PRUEBA - Una guía compacta para el ajuste fino y la creación de LLM personalizados
por Team Databricks
Introducción
La IA generativa (GenAI) tiene el potencial de democratizar la IA, transformar todas las industrias, dar soporte a cada empleado y atraer a cada cliente. Para ser más útil, los modelos de GenAI necesitan una comprensión profunda de los datos empresariales de una organización. Hasta la fecha, las técnicas más populares para dar a los modelos de GenAI conocimiento de su empresa son la ingeniería de prompts, la generación aumentada por recuperación (RAG), las cadenas y los agentes. Sin embargo, esas técnicas alcanzan límites cuando se utilizan modelos generales no adaptados a dominios y aplicaciones específicos. Para mejorar los resultados generados y reducir los costos, los desarrolladores de aplicaciones de GenAI deben recurrir a crear modelos personalizados mediante el ajuste fino o el preentrenamiento.
El ajuste fino especializa un modelo de IA existente a un dominio o tarea específica entrenándolo más con un conjunto más pequeño de datos personalizados. Las técnicas incluyen el ajuste fino supervisado para el seguimiento de instrucciones o el chat, así como el preentrenamiento continuo. El preentrenamiento crea un modelo completamente nuevo entrenándolo desde cero con datos totalmente personalizables. Todas estas técnicas permiten a los desarrolladores crear propiedad intelectual y diferenciación para su dominio o aplicación, con el potencial de crear modelos mejores y más precisos y de utilizar arquitecturas de modelos más pequeñas y de menor costo.
En esta guía para crear modelos personalizados, cubrimos:
- Motivación: ¿Por qué y cuándo debería crear un modelo de GenAI personalizado?
- Principios: ¿Qué prácticas de alto nivel deberían guiar su estrategia e implementación al crear modelos personalizados?
- Técnicas: ¿Cómo puede crear modelos personalizados? ¿Qué técnicas y "errores comunes" debe tener en cuenta para la preparación de datos, el entrenamiento y la evaluación?
Esta guía está dirigida a profesionales que planean crear modelos personalizados. Asumimos un conocimiento de GenAI y modelos de lenguaje grandes (LLMs), incluyendo términos como ingeniería de prompts, RAG, agentes, ajuste fino y preentrenamiento. Para material introductorio, por favor, consulte más sobre IA generativa y LLMs.
Acerca de Databricks
Databricks proporciona herramientas unificadas para construir, implementar y monitorear soluciones de IA y ML, desde la creación de modelos predictivos hasta los últimos modelos de GenAI y LLMs. Construido sobre la Plataforma de Inteligencia de Datos de Databricks, Databricks permite a las organizaciones integrar de forma segura y rentable sus datos empresariales en el ciclo de vida de la IA con cualquier modelo de GenAI. Permitimos a los clientes implementar, gobernar, consultar y monitorear modelos ajustados o preimplementados por Databricks, como Meta Llama 3, DBRX o BGE, o de cualquier otro proveedor de modelos como Azure OpenAI GPT-4, Anthropic Claude, AWS Bedrock y AWS SageMaker. Para personalizar modelos con datos empresariales, Databricks proporciona todos los patrones arquitectónicos, desde la ingeniería de prompts, RAG, ajuste fino y preentrenamiento.
Databricks proporciona capacidades de ajuste fino y preentrenamiento de GenAI inigualables por cualquier otra plataforma de IA. A junio de 2024, los clientes de Databricks habían creado más de 200.000 modelos de IA personalizados en el año anterior. Además, Databricks tiene modelos preentrenados que los clientes pueden usar directamente. En marzo de 2024, Databricks lanzó DBRX, un nuevo LLM de código abierto de alto rendimiento que fue preentrenado desde cero, bajo una licencia comercialmente viable. En junio de 2024, Databricks y Shutterstock lanzaron otro modelo preentrenado, Shutterstock ImageAI, Powered by Databricks, un modelo de vanguardia de texto a imagen.
La infraestructura y la tecnología que utilizamos para construir estos modelos de alto rendimiento son la misma infraestructura y tecnología que proporcionamos a nuestros clientes. Consulte nuestras historias de clientes de Databricks para leer sobre éxitos en datos e IA en todas las industrias.
Motivación: ¿Por qué ajustar o crear LLMs personalizados?
Los clientes generalmente comienzan a crear modelos de GenAI personalizados cuando los modelos existentes tienen limitaciones dolorosas en calidad, costo o latencia. Los detalles son diferentes para cada caso de uso, pero los ejemplos incluyen:
- “Necesito un modelo para generar el lenguaje de consulta especial de mi producto. Puedo hacerlo usando APIs de modelos y prompting de pocas muestras, pero es muy lento y caro.”
- “Mi bot RAG funciona bien, pero está utilizando una API de modelo grande y potente que es demasiado cara para mi caso de uso de alto rendimiento. No necesito un modelo tan general, así que quiero ajustar un modelo pequeño, específico y barato.”
- “No encuentro un modelo de código abierto que sea bueno en el idioma X, así que quiero crear un modelo adaptado para entender X.”
Los modelos de GenAI más famosos son modelos generales destinados a hacer (casi) todo. Si bien son impresionantes, estos modelos son demasiado grandes y caros para la mayoría de los casos de uso, y no saben nada sobre sus datos o aplicación propietarios. En todos los ejemplos anteriores, la creación de un modelo personalizado y especializado aumentó la calidad o disminuyó el costo y la latencia. El modelo personalizado se convirtió en propiedad intelectual y proporcionó una ventaja competitiva para el producto del cliente.
Una motivación menos común pero más apremiante para crear modelos personalizados proviene de preocupaciones legales o regulatorias, especialmente en industrias más reguladas. Algunos clientes quieren o necesitan control total sobre sus modelos para gestionar riesgos, como acusaciones de uso ilegal de contenido para el entrenamiento de modelos. Al preentrenar un modelo completamente personalizado, puede saber y probar exactamente cómo se creó el modelo.
Entonces, ¿cómo puede empezar? Aunque la GenAI es un campo de investigación complejo, puede ser sencillo empezar a personalizar modelos de GenAI. Hay un camino natural desde el ajuste fino básico hasta el preentrenamiento complejo, y la plataforma Databricks soporta todo este flujo de trabajo. A medida que siga este camino, acumulará experiencia y datos que alimentarán tipos futuros y más complejos de personalización de modelos.
Principios: ¿Cuándo y cómo debería ajustar o crear modelos personalizados?
¿Cuándo, por qué y cómo debería crear modelos personalizados?
A un alto nivel, los sistemas de GenAI se pueden personalizar de dos maneras:
- IA Compuesta: Dados uno o más modelos existentes, puede crear RAG, agentes y otros sistemas de IA compuestos alrededor de esos modelos.
- Modelos personalizados: Puede personalizar un modelo existente (ajuste fino) o crear un modelo completamente nuevo (preentrenamiento).
Estas dos opciones se pueden combinar, como RAG utilizando un LLM ajustado. Dichas combinaciones —y la velocidad del desarrollo de GenAI— pueden hacer que la planificación y la creación de aplicaciones de GenAI sean complejas. Para simplificar su enfoque, recomendamos tres principios rectores.
