Seguridad y confianza
La seguridad de sus datos es nuestra máxima prioridad.

Enfoque de Databricks para la IA responsable
Databricks cree que el avance de la IA depende de generar confianza en las aplicaciones inteligentes mediante prácticas responsables en el desarrollo y uso de la IA. Esto requiere que cada organización tenga la propiedad y el control de sus datos y modelos de IA con un monitoreo integral, controles de privacidad y gobernanza durante todo el desarrollo y la implementación de la IA.
Databricks and the EU AI Act
Databricks is committed to responsible AI development and deployment consistent with applicable laws, including laws such as the European Union Artificial Intelligence Act (EU AI Act).
Databricks is an AI system provider and downstream model distributor for third-party general purpose AI models. We are responsible for our assessments of the AI systems we provide directly. We do not place general-purpose AI foundation models on the market as an upstream provider in the AI value chain. Where Databricks integrates third-party foundation models downstream into our services, or offer models downstream of model providers, those models remain subject to the obligations applicable to their respective model providers under the EU AI Act. The upstream model providers are responsible for compliance with applicable laws and regulations.
Databricks services are use-case agnostic and data agnostic. They are not placed on the market for specific high-risk use cases.
Customers are responsible for assessing whether their intended use of Databricks AI systems, or models through Databricks, constitute high-risk AI uses under the EU AI Act, and for complying with applicable obligations in connection with such uses.
Databricks supports customers’ compliance efforts through:
- Platform-level governance controls;
- Security and monitoring capabilities; and
- Documentation describing use and functionality.
Databricks continues to monitor EU AI Act implementation guidance and harmonised standards and will update its governance approach as appropriate.
Marco de pruebas de IA responsable de Databricks: Red Teaming de modelos de IA generativa
El *red teaming* de IA, especialmente para los modelos de lenguaje grandes, es un componente importante para desarrollar e implementar modelos de forma segura. Databricks emplea el *red teaming* de IA de forma regular en los modelos y sistemas desarrollados internamente. A continuación, se incluye una descripción general de nuestro marco de pruebas de IA responsable, que presenta las técnicas que usamos internamente en nuestro laboratorio de ML adversario para probar nuestros modelos, así como técnicas de *red teaming* adicionales que estamos evaluando para su uso futuro en nuestro laboratorio.
