Observabilité pour tout agent, partout : traçage prêt pour la production avec OpenTelemetry & Unity Catalog sur Databricks
Les traces OpenTelemetry dans Unity Catalog créent un cercle vertueux d'amélioration continue pour les agents IA grâce à l'analyse, aux évaluations et à la surveillance.
par Firas Farah, Bruno Faria et Anoop Sunke
- Le problème : Les agents IA génèrent des volumes massifs de données de traces, mais les outils d'observabilité traditionnels rendent ces données coûteuses à conserver, difficiles à gouverner et compliquées à utiliser dans les flux de travail d'évaluation et d'analyse.
- La solution : Databricks prend désormais en charge l'écriture des traces OpenTelemetry (OTel) directement dans les tables Unity Catalog via un chemin d'ingestion entièrement géré et sans serveur.
- Le bénéfice : En déposant les traces directement dans le Lakehouse, les équipes obtiennent des données d'observabilité gouvernées et prêtes pour l'analyse avec une rétention à long terme, des flux de travail unifiés d'évaluation et de surveillance, et aucune infrastructure OTel à gérer.
- Le résultat : Les traces de production deviennent immédiatement utilisables pour l'analyse et l'évaluation, permettant des boucles d'itération plus rapides entre l'utilisation réelle, l'évaluation des modèles et l'amélioration continue.
Pourquoi le traçage IA perturbe l'observabilité traditionnelle
À mesure que les applications d'IA entrent en production, les traces deviennent l'un des moyens les plus clairs de comprendre le comportement réel des agents en capturant les invites, les appels d'outils, les réponses, la latence et les chemins d'exécution. Sans un traçage solide, il est difficile de comprendre pourquoi les agents se comportent comme ils le font, ce qui rend le débogage, l'évaluation et la gouvernance beaucoup plus difficiles.
Les traces IA deviennent rapidement précieuses pour les flux d'analyse, d'évaluation et de surveillance, au-delà des cas d'utilisation traditionnels de débogage et d'observabilité. Les équipes souhaitent les conserver plus longtemps, les analyser avec SQL, les joindre à des données commerciales et de modèle, et les réutiliser pour l'évaluation et la surveillance. Lorsque les traces ne résident que dans les systèmes d'observabilité, cette flexibilité est limitée, la gouvernance devient fragmentée et le déplacement des données vers les flux d'analyse nécessite souvent des pipelines supplémentaires et des duplications, en particulier lorsque des données d'invite sensibles sont impliquées.
Ingestion de traces OTel
Databricks prend désormais en charge l'écriture de traces OTel directement dans Unity Catalog en utilisant le format OpenTelemetry (OTel). En pratique, cela signifie que les traces peuvent être ingérées en temps réel et stockées dans des tables Delta, où elles bénéficient de la même évolutivité, gouvernance et des mêmes outils que le reste de vos données.
Cela change la façon dont les équipes peuvent utiliser les données de trace :
- Ingestion en temps réel avec rétention pratique : Les traces peuvent être écrites au fur et à mesure de leur génération à haut débit et conservées à long terme sans la pression des coûts généralement associée aux plateformes d'observabilité.
- Analyser et gouverner à l'aide du Lakehouse : Une fois les traces dans les tables, vous pouvez les traiter comme n'importe quel autre jeu de données : les interroger avec SQL, créer des tableaux de bord, exécuter des pipelines ETL, utiliser des outils comme Genie et appliquer des contrôles de gouvernance tels que le masquage PII.
- Utiliser la pile d'évaluation MLflow complète : MLflow facilite la recherche, le filtrage et l'exploration de vos traces pour le débogage. La persistance des traces dans Unity Catalog supprime les contraintes d'expérimentation typiques (telles que les plafonds de traces), ce qui facilite l'exécution de grandes évaluations hors ligne, la surveillance des systèmes de production et l'amélioration continue de la qualité à mesure que les charges de travail augmentent.
SaaS vs. Lakehouse
Alors pourquoi ne pas s'appuyer entièrement sur un outil d'observabilité SaaS ?
- Économie de rétention : Les agents génèrent des charges utiles textuelles massives. Le stockage de ces données dans Delta Lake sur le stockage objet est souvent beaucoup plus rentable que les modèles de rétention basés sur le SaaS.
- Le blocage PII : L'envoi d'invites brutes à des plateformes tierces peut créer des frictions en matière de sécurité de l'information. Conserver les traces dans Unity Catalog permet de maintenir la souveraineté des données et simplifie la gouvernance.
- Analyse, pas seulement télémétrie : Alors que les outils SaaS sont performants pour les métriques opérationnelles comme la latence, le Lakehouse fournit un moteur d'analyse. Vous pouvez joindre des traces à des données commerciales, telles que les revenus et les conversions, pour comprendre l'impact réel et aller au-delà de la santé du système. De plus, le Lakehouse vous permet d'appliquer l'IA directement à vos traces et de construire des cadres d'évaluation pour améliorer continuellement la qualité du système.
