Detección del sesgo en los datos con SHAP y aprendizaje automático
Lo que el aprendizaje automático y SHAP pueden decirnos sobre la relación entre los salarios de los desarrolladores y la brecha salarial de género
por Sean Owen
Prueba el notebook de Detección de Sesgo en los Datos con SHAP para reproducir los pasos que se describen a continuación y mira nuestro webinar bajo demanda para obtener más información.
La encuesta anual de desarrolladores de StackOverflow concluyó a principios de este año, y amablemente han publicado los resultados (anonimizados) de 2019 para su análisis. Ofrecen una visión detallada de la experiencia de los desarrolladores de software en todo el mundo: ¿cuál es su editor favorito? ¿cuántos años de experiencia? ¿tabulaciones o espacios? y lo más importante, el salario. Los salarios de los ingenieros de software son buenos y, a veces, exorbitantes y dignos de noticia.
La industria tecnológica también es muy consciente de que no siempre está a la altura de sus supuestos ideales meritocráticos. El salario no es una función puramente del mérito, y una historia tras otra nos cuenta que factores como una escuela de renombre, la edad, la raza y el género tienen un efecto en resultados como el salario.
¿El aprendizaje automático puede hacer algo más que predecir cosas? ¿Puede explicar los salarios y así destacar los casos en los que estos factores podrían estar causando diferencias salariales indeseables? Este ejemplo ilustrará cómo los modelos estándar se pueden aumentar con SHAP (SHapley Additive exPlanations) para detectar instancias individuales cuyas predicciones pueden ser preocupantes y, luego, profundizar en las razones específicas por las que los datos conducen a esas predicciones.
¿Sesgo del modelo o sesgo de los datos?
Aunque este tema se suele caracterizar como la detección del sesgo de un modelo e "" , un modelo no es más que un reflejo de los datos con los que se ha entrenado. Si el modelo es «sesgado», entonces lo ha aprendido a partir de los datos históricos. Los modelos no son el problema en sí mismos; son una oportunidad para analizar datos en busca de indicios de sesgo.
Explicar modelos no es algo nuevo, y la mayoría de las librerías pueden evaluar la importancia relativa de las entradas de un modelo. Estas son vistas agregadas de los efectos de las entradas. Sin embargo, el resultado de algunos modelos de aprendizaje automático tiene efectos muy individuales: ¿se aprobó tu préstamo? ¿recibirás ayuda financiera?, ¿eres un viajero sospechoso?
De hecho, StackOverflow ofrece una calculadora práctica para estimar el salario esperado, basada en su encuesta. Solo podemos especular sobre la precisión general de las predicciones, pero lo único que le importa a un desarrollador son sus propias perspectivas.
Quizás la pregunta correcta no sea si los datos sugieren un sesgo en general, sino si los datos muestran instancias individuales de sesgo.
Evaluación de los datos de la encuesta de StackOverflow
Afortunadamente, los datos de 2019 están limpios y sin problemas de datos. Contiene las respuestas a 85 preguntas de aproximadamente 88,000 desarrolladores.
Este ejemplo se centra únicamente en los desarrolladores de tiempo completo. El conjunto de datos contiene mucha información relevante, como años de experiencia, educación, rol e información demográfica. Cabe destacar que este conjunto de datos no contiene información sobre bonificaciones y participación accionaria, solo sobre el salario.
También contiene respuestas a una amplia gama de preguntas sobre las actitudes hacia blockchain, fizz buzz y la propia encuesta. Se excluyen aquí por ser poco probable que reflejen la experiencia y las habilidades que supuestamente deberían determinar la remuneración. Asimismo, para simplificar, también se centrará únicamente en los desarrolladores residentes en EE. UU.
Los datos necesitan un poco más de transformación antes del modelado. Varias preguntas permiten múltiples respuestas, como "¿Cuáles son tus mayores desafíos para la productividad como desarrollador?" Estas preguntas individuales producen múltiples respuestas de sí/no y deben desglosarse en múltiples características de sí/no.
Algunas preguntas de opción múltiple como "¿Aproximadamente cuántas personas trabajan en la empresa u organización para la que trabajas?" permiten respuestas como "2-9 empleados". Estos son, en efecto, valores continuos agrupados, y puede ser útil volver a asignarlos a valores continuos inferidos como "2" para que el modelo pueda considerar su orden y magnitud relativa. Lamentablemente, esta conversión es manual y conlleva algunas decisiones subjetivas.