NOTA: Es fundamental reconocer que el campo del red teaming de IA aún se encuentra en sus primeras etapas, y el rápido ritmo de la innovación trae tanto oportunidades como desafíos. Nos comprometemos a la evaluación continua de nuevos enfoques para ataques y contraataques, y a incorporarlos en el proceso de prueba de nuestros modelos cuando corresponda.
A continuación, se muestra el diagrama de nuestro marco de pruebas de GenAI:
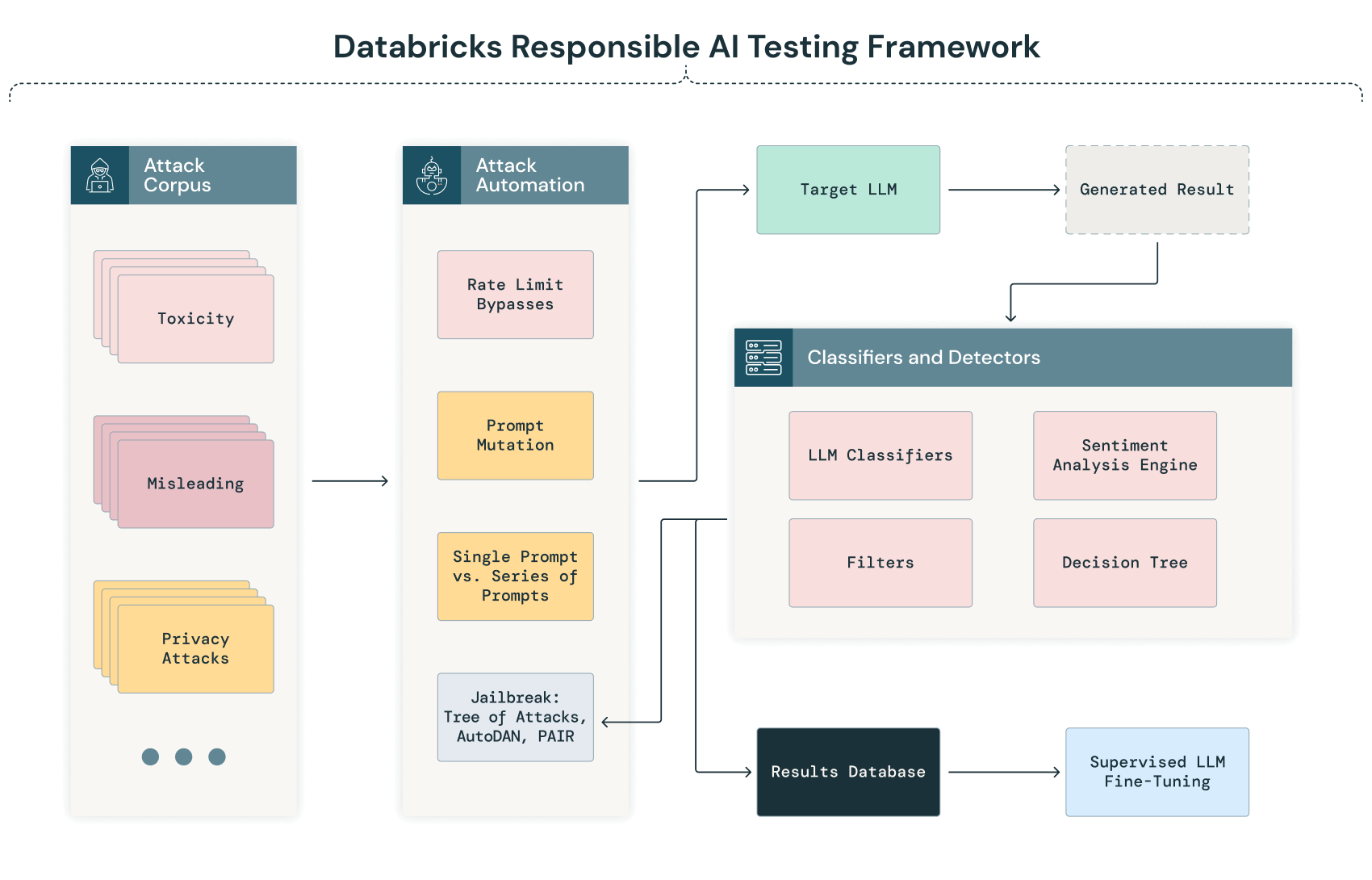
Sondeo y clasificación automatizados
La fase inicial de nuestro proceso de red teaming de IA implica un proceso automatizado en el que se envían sistemáticamente al modelo una serie de corpus de texto diversos. Este proceso tiene como objetivo sondear las respuestas del modelo en una amplia gama de escenarios para identificar posibles vulnerabilidades, sesgos o problemas de privacidad de forma automática antes de que se realice un análisis manual más profundo.
A medida que el LLM procesa estas entradas, sus resultados se capturan y clasifican automáticamente según criterios predefinidos. Esta clasificación podría implicar técnicas de procesamiento del lenguaje natural (NLP) y otros modelos de IA entrenados para detectar anomalías, sesgos o desviaciones del rendimiento esperado. Por ejemplo, un resultado podría marcarse para revisión manual si presenta un posible sesgo, respuestas sin sentido o indicios de filtración de datos.
Jailbreaking de LLM
Databricks emplea múltiples técnicas para el jailbreaking de LLM, entre ellas:
- Instrucciones directas (DI): instrucciones directas del atacante para solicitar contenido dañino.
- Prompts "Haz cualquier cosa ahora" (DAN): una variedad de ataques que animan al modelo a convertirse en un agente de chat "Haz cualquier cosa ahora" capaz de facilitar cualquier tarea sin tener en cuenta los límites éticos o de seguridad.
- Ataques de estilo Riley Goodside: una secuencia de ataques que le piden directamente al modelo que ignore sus instrucciones. Esto fue popularizado por Riley Goodside.
- Corpus Agency Enterprise PromptInject: Reproducción del corpus Agency Enterprise Prompt Injection, de los premios al mejor artículo en el NeurIPS ML Safety Workshop de 2022.
- Refinamiento automático e iterativo del prompt (PAIR): Se utiliza un modelo de lenguaje grande enfocado en ataques para refinar el prompt iterativamente, guiándolo hacia un jailbreak.
- Árbol de ataques con poda (TAP): Similar a un ataque PAIR, sin embargo, se utiliza un LLM adicional para identificar cuándo los prompts generados se desvían del tema y podarlos del árbol de ataque.
