¿Qué es la generación aumentada por recuperación (RAG)?
Técnica que mejora las respuestas de los LLM al recuperar información relevante de bases de conocimientos externas antes de la generación, fundamentando los resultados en hechos
- La generación aumentada por recuperación es un patrón de AI que mejora las respuestas de los modelos de lenguaje grande al recuperar primero documentos relevantes de fuentes de datos externas y luego introducir ese contexto en el modelo.
- RAG ayuda a reducir las alucinaciones, mantener las respuestas actualizadas y adaptar los resultados al propio contenido de una organización sin reentrenar el modelo subyacente.
- Los casos de uso comunes de RAG incluyen chatbots de soporte al cliente, búsqueda de conocimiento interna y experiencias de búsqueda aumentada que responden preguntas directamente a partir de documentos de la empresa.
¿Qué es la generación aumentada por recuperación o RAG?
La generación aumentada por recuperación (RAG) es un marco de trabajo híbrido de AI que refuerza los modelos de lenguaje grande (LLMs) al combinarlos con fuentes de datos externas y actualizadas. En lugar de depender únicamente de datos de entrenamiento estáticos, RAG recupera documentos relevantes en el momento de la consulta y los introduce en el modelo como contexto. Al incorporar datos nuevos y sensibles al contexto, la AI puede generar respuestas más precisas, actuales y específicas de un dominio.
RAG se está convirtiendo rápidamente en la arquitectura de referencia para crear aplicaciones de AI de nivel empresarial. Según encuestas recientes, más del 60 % de las organizaciones están desarrollando herramientas de recuperación impulsadas por AI para mejorar la confiabilidad, reducir las alucinaciones y personalizar los resultados utilizando datos internos.
A medida que la AI generativa se expande a funciones comerciales como el servicio al cliente, la gestión del conocimiento interno y el cumplimiento normativo, la capacidad de RAG para cerrar la brecha entre la AI general y el conocimiento organizacional específico la convierte en una base esencial para implementaciones confiables en el mundo real.
Cómo funciona RAG
RAG mejora la salida de un modelo de lenguaje al inyectarle información en tiempo real y sensible al contexto recuperada de una fuente de datos externa. Cuando un usuario envía una consulta, el sistema primero activa el modelo de recuperación, que utiliza una base de datos vectorial para identificar y "recuperar" documentos, bases de datos u otras fuentes semánticamente similares para obtener información relevante. Una vez identificados, combina esos resultados con el prompt de entrada original y los envía a un modelo de AI generativa, que sintetiza la nueva información en su propio modelo.
Esto permite que el LLM produzca respuestas más precisas y sensibles al contexto, basadas en datos actualizados o específicos de la empresa, en lugar de depender simplemente del modelo con el que fue entrenado.
Los pipelines de RAG suelen constar de cuatro pasos: preparación y fragmentación (chunking) de documentos, indexación vectorial, recuperación y aumento de prompts. Este flujo de proceso ayuda a los desarrolladores a actualizar las fuentes de datos sin tener que volver a entrenar el modelo, y convierte a RAG en una solución escalable y rentable para crear aplicaciones de LLM en dominios como el soporte al cliente, las bases de conocimiento y la búsqueda interna.
¿Qué desafíos resuelve el enfoque de generación aumentada por recuperación?
Problema 1: Los modelos LLM no conocen sus datos
Los LLMs utilizan modelos de aprendizaje profundo (deep learning) y se entrenan con conjuntos de datos masivos para comprender, resumir y generar contenido nuevo. La mayoría de los LLMs se entrenan con una amplia gama de datos públicos para que un solo modelo pueda responder a muchos tipos de tareas o preguntas. Una vez entrenados, muchos LLMs no tienen la capacidad de acceder a datos más allá de su fecha límite de datos de entrenamiento. Esto hace que los LLMs sean estáticos y puede provocar que respondan de forma incorrecta, den respuestas desactualizadas o alucinen cuando se les hacen preguntas sobre datos con los que no han sido entrenados.
