Des capacités de fédération de lakehouses pour Unity Catalog
Découvrez, interrogez et encadrez toutes vos données, où qu'elles résident
par Matei Zaharia, Andrew Li, Can Efeoglu, Cyrielle Simeone, Sachin Thakur et Daniel Tenedorio
Lakehouse Federation est maintenant en préversion publique !
Les équipes data sont confrontées à de nombreux défis pour accéder rapidement aux bonnes données, principalement en raison de la fragmentation des données, du temps et du coût liés à la consolidation des données, et des difficultés à gérer la gouvernance des données sur de nombreux systèmes.
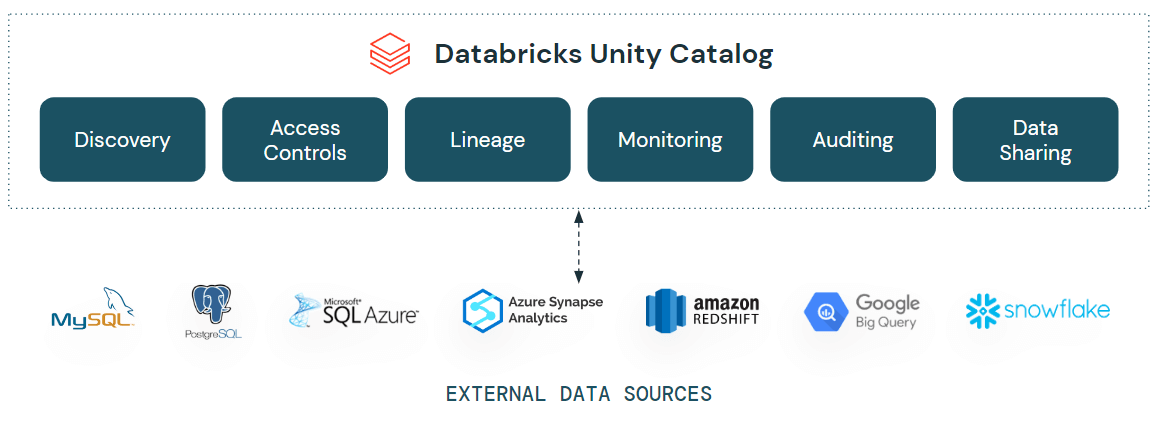
C'est pourquoi aujourd'hui, lors du Data+AI Summit, nous sommes ravis d'annoncer les fonctionnalités de Lakehouse Federation dans Unity Catalog, qui permettent aux organisations de construire une architecture data mesh hautement scalable et performante avec une gouvernance unifiée.
Unity Catalog fournit une solution de gouvernance unifiée pour les données et l'IA. Les fonctionnalités de Lakehouse Federation dans Unity Catalog vous permettent de découvrir, d'interroger et de gouverner des données sur plusieurs plateformes de données, notamment MySQL, PostgreSQL, Amazon Redshift, Snowflake, Azure SQL Database, Azure Synapse, BigQuery de Google, et plus encore, depuis Databricks, sans avoir à déplacer ou à copier les données, le tout dans une expérience simplifiée et unifiée. Cela signifie que les fonctionnalités de sécurité avancées d'Unity Catalog, telles que les contrôles d'accès au niveau des lignes et des colonnes, les fonctionnalités de découverte comme les tags et le lignage des données, seront disponibles sur ces sources de données externes, garantissant ainsi une gouvernance cohérente.
« Les data scientists et les utilisateurs métier peuvent désormais accéder à diverses sources de données via une interface utilisateur uniforme, avec des autorisations cohérentes gérées en un seul endroit », a déclaré Jelle de Jong, Tech Lead chez Bayer. « Nous standardisons continuellement notre format de données sur Delta Lake, mais nous sommes ravis que Lakehouse Federation nous ait permis d'itérer avec agilité avant d'investir dans l'extraction de données. »
La fragmentation des données ralentit l'innovation
Des milliers d'organisations de toutes tailles innovent dans le monde entier et dans tous les Secteurs d'activité grâce aux données et à l'IA sur la Databricks Lakehouse Platform. Mais pour des raisons historiques, organisationnelles ou technologiques, les données sont dispersées dans de nombreux systèmes opérationnels et analytiques, ce qui entraîne de nouveaux défis :
- Difficulté à découvrir et à accéder à toutes les données : la plupart des organisations disposent de données précieuses réparties sur plusieurs sources de données. Elles peuvent se trouver dans plusieurs bases de données, un data warehouse, des systèmes de stockage d'objets, et plus encore. Cela se traduit par des données et des insights incomplets, ce qui empêche les clients de prendre des décisions éclairées et d'innover plus rapidement.