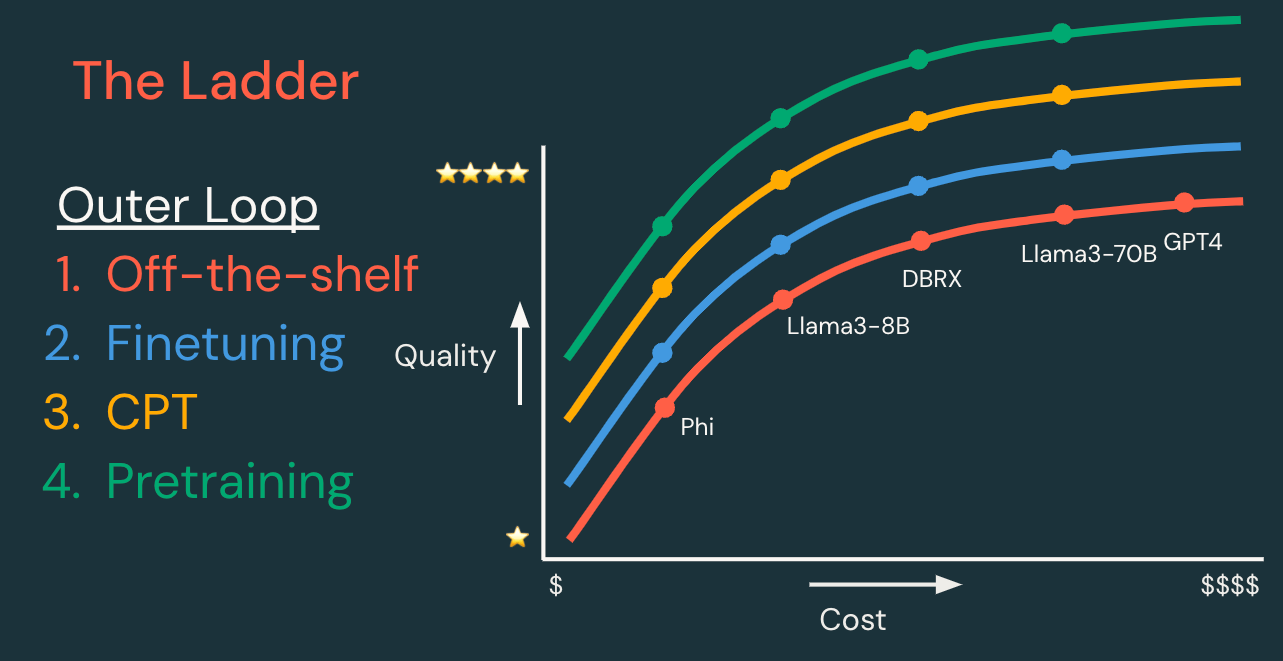
Principio 1: Empiece poco a poco y avance gradualmente
Para cualquier aplicación de GenAI, recomendamos que comience de forma sencilla y agregue complejidad según sea necesario. Eso puede significar comenzar con un modelo existente (como las APIs de Modelos Fundacionales de Databricks) y realizar una ingeniería de prompts simple. Luego, agregue técnicas según sea necesario para mejorar sus métricas de calidad, costo y velocidad.
La "escalera" de técnicas se puede dividir en bucles de desarrollo internos y externos, descritos a continuación.
Bucle externo: Escalera de personalización de modelos | ||||
Cada paso tiene el potencial de crear un modelo de mayor calidad, menor costo y/o menor latencia. | Datos requeridos | Tiempo de desarrollo | Costo de desarrollo | |
Modelo existente | Comience con un modelo o API de modelo existente, y primero itere en el bucle interno. | Ninguno, o datos para RAG | Horas | $ |
Ajuste fino supervisado | Personalice un modelo para que maneje mejor su tarea específica. “Espere consultas como esta y devuelva respuestas como aquella.” | Cientos a decenas de miles de ejemplos | Días | $$ |
Reentrenamiento continuo | Personalice un modelo para que comprenda mejor su dominio. “Aprenda el lenguaje de este nicho de dominio de aplicación.” | Millones a miles de millones de tokens | Semanas | $$$ |
Preentrenamiento | Cree un nuevo modelo para tener control total, personalización y propiedad. “¡Aprenda todo desde cero!” | Miles de millones a billones de tokens | Meses | $$$$$$ |
Bucle interno: Técnicas compuestas de IA | |
Cada técnica a continuación puede mejorar la calidad de la generación para un modelo dado. Estas técnicas se enumeran en orden (aproximado) de complejidad, pero se pueden mezclar y combinar. | |
Ingeniería de prompts | Cree prompts específicos para la tarea para guiar el comportamiento del modelo. |
Prompting de pocos ejemplos | Proporcione datos en los prompts para enseñar a los modelos en tiempo de inferencia. |
RAG | Proporcione datos específicos de la consulta a los modelos como contexto adicional. |
Agentes | Proporcione a los modelos herramientas invocables y/o flujos de control complejos. |
Adoptar una técnica del bucle interno es relativamente barato y rápido, en comparación con subir un nivel en el bucle externo. Por lo tanto, siempre que suba en el bucle externo, vale la pena iterar sobre algunas o todas las técnicas del bucle interno. Esta designación de “interno” versus “externo” es la inversa de lo que esperaría de la arquitectura del sistema: el bucle “interno” de IA compuesta envuelve el bucle “externo” de su modelo. Llamamos al modelo personalización el bucle “externo” porque es el bucle externo en términos de su flujo de trabajo, según lo exigen los costos relativos de los bucles internos y externos.
Principio 2: Sea impulsado por los datos
Antes de invertir seriamente en cualquier proyecto, defina cuidadosamente su medidor de éxito y siga las populares prácticas de desarrollo impulsado por la evaluación.
A nivel de sistemas de IA, considere métricas de calidad, costo y latencia.
- Calidad probablemente implicará varias métricas: precisión, retroalimentación del usuario, toxicidad, etc.
- Costos para sistemas en producción generalmente se centran en la inferencia del modelo y el servicio de datos
- Latencia puede significar latencia de extremo a extremo, o tiempo hasta el primer token para aplicaciones más interactivas
¿Qué números deben alcanzar estas métricas para declarar el éxito? ¿Qué restricciones estrictas tiene sobre estas métricas para garantizar una buena experiencia de usuario, un retorno de la inversión positivo u otros requisitos comerciales? Vea esta charla de nuestro científico jefe de IA para más discusión.
A nivel de proyecto y negocio, analice el retorno de la inversión.
- Costos (inversi�ón) deben dividirse en dos fases:
- Costos de desarrollo podrían incluir costos de cómputo y humanos para preparación de datos, entrenamiento de modelos y desarrollo de sistemas
- Costos continuos podrían incluir servicio de modelos y datos y horas de personal de mantenimiento
- Impacto comercial (retorno)
- Ingresos u otros objetivos comerciales y resultados clave (OKR) podrían variar desde ahorro de tiempo humano (para un bot de soporte de GenAI) hasta ingresos directos (para un producto impulsado por GenAI)
- Creación de propiedad intelectual (PI), como nuevos modelos o datos, puede ser el impacto más difícil de medir pero el más grande a largo plazo. Todos pueden usar las mismas API de proveedores de modelos, pero solo usted puede usar sus modelos y datos propietarios.
Sus objetivos impulsados por datos informarán sus elecciones sobre la personalización del modelo (principio 1). Por ejemplo, si cumple sus métricas de calidad pero excede sus restricciones de costos usando una API de modelo costosa, podría pasar a ajustar un modelo más pequeño y eficiente adaptado a su tarea específica para reducir costos manteniendo la calidad. El ajuste fino incurrirá en costos de desarrollo adicionales pero reducirá los costos continuos, y reducirá el costo general a largo plazo.
Principio 3: Manténgase práctico
Evaluar modelos y sistemas de GenAI es desafiante. Las técnicas de ajuste fino y preentrenamiento son un área de investigación candente. El entusiasmo académico e industrial (y los LLM) están generando mucho más contenido del que se puede leer. Estas fuentes de confusión hacen que sea difícil saber cuándo usar qué técnicas. (“¿Necesito LoRA? ¿Qué es el aprendizaje curricular? ¿Qué arquitectura de modelo es la mejor?”)