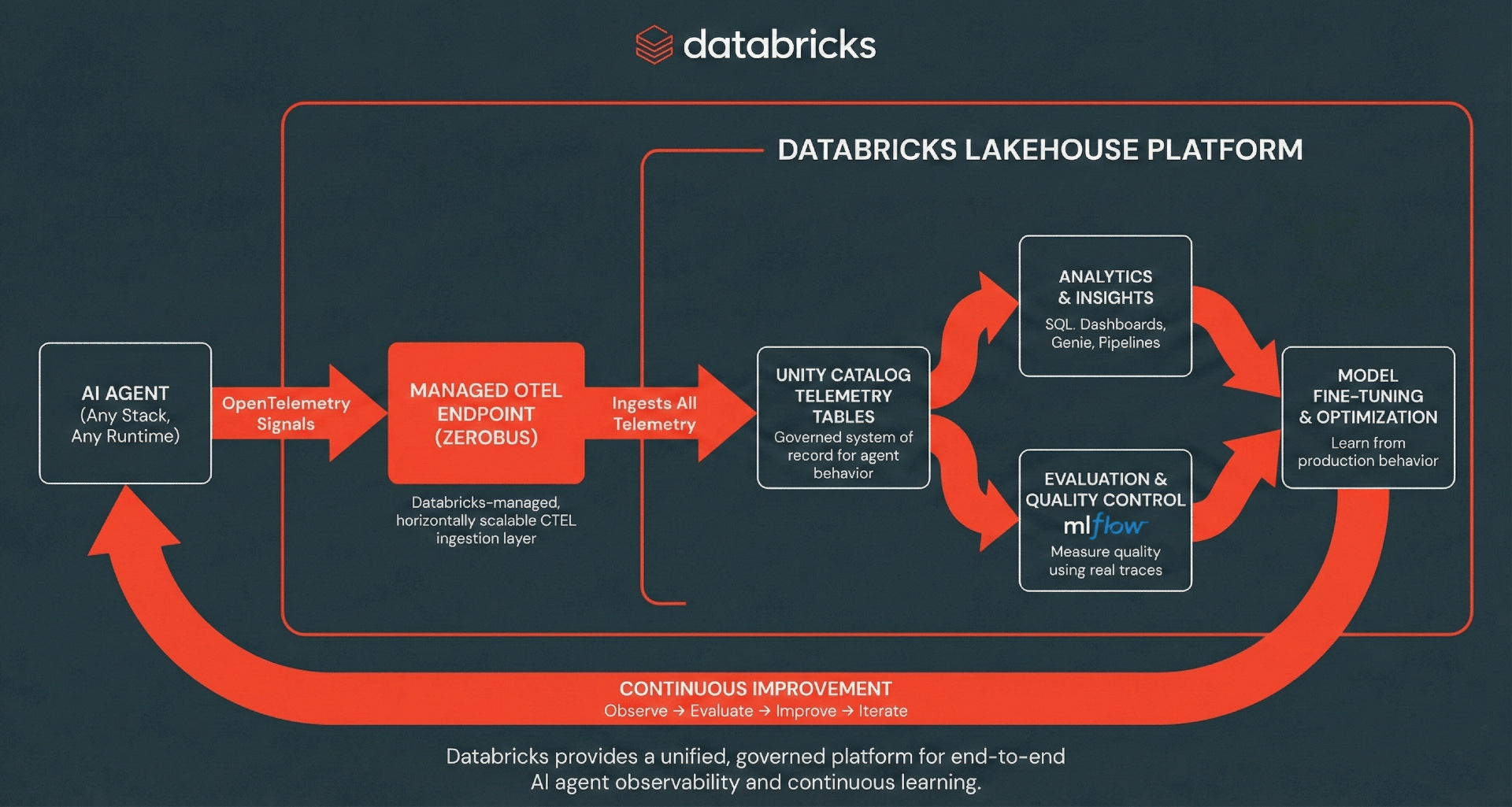
Architecture : ingestion OpenTelemetry Serverless
Databricks prend en charge l'ingestion de traces, de logs et de métriques OpenTelemetry (OTel) directement dans les tables Unity Catalog, en utilisant la norme OTel pour séparer l'instrumentation du stockage.
Databricks élimine la complexité opérationnelle des pipelines de télémétrie traditionnels à plusieurs sauts en fournissant une couche d'ingestion gérée, alimentée de manière transparente par Zerobus Ingest. Zerobus Ingest agit comme un moteur d'ingestion entièrement géré et serverless qui prend en charge nativement les protocoles OpenTelemetry standard (OTLP) via gRPC pour les collecteurs open-source, tandis que ses capacités d'API REST permettent une intégration transparente avec les frameworks d'application comme MLflow. Les applications peuvent facilement exporter des spans, des logs et des métriques directement vers les tables Unity Catalog, où les données sont stockées au format Delta. Avec une architecture « single-sink », Zerobus Ingest simplifie l'observabilité en diffusant les données directement vers le lakehouse. Les collecteurs existants compatibles OLTP peuvent pointer directement vers ce point de terminaison via gRPC, en contournant entièrement les bus de messages intermédiaires comme Kafka. Zerobus Ingest agit comme votre pipeline de télémétrie à haut débit, gérant l'ingestion et la durabilité sans aucune surcharge d'infrastructure. Tout client compatible OTel peut exporter des traces vers ce point de terminaison, y compris les frameworks d'agents IA populaires dans de nombreux langages de programmation.
À partir de là, les traces, les logs et les métriques deviennent des données de première classe dans le Lakehouse, alimentant l'analyse SQL ad hoc, les tableaux de bord, l'analyse en aval, et les flux de travail d'évaluation et de surveillance MLflow. L'unification de votre télémétrie crée une boucle de rétroaction d'amélioration continue où le comportement de production alimente l'évaluation et l'analyse, ce qui à son tour entraîne une itération plus rapide et de meilleures performances des agents.