Problema 2: Las aplicaciones de AI deben aprovechar los datos personalizados para ser eficaces
Para que los LLMs ofrezcan respuestas relevantes y específicas, las organizaciones necesitan que el modelo comprenda su dominio y proporcione respuestas a partir de sus datos, en lugar de dar respuestas amplias y generalizadas. Por ejemplo, las organizaciones crean bots de soporte al cliente con LLMs, y esas soluciones deben ofrecer respuestas específicas de la empresa a las preguntas de los clientes. Otras están creando bots de Q&A internos que deberían responder a las preguntas de los empleados sobre datos internos de HR. ¿Cómo crean las empresas estas soluciones sin volver a entrenar esos modelos?
Solución: La aumentación por recuperación es ahora un estándar de la industria
Una forma sencilla y popular de utilizar sus propios datos es proporcionarlos como parte del prompt con el que consulta al modelo LLM. Esto se denomina generación aumentada por recuperación (RAG), ya que recuperaría los datos relevantes y los utilizaría como contexto aumentado para el LLM. En lugar de depender únicamente del conocimiento derivado de los datos de entrenamiento, un flujo de trabajo de RAG extrae información relevante y conecta los LLMs estáticos con la recuperación de datos en tiempo real.
Con la arquitectura RAG, las organizaciones pueden implementar cualquier modelo LLM y aumentarlo para que devuelva resultados relevantes para su organización proporcionándole una pequeña cantidad de sus datos, sin los costos y el tiempo de realizar un ajuste fino (fine-tuning) o un preentrenamiento del modelo.
¿Cuáles son los casos de uso de RAG?
Existen muchos casos de uso diferentes para RAG. Los más comunes son:
Chatbots de preguntas y respuestas: La incorporación de LLMs en los chatbots les permite obtener automáticamente respuestas más precisas a partir de los documentos y las bases de conocimiento de la empresa. Los chatbots se utilizan para automatizar el soporte al cliente y el seguimiento de clientes potenciales en el sitio web para responder preguntas y resolver problemas rápidamente.
Por ejemplo, Experian, una empresa multinacional de intermediación de datos e informes de crédito al consumo, quería crear un chatbot para atender necesidades internas y de cara al cliente. Pronto se dieron cuenta de que sus tecnologías de chatbot actuales tenían dificultades para escalar y satisfacer la demanda. Al desarrollar su chatbot de GenAI (Latte) en la plataforma Databricks Data Intelligence Platform, Experian pudo mejorar la gestión de prompts y la precisión del modelo, lo que dio a sus equipos una mayor flexibilidad para experimentar con diferentes prompts, perfeccionar los resultados y adaptarse rápidamente a las evoluciones de la tecnología de GenAI.
- Aumento de búsqueda: La incorporación de LLMs en los motores de búsqueda que aumentan los resultados de búsqueda con respuestas generadas por LLM puede responder mejor a las consultas informativas y facilitar que los usuarios encuentren la información que necesitan para realizar su trabajo.
Motor de conocimiento: Hacer preguntas sobre sus datos (por ejemplo, documentos de HR o de cumplimiento normativo): Los datos de la empresa se pueden utilizar como contexto para los LLMs y permitir que los empleados obtengan respuestas a sus preguntas fácilmente, incluidas las preguntas de HR relacionadas con beneficios y políticas, y las preguntas de seguridad y cumplimiento normativo.
Una forma en que se está implementando esto es en Cycle & Carriage, un grupo automotriz líder en el sudeste asiático. Recurrieron a Databricks para desarrollar un chatbot de RAG que mejora la productividad y el compromiso del cliente al aprovechar sus bases de conocimiento patentadas, como manuales técnicos, transcripciones de soporte al cliente y documentos de procesos comerciales. Esto facilitó que los empleados buscaran información a través de consultas en lenguaje natural que ofrecen respuestas contextuales en tiempo real.
¿Cuáles son los beneficios de RAG?
El enfoque RAG tiene una serie de beneficios clave, que incluyen:
- Proporcionar respuestas actualizadas y precisas: RAG garantiza que la respuesta de un LLM no se base únicamente en datos de entrenamiento estáticos y desactualizados. En su lugar, el modelo utiliza fuentes de datos externas actualizadas para proporcionar respuestas.
