5 pasos clave para migrar con éxito de Hadoop a la arquitectura de Lakehouse
por Harsh Narula
La decisión de migrar de Hadoop a una arquitectura moderna basada en la nube como la arquitectura de lakehouse es una decisión de negocios, no una decisión tecnológica. En un blog anterior, analizamos las razones por las que toda organización debe reevaluar su relación con Hadoop. Una vez que las partes interesadas de las áreas de tecnología, datos y negocios toman la decisión de migrar la empresa fuera de Hadoop, hay varias consideraciones que se deben tener en cuenta antes de iniciar la transición real. En este blog, nos centraremos específicamente en el proceso de migración en sí. Aprenderá sobre los pasos clave para una migración exitosa y el papel que desempeña la arquitectura de lakehouse para impulsar la próxima ola de innovación basada en datos.
Los pasos de la migración
Digamos las cosas como son. Las migraciones nunca son fáciles. Sin embargo, las migraciones pueden estructurarse para minimizar el impacto adverso, garantizar la continuidad del negocio y gestionar los costos de manera eficaz. Para ello, sugerimos dividir la migración de Hadoop en estos cinco pasos clave:
- Administración
- Migración de datos
- Procesamiento de datos
- Seguridad y gobernanza
- Capa de SQL y BI
Paso 1: Administración
Revisemos algunos de los conceptos esenciales de Hadoop desde una perspectiva de administración y cómo se comparan y contrastan con Databricks.
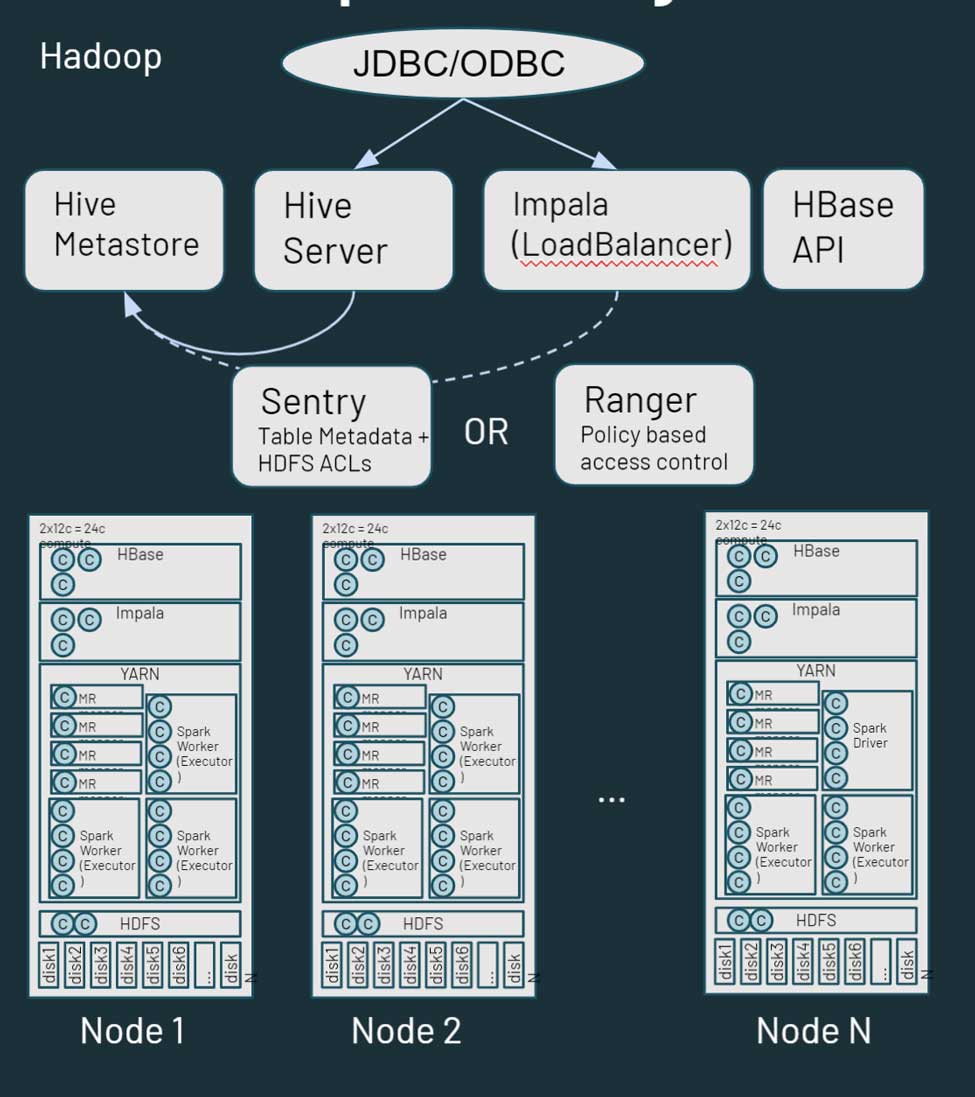
Hadoop es esencialmente una plataforma monolítica de almacenamiento distribuido y computación. Consta de múltiples nodos y servidores, cada uno con su propio almacenamiento, CPU y memoria. El trabajo se distribuye entre todos estos nodos. La gestión de recursos se realiza a través de YARN, que hace lo posible por garantizar que las cargas de trabajo obtengan su parte de la computación.