El código de Apache Spark que puede lograr esto se encuentra en el cuaderno adjunto, para los interesados.
Selección de modelos con Apache Spark
Con los datos en una forma más compatible con el aprendizaje automático, el siguiente paso es ajustar un modelo de regresión que prediga el salario a partir de estas características. El conjunto de datos en sí, después del filtrado y la transformación con Spark, es de apenas 4 MB, contiene 206 características de aproximadamente 12 600 desarrolladores y podría caber fácilmente en la memoria como un DataFrame en su reloj de pulsera, y mucho más en un servidor.
xgboost, un paquete popular de árboles de gradiente aumentado, puede ajustar un modelo a estos datos en minutos en una sola máquina, sin Spark. xgboost ofrece muchos "hiperparámetros" ajustables que afectan la calidad del modelo: profundidad máxima, tasa de aprendizaje, regularización, etc. En lugar de adivinar, una práctica estándar y sencilla es probar muchas configuraciones de estos valores y elegir la combinación que dé como resultado el modelo más preciso.
Afortunadamente, aquí es donde Spark vuelve a entrar en juego. Puede construir cientos de estos modelos en paralelo y recopilar los resultados de cada uno. Como el conjunto de datos es pequeño, es simple transmitirlo a los workers, crear un conjunto de combinaciones de esos hiperparámetros para probar y usar Spark para aplicar el mismo código simple no distribuido de xgboost que podría construir un modelo localmente a los datos con cada combinación.