- Reducir las respuestas inexactas o alucinaciones: Al basar la salida del modelo LLM en conocimiento externo relevante, RAG intenta mitigar el riesgo de responder con información incorrecta o inventada (también conocida como alucinaciones). Los resultados pueden incluir citas de fuentes originales, lo que permite la verificación humana.
- Proporcionar respuestas relevantes y específicas del dominio: Al usar RAG, el LLM podrá proporcionar respuestas contextualmente relevantes adaptadas a los datos patentados o específicos del dominio de una organización.
- Ser eficiente y rentable: En comparación con otros enfoques para personalizar los LLMs con datos específicos del dominio, RAG es simple y rentable. Las organizaciones pueden implementar RAG sin necesidad de personalizar el modelo. Esto es especialmente beneficioso cuando los modelos deben actualizarse con frecuencia con datos nuevos.
¿Cuándo debería usar RAG y cuándo debería realizar un ajuste fino del modelo?
RAG es el punto de partida adecuado, ya que es sencillo y posiblemente sea completamente suficiente para algunos casos de uso. El ajuste fino (fine-tuning) es más apropiado en una situación diferente, cuando se desea cambiar el comportamiento del LLM o aprender un "idioma" diferente. Estos no son mutuamente excluyentes. Como paso futuro, es posible considerar el ajuste fino de un modelo para comprender mejor el lenguaje del dominio y la forma de salida deseada, y también utilizar RAG para mejorar la calidad y relevancia de la respuesta.
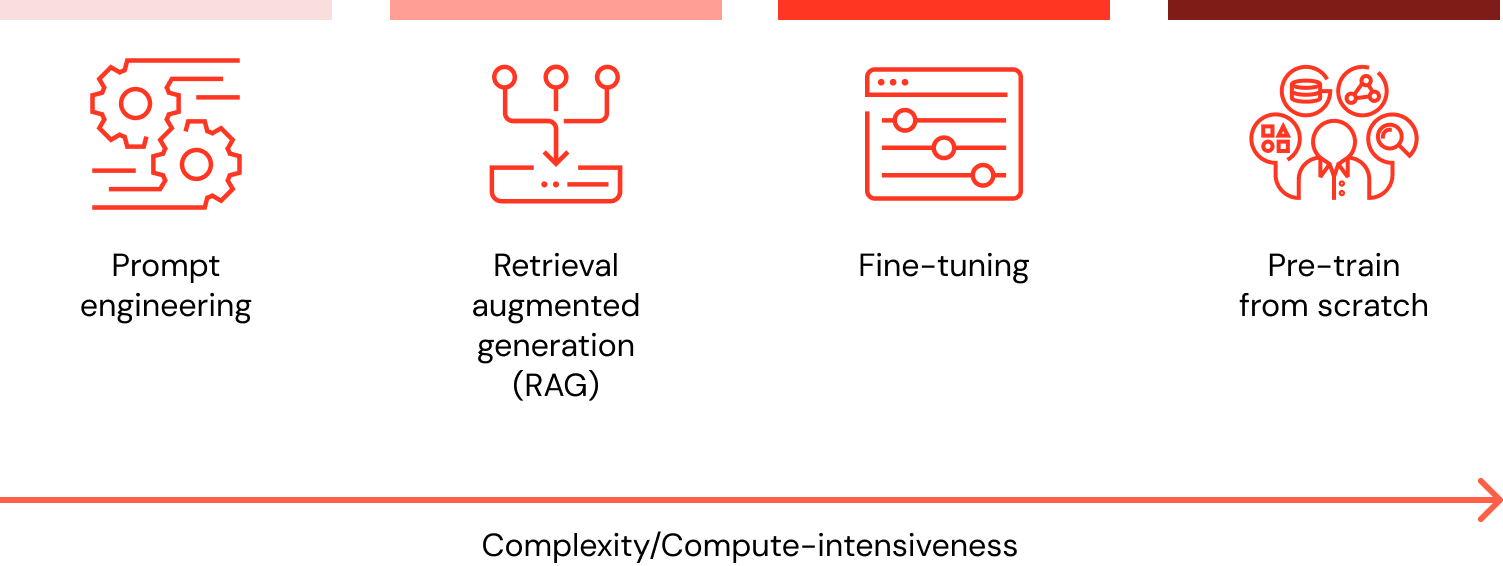
Cuando quiero personalizar mi LLM con datos, ¿cuáles son todas las opciones y qué método es el mejor (ingeniería de prompts frente a RAG frente a ajuste fino frente a preentrenamiento)?