Hadoop también consta de información de metadatos. Hay un metaalmacén de Hive, que contiene información estructurada sobre sus activos que se almacenan en HDFS. Puede utilizar Sentry o Ranger para controlar el acceso a los datos. Desde la perspectiva del acceso a los datos, los usuarios y las aplicaciones pueden acceder a los datos directamente a través de HDFS (o las CLI/API correspondientes) o a través de una interfaz de tipo SQL. A su vez, la interfaz SQL puede ser a través de una conexión JDBC/ODBC usando Hive para SQL genérico (o, en algunos casos, scripts ETL) o Hive en Impala o Tez para consultas interactivas. Hadoop también proporciona una API de HBase y servicios de fuente de datos relacionados. Más información sobre el ecosistema de Hadoop aquí.
A continuación, analicemos cómo estos servicios se asignan o se tratan en la plataforma Databricks Lakehouse. En Databricks, una de las primeras diferencias que se deben tener en cuenta es que se observan varios clústeres en un entorno de Databricks. Cada clúster se puede usar para un caso de uso, un proyecto, una unidad de negocio, un equipo o un grupo de desarrollo específicos. Más importante aún, estos clústeres están diseñados para ser efímeros. En el caso de los clústeres de trabajo, su ciclo de vida está pensado para durar lo que dure el flujo de trabajo. Se ejecutará el flujo de trabajo y, una vez que se complete, el entorno se eliminará automáticamente. Del mismo modo, si piensas en un caso de uso interactivo, en el que tienes un entorno de computación compartido entre los desarrolladores, este entorno se puede iniciar al principio de la jornada laboral, con los desarrolladores ejecutando su código durante todo el día. Durante los períodos de inactividad, Databricks lo eliminará automáticamente a través de la funcionalidad de terminación automática (configurable) que está integrada en la plataforma.
A diferencia de Hadoop, Databricks no proporciona servicios de almacenamiento de datos como HBase o SOLR. Sus datos residen en su almacenamiento de archivos, dentro del almacenamiento de objetos. Muchos de los servicios, como HBase o SOLR, tienen alternativas u ofertas de tecnología equivalentes en la nube. Puede ser una solución nativa de la nube o una solución de un ISV.