Muchas personas nuevas en GenAI han oído que pueden lanzar montones de datos a GenAI y aprenderá cosas asombrosas. Modere estas expectativas. La cantidad de datos importa, pero la calidad de los datos, las técnicas de entrenamiento y la evaluación también importan.
Los clientes de Databricks pueden confiar en parte en la guía integrada en Databricks durante su viaje por la escalera de personalización de GenAI. Esta guía varía desde APIs simples para modelos generales hasta el Agent Bricks Custom Agents para RAG y agentes, hasta una interfaz de usuario y API para ajuste fino e incluso una API guiada para preentrenamiento.
Sin embargo, cuanto más avance en la personalización, más técnicas y decisiones posibles deberá tomar. Recomendamos que se mantenga práctico. Las técnicas que funcionaron en investigación pueden no funcionar en aplicaciones de la vida real. Los modelos buenos para una tarea pueden ser malos para otra. Las mejores técnicas cambiarán con el tiempo. Para navegar esta complejidad, tenga en cuenta los principios 1 y 2: Defina su estrella polar y sígala basándose en datos y métricas.
También recomendamos asociarse con nosotros. Más allá de su equipo inmediato de Databricks, nuestro equipo de Servicios Profesionales puede guiarlo desde pruebas de concepto iniciales hasta ejecuciones completas de preentrenamiento. Nuestro equipo de Investigación Mosaic se asocia con muchos clientes para ejecuciones de preentrenamiento, brindándoles acceso a conocimientos y asesoramiento de vanguardia.
Técnicas para Construir LLMs Personalizados
Dado que desea ascender en el bucle externo de personalización de modelos, ¿cómo debería abordar las técnicas introducidas con el principio 1? Esta sección discute la evaluación y luego profundiza en las principales técnicas de personalización.
Nota: Esta guía no se enfoca en el bucle interno de iteración sobre un modelo fijo. Para obtener más información sobre esas técnicas, consulte los cursos Fundamentos de IA Generativa y Ingeniería de IA Generativa con Databricks.
Esta sección desarrolla las técnicas de personalización descritas anteriormente en el bucle externo del principio 1. Las enumeramos aquí y observamos que su elección de técnica estará en gran medida determinada por los datos que tenga disponibles (principio 2).
Bucle externo: Escalera de personalización del modelo | ||
Tipo de datos requerido | Orientación del tamaño de los datos | |
Modelo existente | NA | Ninguno, o datos para RAG |
Ajuste fino supervisado | Datos de consulta-respuesta (o datos “etiquetados” de otro modo) | Al menos cientos a decenas de miles de ejemplos |
Preentrenamiento continuo | Texto “crudo” para la predicción del siguiente token | Millones a miles de millones de tokens, o el 1% del conjunto de entrenamiento original |
Preentrenamiento | Texto “crudo” para la predicción del siguiente token | Miles de millones a billones de tokens |
En la siguiente sección, cubriremos cada técnica con más detalle, comenzando con la orientación que se mantiene constante en todas las técnicas.
Datos
Sus datos deben coincidir con su caso de uso. Si está ajustando un modelo para que responda de cierta manera, entonces sus datos de entrenamiento deben demostrar respuestas “buenas”. Si está realizando preentrenamiento continuo para comprender un dominio específico, sus datos deben representar ese dominio.
Aborde los problemas legales y de licencias desde el principio. Al utilizar datos públicos, especialmente para el preentrenamiento, tenga en cuenta que algunos conjuntos de datos públicos están bien curados para evitar complicaciones legales y algunos conjuntos de datos no lo están. Al utilizar sus propios datos empresariales, asegúrese de estar seguro de la procedencia, en particular si los datos provienen de clientes o de modelos GenAI con licencias restrictivas.
Recopile datos temprano y con frecuencia. Las consultas, respuestas y comentarios de los usuarios de sus aplicaciones hoy pueden convertirse en entradas para el ajuste y entrenamiento de su modelo GenAI en el futuro, pero solo si tiene cuidado al respecto. Muchos modelos propietarios y de código abierto vienen con restricciones de uso, por lo que debe rastrear cuidadosamente la procedencia de las respuestas generadas. Para darse flexibilidad en el futuro, evite mezclar modelos y datos con licencias incompatibles y opte por licencias abiertas.
Utilice datos sintéticos con cuidado. Los datos sintéticos pueden ser útiles, pero los datos empresariales genuinos son casi siempre más valiosos. Los datos “reales” se pueden usar para informar a los LLM sobre cómo generar datos sintéticos, lo que aprenderá más adelante en esta guía. Los datos sintéticos siguen siendo un área activa de investigación.
Modelos
Tenga en cuenta los modelos base frente a los modelos de instrucciones/chat. La mayoría de las principales versiones de LLM incluyen tanto modelos base (preentrenados pero no ajustados) como variantes de seguimiento de instrucciones o chat (ajustados). Consulte nuestras recomendaciones sobre qué tipo usar en las siguientes secciones.
Utilice los modelos sugeridos por las funciones de Databricks. Mosaic Research estudia arquitecturas de modelos de vanguardia, comparte algunas recomendaciones principales para modelos GenAI y prioriza esos modelos principales en Databricks Model Training y otras funciones.
Descienda a código más personalizado según sea necesario. Si los modelos o métodos de entrenamiento predeterminados no se ajustan a sus necesidades, siempre puede “bajar en la pila” y usar código más personalizado. Los clústeres acelerados por GPU de Databricks (cómputo general) y Databricks Model Training (cómputo especializado de aprendizaje profundo) admiten código de entrenamiento arbitrario para GenAI y otros modelos de aprendizaje profundo.
Identifique modelos que muestren potencial para su caso de uso. Antes de ajustar, examine si el modelo genérico muestra potencial para su aplicación. El “potencial” puede medirse mediante pruebas manuales ad hoc utilizando el AI Playground o una prueba más rigurosa utilizando un conjunto de datos de referencia o su conjunto de datos de evaluación personalizado. Las pruebas pueden requerir entrenamiento a pequeña escala. Para el ajuste fino, ¿mejora el modelo después del ajuste fino en un pequeño conjunto de 100 ejemplos? Para el preentrenamiento, ¿mejora el modelo a partir del preentrenamiento continuo en un conjunto de datos específico?
Recuerde sus restricciones. Elija el tamaño de su modelo en función de sus restricciones de costo y latencia en el momento de la inferencia. También recuerde que la creación de modelos personalizados es solo el bucle externo; también puede optimizar los costos y la latencia en el bucle interno, por ejemplo, dirigiendo las solicitudes más simples a modelos más pequeños.
Consejo: Su trabajo en técnicas más simples no se desperdiciará, ya que estas técnicas forman una secuencia. Por ejemplo, después de preentrenar un modelo, generalmente realiza un ajuste fino supervisado a continuación.
Evaluación
El Principio 2 recomienda ser impulsado por los datos, con métricas. Antes de profundizar en los detalles de la creación de modelos personalizados, abordaremos las métricas de evaluación y calidad que pueden guiar su trabajo.
Al igual que en la ingeniería de software, recomendamos seguir una pirámide de pruebas.
Analogía de prueba de software | Velocidad/costo frente a fidelidad | Ejemplos |
Pruebas unitarias | Medidas proxy rápidas y baratas | Pruebas con respuestas correctas/incorrectas |
Pruebas de integración | Pruebas de velocidad/costo medio | Métricas de LLM-como-juez en conjuntos de datos de referencia |
Pruebas de extremo a extremo | Pruebas lentas pero realistas | Retroalimentación humana |
Los ejemplos en la pirámide de pruebas anterior están escritos de forma genérica y evitan la cuestión de probar modelos (el bucle externo del principio 1) frente a sistemas de IA compuestos (bucle interno). Al crear un modelo personalizado, querrá probar tanto el modelo en sí como los sistemas de IA que lo utilizarán. Por ejemplo, las “métricas de LLM-como-juez” podrían usarse para probar la capacidad de seguimiento de instrucciones de un modelo, y podrían usarse para probar las métricas de recuperación y las métricas de respuesta a preguntas de un sistema RAG.