Hay cuatro patrones arquitectónicos a considerar al personalizar una aplicación de LLM con los datos de su organización. Estas técnicas se describen a continuación y no son mutuamente excluyentes. Más bien, pueden (y deben) combinarse para aprovechar las fortalezas de cada una.
| Método | Definición | Caso de uso principal | Requisitos de datos | Ventajas | Consideraciones |
|---|---|---|---|---|---|
Ingeniería de prompts | Creación de prompts especializados para guiar el comportamiento de los LLM | Guía rápida y sobre la marcha para el modelo | Ninguno | Rápido, rentable, no requiere entrenamiento | Menor control que el ajuste fino (fine-tuning) |
Generación aumentada por recuperación (RAG) | Combinación de un LLM con recuperación de conocimiento externo | Conjuntos de datos dinámicos y conocimiento externo | Base de datos o base de conocimientos externa (por ejemplo, base de datos vectorial) | Contexto actualizado dinámicamente, precisión mejorada | Aumenta la longitud del prompt y el cálculo de inferencia |
Fine-tuning | Adaptación de un LLM preentrenado a conjuntos de datos o dominios específicos | Especialización en dominios o tareas | Miles de ejemplos específicos del dominio o de instrucciones | Control granular, alta especialización | Requiere datos etiquetados, costo computacional |
Preentrenamiento | Entrenamiento de un LLM desde cero | Tareas únicas o corporación específica del dominio | Grandes conjuntos de datos (de miles de millones a billones de tokens) | Control máximo, adaptado a necesidades específicas | Extremadamente intensivo en recursos |

Independientemente de la técnica seleccionada, crear una solución de manera bien estructurada y modularizada garantiza que las organizaciones estén preparadas para iterar y adaptarse. Obtenga más información sobre este enfoque y otros temas en The Big Book of MLOps.
Desafíos comunes en la implementación de RAG
La implementación de RAG a escala plantea varios desafíos técnicos y operativos.
- Calidad de la recuperación. Incluso los LLM más potentes pueden generar respuestas deficientes si recuperan documentos irrelevantes o de baja calidad. Por lo tanto, es fundamental desarrollar un pipeline de recuperación eficaz que incluya una selección cuidadosa de modelos de embedding, métricas de similitud y estrategias de ranking.
- Limitaciones de la ventana de contexto. Al tener a su alcance toda la documentación del mundo, el riesgo puede ser inyectar demasiado contenido en el modelo, lo que da lugar a fuentes truncadas o respuestas diluidas. Las estrategias de fragmentación (chunking) deben sopesar la coherencia semántica con la eficiencia de los tokens.
- Actualización de los datos. El beneficio de RAG radica en su capacidad para extraer información actualizada. Sin embargo, los índices de documentos pueden quedar desactualizados rápidamente sin tareas de ingesta programadas o actualizaciones automatizadas. Al garantizar que sus datos estén actualizados, puede evitar alucinaciones o respuestas obsoletas.
- Latencia. Al trabajar con grandes conjuntos de datos o API externas, la latencia puede interferir con la recuperación, el ranking y la generación.
- Evaluación de RAG. Debido a la naturaleza híbrida de RAG, los modelos tradicionales de evaluación de AI se quedan cortos. Evaluar la precisión de los resultados requiere una combinación de criterio humano, puntuación de relevancia y comprobaciones de fundamentación (groundedness) para evaluar la calidad de la respuesta.