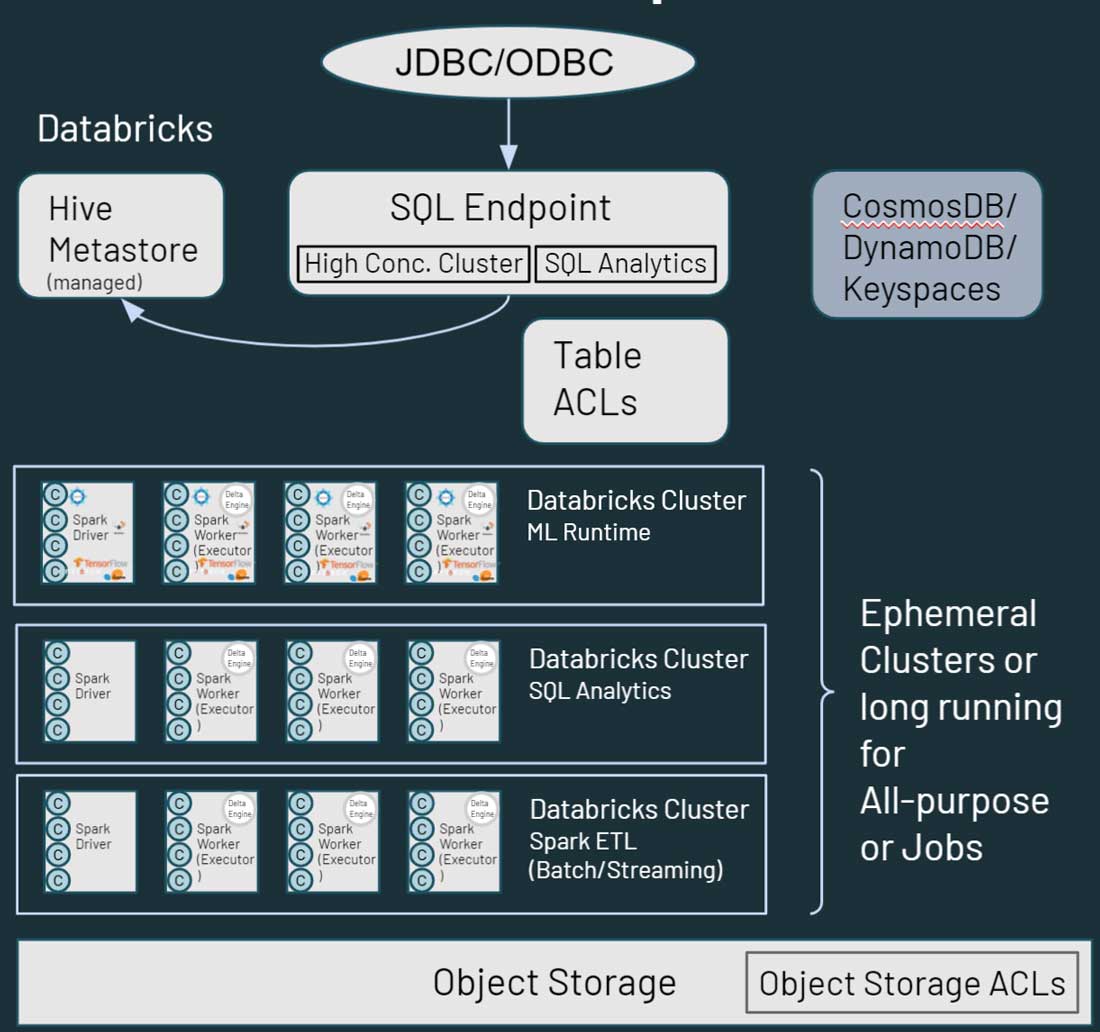
Como puedes ver en el diagrama anterior, cada nodo de clúster en Databricks corresponde a un driver o a un worker de Spark. Lo fundamental aquí es que los diferentes clústeres de Databricks están completamente aislados entre sí. Esto te permite garantizar que se puedan cumplir los estrictos SLA para proyectos y casos de uso específicos. Puedes aislar verdaderamente los casos de uso de streaming o en tiempo real de otras cargas de trabajo orientadas a lotes, y no tienes que preocuparte por aislar manualmente los trabajos de larga duración que podrían acaparar los recursos del clúster durante mucho tiempo. Simplemente puedes crear nuevos clústeres como capacidad de cómputo para diferentes casos de uso. Databricks también desacopla el almacenamiento del cómputo y te permite aprovechar el almacenamiento en la nube existente, como AWS S3, Azure Blob Storage y Azure Data Lake Store (ADLS).