Modelos y tareas específicos frente a generales
Su pirámide de pruebas se verá muy diferente al ajustar un modelo para una tarea específica en comparación con el preentrenamiento de un modelo de propósito general. Ser impulsado por datos y métricas significa adaptar su pirámide de pruebas a los casos de uso posteriores de su modelo.
Si está ajustando un modelo para una tarea específica, recuerde comenzar poco a poco (principio 1). Por ejemplo, podría:
- Crear un conjunto de datos “dorado” de consulta-respuesta para la evaluación. Asegúrese de que esté equilibrado en cuanto a consultas y temas potenciales.
- Utilizar métricas de LLM-como-juez para escalar la evaluación. Seleccione o personalice métricas para su tarea específica.
- Utilizar la evaluación humana o del usuario como prueba final
A medida que comience el preentrenamiento continuo o el preentrenamiento completo, sus evaluaciones pueden volverse más complejas. Al planificar su pirámide de pruebas, desglosa su evaluación a lo largo de las diferentes habilidades que cree que su modelo necesita para que pueda centrarse en las áreas importantes. Eso puede significar:
- Habilidades como conocimiento general, lógica o comprensión lectora
- Dominios como finanzas, derecho o atención médica
- Idiomas, incluidos idiomas naturales o lenguajes de programación
- Otras dimensiones, desde la longitud del contexto hasta las salvaguardias incorporadas
Consejos:
- Adapta tu evaluación a tus casos de uso. Por ejemplo, si estás modificando un modelo para manejar longitudes de contexto más largas, recuerda que las métricas de perplejidad de preentrenamiento continuo no son suficientes. Tu conjunto de datos de evaluación también debe incluir tareas de contexto largo.
- Prueba tanto el aprendizaje como el olvido. Si estás realizando preentrenamiento continuo para mejorar la comprensión de un modelo de un idioma específico (por ejemplo, malayo), considera si tus casos de uso requieren que el modelo mantenga su comprensión existente de otros idiomas (por ejemplo, inglés). Si es así, tu evaluación debería probar tanto el malayo como el inglés.
- Prueba lo que tus clientes usarán realmente. Si estás preentrenando un modelo (base) nuevo, probablemente harás un ajuste fino de instrucciones para crear la versión del modelo que tus clientes usarán realmente. Tu evaluación final (de extremo a extremo) debe ser sobre el modelo ajustado, no sobre el modelo base.
Ejemplos de la creación de DBRX
En mayo de 2024, Databricks lanzó DBRX, un LLM de código abierto de última generación (en ese momento). Su conjunto de evaluación proporciona un buen ejemplo de una pirámide de pruebas, que se describe a continuación.
Analogía de prueba de software | Métricas de ejemplo de la creación de DBRX | |
Pruebas unitarias | 39 benchmarks disponibles públicamente divididos en seis competencias principales: comprensión del lenguaje, comprensión de lectura, resolución de problemas simbólicos, conocimiento del mundo, sentido común y programación | |
Pruebas de integración | Datos de benchmark de conversación multivuelta y seguimiento de instrucciones | |
Datos de benchmark de seguimiento de instrucciones | ||
Chatbot Arena - generador basado en datos de benchmark de preferencia humana | ||
Pruebas de extremo a extremo | Retroalimentación interna y de clientes y pruebas A/B | Pruebas iterativas con usuarios internos y externos para recopilar métricas de pruebas A/B y anotaciones humanas |
Red-teaming | Pruebas de expertos para generar resultados indeseables (ofensivos, sesgados o inseguros) |
Para obtener más información sobre métricas de evaluación, recomendamos este curso de Ingeniería de IA Generativa. Para herramientas, recomendamos Databricks MLflow, que admite métricas automatizadas (LLM como juez), conjuntos de datos de evaluación y una aplicación de evaluación humana. Agent Evaluation utiliza las APIs de MLflow de código abierto para la evaluación de LLM. Para una evaluación más profunda para el preentrenamiento, podemos trabajar contigo para desarrollar tu plan de evaluación personalizado.
Ajuste fino supervisado
La primera técnica de personalización de modelos utilizada por la mayoría de los profesionales es el ajuste fino supervisado (SFT), en el que un modelo se entrena con datos etiquetados para optimizarlo para una tarea o comportamiento específico.
Los casos de uso comunes incluyen:
- Reconocimiento de entidades nombradas: Ajuste fino de un modelo para reconocer entidades específicas del dominio
- Completado de chat y respuesta a preguntas: Ajuste fino de un modelo para responder con un tono específico
- Formato de salida: Ajuste fino de un modelo para responder con salidas estructuradas específicas
- Seguimiento de instrucciones: Después de preentrenar un modelo general, es común usar el ajuste fino de instrucciones para enseñar al modelo a responder a instrucciones y consultas, en lugar de simplemente generar texto de completado
Terminología: “Ajuste fino” a menudo se usa para significar “ajuste fino supervisado”, pero técnicamente, “ajuste fino” es cualquier adaptación de un modelo existente. El preentrenamiento continuo y el aprendizaje por refuerzo a partir de retroalimentación humana (RLHF) también son tipos de ajuste fino.
El ajuste fino es, con diferencia, el tipo de personalización de modelos más rápido y económico. Por ejemplo, para el modelo MPT-7B lanzado en mayo de 2023, el ajuste fino de instrucciones costó $46 para procesar 9.6 millones de tokens, mientras que el preentrenamiento costó $250,800 para procesar 1 billón de tokens.
Datos
Al preparar tus datos, el contenido y el formato son clave. Una gran parte del ajuste fino es enseñar al modelo qué entradas esperar y qué salidas esperas. ¿Cómo esperas que se vean las consultas de tus usuarios, en términos de formato, tono, cobertura temática u otros aspectos? Tus datos de entrenamiento deben representar estas expectativas.
El tamaño de los datos es un tema de pregunta común y, en última instancia, depende del caso de uso. En algunos casos, hemos visto buenos resultados ajustando modelos con conjuntos de datos pequeños de cientos o miles de ejemplos, pero algunas aplicaciones requieren 10,000 o 100,000 ejemplos. Comienza con poco para validar tu plan y luego escala iterativamente, ampliando tu conjunto de datos de entrenamiento si es necesario.
Los datos sintéticos pueden ser útiles para SFT, más comúnmente para expandir un conjunto demasiado pequeño de datos “reales”. Un LLM puede ser instruido para generar datos sintéticos de SFT similares a ejemplos de tus datos reales.
Consulta también la documentación sobre la preparación de datos para Databricks Model Training.
Modelos
Anteriormente en esta guía, recomendamos usar los modelos compatibles con Databricks Model Training por defecto y probar modelos prometedores para tu caso de uso. Un buen ejemplo de esto provino de MPT. Aunque MPT no fue entrenado pensando en el japonés, una prueba rápida de ajuste fino con 100 ejemplos de respuesta a indicaciones en japonés resultó en un modelo sorprendentemente efectivo para un cliente. Esa prueba rápida validó el enfoque y allanó el camino para un ajuste fino a mayor escala.
Al elegir el tamaño de un modelo, considera comenzar con un modelo sobredimensionado. Al ajustar con un conjunto de datos pequeño, es más probable que un modelo más grande produzca buenos resultados que un modelo más pequeño. Comenzar con un modelo grande puede informarte sobre el potencial de tus datos y caso de uso, y el SFT es relativamente económico. Después de ver el potencial, puedes probar con modelos más pequeños y más datos.