¿Qué es una arquitectura de referencia para aplicaciones RAG?
Existen muchas formas de implementar un sistema de generación aumentada por recuperación, según las necesidades específicas y los matices de los datos. A continuación, se presenta un flujo de trabajo comúnmente adoptado para proporcionar una comprensión fundamental del proceso.
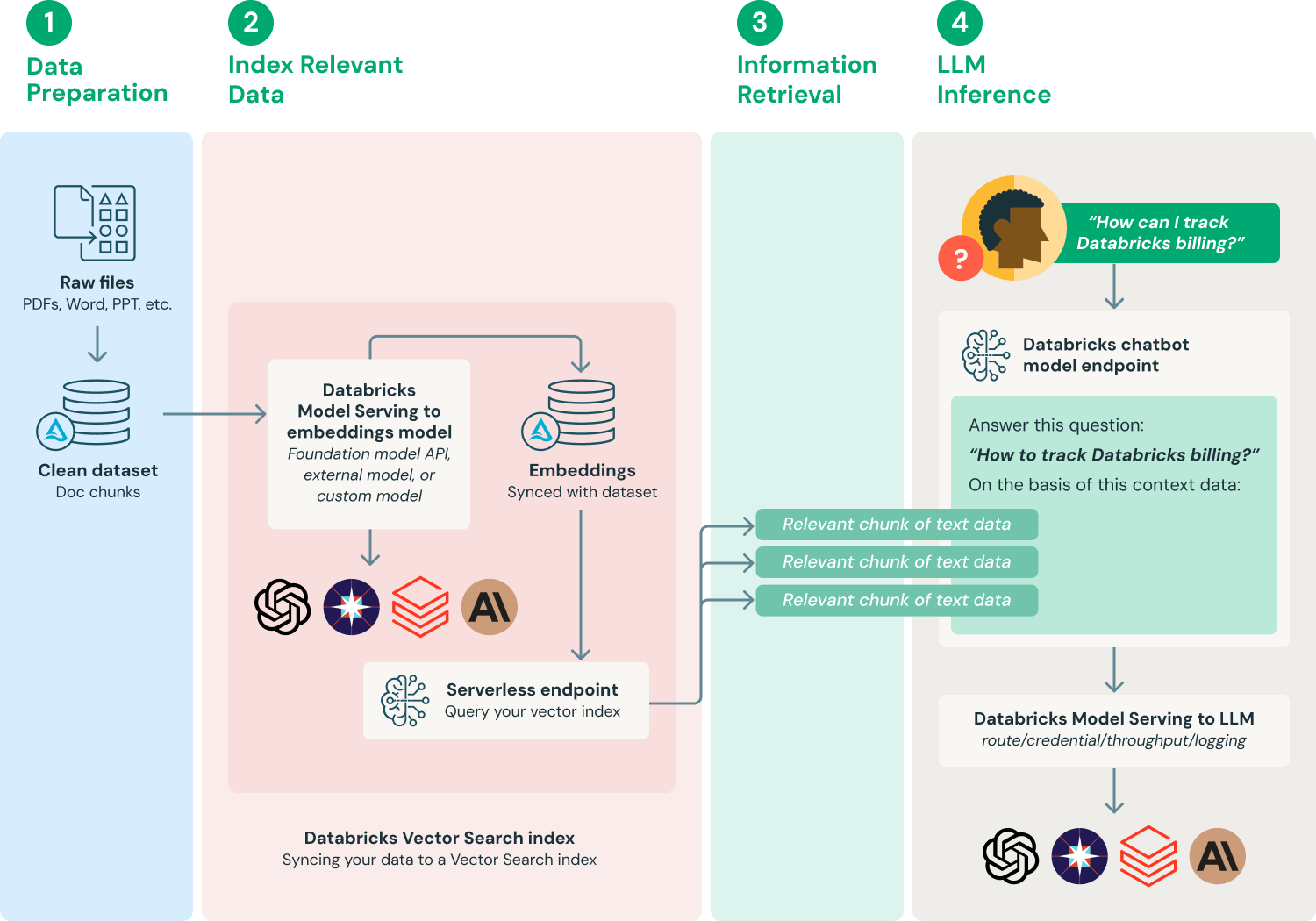
- Preparar los datos: Se recopilan los datos de los documentos junto con los metadatos y se someten a un preprocesamiento inicial; por ejemplo, el manejo de PII (detección, filtrado, redacción, sustitución). Para utilizarlos en aplicaciones RAG, los documentos deben fragmentarse en longitudes adecuadas según la elección del modelo de embedding y la aplicación de LLM descendente (downstream) que utiliza estos documentos como contexto.