Eso creará muchos modelos. Para seguir y evaluar los resultados, mlflow puede registrar cada uno con sus métricas e hiperparámetros y verlos en el Experimento del notebook. Aquí, un hiperparámetro a lo largo de muchas ejecuciones se compara con la precisión resultante (error absoluto medio):
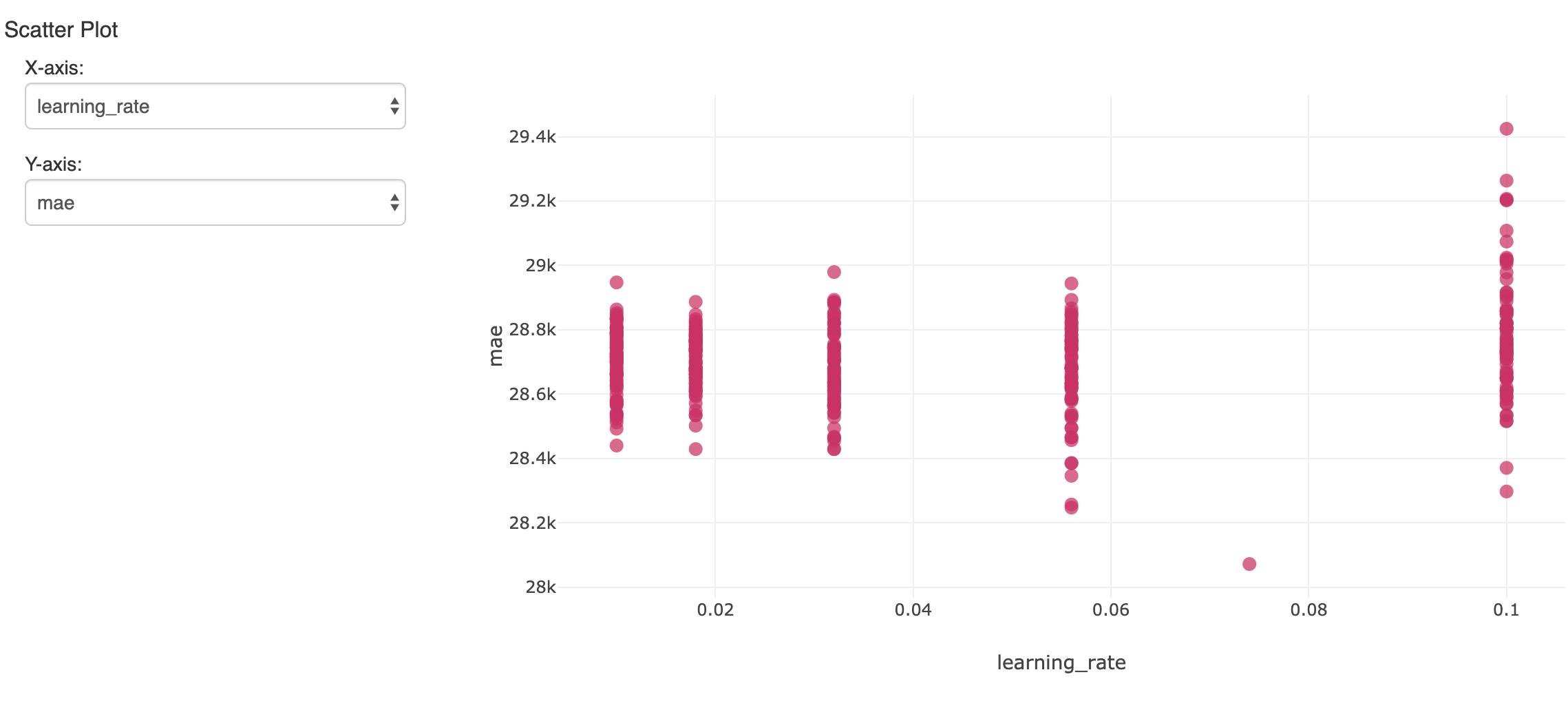
Es de interés el único modelo que mostró el menor error en el conjunto de datos de validación retenidos. Arrojó un error absoluto medio de aproximadamente 28 000 USD en salarios que promedian aproximadamente 119 000 USD. No está mal, aunque debemos darnos cuenta de que el modelo solo puede explicar la mayor parte de la variación en el salario.
Interpretación del modelo xgboost
Aunque el modelo se puede usar para predecir salarios futuros, la pregunta es más bien qué dice el modelo sobre los datos. ¿Qué características parecen importar más al predecir el salario con precisión? El propio modelo xgboost calcula una noción de la importancia de las características:
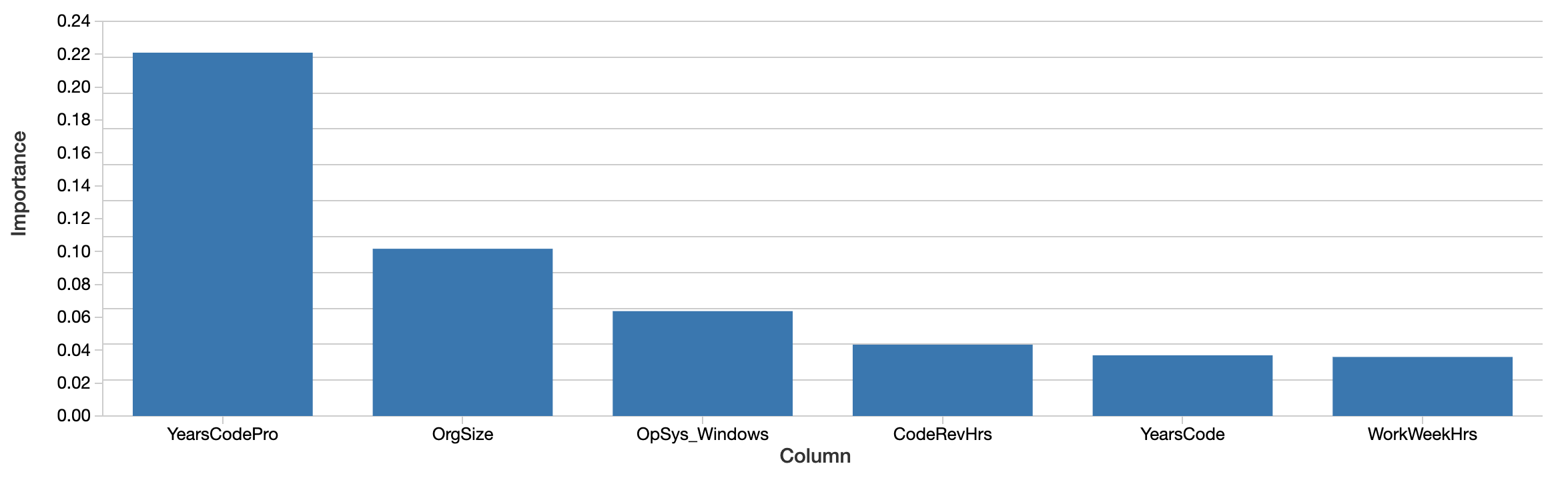
Factores como los años de codificación profesional, el tamaño de la organización y el uso de Windows son los más "importantes". Esto es interesante, pero difícil de interpretar. Los valores reflejan una importancia relativa y no absoluta. Es decir, el efecto no se mide en dólares. La definición de importancia aquí (ganancia total) también es específica de cómo se construyen los árboles de decisión y es difícil de asignar a una interpretación intuitiva. Las características importantes ni siquiera se correlacionan necesariamente de forma positiva con el salario.