Databricks también tiene un metastore de Hive administrado y predeterminado, que almacena información estructurada sobre los activos de datos que residen en el almacenamiento en la nube. También admite el uso de un metastore externo, como AWS Glue, Azure SQL Server o Azure Purview. También puede especificar controles de seguridad como las ACL de tabla dentro de Databricks, así como permisos de almacenamiento de objetos.
En lo que respecta al acceso a los datos, Databricks ofrece capacidades similares a las de Hadoop en cuanto a cómo sus usuarios interactúan con los datos. A los datos almacenados en la nube se puede acceder a través de varias rutas en el entorno de Databricks. Los usuarios pueden usar los SQL Endpoints y Databricks SQL para consultas y análisis interactivos. También pueden usar los notebooks de Databricks para ingeniería de datos y machine learning con los datos almacenados en la nube. HBase en Hadoop se corresponde con Azure CosmosDB o AWS DynamoDB/Keyspaces, que se pueden aprovechar como una capa de servicio para aplicaciones posteriores.
Paso 2: Migración de datos
Viniendo de un entorno de Hadoop, asumiré que la mayor parte de la audiencia ya está familiarizada con HDFS. HDFS es el sistema de archivos de almacenamiento utilizado con las implementaciones de Hadoop que aprovecha los discos en los nodos del clúster de Hadoop. Entonces, cuando escalas HDFS, necesitas agregar capacidad a todo el clúster (es decir, necesitas escalar el cómputo y el almacenamiento juntos). Si esto implica la adquisición e instalación de hardware adicional, puede demandar una cantidad significativa de tiempo y esfuerzo.
En la nube, tienes una capacidad de almacenamiento casi ilimitada en forma de almacenamiento en la nube, como AWS S3, Azure Data Lake Storage o Blob Storage o Google Storage. No se necesitan verificaciones de mantenimiento ni de estado, y ofrece redundancia integrada y altos niveles de durabilidad y disponibilidad desde el momento en que se implementa. Recomendamos usar los servicios nativos de la nube para migrar sus datos y, para facilitar la migración, existen varios socios/ISV.
Entonces, ¿cómo empezar? La ruta más recomendada es comenzar con una estrategia de ingesta dual (es decir, agregar una fuente que cargue datos en el almacenamiento en la nube además de tu entorno local). Esto te permite comenzar a usar nuevos casos de uso (que aprovechan datos nuevos) en la nube sin que afecte tu configuración actual. Si buscas la aprobación de otros grupos dentro de la organización, para empezar, puedes plantear esto como una estrategia de respaldo. Tradicionalmente, HDFS ha sido un desafío para respaldar debido a su gran tamaño y al esfuerzo que implica, por lo que respaldar los datos en la nube puede ser una iniciativa productiva de todos modos.
En la mayoría de los casos, puedes aprovechar las herramientas de entrega de datos existentes para bifurcar la fuente y escribir no solo en Hadoop, sino también en el almacenamiento en la nube. Por ejemplo, si está utilizando herramientas o frameworks como Informatica y Talend para procesar y escribir datos en Hadoop, es muy fácil añadir el paso adicional y hacer que escriban en el almacenamiento en la nube. Una vez que los datos están en la nube, hay muchas formas de trabajar con ellos.
En cuanto a la dirección de los datos, estos pueden extraerse del entorno local a la nube o enviarse a la nube desde el entorno local. Algunas de las herramientas que se pueden aprovechar para subir los datos a la nube son las soluciones nativas de la nube (Azure Data Box, AWS Snow Family, etc.), DistCP (una herramienta de Hadoop), otras herramientas de terceros, así como cualquier framework interno. La opción de subida suele ser más fácil en cuanto a obtener las aprobaciones necesarias de los equipos de seguridad.