Puedes ejecutar SFT en variantes base o instruct/chat de los modelos. Por defecto, recomendamos que uses una variante instruct/chat, especialmente si tienes un conjunto de datos pequeño. Si has realizado preentrenamiento continuo para crear un modelo base personalizado, entonces puedes ejecutar SFT en tu modelo base personalizado.
Databricks Model Training
Databricks Model Training proporciona interfaces sencillas (UI y API) para tareas de ajuste fino supervisado. Más allá de los consejos sobre datos y modelos ya presentados en esta guía, considera:
- Tarea: Las tareas de SFT se pueden especificar de diferentes maneras, dependiendo del formato de consulta esperado. Ten en cuenta que recomendamos el formato de completado de chat por defecto, incluso para tareas de seguimiento de instrucciones, para ajustarse a los estándares comunes.
- Configuración: Al iterar, el primer hiperparámetro a optimizar es la tasa de aprendizaje. Prueba una cuadrícula de tasas y luego amplía a una cuadrícula de tasas de aprendizaje más finas centradas en las mejores tasas iniciales, similar a ajustar las tasas de aprendizaje en los algoritmos tradicionales de aprendizaje automático (ML). Considera también ajustar la duración del entrenamiento (épocas o tokens) basándote en gráficos del progreso del aprendizaje. Algunas tareas de ajuste fino requieren pocas épocas y otras se benefician de más de 50 épocas.
- Evaluación: Especifica un conjunto de datos de evaluaci�ón para que Databricks Model Training calcule las evaluaciones iniciales ("pruebas unitarias"). Incluso un pequeño conjunto de datos de 50 pares de consulta-respuesta puede darte una señal, aunque los conjuntos de datos más grandes y variados son mejores. Usa Databricks MLflow para evaluaciones más exhaustivas, especialmente porque la pérdida de evaluación (o precisión) durante el entrenamiento puede no correlacionarse bien con las evaluaciones del usuario final.
Más sobre ajuste fino supervisado
Recomendamos Databricks Model Training para un flujo de trabajo simple y eficiente por defecto. Sin embargo, si necesitas usar una arquitectura de modelo no compatible o métodos de ajuste más personalizados, puedes ejecutar código completamente personalizado en clústeres de Databricks con aceleración por GPU (cómputo general) y Databricks Model Training.
Esta guía no profundiza en el ajuste fino eficiente de parámetros (PEFT), una familia de técnicas como la adaptación de bajo rango (LoRA) para hacer que el ajuste fino y la inferencia sean más eficientes. Consulta este blog, este blog o Hugging Face PEFT para obtener descripciones y ejemplos de estas técnicas.
Preentrenamiento continuo
El ajuste fino supervisado (SFT) no está diseñado para enseñar a un modelo a comprender un nuevo dominio. Para personalizar un modelo y que comprenda un nuevo idioma, una industria nicho u otra área específica, los profesionales pueden recurrir al preentrenamiento continuo (CPT). El CPT es similar al preentrenamiento, excepto que tomas un modelo preentrenado existente y luego *continúas* el proceso de preentrenamiento utilizando nuevos datos. Después del CPT para adaptarlo a un nuevo dominio, el modelo generalmente se adapta a tareas específicas mediante ajuste fino supervisado.
Los casos de uso comunes incluyen:
- Idiomas: Los modelos generales a menudo han visto muchos idiomas naturales en sus datos de entrenamiento, pero pueden ser débiles en todos menos en los idiomas principales. El CPT puede mejorar la comprensión de un modelo de un idioma específico.
- Programación: Los modelos generales a menudo han visto al menos algunos lenguajes de programación en sus datos de entrenamiento, pero los modelos pueden no estar diseñados principalmente para codificar o pueden no entender bien un lenguaje de programación específico. El CPT puede enseñar a un modelo a codificar en un lenguaje de programación específico.
- Dominios industriales: Los modelos generales pueden no tener un conocimiento profundo de áreas temáticas específicas, como biología molecular, derecho ambiental o regulaciones financieras. El CPT puede mejorar el conocimiento y la comprensión de un modelo de un dominio específico.
Para mejorar el modelo de seguimiento de instrucciones de mi bot de RAG Q&A, ¿debería usar ajuste fino supervisado (SFT) o preentrenamiento continuo (CPT)?
Ambas técnicas pueden ser aplicables, pero depende de los datos de entrenamiento que tengas y de lo que quieras mejorar en el modelo. Si quieres enseñar al modelo a responder de cierta manera, usa SFT, si tienes datos de consulta-respuesta para entrenar. Si el modelo no entiende tu dominio o idioma, usa CPT, si tienes una cantidad considerable de datos de texto para entrenar. Ten en cuenta que después del CPT, probablemente necesitarás ejecutar SFT para volver a enseñar al modelo cómo responder a las consultas.
¿Puedo usar SFT o CPT para enseñar a mi modelo nuevos conocimientos y hechos?
Sí, ambas técnicas pueden impartir algo de conocimiento, pero el CPT es más aplicable. Independientemente, es posible que necesites usar RAG para hacer que tu sistema de IA sea robusto al basar las respuestas en datos de origen.
Datos
Al considerar los datos que necesitas para CPT, recuerda el principio 2 ("basado en datos"). *¿Qué quieres mejorar sobre el modelo original?* Tus datos deben representar el dominio, idioma, conocimiento, etc. que deseas inculcar en el modelo. Para un caso de uso específico, esto probablemente se traducirá en ejecutar CPT en tus datos empresariales propietarios relevantes para el caso de uso: tus documentos de base de conocimiento internos, artículos de investigación relevantes de los últimos 20 años, etc. Para un modelo más general, nuestra guía para datos se parece más a la del preentrenamiento, donde puedes seleccionar varios conjuntos de datos para representar las diferentes habilidades importantes para tu caso de uso.
*Consejo: Olvidar vs. aprender*. Al probar CPT, ten en cuenta que existen compensaciones entre olvidar el conocimiento pasado y aprender nuevo conocimiento. Tu objetivo es cambiar el comportamiento del modelo para que imite tus datos de entrenamiento CPT, pero eso puede significar olvidar aspectos de los datos de preentrenamiento originales. Por lo tanto, asegúrate de que tanto tus datos de entrenamiento CPT como tu conjunto de evaluación cubran los dominios que te importan.
Para el *formato de datos*, tus datos serán texto "crudo". Es decir, ejecutarás CPT haciendo predicción del siguiente token, al igual que en el preentrenamiento.
Para el *tamaño de los datos*, el CPT puede abarcar desde ajustar un modelo usando menos tokens hasta cambiar significativamente un modelo usando muchos tokens. "Menos" y "muchos" dependerán del tamaño del modelo, pero una estimación razonable son miles de millones de tokens para LLMs modernos de tamaño mediano. Una regla general es que el CPT requerirá al menos ~1% del tamaño del conjunto de entrenamiento original.
¿Necesito datos crudos para CPT y datos de respuesta a indicaciones para SFT?
Si ejecutas CPT seguido de SFT, entonces sí. Sin embargo, si tienes datos para CPT pero pocos datos para SFT, puedes aumentar tu pequeño conjunto de datos SFT con datos de consulta-respuesta utilizando otros conjuntos de datos SFT o datos sintéticos.
Los *datos sintéticos* pueden ser útiles para CPT, especialmente para la destilación, en la que se utiliza un modelo grande y potente para generar datos para entrenar un modelo más pequeño. La destilación puede ayudar a crear modelos más pequeños, rápidos y económicos, y puede complementar tus datos no sintéticos específicos para tus casos de uso.