- Exécution lente en raison de goulots d'étranglement techniques : pour interroger des données sur plusieurs sources de données, les clients doivent généralement d'abord déplacer leurs données depuis des sources de données externes vers la plateforme de leur choix. Certaines données pourraient ne même pas en valoir la peine. Certaines données mettront trop longtemps à parvenir à un emplacement unique et unifié, ce qui ralentit l'innovation.
- Faible conformité sur des systèmes en silos : la gouvernance fragmentée entraîne une duplication des efforts et augmente le risque de ne pas pouvoir surveiller et se prémunir contre les accès inappropriés ou les fuites, ce qui entrave la collaboration et la démocratisation des données.
Unifiez votre patrimoine de données avec Lakehouse Federation dans Unity Catalog
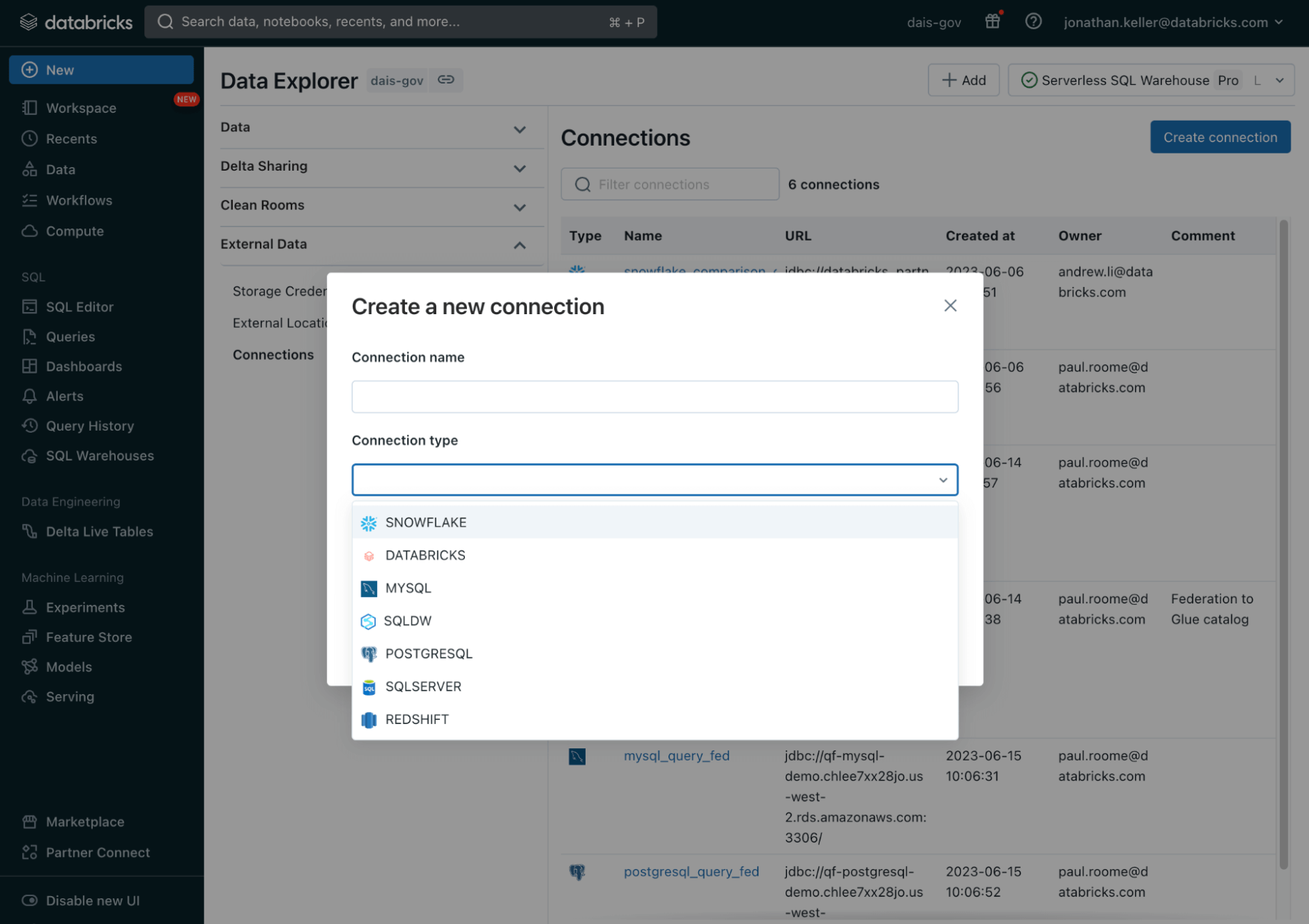
Lakehouse Federation répond à ces points de friction critiques et permet aux organisations d'exposer, de query et de gouverner facilement les systèmes de données cloisonnés en tant qu'extension de leur lakehouse. Avec ces nouvelles fonctionnalités, vous pouvez :
- Créez une vue unifiée de votre patrimoine de données : Classez et découvrez automatiquement toutes vos données, structurées et non structurées, en un seul endroit et permettez à tous les membres de votre organisation d'accéder en toute sécurité et d'explorer toutes les données disponibles à portée de main, où qu'elles se trouvent.