Para extraer los datos a la nube, puede usar pipelines de ingesta de Spark/Kafka Streaming o por lotes (Batch) que se activan desde la nube. Para el procesamiento por lotes (batch), puede ingerir archivos directamente o usar conectores JDBC para conectarse a las plataformas tecnológicas ascendentes (upstream) relevantes y extraer los datos. Por supuesto, también hay herramientas de terceros disponibles para esto. La opción de empuje (push) es la más aceptada y comprendida de las dos, así que profundicemos un poco más en el enfoque de extracción (pull).
Lo primero que necesitarás es configurar la conectividad entre tu entorno on-premises y la nube. Esto se puede lograr con una conexión a Internet y una puerta de enlace. También puedes aprovechar las opciones de conectividad dedicada, como AWS Direct Connect, Azure ExpressRoute, etc. En algunos casos, si su organización no es nueva en la nube, es posible que esto ya se haya configurado para que pueda reutilizarlo en su proyecto de migración de Hadoop.
Otra consideración es la seguridad dentro del entorno de Hadoop. Si es un entorno Kerberizado, puede adaptarse desde Databricks. Puedes configurar scripts de inicialización de Databricks que se ejecutan al iniciar el clúster, instalar y configurar el cliente kerberos necesario, acceder a los archivos krb5.conf y keytab, que se almacenan en una ubicación de almacenamiento en la nube y, finalmente, ejecutar la función kinit(), que permitirá que el clúster de Databricks interactúe directamente con tu entorno de Hadoop.
Por último, también necesitará un metastore externo compartido. Si bien Databricks tiene un servicio de metastore que se implementa de forma predeterminada, también admite el uso de uno externo. El metastore externo será compartido por Hadoop y Databricks, y se puede implementar ya sea on-premises (en tu entorno de Hadoop) o en la nube. Por ejemplo, si tienes procesos de ETL existentes que se ejecutan en Hadoop y aún no puedes migrarlos a Databricks, puedes aprovechar esta configuración con el metastore on-premises existente para que Databricks consuma el conjunto de datos final depurado de Hadoop.
Paso 3: Procesamiento de datos
Lo principal a tener en cuenta es que, desde la perspectiva del procesamiento de datos, todo en Databricks utiliza Apache Spark. Todos los lenguajes de programación de Hadoop, como MapReduce, Pig, Hive QL y Java, se pueden convertir para ejecutarse en Spark, ya sea a través de Pyspark, Scala, Spark SQL o incluso R. Con respecto al código y al IDE, los notebooks de Apache Zeppelin y Jupyter se pueden convertir en notebooks de Databricks, pero es un poco más fácil importar los notebooks de Jupyter. Los notebooks de Zeppelin deberán convertirse a Jupyter o Ipython antes de poder importarse. Si su equipo de ciencia de datos desea seguir programando en Zeppelin o Jupyter, puede usar Databricks Connect, que le permite aprovechar su IDE local (Jupyter, Zeppelin o incluso IntelliJ, VScode, RStudio, etc.) para ejecutar código en Databricks.
Cuando se trata de migrar trabajos de Apache Spark™, la consideración más importante son las versiones de Spark. Es posible que su clúster de Hadoop local esté ejecutando una versión anterior de Spark y puede usar la guía de migración de Spark para identificar qué cambios se realizaron y ver los impactos en su código. Otro aspecto para tener en cuenta es la conversión de RDD a dataframes. Los RDD se usaban comúnmente con las versiones de Spark hasta la 2.x, y si bien todavía se pueden usar con Spark 3.x, hacerlo puede impedir que aproveche todas las capacidades del optimizador de Spark. Recomendamos que cambie sus RDD por dataframes siempre que sea posible.
Por último, pero no por ello menos importante, uno de los problemas comunes que hemos encontrado con los clientes durante la migración son las referencias codificadas al entorno local de Hadoop. Por supuesto, será necesario actualizarlas, ya que, de lo contrario, el código no funcionará en la nueva configuración.