Consulta también la documentación sobre la preparación de datos para Databricks Model Training.
Modelos
Al igual que para SFT, recomendamos usar los modelos compatibles con Databricks Model Training por defecto y probar modelos para ver si prometen para tu caso de uso.
Nuestras recomendaciones sobre el ajuste de un modelo base frente a una variante de instrucción/chat, y sobre la ejecución de SFT después de CPT, están interrelacionadas. La ruta más común, y nuestra recomendación por defecto, es ejecutar CPT en un modelo base, seguido de SFT para ajuste fino de instrucciones o chat. Sin embargo, hay matices:
- Variante base vs. instrucción/chat: Lo más común es ejecutar CPT en el modelo base. Ejecutar CPT en un gran conjunto de datos en una variante de instrucción o chat puede hacer que ese modelo pierda parte de su capacidad de seguir instrucciones o de chatear.
- SFT después de CPT: Si ejecutas CPT en una gran cantidad de datos, probablemente lo seguirás con SFT. Sin embargo, si ejecutas CPT en un modelo de seguimiento de instrucciones o chat usando una pequeña cantidad de datos, es posible que no necesites SFT después. Hemos visto a algunos clientes hacer esto y luego usar el modelo resultante directamente en sus aplicaciones.
Databricks Model Training
Databricks Model Training ofrece interfaces sencillas (UI y API) para CPT. Los consejos para SFT mencionados anteriormente en esta guía se aplican en gran medida a CPT también. Convenientemente, la función de Model Training se puede usar para ejecutar tanto CPT como SFT.
Su pirámide de pruebas de la discusión de evaluación anterior necesitará pruebas más robustas y generales, ya que CPT puede cambiar el modelo de manera más fundamental que SFT. A medida que escale CPT, su pirámide de pruebas puede comenzar a parecerse más a un conjunto de pruebas de preentrenamiento.
Más sobre CPT
A medida que sus cargas de trabajo de CPT se vuelvan más personalizadas y grandes, también puede desear explorar el stack de preentrenamiento que se discute a continuación.
CPT es útil para probar datos para preentrenamiento. Si sus datos de CPT cubren un nuevo dominio (como un nuevo lenguaje de programación), entonces mostrar éxito con CPT indica que los datos pueden ser útiles como parte de un conjunto de datos de preentrenamiento.
Preentrenamiento
Supongamos que su aplicación GenAI ha progresado a través del preentrenamiento continuo y cree que preentrenar un modelo completamente personalizado es el siguiente paso necesario para mejorar su aplicación. Esta sección describe el proceso y las mejores prácticas a un alto nivel, pero en la práctica, debe pasar por el proceso de preentrenamiento con su equipo de Databricks.
¿Debería saltar directamente al preentrenamiento?
No. Incluso si las restricciones regulatorias u otras le exigen que cree un modelo nuevo que posea por completo, es mejor prototipar en los niveles inferiores de la escalera de personalización primero. Esto le permite reducir el riesgo de ejecuciones de preentrenamiento más costosas y complejas.
¿Cuáles son los pasos para el preentrenamiento?
La realidad es que el preentrenamiento es un proceso iterativo y adaptativo, pero los pasos comunes de alto nivel en el preentrenamiento incluyen:
- Primero, avance a través del ajuste fino y el preentrenamiento continuo. ¡Haga su debida diligencia!
- Prepare los conjuntos de datos. Esto ocurre durante el paso 1, en el que CPT le ayuda a probar la utilidad de ciertos conjuntos de datos.
- Preentrene un modelo base que pueda completar texto. Esto implica monitorear el entrenamiento, ajustar la ejecución sobre la marcha y técnicas adaptativas como el aprendizaje curricular para ajustar la mezcla de datos.
- Ejecute el ajuste fino de instrucciones o chat para crear una variante de instrucciones/chat.
- Posiblemente use técnicas como el aprendizaje por refuerzo a partir de retroalimentación humana (RLHF) para ajustar aún más el modelo.
- Durante cada paso anterior, evalúe sus modelos sobre la marcha.
Este breve resumen procesal enfatiza la debida diligencia y la evaluación debido al costo relativamente alto del preentrenamiento completo. Recuerde el ejemplo citado anteriormente del modelo MPT-7B, para el cual el preentrenamiento costó 5452 veces más que el ajuste fino de instrucciones.
Datos
Su elección y tratamiento de los datos jugarán un papel importante en la determinación del éxito de sus ejecuciones de preentrenamiento.
¿Qué datos?
Su mezcla de datos debe elegirse cuidadosamente para representar su aplicación de destino.
- Al igual que las evaluaciones deben desglosarse por las habilidades que desea que tenga su modelo, considere qué le enseñará cada conjunto de datos que aporte al preentrenamiento. Puede probar el impacto de estos conjuntos de datos de antemano utilizando el preentrenamiento continuo.
- Pocos modelos de alto rendimiento vienen con detalles publicados sobre sus mezclas de datos. Algunos modelos más antiguos tienen listas publicadas (por ejemplo, MPT, LLaMA, OLMo). Consulte también esta discusión sobre la mezcla de datos.
- Probablemente mezclará conjuntos de datos públicos y propietarios. Los conjuntos de datos públicos debidamente verificados pueden satisfacer algunas de sus necesidades de entrenamiento, como enseñar habilidades lingüísticas, conocimiento general y algunas habilidades específicas. Los conjuntos de datos propietarios brindan a sus modelos una ventaja competitiva que nadie más puede tener.
La cantidad y calidad de los datos importan, pero en diferentes momentos. Es común comenzar el preentrenamiento con “todos los datos” con controles de calidad más laxos. Inicialmente, más tokens se traducen en más aprendizaje de habilidades lingüísticas básicas. Sin embargo, más tarde, durante el preentrenamiento, es común cambiar la mezcla de datos a un conjunto más pequeño y de mayor calidad. “Alta calidad” no tiene una definición académica, pero intuitivamente significa curado utilizando técnicas de sentido común. Consulte lo siguiente para obtener más información sobre la preparación de datos.
¿Cuántos datos?
- Su tamaño de datos debe elegirse teniendo en cuenta el tamaño y la arquitectura del modelo.
- La regla general de “Chinchilla” es la regla más famosa: # tokens = 20 * # parámetros. Para reducir los costos de inferencia, recomendamos que entrene un modelo más pequeño con más datos para lograr una calidad de generación similar, según los resultados de este artículo de LLaMA.
- Las arquitecturas de mezcla de expertos (MoE) pueden cambiar este cálculo, requiriendo a menudo menos datos para un tamaño de modelo dado. Para MoE, use el número de parámetros activos (no el total de parámetros) para hacer este cálculo.
- Tenga en cuenta que algunas tareas son más difíciles que otras. Por ejemplo, los modelos de 7 mil millones de parámetros generalmente requieren al menos 2 billones de tokens de datos de entrenamiento para abordar el benchmark de codificación HumanEval.
¿Cómo deben prepararse los datos?
- Descarga y análisis: Generalmente necesita adquirir los datos usted mismo. Pocos proveedores ofrecen datos a escala de internet predescargados, y los requisitos regulatorios pueden variar según el cliente.
- Limpieza: Si bien el preentrenamiento puede aprovechar grandes cantidades de datos de baja calidad, vale la pena mejorar la calidad de los datos. Por ejemplo, este artículo de RefinedWeb estima que aproximadamente el 11% de Common Crawl es útil. La limpieza de datos para el preentrenamiento es un tema grande y complejo con mucha investigación activa. Consulte este artículo para una excelente encuesta de pasos comunes, que incluyen:
- Filtrado de idiomas para reducir el texto a los idiomas principales de interés
- Filtrado heurístico para eliminar texto repetitivo, documentos demasiado cortos o largos, texto no natural, etc.