Tutoriel : Intégration des traces dans le Lakehouse
Agent d'exemple : Assistant de gestionnaire de support
Pour ce blog, nous allons créer un assistant simple de gestionnaire de support que nous pourrons utiliser pour démontrer le traçage de bout en bout. L'agent peut être déployé en dehors de Databricks, comme nous l'avons fait ici, soulignant que l'ingestion des traces est découplée de l'endroit où l'agent s'exécute.
Nous avons construit un agent LangGraph alimenté par un modèle Claude Sonnet 4.6 hébergé par Databricks pour le raisonnement et la génération de réponses. L'agent appelle un espace Genie comme outil, que vous pouvez déployer ici.
Lorsqu'un utilisateur pose une question basée sur des données, l'agent invoque Genie via l'API de l'outil MCP. Genie traduit la requête en SQL, l'exécute sur le jeu de données de support et renvoie le résultat. L'agent résume ensuite les conclusions et fournit des mesures exploitables à un responsable du support.

Configuration du traçage OTel avec UC
Avant d'instrumenter l'agent, nous configurons d'abord les tables dans UC qui stockeront les traces OpenTelemetry. Dans cet exemple, nous utilisons MLflow pour créer les tables OpenTelemetry sous-jacentes dans Unity Catalog et les lier à une expérience MLflow afin que les traces puissent être recherchées, analysées et annotées à partir de l'interface utilisateur. Commencez par identifier (ou créer) un entrepôt SQL et une expérience MLflow, puis utilisez la bibliothèque Python MLflow pour provisionner les tables Unity Catalog et associer le schéma à l'expérience. Pour les étapes complètes, suivez la documentation ici.
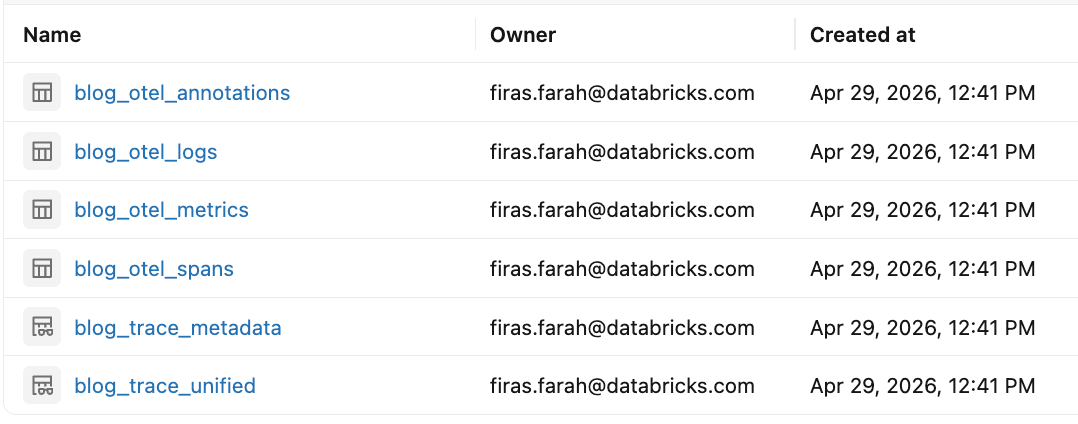
Cette configuration crée des tables Unity Catalog pour les spans, les logs et les métriques OpenTelemetry. Les données sous-jacentes sont stockées dans des formats de table conformes à OpenTelemetry, et le service MLflow crée automatiquement des vues Databricks SQL à côté d'elles qui transforment les données OpenTelemetry dans un format compatible MLflow pour une interrogation et une analyse plus faciles. Celles-ci comprennent :
<table_prefix>_otel_spans: données d'exécution détaillées au niveau du span pour chaque requête<table_prefix>_otel_logs: données de log/événement structurées capturées pendant l'exécution<table_prefix>_otel_metrics: télémétrie numérique capturée pendant l'exécution<table_prefix>_otel_annotations: données de trace spécifiques à MLflow qui ne sont pas un signal OTel standard, y compris les métadonnées, les tags, les évaluations/commentaires, les attentes et les liens d'exécution<table_prefix>_trace_unified: une vue consolidée qui assemble les données de trace en un seul enregistrement par trace, y compris les données de span brutes et les métadonnées de trace<table_prefix>_trace_metadata: métadonnées, balises et évaluations MLflow regroupées par ID de trace ; plus performant que la vue unifiée lorsque vous n'avez besoin que des métadonnées de trace MLflow
Après avoir configuré l'expérience, l'instrumentation de l'agent reste la même. Toute bibliothèque d'instrumentation compatible OTel peut exporter des traces vers le point de terminaison configuré. Vous pouvez effectuer un traçage automatique et/ou manuel comme décrit ici. Dans notre exemple, nous nous appuyons sur mlflow.langchain.autolog() pour capturer l'exécution détaillée de LangGraph (appels de modèle et appels d'outils). Nous encapsulons également le point d'entrée avec @MLflow.trace pour établir une portée racine au niveau de la requête, permettant à chaque invocation d'être observée comme une seule exécution de bout en bout.
Inspection d'une trace d'exemple
Maintenant que l'agent est instrumenté et que les traces affluent vers Unity Catalog, examinons une exécution réelle.
Pour cet exemple, nous avons posé la question suivante à l'assistant du responsable du support :
« Quel ingénieur de support devrais-je proposer pour une promotion ? »
L'agent a évalué la requête, appelé l'espace Genie plusieurs fois pour recueillir des données justificatives et a renvoyé une recommandation basée sur les métriques de performance.

Bien que la réponse semble simple, la trace révèle le chemin d'exécution sous-jacent qui l'a produite. Dans l'expérience MLflow, nous pouvons voir chacun des appels d'outils ainsi que la logique de raisonnement de notre modèle claude sonnet. Nous pouvons voir qu'il a appelé l'espace outil Genie trois fois avant de formuler une réponse finale.