A continuación, hablemos de la conversión de las cargas de trabajo que no son de Spark, lo que, en su mayor parte, implica reescribir el código. En el caso de MapReduce, en algunos casos, si se utiliza lógica compartida en forma de una biblioteca de Java, Spark puede aprovechar el código. Sin embargo, es posible que aún deba reescribir algunas partes del código para ejecutarlo en un entorno de Spark en lugar de en MapReduce. Sqoop es relativamente fácil de migrar, ya que en los nuevos entornos se ejecuta un conjunto de comandos de Spark (en lugar de comandos de MapReduce) utilizando una fuente JDBC. Puede especificar parámetros en el código de Spark de la misma manera que los especifica en Sqoop. Para Flume, la mayoría de los casos de uso que hemos visto giran en torno al consumo de datos de Kafka y la escritura en HDFS. Esta es una tarea que se puede realizar fácilmente con Spark streaming. La tarea principal al migrar Flume es que tiene que convertir el enfoque basado en archivos de configuración en un enfoque más programático en Spark. Por último, tenemos Nifi, que se utiliza principalmente fuera de Hadoop, sobre todo como una herramienta de ingesta de autoservicio de arrastrar y soltar. Nifi también se puede aprovechar en la nube, pero vemos que muchos clientes aprovechan la oportunidad de migrar a la nube para reemplazar Nifi con otras herramientas más nuevas disponibles en ella.
Migrar HiveQL es quizás la tarea más fácil de todas. Existe un alto grado de compatibilidad entre Hive y Spark SQL, y la mayoría de las consultas deberían poder ejecutarse en Spark SQL tal como están. Hay algunos cambios menores en el DDL entre HiveQL y Spark SQL, como el hecho de que Spark SQL utiliza la cláusula “USING” en lugar de la cláusula “FORMAT” de HiveQL. Recomendamos cambiar el código para usar el formato Spark SQL, ya que permite que el optimizador prepare el mejor plan de ejecución posible para su código en Databricks. Aún puede aprovechar los SerDes y las UDF de Hive, lo que facilita aún más la migración de HiveQL a Databricks.
Con respecto a la orquestación del flujo de trabajo, debe considerar los posibles cambios en la forma en que se enviarán sus trabajos. Puede seguir aprovechando la semántica de envío de Spark, pero también hay otras opciones disponibles más rápidas y con una integración más fluida. Puede aprovechar los trabajos de Databricks y Delta Live Tables para un ETL sin código a fin de reemplazar los trabajos de Oozie, y definir canalizaciones de datos de extremo a extremo dentro de Databricks. Para los flujos de trabajo que implican dependencias de procesamiento externas, tendrá que crear los flujos de trabajo/las canalizaciones equivalentes en tecnologías como Apache Airflow, Azure Data Factory, etc. para la automatización/programación. Con las API de REST de Databricks, se puede integrar y configurar casi cualquier plataforma de programación para que funcione con Databricks.
También existe una herramienta automatizada llamada MLens (creada por KnowledgeLens), que puede ayudar a migrar sus cargas de trabajo de Hadoop a Databricks. MLens puede ayudar a migrar el código de PySpark y HiveQL, incluida la traducción de algunas de las características específicas de Hive a Spark SQL para que pueda aprovechar toda la funcionalidad y los beneficios de rendimiento del optimizador de Spark SQL. También planean admitir pronto la migración de flujos de trabajo de Oozie a Airflow, Azure Data Factory, etc.
Paso 4: Seguridad y gobernanza
Echemos un vistazo a la seguridad y la gobernanza. En el mundo de Hadoop, tenemos la integración con LDAP para la conectividad con consolas de administración como Ambari o Cloudera Manager, o incluso Impala o Solr. Hadoop también tiene Kerberos, que se utiliza para la autenticación con otros servicios. Desde la perspectiva de la autorización, Ranger y Sentry son las herramientas más utilizadas.