- Indexar datos relevantes: Producir embeddings de documentos e hidratar un índice de AI Search con estos datos.
- Recuperar datos relevantes: Recuperación de las partes de sus datos que son relevantes para la consulta de un usuario. Esos datos de texto se proporcionan luego como parte del prompt que se utiliza para el LLM.
- Crear aplicaciones de LLM: Encapsular los componentes de aumento de prompts y consulta al LLM en un endpoint. Este endpoint se puede exponer a aplicaciones como chatbots de Q&A a través de una API REST sencilla.
Databricks también recomienda algunos elementos arquitectónicos clave de una arquitectura RAG:
- Base de datos vectorial: Algunas aplicaciones de LLM (pero no todas) utilizan bases de datos vectoriales para realizar búsquedas rápidas de similitud, la mayoría de las veces para proporcionar contexto o conocimiento del dominio en las consultas de LLM. Para garantizar que el modelo de lenguaje implementado tenga acceso a información actualizada, las actualizaciones periódicas de la base de datos vectorial se pueden programar como un job. Tenga en cuenta que la lógica para recuperar de la base de datos vectorial e inyectar información en el contexto del LLM se puede empaquetar en el artefacto del modelo registrado en MLflow utilizando las variantes de modelo (flavors) de MLflow LangChain o PyFunc.
- MLflow LLM Deployments o Model Serving: En las aplicaciones basadas en LLM donde se utiliza una API de LLM de terceros, el soporte de MLflow LLM Deployments o Model Serving para modelos externos se puede utilizar como una interfaz estandarizada para enrutar las solicitudes de proveedores como OpenAI y Anthropic. Además de proporcionar una puerta de enlace de API (API gateway) de nivel empresarial, MLflow LLM Deployments o Model Serving centraliza la gestión de claves de API y ofrece la capacidad de aplicar controles de costos.
- Model Serving: En el caso de RAG que utiliza una API de terceros, un cambio arquitectónico clave es que el pipeline de LLM realizará llamadas a API externas, desde el endpoint de Model Serving a las API de LLM internas o de terceros. Cabe señalar que esto añade complejidad, latencia potencial y otra capa de gestión de credenciales. Por el contrario, en el ejemplo del modelo con ajuste fino (fine-tuned), se implementarán el modelo y su entorno de modelo.
Recursos
- Publicaciones de blog de Databricks
- Demostración de Databricks
- eBook de Databricks — The Big Book of MLOps
Clientes de Databricks que utilizan RAG
JetBlue
JetBlue ha implementado "BlueBot", un chatbot que utiliza modelos de AI generativa de código abierto complementados con datos corporativos, con tecnolog�ía de Databricks. Todos los equipos de JetBlue pueden usar este chatbot para acceder a datos regulados por rol. Por ejemplo, el equipo de finanzas puede ver datos de SAP y presentaciones regulatorias, pero el equipo de operaciones solo verá información de mantenimiento.
Lea también este artículo.
Chevron Phillips
Chevron Phillips Chemical utiliza Databricks para dar soporte a sus iniciativas de AI generativa, incluida la automatización del procesamiento de documentos.
Thrivent Financial
Thrivent Financial está analizando la AI generativa para mejorar las búsquedas, generar insights mejor resumidos y más accesibles, y mejorar la productividad de la ingeniería.
¿Dónde puedo encontrar más información sobre la generación aumentada por recuperación?