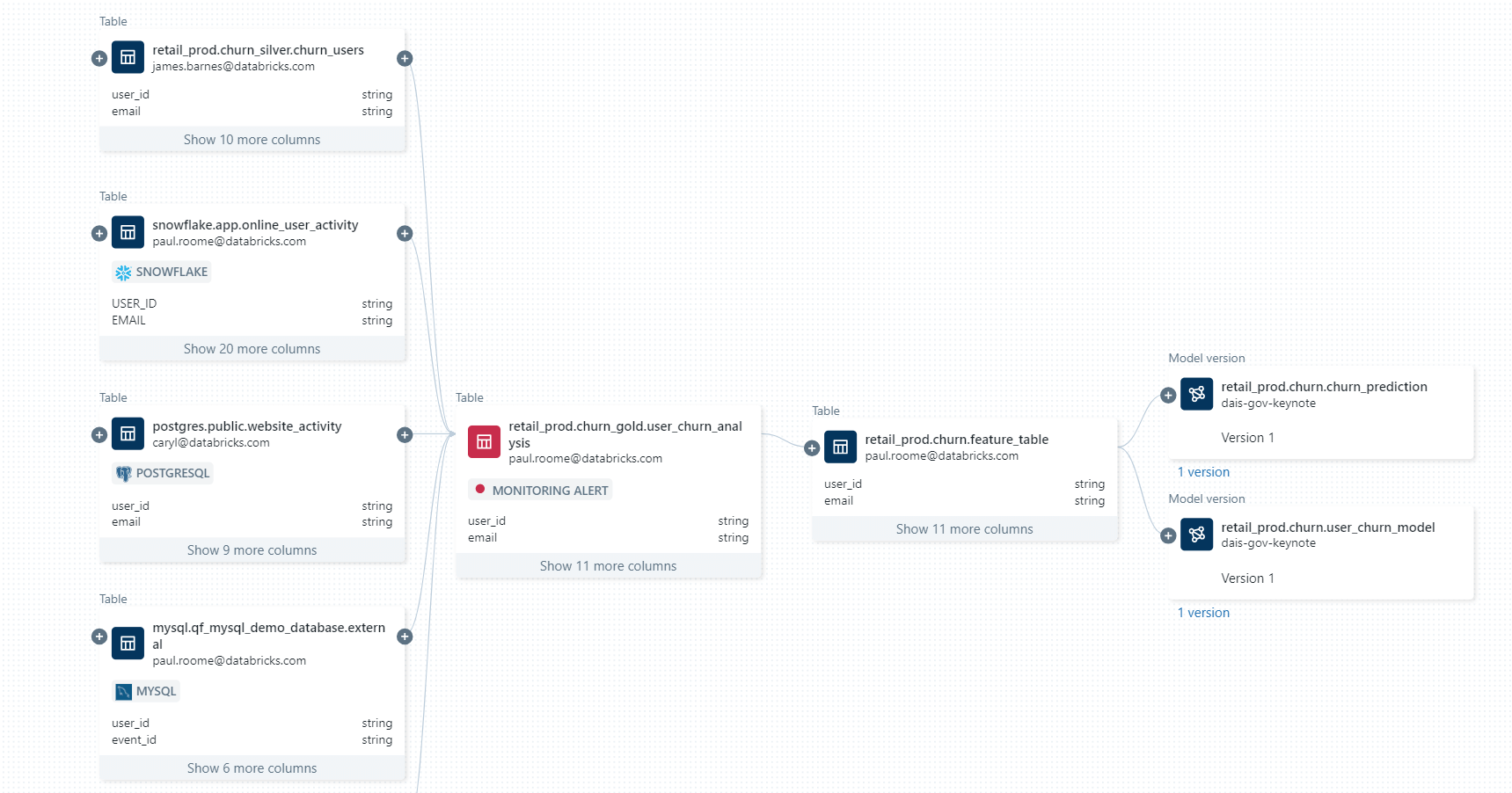
- Interrogez et combinez efficacement toutes les données avec un moteur unique : Accélérez l'analyse ad hoc et le prototypage pour tous vos cas d'utilisation de données, d'analytique et d'IA sur les données les plus complètes — aucune ingestion requise — avec un moteur unique. La planification avancée des requêtes sur plusieurs sources et la mise en cache garantissent des performances de requête optimales, même lors de l'accès et de la combinaison de données provenant de plusieurs plateformes avec une seule requête.