Con Databricks, la integración del inicio de sesión único (SSO) está disponible con cualquier proveedor de identidad que admita SAML 2.0. Esto incluye Azure Active Directory, Google Workspace SSO, AWS SSO y Microsoft Active Directory. Para la autorización, Databricks proporciona ACL (listas de control de acceso) para los objetos de Databricks, lo que le permite establecer permisos en entidades como notebooks, trabajos y clústeres. Para los permisos de datos y el control de acceso, puede definir ACL de tabla y vistas para limitar el acceso a columnas y filas, así como aprovechar el paso de credenciales (credential passthrough), con el que Databricks pasa sus credenciales de inicio de sesión del espacio de trabajo a la capa de almacenamiento (S3, ADLS, Blob Storage) para determinar si está autorizado a acceder a los datos. Si necesita capacidades como los controles basados en atributos o el enmascaramiento de datos, puede aprovechar herramientas de socios como Immuta y Privacera. Desde una perspectiva de gobernanza empresarial, puede conectar Databricks a un catálogo de datos empresariales como AWS Glue, Informatica Data Catalog, Alation y Collibra.
Paso 5: Capa de SQL & BI
En Hadoop, como se mencionó anteriormente, cuenta con Hive e Impala como interfaces para hacer ETL, así como consultas ad-hoc y análisis. En Databricks, cuenta con capacidades similares a través de Databricks SQL. Databricks SQL también ofrece un rendimiento extremo a través del motor Delta, así como soporte para casos de uso de alta simultaneidad con clústeres de escalado automático. El motor Delta también incluye Photon, que es un nuevo motor MPP creado desde cero en C++ y está vectorizado para aprovechar el paralelismo tanto a nivel de datos como a nivel de instrucción.
Databricks proporciona integración nativa con herramientas de BI como Tableau, PowerBI, Qlik y Looker, así como conectores JDBC/ODBC altamente optimizados que pueden ser aprovechados por esas herramientas. Los nuevos drivers JDBC/ODBC tienen una sobrecarga (overhead) muy pequeña (¼ seg.) y una tasa de transferencia un 50 % superior utilizando Apache Arrow, así como varias operaciones de metadatos que soportan operaciones de recuperación de metadatos significativamente más rápidas. Databricks también es compatible con SSO para PowerBI, y próximamente lo será para otras herramientas de BI y creación de dashboards.
Databricks tiene una experiencia de usuario (UX) de SQL integrada, además de la experiencia con notebooks mencionada anteriormente, que ofrece a sus usuarios de SQL su propia perspectiva con un workbench de SQL, así como capacidades sencillas de creación de dashboards y alertas. Esto permite realizar transformaciones de datos basadas en SQL y análisis exploratorios de los datos dentro del data lake, sin necesidad de moverlos a sistemas descendentes (downstream) como un data warehouse u otras plataformas.
Próximos pasos
Al considerar su proceso de migración a una arquitectura de nube moderna, como la arquitectura de lakehouse, hay dos cosas que debe recordar:
- Recuerde involucrar a los principales interesados del negocio en el proceso. Esta es una decisión tanto tecnológica como de negocio, y es necesario que los principales interesados del negocio se comprometan con el proceso y su resultado final.
- Además, recuerda que no estás solo, y que hay recursos calificados en Databricks y en nuestros socios que han hecho esto lo suficiente como para desarrollar las mejores prácticas repetibles, lo que ahorra a las organizaciones tiempo, dinero, recursos y reduce el estrés general.
- Descargue la guía de migración técnica de Hadoop a Databricks para obtener orientación paso a paso, notebooks y código para comenzar su migración.
Para obtener más información sobre cómo Databricks aumenta el valor empresarial y empezar a planificar su migración desde Hadoop, visite www.databricks.com/solutions/migration.

Guía de migración: de Hadoop a Databricks
Desbloquee todo el potencial de sus datos con este manual autoguiado.
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.