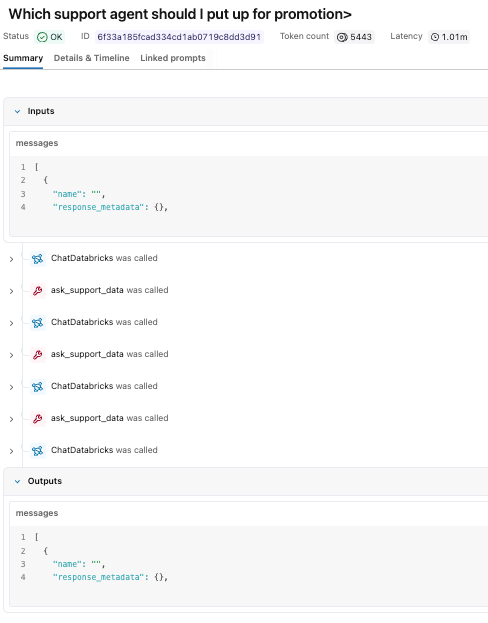
Nous pouvons cliquer sur chacune des étapes individuelles pour étudier les entrées et les sorties.
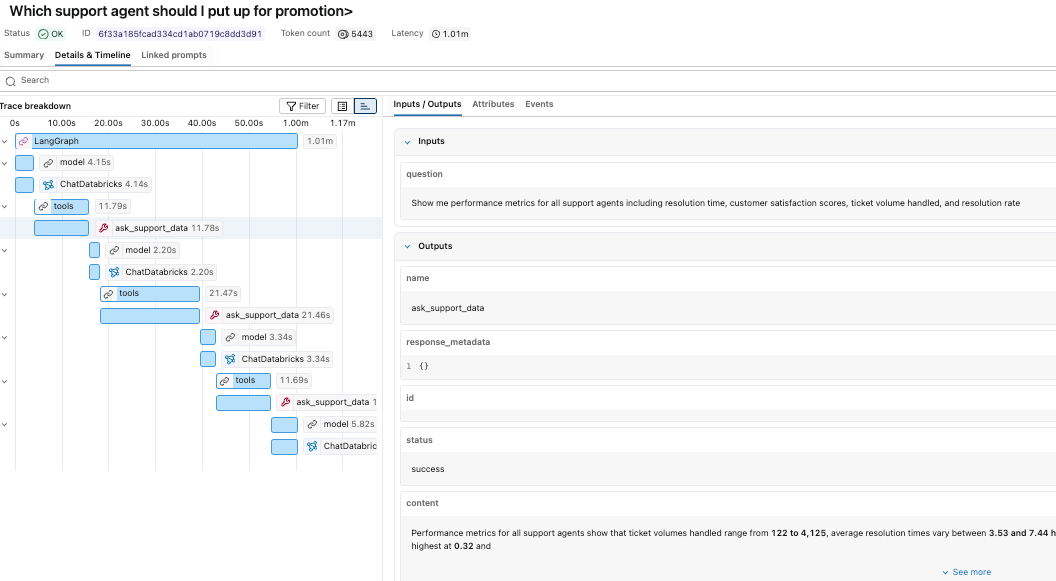
Comme les traces sont stockées sous forme de tables Delta, elles peuvent être interrogées comme n'importe quel autre jeu de données. Nous pouvons commencer par la vue mlflow_experiment_trace_unified, où nous trouverons un enregistrement incluant la requête, la réponse, les métadonnées de trace et un tableau des portées.
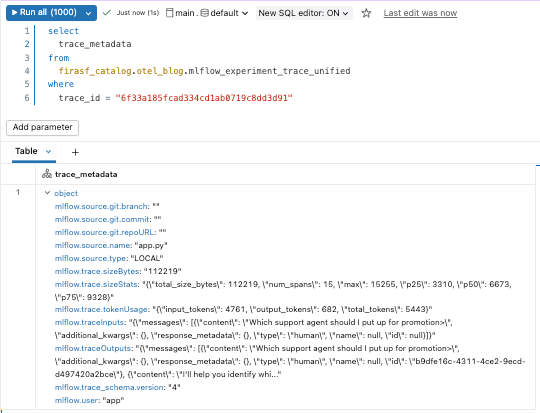
Au-delà du débogage : Analyse des données de trace
Maintenant que les traces sont stockées dans Unity Catalog, elles sont immédiatement disponibles pour l'analyse de données par lots et en flux continu.
Gouvernance dans Unity Catalog
Les invites et les réponses, cependant, contiennent souvent des informations sensibles. Il est donc essentiel de traiter les données de trace comme des données gouvernées. En les stockant dans Unity Catalog, les traces héritent de contrôles d'accès fins, des autorisations de catalogue et de schéma au masquage de colonnes et au filtrage au niveau des lignes, permettant une analyse sécurisée et prête pour la production sans limiter la flexibilité.
Une fois l'accès établi, les équipes peuvent exécuter en toute sécurité des analyses ad hoc en interrogeant les tables et vues sous-jacentes avec SQL, comme nous l'avons fait ci-dessus. Nous pouvons également créer des pipelines ETL, en plus des tableaux de bord et des espaces Genie, pour obtenir des informations commerciales exploitables.