Más importante aún, esta es una vista 'global' de cuánto importan las características en conjunto. Factores como el género y la etnia no aparecen en esta lista sino hasta más adelante. Esto no significa que estos factores no sigan siendo significativos. Por un lado, las características pueden estar correlacionadas o interactuar. Es posible que factores como el género se correlacionen con otras características que los árboles seleccionaron en su lugar, y esto, hasta cierto punto, enmascara su efecto.
La pregunta más interesante no es tanto si estos factores importan en general —es posible que su efecto promedio sea relativamente pequeño—, sino si tienen un efecto significativo en algunos casos individuales. Estos son los casos en los que el modelo nos dice algo importante sobre la experiencia de los individuos, y para esos individuos, esa experiencia es lo que importa.
Aplicación del paquete SHAP para explicaciones a nivel de desarrollador
Afortunadamente, en los últimos cinco años aproximadamente, ha surgido un conjunto de técnicas para una interpretación de modelos teóricamente más sólida a nivel de predicción individual. Se conocen colectivamente como "Shapley Additive Explanations" y, convenientemente, están implementados en el paquete de Python shap.
Dado cualquier modelo, esta biblioteca calcula los "valores SHAP" del modelo. Estos valores son fácilmente interpretables, ya que cada valor es el efecto de una característica en la predicción, en sus unidades. Un valor SHAP de 1000 aquí significa "explicó +1000 USD del salario predicho". Los valores SHAP se calculan de una manera que también intenta aislar la correlación y la interacción.
Los valores SHAP también se calculan para cada entrada, no para el modelo en su conjunto, por lo que estas explicaciones están disponibles para cada entrada individualmente. También puede estimar el efecto de las interacciones de las características por separado del efecto principal de cada característica, para cada predicción.
IA explicable: Descubriendo los efectos generales de las características
Las explicaciones a nivel de desarrollador pueden agregarse en explicaciones de los efectos de las características sobre el salario en todo el conjunto de datos simplemente promediando sus valores absolutos. La evaluación de SHAP de las características más importantes en general es similar:
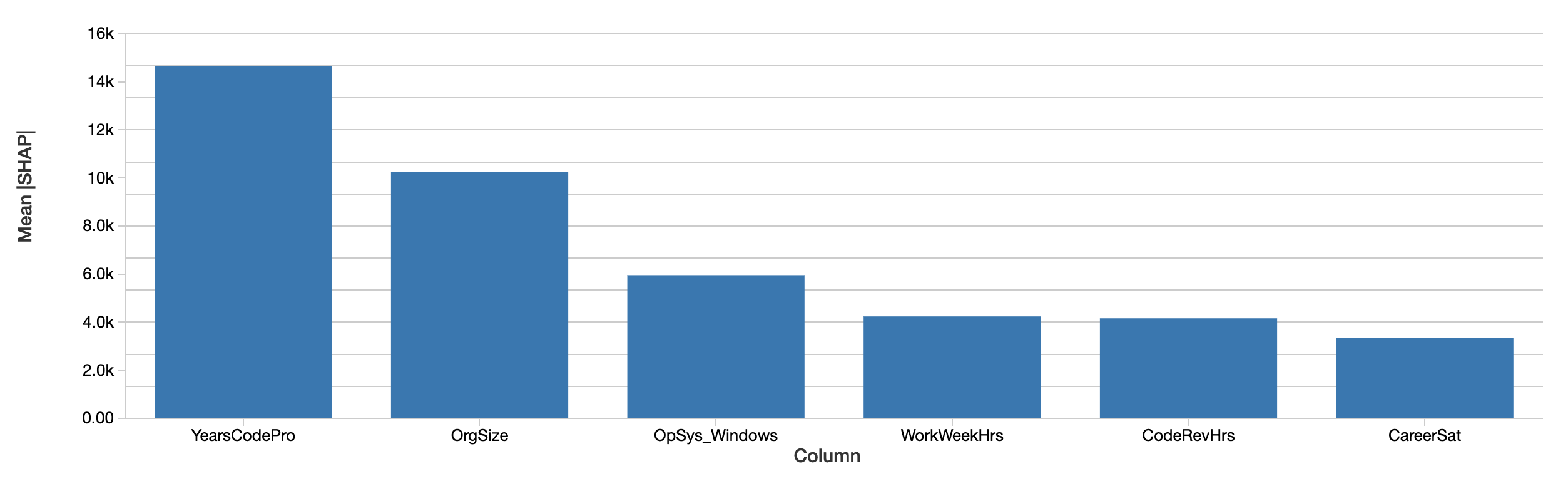