- Protégez les données sur l'ensemble des sources de données : utilisez un seul modèle d'autorisation pour définir et appliquer des règles d'accès et protéger toutes vos données sur l'ensemble des sources de données. Appliquez des règles telles que la sécurité au niveau des lignes et des colonnes, les politiques basées sur des tags et l'audit centralisé de manière cohérente sur toutes les plates-formes, suivez l'utilisation des données et répondez aux exigences de conformité grâce au data lineage et à l'auditabilité intégrés.
« Lakehouse Federation nous permet de combiner des données (telles que les données d'utilisation, de Ventes et de télémétrie de jeu) provenant de sources multiples, à travers plusieurs clouds, et de tout consulter et interroger depuis un seul endroit. » « Désormais, nous laissons les données dans la source de données d'origine, mais nous pouvons les utiliser depuis le Lakehouse Databricks », a déclaré Felix Baker, Head of Data Services chez SEGA Europe. « Comme nous n'avons plus à déplacer nos données financières, qui sont fréquemment actualisées, nous gagnons un temps précieux que nous pouvons consacrer à offrir à nos consommateurs la meilleure expérience de jeu possible. »
« Lakehouse Federation nous a permis de consolider plus rapidement notre paysage de données existant dans Unity Catalog. Cela simplifie la gouvernance des données de Shell – davantage de datasets deviennent découvrables en un seul endroit, l'authentification est normalisée et l'interrogation de datasets avec un langage de programmation commun devient possible », a déclaré Bryce Bartmann, conseiller principal en Technologie digital chez Shell. « En fin de compte, cela nous rend plus efficaces pour naviguer dans la transformation qui s'opère aujourd'hui dans le secteur de l'énergie. »
Ces nouvelles fonctionnalités, associées à l'interface Hive ouverte récemment annoncée, permettent aux organisations de centraliser la gestion de données, la découverte et la gouvernance de leurs données dans Unity Catalog, et de s'y connecter à partir d'un large éventail de plateformes de calcul, notamment Amazon EMR, Apache Spark, Amazon Athena, Presto, Trino et d'autres. La nouvelle interface élimine le besoin de maintenir plusieurs data catalogs et garantit une gouvernance cohérente des données sur ces plateformes.
Et ensuite ?
Ces fonctionnalités sont actuellement en préversion publique, vous pouvez donc démarrer dès maintenant !
Nous étendons également les capacités de gouvernance de Unity Catalog à divers formats de stockage ouverts, notamment Apache Iceberg et Hudi, avec la préversion publique du format universel Delta (« UniForm »). Cette intégration permet de lire les tables Delta comme s'il s'agissait de tables Iceberg (et bientôt Apache Hudi également), faisant de Unity Catalog le seul catalogue universel qui prend en charge les trois principaux formats de stockage ouverts de lakehouse.
Enfin, à l'avenir, vous pourrez également propager les politiques d'accès définies dans Unity Catalog aux sources de données fédérées pour une application cohérente, quel que soit l'endroit où les données sont consultées. Il n'est ainsi plus nécessaire de maintenir des définitions de politiques redondantes sur différents outils de gouvernance.
Regardez la keynote du Data+AI Summit 2023 de Matei Zaharia, co-fondateur et Chief Technologie Officer de Databricks, pour en savoir plus.
Inscrivez-vous au Data + AI Summit ici pour nous rejoindre en personne ou virtuellement et découvrir les nouveautés en matière de données, d'analytique et d'IA !
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.