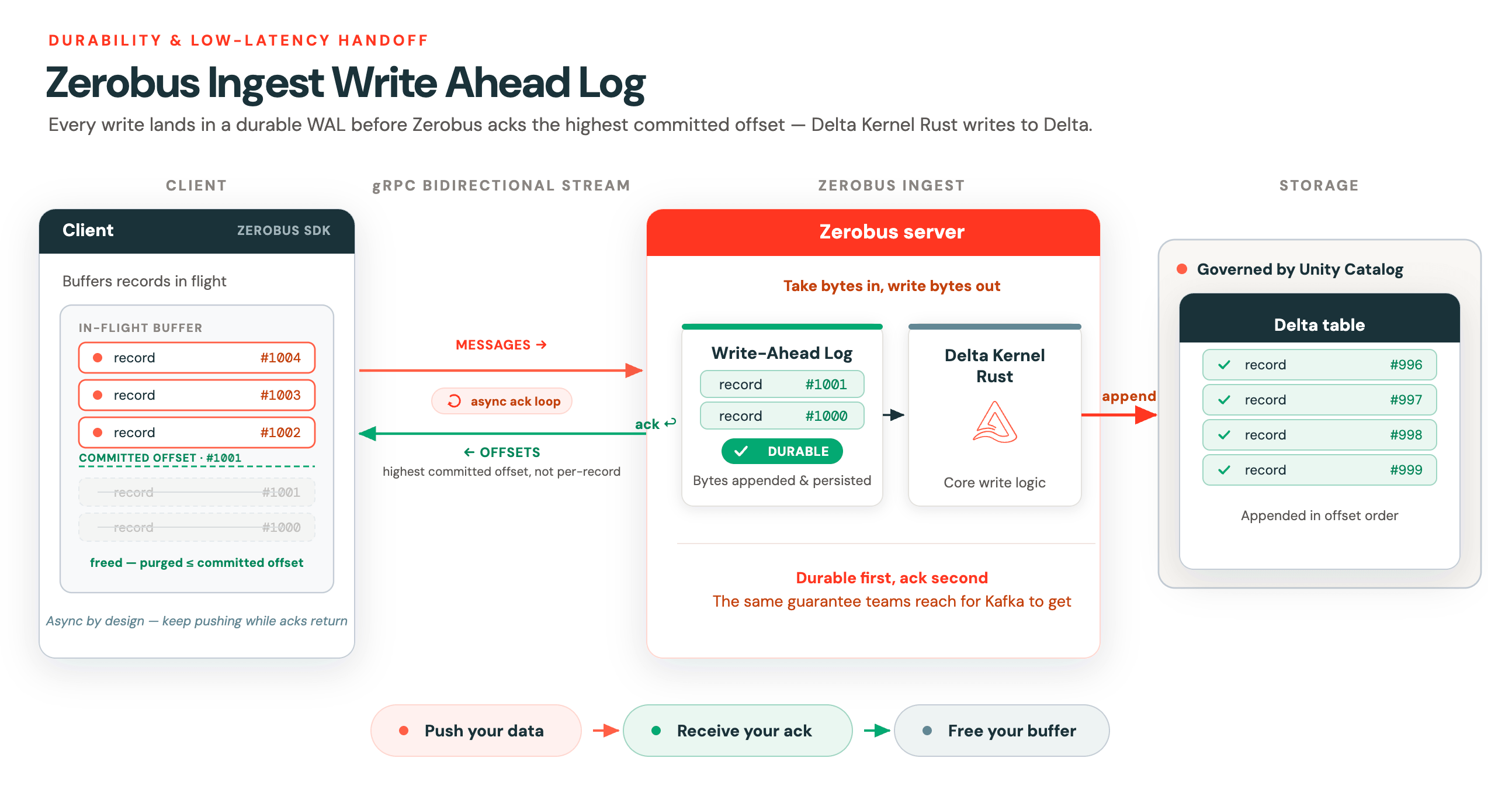
Journal d'écriture anticipée (WAL)
Le streaming ne consiste pas seulement à gérer des charges de travail à haut débit. Pour être un véritable service de streaming, vous devez également prendre en charge le transfert de messages le plus rapidement possible. C'est cette faible latence dans le transfert des données qui distingue véritablement les charges de travail de streaming du traitement par lots.
Pour prendre en charge ce transfert à faible latence avec une garantie de durabilité, Zerobus implémente un journal d'écriture anticipée (WAL) optimisé pour la latence. Une fois les messages durabilisés, Zerobus renvoie un accusé de réception au client. Plutôt que d'accuser réception de chaque enregistrement individuellement, le serveur renvoie l'offset validé le plus élevé sur le flux. Le résultat est cette boucle d'accusé de réception asynchrone. Delta Kernel Rust est ensuite utilisé pour la logique principale d'écriture dans Delta.
Cette conception asynchrone est essentielle pour les clients qui mettent en mémoire tampon les données en cours de transfert. Zerobus utilise le streaming bidirectionnel gRPC, où chaque flux Zerobus dispose de deux lignes de communication :
- L'une pour l'envoi de messages
- L'autre pour la réception des accusés de réception d'offsets.
Une fois que le client reçoit cet offset, il peut purger en toute sécurité tout ce qui a été accumulé jusqu'à ce point de son tampon local en cours de transfert. Tout cela est géré pour vous par les SDK Zerobus.
Le WAL est ce qui permet de garder les clients légers. Envoyez vos données, recevez votre accusé de réception, libérez votre tampon. Ce transfert à faible latence et haute durabilité a toujours été la raison pour laquelle les équipes se tournent vers Kafka. Zerobus vous offre la même garantie.