Los valores SHAP muestran una tendencia similar. En primer lugar, SHAP es capaz de cuantificar el efecto sobre el salario en dólares, lo que mejora considerablemente la interpretación de los resultados. Arriba se muestra un gráfico del efecto absoluto de cada característica sobre el salario previsto, promediado entre todos los desarrolladores. Los años de experiencia profesional en programación siguen siendo el factor determinante, lo que explica un efecto medio de casi 15 000 dólares en el salario.
Análisis de los efectos del género con valores SHAP
Analizamos específicamente los efectos del género, la raza y otros factores que supuestamente no deberían ser predictivos del salario per se. Este ejemplo examinará el efecto del género, aunque esto de ninguna manera sugiere que sea el único o más importante tipo de sesgo que se debe buscar.
El género no es binario, y la encuesta reconoce las respuestas de "Hombre", "Mujer" y "No binario, genderqueer o de género no conforme", así como "Trans" por separado. (Tenga en cuenta que, si bien la encuesta también registra por separado las respuestas sobre la sexualidad, estas no se consideran aquí). SHAP calcula el efecto sobre el salario previsto para cada uno de estos. Para un desarrollador masculino (que se identifica solo como hombre), el efecto del género no es solo el efecto de ser hombre, sino de no identificarse como mujer, transgénero, etc.
Los valores SHAP nos permiten leer la suma de estos efectos para los desarrolladores que se identifican con cada una de las cuatro categorías:

Mientras que el género de los desarrolladores varones explica una variación modesta de aproximadamente -$230 a +$890 con una media de unos $225, para las mujeres el rango es más amplio: de aproximadamente -$4,260 a -$690 con una media de -$1,320. Los resultados para los desarrolladores transgénero y no binarios son similares, aunque ligeramente menos negativos.
Al evaluar lo que esto significa a continuación, es importante recordar las limitaciones de los datos y del modelo aquí:
- La correlación no implica causalidad; 'explicar' el salario previsto es sugerente, pero no prueba que una característica haya causado directamente que el salario fuera más alto o más bajo
- El modelo no es perfectamente preciso.
- Estos son datos de solo 1 año, y únicamente de desarrolladores de EE. UU.
- Esto refleja solo el salario base, no las bonificaciones ni las acciones, que pueden variar más ampliamente.