- Filtrado de calidad para identificar texto que probablemente haya sido escrito o revisado por humanos
- Filtrado de dominio para identificar texto sobre los dominios de interés
- Desduplicación de contenido dentro o entre conjuntos de datos
- Filtrado de contenido tóxico y explícito según el origen o el texto
- Tenga en cuenta que todas estas técnicas tienen advertencias. Para cada una, la estrictez del filtro debe ajustarse para equilibrar precisión y exhaustividad. Para algunas, el filtro puede ser erróneo: la duplicación puede indicar que el texto es más válido o importante, y un modelo que nunca ha visto contenido tóxico puede no reconocer la toxicidad y, por lo tanto, repetir fácilmente las entradas tóxicas del usuario.
- Como se mencionó, el preentrenamiento temprano puede usar más datos con controles de calidad más laxos, mientras que el preentrenamiento posterior puede centrarse en subconjuntos de datos más cuidadosamente limpiados.
- Precomputación: Pretokenizar y concatenar datos para optimizar su formato para el preentrenamiento puede mejorar la eficiencia.
El procesamiento de datos es el fuerte original de Databricks. Haga uso de lo siguiente:
- Workflows para definir trabajos y orquestación, con Apache Spark™ y optimizaciones de Delta para procesamiento a escala
- Delta Lake como su formato de almacenamiento de datos
- Unity Catalog para la gestión de datos
- Notebooks,integración con IDE y Databricks SQL para desarrollo y exploración de datos
- Lakehouse Monitoring para monitoreo a largo plazo de pipelines y fuentes de datos
Modelos
Si bien los investigadores anuncian naturalmente nuevas arquitecturas de modelos como grandes avances, hay una razón por la que la arquitectura Transformer todavía domina, a pesar de ser de 2017 — funciona muy bien. De manera similar, generalmente recomendamos adherirse a opciones arquitectónicas probadas y verdaderas, tales como:
- Utilice mecanismos de atención estándar como la atención cuadrática o FlashAttention-2, en lugar de métodos menos probados de la investigación
- Considere arquitecturas de mezcla de expertos (MoEs) para un entrenamiento e inferencia más eficientes, así como aritmética de menor precisión
- Entrene su transformador utilizando la predicción del siguiente token
Databricks admite el preentrenamiento en arquitecturas arbitrarias, pero proporcionamos configuraciones de preentrenamiento más sencillas para las arquitecturas recomendadas principales a través de Databricks Model Training, que proporciona versiones administradas y optimizadas de herramientas como Mosaic LLM Foundry y Mosaic Diffusion. Estas herramientas pueden simplificar las decisiones al proporcionar valores predeterminados estándar y bien probados. Por ejemplo, a partir de julio de 2024, LLM Foundry recomienda FlashAttention-2 como mecanismo de atención estándar y admite arquitecturas MoE como DBRX. Para su aplicación particular, podemos asesorarle sobre los detalles de la arquitectura.
En cuanto al tamaño del modelo, recuerde empezar con uno pequeño (principio 1). Entrenar un modelo de 7 mil millones de parámetros cuesta aproximadamente 10 veces menos que un modelo de 70 mil millones, y puede informar sus decisiones de modelado para cuando escale. Además, considere las restricciones de latencia y costo de su caso de uso como límites para el tamaño potencial del modelo.
Pila de entrenamiento e infraestructura
Con sus datos y decisiones de modelado preparados, es posible que ahora esté listo para el preentrenamiento. Este puede ser el paso más costoso que dé con GenAI, de ahí la cuidadosa preparación en pasos anteriores. Durante este paso, es fundamental utilizar herramientas sólidas y asesores expertos para que el preentrenamiento se desarrolle sin problemas.
Las ejecuciones de preentrenamiento incluyen muchos desafíos. La plataforma Databricks maneja muchos de estos desafíos automáticamente para el usuario.
Desafío | Databricks |
Carga de datos: Es posible que necesite cargar billones de tokens. | Databricks proporciona tiempos de inicio y recuperación rápidos. |
Escalado y optimización: Es posible que necesite escalar de 10 a 1000 GPUs. Hay muchas técnicas para optimizar el rendimiento del entrenamiento. | Databricks proporciona escalado perfecto a través de paralelismo de datos y FSDP, y una biblioteca de optimizaciones componibles. Logra una utilización de FLOPS de modelo de primer nivel (MFU). |
Recuperación de fallos: Puede esperar ~1 fallo de infraestructura cada 1000 días de GPU en la mayoría de las nubes. Los trabajos de preentrenamiento pueden experimentar picos de pérdida o divergencia. | Databricks detecta fallos automáticamente y realiza reinicios rápidos. La pila de entrenamiento también reduce los picos de pérdida. |
Determinismo: La carga y el entrenamiento de datos distribuidos dificultan el determinismo, pero es valioso para la recuperación y la reproducibilidad. | Los algoritmos de carga y entrenamiento de datos de Databricks hacen que el preentrenamiento sea mucho más reproducible. |
La pila de Databricks Training abarca desde el hardware hasta la gestión de cargas de trabajo. La siguiente tabla enumera las piezas clave para aprender primero.
Etapa | Componente de Databricks | Detalles |
Carga de datos | Proporciona streaming rápido y reproducible de datos de entrenamiento desde el almacenamiento en la nube, incluyendo inicios y reinicios rápidos. | |
Entrenamiento | Proporciona mejores prácticas y técnicas componibles para un entrenamiento distribuido y eficiente. | |
Configuración del flujo de trabajo | Permite la definición sencilla de flujos de trabajo, incluyendo preparación de datos, entrenamiento, ajuste fino y evaluación. Databricks puede proporcionar configuraciones estándar para ayudarle a empezar a preentrenar arquitecturas comunes. | |
Seguimiento de experimentos | Realiza un seguimiento de la evaluación y otras métricas durante las ejecuciones de preentrenamiento. Databricks también admite Weights & Biases. |
Su caso de uso puede seguir los caminos bien transitados establecidos como configuraciones “recetas” por LLM Foundry, en cuyo caso su flujo de trabajo puede estar muy impulsado por la configuración. O, si requiere arquitecturas o código más personalizados, puede centrarse en partes de nivel inferior de la pila como MCLI, trabajando más directamente con la infraestructura de Databricks.
Cómputo y costos
Antes de preentrenar un modelo, es importante estimar los costos. El costo de cómputo del preentrenamiento a menudo es sencillo de estimar, ya que se reduce a estimar las horas de GPU, basándose en el tamaño de los datos y del modelo. Su equipo de Databricks puede proporcionar estimaciones precisas, pero para cualquier proveedor, asegúrese de comprender dos cálculos clave:
FLOPS = 6 x parámetros x tokens
Esta regla general le dice que el cómputo (y el costo) escalarán linealmente con el tamaño del modelo y con el tamaño de los datos. Tenga en cuenta que “parámetros” se traducirá como “parámetros activos” para arquitecturas dispersas como MoEs.
Utilización de FLOPS del modelo (MFU) = utilización promedio de GPU en la práctica
La MFU nunca es del 100% en la práctica, y a menudo está muy por debajo. Diferentes modelos y tipos de datos pueden lograr diferentes MFUs. La pila de Databricks está optimizada para lograr una MFU de alto rendimiento.
¿Qué pasa con las épocas?
Entrenar durante N épocas costará N veces más que 1 época. Sin embargo, para el preentrenamiento, es común usar una sola época, aunque puede repetir algunos datos clave de alta calidad en su entrenamiento. Esto es diferente de las muchas épocas utilizadas en el aprendizaje profundo más tradicional. Consulte este artículo para obtener más información.