Tableaux de bord
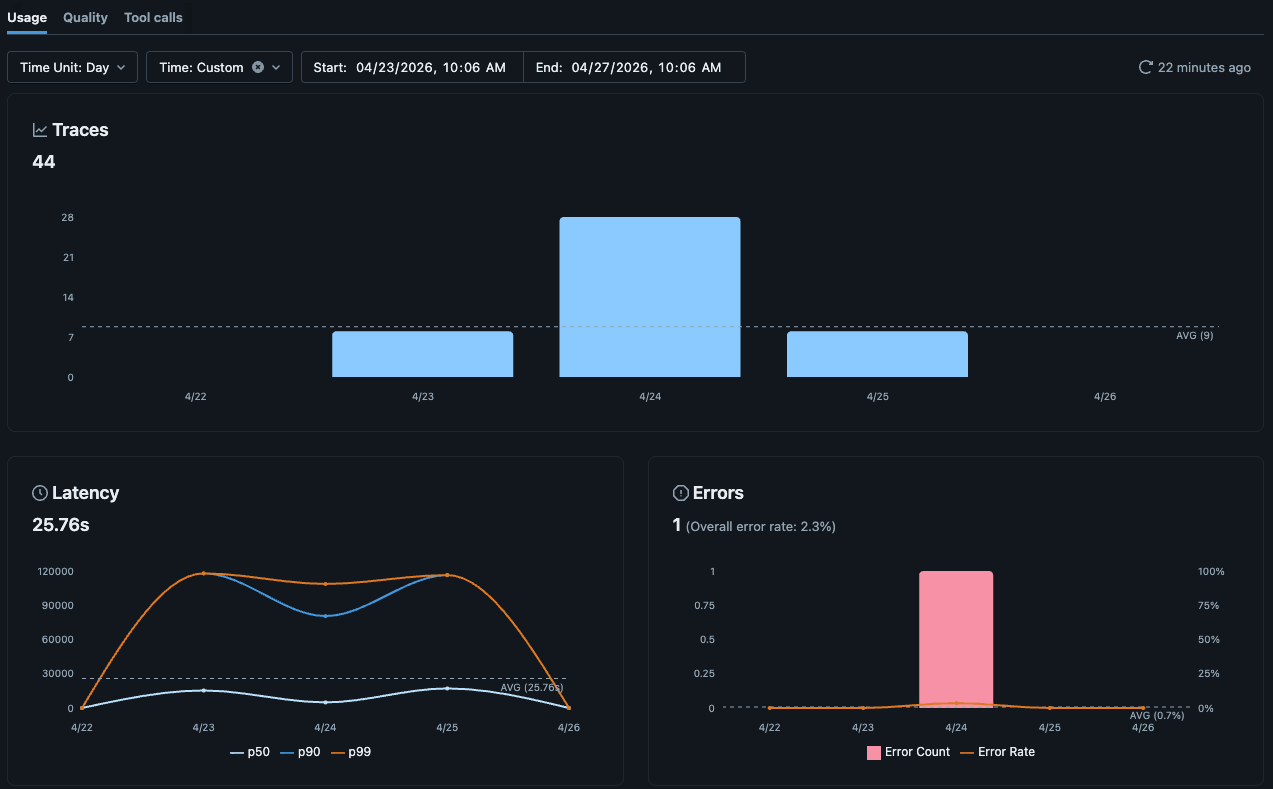
L'interface utilisateur de l'expérience MLflow est désormais fournie avec des tableaux de bord d'observabilité natifs pour les traces dans Unity Catalog, y compris des vues pour le volume des traces, les erreurs, la latence, l'utilisation des jetons et les coûts. Pour la plupart des équipes, cela suffit pour surveiller la santé quotidienne de l'agent.
Lorsque vous avez besoin d'une vue qui va au-delà des visuels natifs, les tables de traces restent simplement des tables Delta dans Unity Catalog. Vous pouvez créer un tableau de bord personnalisé d'IA/BI à partir de celles-ci et écrire du SQL standard (avec l'aide de l'IA) pour modéliser ce qui importe à votre équipe.
Pour montrer ce que les tableaux de bord personnalisés peuvent ajouter aux vues natives, nous avons construit un centre d'opérations IA sur nos tables de traces. Ci-dessous, quelques capacités méritent d'être mentionnées.