Uso de SHAP para visualizar las características que interactúan con el género
La biblioteca SHAP ofrece visualizaciones interesantes que aprovechan su capacidad para aislar el efecto de las interacciones de las características. Por ejemplo, los valores anteriores sugieren que se predice que los desarrolladores que se identifican como hombres ganarán un salario ligeramente superior al de los demás, pero ¿hay algo más? Un gráfico de dependencia como este puede ayudar:
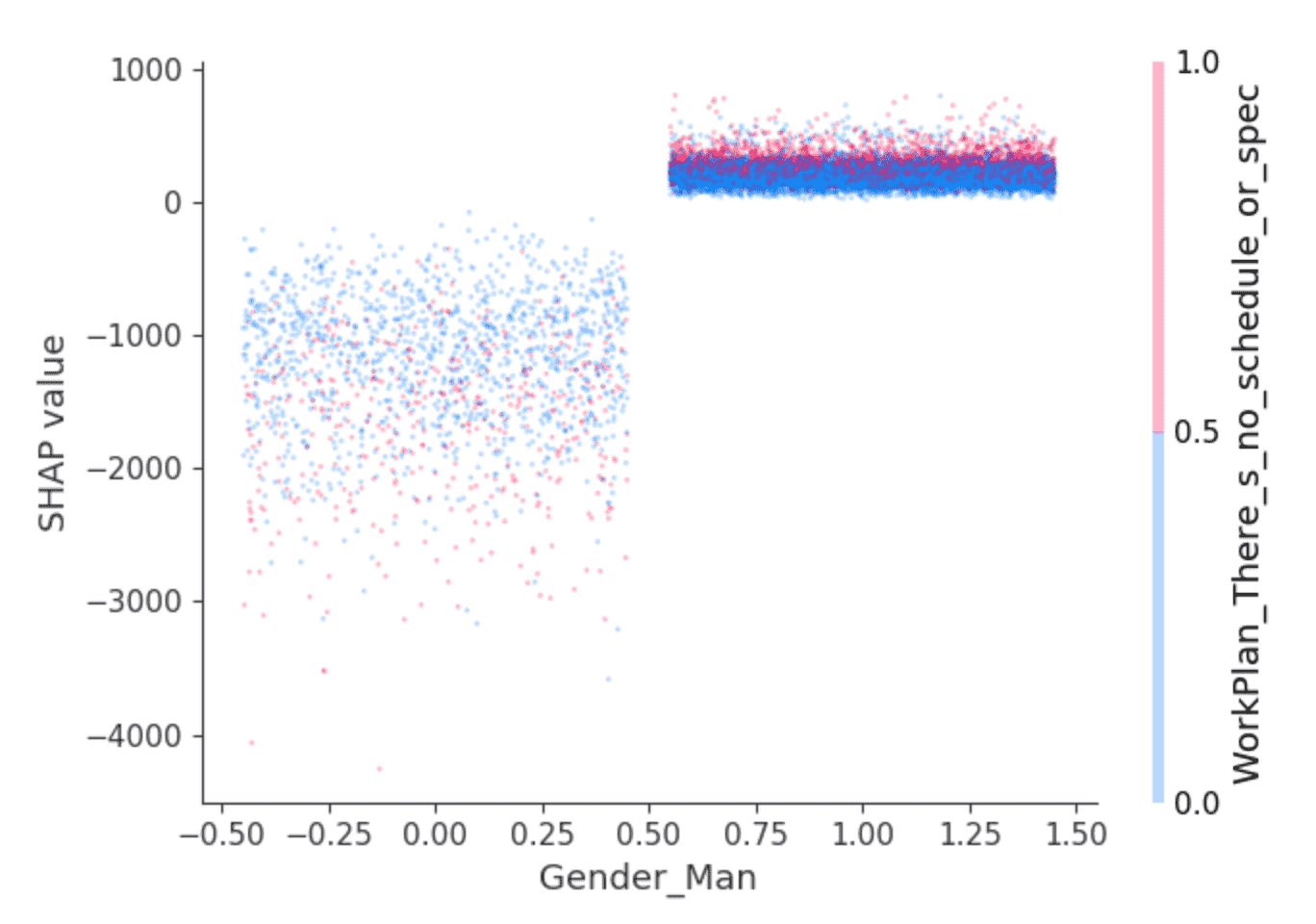
Los puntos son desarrolladores. Los desarrolladores de la izquierda son aquellos que no se identifican como hombres, y a la derecha, los que sí lo hacen, que son predominantemente los que se identifican solo como hombres. (Los puntos se distribuyen horizontalmente al azar para mayor claridad). El eje y es el valor SHAP, o lo que el hecho de identificarse como hombre o no explica sobre el salario predicho para cada desarrollador. Como se indicó anteriormente, quienes no se identifican como hombres muestran valores SHAP negativos en general y con una amplia variación, mientras que otros muestran consistentemente un pequeño valor SHAP positivo.
