Qu'est-ce que Sparklyr ?
Un package R qui fournit une syntaxe de type dplyr pour Apache Spark, permettant aux utilisateurs de R d'effectuer des manipulations de données distribuées et de l'apprentissage automatique sur des ensembles de données massifs.
- Offre la syntaxe familière de dplyr (select, filter, mutate, group_by) qui se traduit de manière transparente en opérations Spark distribuées sur des jeux de données trop volumineux pour un traitement R local.
- S'intègre à Spark MLlib et H2O SparkingWater pour l'apprentissage automatique distribué et prend en charge les fonctions définies par l'utilisateur via spark_apply pour des calculs R personnalisés à grande échelle.
- Se connecte aux clusters Databricks via la méthode « databricks » de spark_connect, fonctionnant avec SparkR et compatible avec RStudio pour le développement et le débogage interactifs.
Qu'est-ce que Sparklyr ?
Sparklyr est un paquet open source qui fournit une interface entre R et Apache Spark. Vous pouvez désormais exploiter les capacités de Spark dans un environnement R moderne, car Spark peut interagir avec les données distribuées avec une faible latence. Sparklyr est un outil efficace qui sert d'interface avec les grands datasets dans un environnement interactif. Vous pouvez ainsi utiliser les outils bien connus de R pour analyser les données dans Spark, en profitant du meilleur des deux mondes. 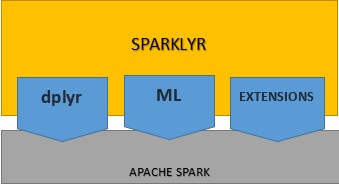 Avec Sparklyr, vous pouvez utiliser Spark comme back-end de dplyr, un paquet de manipulation des données populaire. Sparklyr offre un large éventail de fonctions donnant accès aux outils Spark pour transformer et prétraiter les données. Surtout, il sert d'interface avec les algorithmes de machine learning distribué de Spark, entre autres. Autre avantage, Sparklyr est extensible. Il est possible de créer des paquets R dépendants de Sparklyr pour appeler toute l'API Spark. Rsparkling de H2O est justement une extension de ce type : ce paquet R est compatible avec l'algorithme de machine learning de H2O.
Avec Sparklyr, vous pouvez utiliser Spark comme back-end de dplyr, un paquet de manipulation des données populaire. Sparklyr offre un large éventail de fonctions donnant accès aux outils Spark pour transformer et prétraiter les données. Surtout, il sert d'interface avec les algorithmes de machine learning distribué de Spark, entre autres. Autre avantage, Sparklyr est extensible. Il est possible de créer des paquets R dépendants de Sparklyr pour appeler toute l'API Spark. Rsparkling de H2O est justement une extension de ce type : ce paquet R est compatible avec l'algorithme de machine learning de H2O.
Le guide pratique de l'IA agentique pour l'entreprise

Principaux avantages de Sparklyr :
- Les utilisateurs peuvent manipuler les données Spark de façon interactive en utilisant aussi bien dplyr que SQL (via DBI).
- Les datasets Spark peuvent �être filtrés et agrégés avant d'être importés dans R à des fins d'analyse.
- Vous pourrez alors orchestrer du machine learning distribué depuis R à l'aide de Spark MLlib ou H2O SparkingWater.
- Les utilisateurs Sparklyr peuvent créer des extensions qui appellent toute l'API Spark et servent d'interface avec les paquets Spark.
- L'outil Sparklyr fournit un back-end dplyr complet, très utile pour manipuler, analyser et visualiser des données.
- Charge les données dans des DataFrames Spark depuis différents emplacements, comme les DataFrames R locaux, les tables Hive et les fichiers CSV, JSON et Parquet.
- Sparklyr est capable de se connecter aussi bien aux instances locales de Spark qu'aux clusters Spark distants
Ressources complémentaires
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.