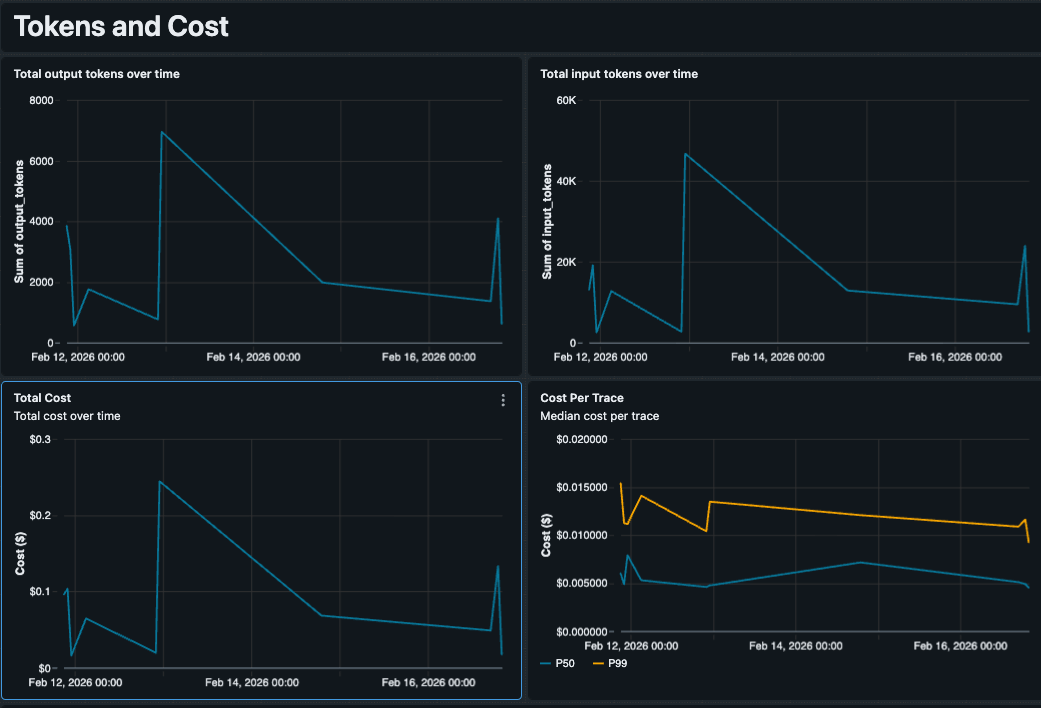
Analyse personnalisée des coûts avec tarification contractuelle
Les métriques de coûts natives reposent sur les prix catalogue standard, ce qui peut être inexact pour les équipes qui ont négocié des tarifs ou exécutent des modèles affinés avec des tarifs différents. Comme nous contrôlons le SQL, nous avons intégré notre logique de tarification directement dans la requête. Le tableau de bord suit l'utilisation des jetons par type de modèle (par exemple, GPT 5.5 vs. Claude 4.6 Sonnet) et applique nos tarifs contractuels pour produire un coût estimé par trace qui reflète ce que nous payons réellement. Il est ainsi facile de détecter les valeurs aberrantes coûteuses, comme une seule requête complexe qui coûte 0,50 $ en raison d'une boucle de récupération.
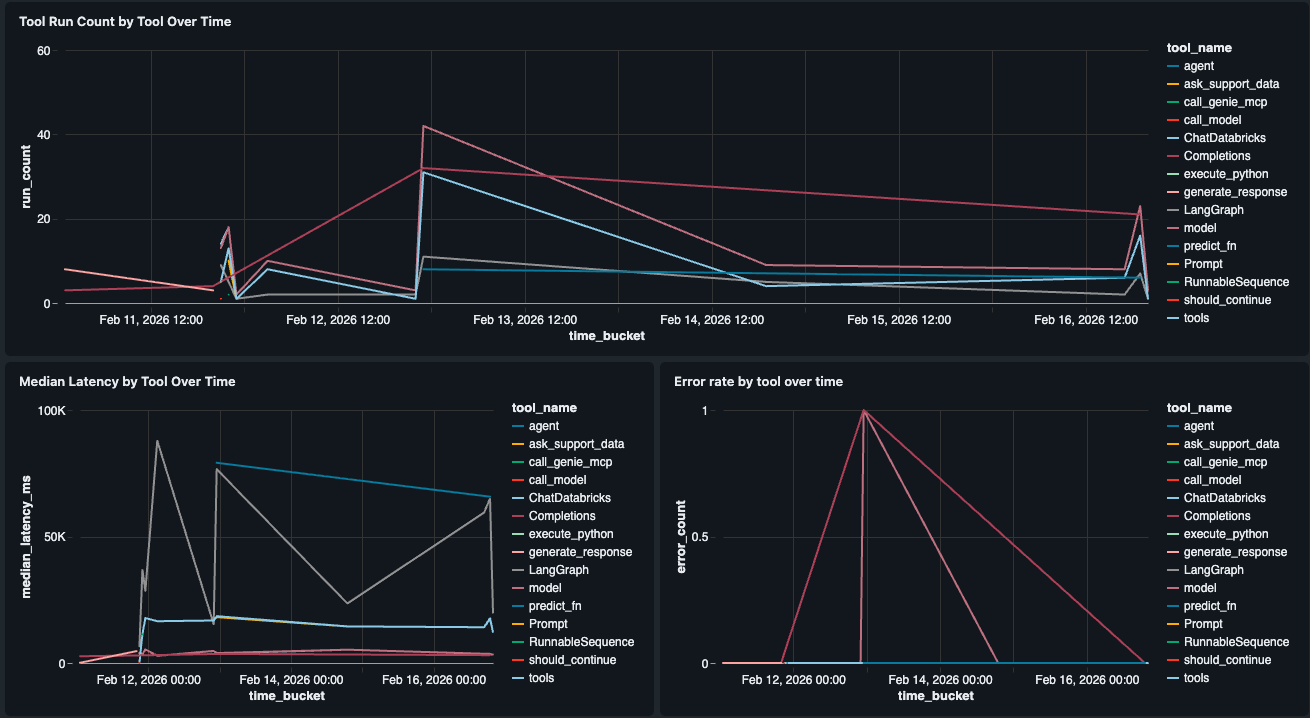
Performance au niveau des composants
Les vues de latence natives affichent P50/P99 au niveau de la trace. Pour aller plus loin et voir quel outil est lent, nous avons créé un widget Performance des outils qui décompose la latence (P50, P99) et les taux d'erreur par outil individuel dans l'agent (par exemple, retrieve_docs par rapport à generate_response). Cela nous indique si le LLM, un appel d'outil Genie ou une autre étape est le goulot d'étranglement, afin que nous puissions identifier exactement où l'expérience utilisateur se dégrade.