¿Qué hay detrás de esa varianza? SHAP puede seleccionar una segunda característica cuyo efecto varía más dado el valor de, en este caso, identificarse como hombre o no. Selecciona la respuesta "Trabajo en lo que parece más importante o urgente" a la pregunta "¿Qué tan estructurado o planificado es su trabajo?" Entre los desarrolladores que se identifican como hombres, aquellos que respondieron de esta manera (puntos rojos) parecen tener valores SHAP ligeramente más altos. Entre los demás, el efecto es más mixto, pero parece tener valores SHAP generalmente más bajos.
La interpretación queda a cargo del lector, pero quizás: ¿los desarrolladores hombres que se sienten empoderados en este sentido también disfrutan de salarios ligeramente más altos, mientras que otros desarrolladores disfrutan de esto cuando va de la mano con puestos de menor remuneración?
Exploración de instancias con efectos de género desproporcionados
¿Qué tal si investigamos al desarrollador cuyo salario se ve más afectado negativamente? Así como es posible observar el efecto general de las características relacionadas con el género, también es posible buscar al desarrollador cuyas características relacionadas con el género tuvieron el mayor impacto en el salario previsto. Esta persona es mujer y el efecto es negativo. Según el modelo, se prevé que gane unos $4,260 menos al año debido a su género:

El salario previsto, algo más de 157 000 dólares, es exacto en este caso, ya que tu salario real declarado es de 150 000 dólares.
Las tres características más positivas y negativas que influyen en el salario previsto son que ella:
- Tiene un título universitario (únicamente) (+$18,200)
- Tiene 10 años de experiencia profesional (+$9,400)
- Se identifica como asiática oriental (+$9,100)
- ...
- Trabaja 40 horas por semana (-$4,000)
- No se identifica como hombre (-$4,250)
- Trabaja en una organización de tamaño mediano de 100-499 empleados (-$9,700)
Dada la magnitud del efecto en el salario previsto de no identificarse como hombre, podríamos detenernos aquí e investigar los detalles de este caso fuera de línea para comprender mejor el contexto que rodea a esta desarrolladora y si su experiencia, su salario, o ambos, necesitan un cambio.
Explicación de las interacciones mediante valores SHAP
Hay más detalles disponibles dentro de esos -$4,260. SHAP puede desglosar los efectos de estas características en interacciones. El efecto total de identificarse como mujer en la predicción se puede desglosar en el efecto de identificarse como mujer y ser gerente de ingeniería, y trabajar con Windows, etc.
El efecto sobre el salario previsto explicado por los factores de género per se solo suma alrededor de -$630. Más bien, SHAP asigna la mayoría de los efectos del género a las interacciones con otras características:
Identificarse como mujer y trabajar con PostgreSQL afecta el salario previsto de forma ligeramente positiva, mientras que identificarse también como de Asia Oriental afecta el salario previsto de forma más negativa. Interpretar estos valores a este nivel de granularidad es difícil en este contexto, pero este nivel adicional de explicación está disponible.
Aplicación de SHAP con Apache Spark
Los valores SHAP se calculan de forma independiente para cada fila, dado el modelo, por lo que esto también podría haberse hecho en paralelo con Spark. El siguiente ejemplo calcula los valores SHAP en paralelo y, de manera similar, localiza a los desarrolladores con valores SHAP desproporcionados relacionados con el género:
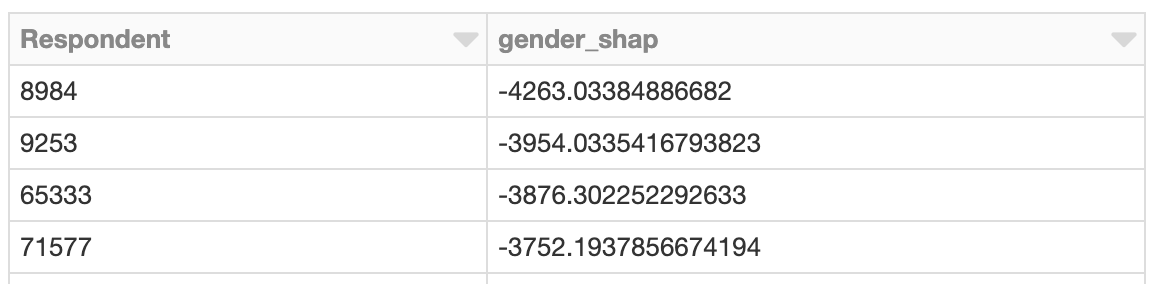
Clustering de valores SHAP
Aplicar Spark es ventajoso cuando hay un gran número de predicciones que evaluar con SHAP. Dada esa salida, también es posible usar Spark para agrupar los resultados con, por ejemplo, k-means bisectriz:
El clúster cuyos efectos SHAP totales relacionados con el género son más negativos podría merecer una investigación más a fondo. ¿Cuáles son los valores SHAP de esos encuestados en el clúster? ¿Cómo se comparan los miembros del clúster con la población general de desarrolladores?