Preuve : Ingestion de la Voie lactée
La clé pour évaluer les performances d'un système réside dans la compréhension de la façon dont il serait utilisé dans un environnement de production, puis dans l'émulation de ce comportement et de cette utilisation. C'est pourquoi, pour tester les limites de Zerobus Ingest, nous avons choisi le jeu de données NEOWISE de la NASA et utilisé Locust pour émuler des modèles de regroupement de flux (fan-in) réels.
Pourquoi Locust ? Le problème du regroupement de flux (Fan-In)
Zerobus Ingest est conçu pour agréger les flux de nombreux producteurs indépendants dans une seule table de destination. Son débit évolue proportionnellement au nombre de flux ouverts simultanément. Cela signifie que vous ne pouvez pas tester ses limites de manière équitable à partir d'une seule machine ou d'un petit cluster. Un seul hôte puissant saturerait sa propre bande passante ou son CPU avant d'exercer une pression significative sur notre service, évaluant ainsi le producteur plutôt que Zerobus.
Pour simuler un modèle de regroupement de flux (fan-in) réel, nous utilisons Locust pour coordonner l'ouverture de flux distincts par des pods afin de tester l'ingestion à grande échelle sous pression.
La mise à l'échelle automatique (autoscaling) de Zerobus réagit ensuite au nombre de flux et au débit pour gérer le taux d'ingestion.
Configuration du test
Notre benchmark a été déployé sur Kubernetes avec un master Locust et une flotte de workers Locust, chacun s'exécutant dans un pod distinct. Paramètres clés :
Chaque worker reçoit une liste unique de fichiers Parquet à ingérer. Un worker diffuse son segment en continu et ne répète pas les lignes.
Les résultats
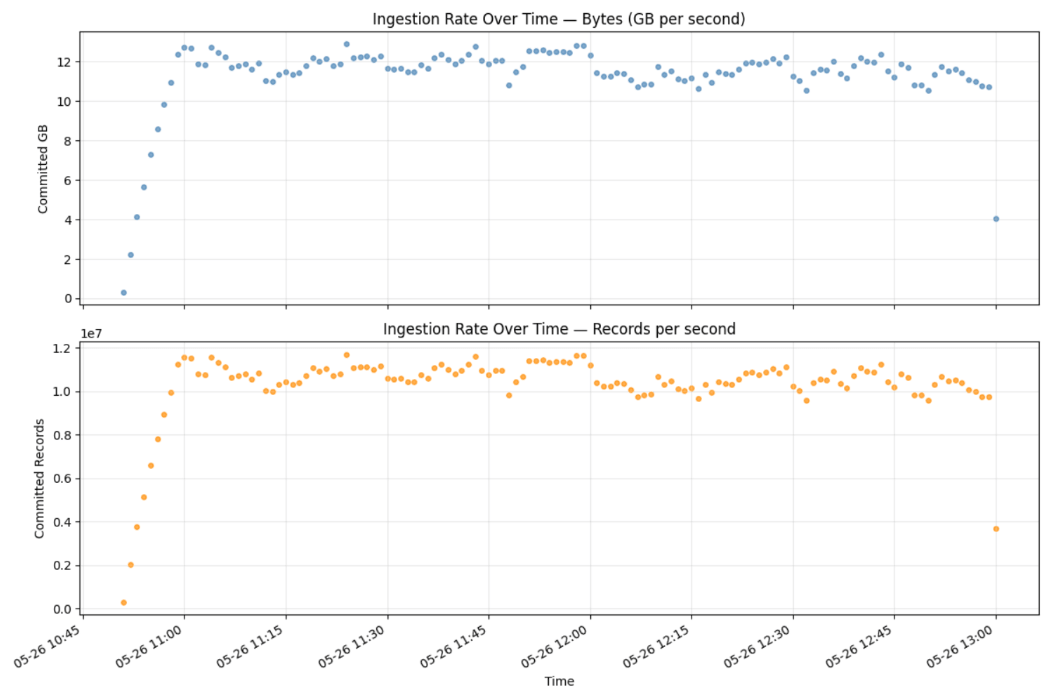
Nos résultats de test ont démontré la capacité de Zerobus Ingest à maintenir un débit de 12 GB/s vers une table unique sur une période de 24 heures, à partir de 2 048 workers simultanés. Durant cette période, Zerobus a ingéré plus d'un billion d'enregistrements.
L'agrégation par intervalles de 5 secondes sur la colonne client_ts_ms offre une vue précise et confirmée par le serveur des lignes validées et des octets reçus :
Cette requête s'exécute sur la table Unity Catalog active. Les chiffres reflètent les lignes qui ont été entièrement validées dans le stockage Delta.
Vous voulez l'essayer vous-même ?
La suite de benchmark complète avec la préparation du jeu de données, le code producteur et les instructions pour l'exécuter sur votre propre point de terminaison Zerobus. Découvrez-la ici.
Prochaines étapes
Zerobus Ingest est désormais disponible de façon générale sur Databricks et prêt pour toutes vos charges de travail de production.
Nos métriques de performance de 12 GB/s vers une table sont ce que vous obtenez par défaut avec Zerobus Ingest. Les quotas peuvent être augmentés en contactant votre équipe de compte.
Sur la feuille de route :
- Prise en charge de l'API Kafka Producer
- Prise en charge de l'API MQTT
- Colonne de récupération
- Colonne de métadonnées système
- Prise en charge d'Avro
Dites-nous où vous souhaitez que nous emmenions Zerobus ensuite ! Quelle est selon vous la prochaine frontière du streaming ? Envoyez-nous vos commentaires sur notre blog compagnon de la communauté Databricks.
Si vous êtes prêt à commencer avec Zerobus Ingest, consultez notre documentation technique, le SDK Zerobus Ingest, ou découvrez le dépôt GitHub avec le benchmark Neowise.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.