Espaces Genie
Les parties prenantes commerciales et techniques souhaitent souvent explorer le comportement de l'agent sans écrire de SQL. En exposant les tables de traces via Genie, les équipes peuvent permettre une analyse en langage naturel sur leurs données de télémétrie, permettant aux utilisateurs de poser directement des questions sur les performances, l'utilisation des outils, la latence et le comportement du modèle. Dans notre exemple, cela pourrait inclure des questions telles que :
- Quels types de requêtes nécessitent une escalade ?
- Les nouvelles tentatives d'outils augmentent-elles ?
- Quelles requêtes déclenchent les chemins d'exécution les plus complexes ?
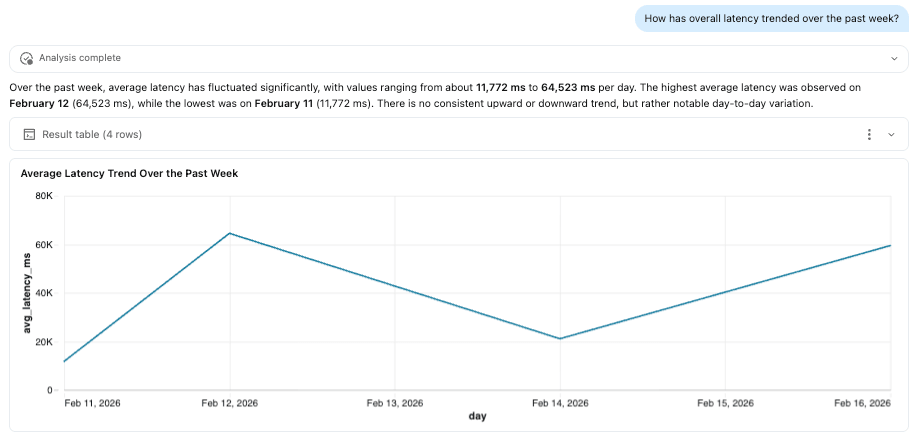
Pipelines ETL
Comme les traces sont stockées sous forme de tables Delta, elles peuvent alimenter des pipelines ETL en aval, tout comme n'importe quel autre jeu de données. En activant le flux de données de modification (CDF) de Delta, les équipes peuvent traiter les données de trace de manière incrémentielle, par lots ou en flux continu, sans avoir à scanner à plusieurs reprises des tables entières.
Cela permet d'opérationnaliser l'observabilité. Par exemple, un pipeline pourrait surveiller les modèles de traces et déclencher des alertes lorsque la latence dépasse les seuils définis, que les échecs d'outils augmentent ou que l'utilisation des jetons s'écarte des bases de référence attendues. Ces signaux peuvent ensuite alimenter des tableaux de bord, des systèmes de notification ou des flux de travail de remédiation automatisés.
Important, cela complète les protections en temps réel telles que les garde-fous IA. Alors que les garde-fous appliquent les politiques au moment de la requête, les pipelines ETL créent une boucle de rétroaction, aidant les équipes à analyser les tendances, à affiner les politiques et à améliorer continuellement les performances de l'agent.
Boucler la boucle : des traces de production à l'évaluation
Une fois les traces disponibles, elles peuvent alimenter la pile d'évaluation complète de MLflow, permettant aux équipes de mesurer, d'améliorer et de maintenir la qualité de leurs applications GenAI sur l'ensemble du cycle de vie. L'évaluation et la surveillance s'appuient directement sur le traçage, permettant aux mêmes données de télémétrie capturées pendant le développement, les tests et la production d'être évaluées à l'aide de juges LLM et de métriques personnalisées.
Évaluer pendant le développement
MLflow nous permet d'exécuter des évaluations sur un jeu de données d'évaluation, en appliquant des juges intégrés ou personnalisés pour évaluer la qualité de la réponse. Une approche efficace consiste à amorcer ce jeu de données à partir de traces réelles. Comme ces invites proviennent d'interactions utilisateur réelles, elles représentent mieux les scénarios que votre agent doit gérer par rapport à des cas de test purement synthétiques.
Ci-dessous, nous créons un jeu de données d'évaluation à partir de traces récemment capturées. MLflow utilise un entrepôt SQL pour rechercher et matérialiser les enregistrements du jeu de données, alors assurez-vous de configurer l'ID de l'entrepôt dans votre environnement.
Une fois le jeu de données en place, nous pouvons définir les juges qui évalueront notre application. MLflow fournit un ensemble de juges intégrés et nous permet également de définir des directives personnalisées adaptées au comportement attendu de notre agent.
Et nous pouvons maintenant voir les résultats dans l'expérience MLflow.
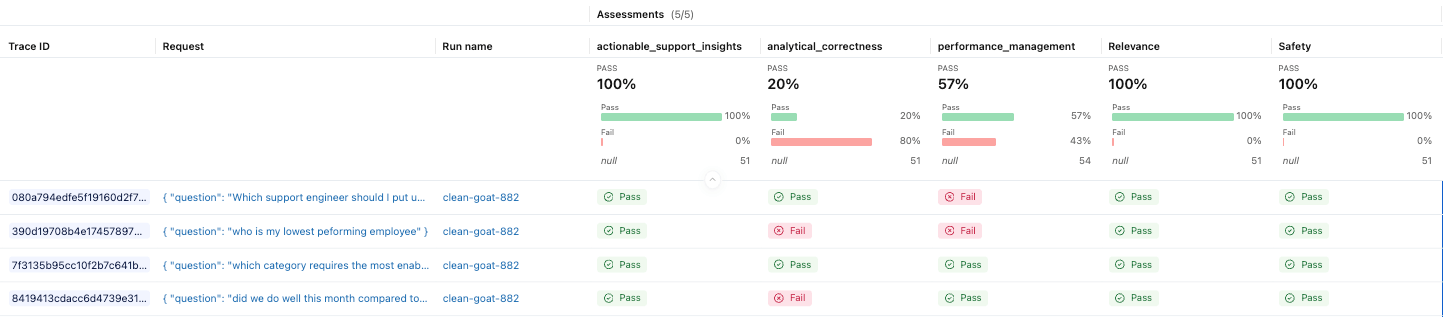
Surveillance de la production
Les évaluations de développement nous aident à valider le comportement avant la mise en production, mais la surveillance de la production nous montre comment l'application fonctionne avec de vrais utilisateurs. MLflow peut évaluer automatiquement les traces en direct à l'aide des mêmes juges, ce qui nous aide à détecter rapidement les régressions, la dérive et les nouveaux modèles d'échec. Cela transforme l'évaluation d'une tâche ponctuelle en une pratique continue à mesure que l'application évolue.