Hay muchos recursos disponibles para encontrar más información sobre RAG, entre ellos:
Blogs
- Creación de aplicaciones RAG de alta calidad con Databricks
- Vista previa pública de Databricks AI Search
- Mejore la calidad de las respuestas de las aplicaciones RAG con datos estructurados en tiempo real
- Cree aplicaciones de Gen AI más rápido con las nuevas capacidades de modelos fundacionales
- Prácticas recomendadas para la evaluación con LLM de aplicaciones RAG
- Uso de MLflow AI Gateway y Llama 2 para crear aplicaciones de AI generativa (Logre una mayor precisión utilizando la generación aumentada por recuperación (RAG) con sus propios datos)
E-books
Demos
Póngase en contacto con Databricks para programar una demostración y hablar con alguien sobre sus proyectos de LLM y generación aumentada por recuperación (RAG)
La guía de IA agéntica para la empresa

El futuro de la tecnología RAG
RAG está evolucionando rápidamente de ser una solución provisional improvisada a convertirse en un componente fundamental de la arquitectura de AI empresarial. A medida que los LLM se vuelven más capaces, el papel de RAG está cambiando. Está pasando de simplemente llenar vacíos de conocimiento a sistemas estructurados, modulares y más inteligentes.
Una de las formas en que RAG se está desarrollando es a través de arquitecturas híbridas, donde RAG se combina con herramientas, bases de datos estructuradas y agentes de llamada a funciones. En estos sistemas, RAG proporciona una base no estructurada, mientras que los datos estructurados o las API se encargan de tareas más precisas. Estas arquitecturas multimodales ofrecen a las organizaciones una automatización integral más confiable.
Otro avance importante es el coentrenamiento de recuperador y generador. Este es un modelo en el que el recuperador de RAG y el generador se entrenan conjuntamente para optimizar la calidad de las respuestas del otro. Esto puede reducir la necesidad de ingeniería de prompts manual o de ajuste fino (fine-tuning), y da lugar a aspectos como el aprendizaje adaptativo, la reducción de alucinaciones y un mejor rendimiento general de los recuperadores y generadores.
A medida que las arquitecturas de LLM maduren, es probable que RAG se vuelva más integrado y contextual. Yendo más allá de los almacenes finitos de memoria e información, estos nuevos sistemas serán capaces de gestionar flujos de datos en tiempo real, razonamiento multidocumento y memoria persistente, convirtiéndose en asistentes expertos y confiables.
Preguntas frecuentes (FAQ)
¿Qué es la generación aumentada por recuperación (RAG)?
RAG es una arquitectura de AI que refuerza los LLM mediante la recuperación de documentos relevantes y su inserción en el prompt. Esto permite obtener respuestas más precisas, actualizadas y específicas del dominio sin perder tiempo en volver a entrenar el modelo.
¿Cuándo debería usar RAG en lugar del ajuste fino (fine-tuning)?
Utilice RAG cuando desee incorporar datos dinámicos sin el costo ni la complejidad del ajuste fino. Es ideal para casos de uso en los que se requiere información precisa y oportuna.
¿RAG reduce las alucinaciones en los LLM?
Sí. Al fundamentar la respuesta del modelo en contenido recuperado y actualizado, RAG reduce la probabilidad de alucinaciones. Este es especialmente el caso en dominios que requieren una alta precisión, como la atención médica, el trabajo legal o el soporte empresarial.
¿Qué tipo de datos necesita RAG?
RAG utiliza datos de texto no estructurados (piense en fuentes como PDF, correos electrónicos y documentos internos) almacenados en un formato recuperable. Por lo general, estos se almacenan en una base de datos vectorial, y los datos deben indexarse y actualizarse periódicamente para mantener su relevancia.
¿Cómo se evalúa un sistema RAG?
Los sistemas RAG se evalúan mediante una combinación de puntuación de relevancia, comprobaciones de fundamentación (groundedness), evaluaciones humanas y métricas de rendimiento específicas de la tarea. Pero como hemos visto, las posibilidades de coentrenamiento de recuperador y generador pueden facilitar la evaluación periódica a medida que los modelos aprenden unos de otros y se entrenan mutuamente.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.