Además de los costos de cómputo de preentrenamiento, también haga estimaciones para:
- Costos de datos, incluyendo compra, curación y etiquetado
- Costos de inferencia
Durante el preentrenamiento
Una vez que inicie el preentrenamiento, es posible que funcione “simplemente” en Databricks, pero aún así es importante monitorear el entrenamiento y saber cómo depurar o mejorar el aprendizaje. Su equipo de Databricks puede ayudarle a monitorear y depurar problemas.
El monitoreo implica dos áreas principales:
- Infraestructura: Databricks Training se encarga de la mayoría de los problemas de infraestructura por usted. Por ejemplo, automáticamente creará puntos de control y reanudará el entrenamiento cuando fallen las GPUs, la red u otra infraestructura. Es valioso monitorear la utilización, especialmente cuando se usan configuraciones no estándar.
- Progreso del aprendizaje: Se deben supervisar la pérdida y otras métricas en los datos de entrenamiento y evaluación para detectar problemas de configuración y datos. Los síntomas más comunes a tener en cuenta son picos de pérdida y divergencia. En Databricks Training, recomendamos registrar en Experimentos de MLflow de forma predeterminada para la supervisión en vivo y la revisión posterior.
Depuración con mayor frecuencia requiere ajustar:
- Configuraciones: Si sus configuraciones están mal establecidas, estos problemas a menudo aparecen temprano durante el entrenamiento. La tasa de aprendizaje es la configuración más común que requiere ajustes.
- Datos: Por ejemplo, un problema común de entrenamiento es ver picos de pérdida debido a conjuntos de datos mal barajados. Databricks Training simplifica el barajado a través de la biblioteca Mosaic Streaming, pero el barajado tiene un costo, por lo que Streaming admite diferentes configuraciones de barajado para admitir compensaciones de calidad-costo. Si ve picos de pérdida, es posible que la configuración de barajado más sólido en Streaming evite los picos. Por ejemplo, si sus datos provienen de diferentes grupos (dominios, idiomas, etc.) y no se barajan correctamente, es más probable que vea picos de pérdida.
Aprendizaje curricular: El preentrenamiento a menudo no se ejecutará en un conjunto de datos único y homogéneo. El modelo final a menudo se puede mejorar variando la mezcla de datos durante el proceso de entrenamiento, y la técnica más común para eso es el aprendizaje curricular, en el que se enfatizan los conjuntos de datos de mayor calidad y más específicos en la mezcla de datos más adelante durante el entrenamiento. Las mezclas de datos se pueden especificar de antemano, o la mezcla de datos se puede ajustar manualmente para fortalecer el modelo en ciertas áreas.
Después del preentrenamiento
Después del preentrenamiento, puede haber pasos adicionales para preparar un modelo para aplicaciones finales, tales como:
- Aprendizaje curricular adicional o preentrenamiento continuo para ajustar el modelo
- Ajuste fino supervisado, como para seguir instrucciones o chatear
- Aprendizaje por refuerzo a partir de retroalimentación humana (RLHF), una técnica avanzada para ajustar un modelo para que coincida con las preferencias humanas. Esto puede ser muy poderoso pero complejo de hacer correctamente, y no es necesario para todas las aplicaciones. Para muchas aplicaciones, el ajuste fino supervisado o las salvaguardias pueden ser suficientes.
- Iterar sobre lo anterior, basándose en las evaluaciones de los usuarios finales del modelo o la aplicación
El Futuro
El ritmo del desarrollo de GenAI no se está desacelerando. Las GPU y otro hardware especializado serán más rápidos y baratos. Las pilas de software mejorarán. Las nuevas arquitecturas de modelos y técnicas de entrenamiento pasarán de la investigación a la práctica. ¿Qué puede hacer para estar preparado?
Con Databricks, podrá aprovechar muchos desarrollos de forma predeterminada. Databricks Model Training, Model Serving y otras características continuarán agregando soporte para los últimos modelos principales. Se integrarán nuevas técnicas de entrenamiento e inferencia bajo el capó. Para cargas de trabajo más grandes y complejas, Databricks admitirá la personalización completa, y las cargas de trabajo más vanguardistas se realizarán de la mano del equipo de Investigación de Mosaic.
En su organización, concéntrese en admitir cargas de trabajo flexibles y personalizables ahora y en el futuro:
- Desarrolle su infraestructura de IA. Configure la gobernanza de API de modelos a través de una puerta de enlace de IA. Configure procesos de seguridad utilizando un marco de seguridad de IA. Estandarice y unifique los datos y la gobernanza de IA bajo Unity Catalog. Desarrolle tanto el bucle interno utilizando Agent Framework como el bucle externo utilizando Model Training. Desarrolle su práctica de MLOps, incluyendo Model Serving robusto y Monitoreo.
- Desarrolle su experiencia en IA. Trabaje con su equipo de Databricks para desarrollar un centro de excelencia (CoE) para IA. Aproveche Databricks Training para guiar a los equipos a lo largo de rutas de aprendizaje adaptadas a sus roles.
- Desarrolle su propiedad intelectual. Esta PI incluirá no solo modelos personalizados sino, lo que es más importante, sus datos empresariales. Recopile datos de aplicaciones y usuarios actuales, rastree la procedencia y tenga cuidado con la regulación y las licencias. Estos datos potenciarán toda su personalización de GenAI, tanto RAG en el bucle interno como ajuste fino y preentrenamiento en el bucle externo.
Recursos
Cursos
- Tome el tutorial de ritmo propio Introducción a la IA Generativa y obtenga un certificado de Databricks
- Fundamentos de IA Generativa (Databricks Academy)
- Ingeniería de IA Generativa con Databricks (Capacitación impartida por instructor y Databricks Academy)
- Consulte Databricks Training y Databricks Academy para ver nuevos cursos
Lectura
- El Gran Libro de la IA Generativa para una colección de publicaciones de blog que profundizan en diferentes aspectos del desarrollo de modelos y sistemas de IA generativa
- Una Guía Compacta de Generación Aumentada por Recuperación (RAG) para una inmersión profunda en la creación de aplicaciones de IA generativa utilizando LLM que han sido aumentados con datos empresariales
- Publicaciones del blog de Mosaic Research
- Creación de LLM personalizados de clase DBRX con Databricks Training (mayo de 2024)
- MosaicML StreamingDataset: Streaming Rápido y Preciso de Datos de Entrenamiento desde Almacenamiento en la Nube (febrero de 2023)
- Entrenamiento de Stable Diffusion desde Cero por menos de $50k con MosaicML (abril de 2023)
- El Gran Libro de MLOps: Segunda Edición para una inmersión profunda en MLOps con Databricks, incluyendo LLMOps
- Página Databricks para una descripción general del producto, detalles de las características y enlaces a muchos recursos
- Documentación de Databricks para GenAI para AWS, Azure y GCP
Charlas de Data + AI Summit 2024
- Personalización de sus modelos: RAG, ajuste fino y preentrenamiento
- En las trincheras con DBRX: Construcción de un modelo de código abierto de última generación
Acerca de Databricks
Databricks es la empresa de datos e IA. Más de 10.000 organizaciones en todo el mundo —incluyendo Block, Comcast, Condé Nast, Rivian, Shell y el 70% de las Fortune 500— confían en la Plataforma de Inteligencia de Datos de Databricks para tomar el control de sus datos y ponerlos a trabajar con IA. Databricks tiene su sede en San Francisco, con oficinas en todo el mundo, y fue fundada por los creadores originales de Lakehouse, Apache SparkTM, Delta Lake y MLflow. Para obtener más información, sigue a Databricks en LinkedIn, X y Facebook.
Contáctanos para una demostración personalizada:
databricks.com/contact
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.