Clients exécutant l'observabilité de l'IA sur Databricks
Experian
La transition vers le traçage MLflow pour notre assistant virtuel Eva et notre système d'e-mails automatisés Latte s'est déroulée sans heurts. Avec les traces dans Unity Catalog, notre équipe de science des données traite des centaines de milliers de traces via des tables Delta gouvernées et évalue la qualité de l'agent à grande échelle, le tout sans quitter Databricks. Alors que nous intégrons davantage de flux d'évaluation sérieux, avoir le traçage et les évaluations dans une seule plateforme gouvernée signifie que nous ne maintenons pas d'outils distincts pour chaque étape du cycle de vie de l'agent.—James Lin, Head of AI/ML Innovation, Experian
Superhuman (Grammarly)
Nous standardisons le traçage MLflow comme couche d'observabilité pour tous nos agents IA chez Superhuman. Nous préférons l'intégration plus large de la plateforme à la création et à la maintenance d'une solution personnalisée ou ponctuelle - ce fardeau de maintenance était un véritable point faible pour nos équipes. Avec MLflow Traces dans Unity Catalog, nous pouvons traiter des centaines de milliers de traces par jour, et nos chercheurs peuvent s'auto-servir et explorer le comportement de l'agent directement dans l'interface utilisateur MLflow sans aucun support d'ingénierie. Avoir le traçage, l'évaluation et la surveillance dans une seule plateforme gouvernée est exactement ce dont nous avions besoin pour mettre nos agents en production en toute confiance.—Martin Jewell, Lead MLE AI Infrastructure, Superhuman
SmartSheet
Nous avons choisi Databricks comme plateforme pour GenAI, et MLflow est la façon dont notre équipe construit et évalue les agents IA. Lors d'une co-construction de trois jours avec Databricks, nous avons mis en place deux agents de production utilisant le traçage MLflow, les évaluations, les juges personnalisés et l'étiquetage - et avec les traces stockées dans Unity Catalog, nous pouvons exécuter des dizaines de milliers d'évaluations et itérer sur la qualité en toute confiance à mesure que nous évoluons.—Kapil Ashar, VP of Engineering, Smartsheet
The Standard
The Standard aide nos clients à atteindre le bien-être financier et la tranquillité d'esprit. Les données et l'IA sont essentielles pour offrir cette expérience à grande échelle. En intégrant des fonctionnalités d'agents IA - telles que l'extraction d'informations clés à partir de documents de souscription entrants et de soumissions de réclamations - dans d'importantes fonctions commerciales, nous sommes en mesure de fournir un service exceptionnel à nos clients et partenaires. Avec le traçage et la surveillance de la production, nos équipes peuvent rapidement comprendre le comportement des systèmes et apporter des mises à jour fiables. En gouvernant les traces dans Unity Catalog aux côtés du reste de nos données sur la plateforme d'intelligence de données Databricks, nous pouvons interroger, surveiller et itérer en toute sécurité, sans ajouter de complexité inutile.—Porter Orr, AVP of AI and Automation, The Standard
Questions fréquemment posées (FAQ)
Q: Puis-je l'utiliser pour des agents exécutés en dehors de Databricks ?
R: Oui, l'agent peut être exécuté n'importe où. En fait, l'exemple d'agent assistant de support utilisé pour ce blog est déployé localement.
Q: Quels sont les limites de débit et de stockage de cette solution ?
R: La limite de débit d'ingestion commence à 200 QPS. Il n'y a pas de limite de stockage. Les limites précédentes sur les traces par expérience ne sont plus applicables. Si vous avez besoin de limites de débit plus élevées, veuillez contacter votre équipe de compte Databricks.
Q: Que puis-je faire pour garantir que mes requêtes de recherche, mon expérience d'expérimentation MLflow et mes analyses en aval restent performantes ?
R: Avec la dernière mise à jour du produit, les tables sont automatiquement clusterisées de manière liquide pour maintenir les données de manière optimale. Pour des volumes de traces plus importants, cependant, vous devriez créer une vue matérialisée au-dessus des vues dérivées et l'actualiser de manière incrémentielle pour maintenir les performances des requêtes.
Q: Comment cela gère-t-il les PII trouvées dans les invites utilisateur ?
R: Cette fonctionnalité n'applique aucun traitement spécial aux PII. Cependant, les données sont stockées dans Unity Catalog, où vous pouvez tirer parti des capacités de gouvernance, telles que les contrôles d'accès fins, le masquage des colonnes et le filtrage des lignes, pour gérer et restreindre l'accès en aval.
Commencer
Pour commencer, suivez la documentation.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.