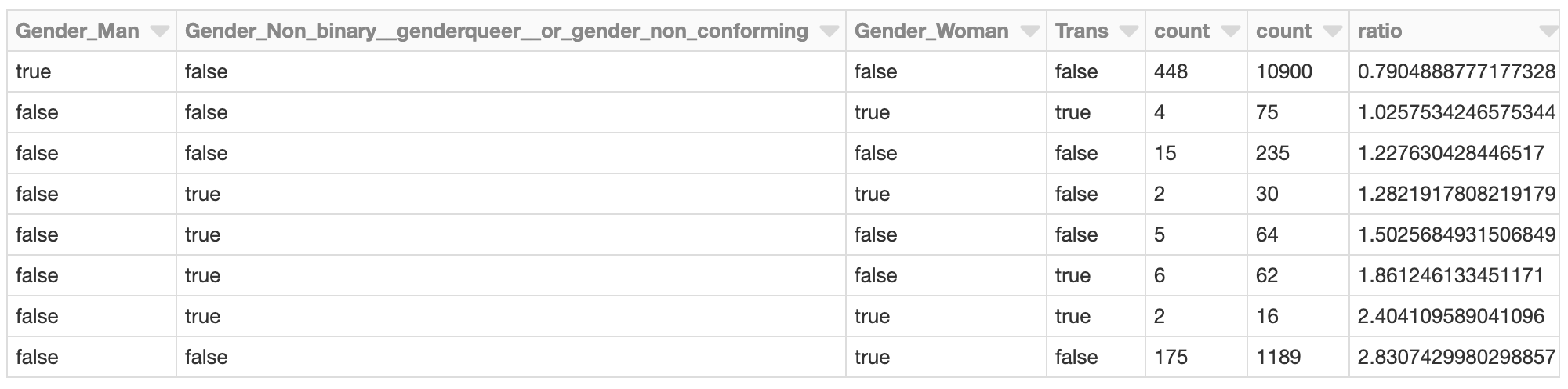
Por ejemplo, los desarrolladores que se identifican como mujeres (únicamente) están representados en este clúster a una tasa de casi 2.8 veces la de la población general de desarrolladores. Esto no es sorprendente, dado el análisis anterior. Este clúster podría investigarse más a fondo para evaluar otros factores específicos de este grupo que contribuyen a un salario previsto general más bajo.
Conclusión
Este tipo de análisis con SHAP se puede ejecutar para cualquier modelo y también a gran escala. Como herramienta analítica, convierte los modelos en detectives de datos para sacar a la luz instancias individuales cuyas predicciones sugieren que merecen un examen más detallado. El resultado de SHAP es fácilmente interpretable y produce gráficos intuitivos que pueden ser evaluados caso por caso por los usuarios de negocio.
Por supuesto, este análisis no se limita a examinar cuestiones de sesgo de género, edad o raza. De forma más prosaica, podría aplicarse a modelos de pérdida de clientes. Ahí, la pregunta no es solo "¿este cliente se dará de baja?", sino "¿por qué se está dando de baja?". A un cliente que cancela por el precio se le puede ofrecer un descuento, mientras que uno que cancela por un uso limitado podría necesitar una venta adicional.
Finalmente, este análisis se puede ejecutar como parte de un proceso de validación, lo que aporta una mayor transparencia al modelo de aprendizaje automático en general. La validación de modelos suele centrarse en la precisión general de un modelo. También debería centrarse en el 'razonamiento' del modelo, o en qué características contribuyeron más a las predicciones. Con SHAP, también puede ayudar a detectar cuándo las explicaciones de demasiadas predicciones individuales contradicen la importancia general de las características.
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.