Las pruebas de jailbreak brindan una comprensión adicional de la capacidad del modelo para generalizar y responder a prompts que son significativamente diferentes de los datos de entrenamiento o que tienen una forma alternativa de acceder a la información protegida. Esto también nos permite identificar las maneras en que un ataque puede engañar a los LLM para que generen contenido dañino o no deseado.
Dado que este es un campo en constante evolución, seguiremos considerando y evaluando técnicas adicionales a medida que cambie el panorama del jailbreaking.
Validación y análisis manuales
Después de la fase automatizada, el proceso de red teaming de IA implica una revisión manual de los resultados marcados y, para aumentar la probabilidad de que se identifiquen todos los problemas críticos, una revisión aleatoria de los resultados no marcados. Este análisis manual permite una interpretación y validación matizadas de los problemas identificados a través del proceso automatizado.
El proceso de red teaming de IA implica una cantidad significativa de trabajo manual en el que los análisis automatizados pueden generar resultados que no muestran problemas, pero la evaluación manual por parte del Red Team puede intentar variantes en las que estos prompts se pueden ajustar o encadenar para encontrar debilidades que de otro modo no serían identificadas por los análisis automatizados.
Seguridad de la cadena de suministro del modelo
A medida que nuestros esfuerzos de red teaming de IA continúan evolucionando, también incluimos procesos para evaluar la seguridad de la cadena de suministro de modelos de IA, desde el entrenamiento hasta la implementación y la distribución. Las áreas que se evalúan actualmente incluyen:
- Comprometer los datos de entrenamiento (envenenamiento por manipulación de etiquetas o inyección de datos maliciosos)
- Comprometer la infraestructura de entrenamiento (GPU, VM, etc.)
- Obtener acceso a los LLM implementados para alterar los pesos y los hiperparámetros
- Manipulación de filtros y otras capas defensivas implementadas
- Poner en riesgo la distribución del modelo, por ejemplo, al vulnerar a terceros de confianza como Hugging Face.
Ciclo de retroalimentación continuo
Un área adicional para nuestros esfuerzos de red teaming de IA será un proceso para un bucle de mejora continua, que capturaría la información obtenida tanto de los análisis automatizados como de los manuales. Nuestro objetivo para el ciclo de mejora continua es impulsar la evolución de nuestros modelos para que sean más robustos y estén alineados con los más altos estándares de rendimiento.
Categorías de sondas de prueba utilizadas por el Red Team de Databricks
Databricks utiliza una serie de corpus seleccionados (sondeos) que se envían al modelo durante las pruebas. Las sondas son pruebas o experimentos específicos diseñados para desafiar al sistema de IA de varias maneras. Para cualquier sondeo que genere un resultado exitoso y sin infracciones, el Red Team evaluaría la respuesta del modelo para detectar comportamientos indebidos, probando otras variantes del mismo sondeo. En el contexto de los LLM, las sondas utilizadas por el Red Team de Databricks se pueden clasificar de la siguiente manera:
Sondeos de seguridad
- Manipulación de entradas: Probar la respuesta del modelo a entradas alteradas, con ruido o maliciosas para identificar vulnerabilidades en el procesamiento de datos.
- Técnicas de evasión: intento de eludir las salvaguardas o los filtros del modelo para inducir resultados dañinos o no deseados.
- Inversión del modelo: Intentos de extraer información sensible del modelo, lo que compromete la privacidad de los datos.
Pruebas de ética y sesgo
- Detección de sesgos: evaluación del modelo para detectar sesgos relacionados con la raza, el género, la edad, etc., mediante el análisis de sus respuestas a prompts específicos.
- Dilemas éticos: Presentar al modelo situaciones que pongan a prueba su alineación con las normas y los valores éticos.
Sondas de robustez y confiabilidad
- Ataques adversarios: Introducción de entradas ligeramente modificadas que están diseñadas para engañar al modelo y generar salidas incorrectas.
- Verificaciones de coherencia: prueba de la capacidad del modelo para proporcionar respuestas coherentes y confiables en consultas similares o repetidas.
Sondas de cumplimiento y seguridad
- Cumplimiento normativo: Prueba de los resultados y procesos del modelo frente a las normativas aplicables.
- Escenarios de seguridad: Evaluación del comportamiento del modelo en escenarios donde la seguridad es una preocupación crítica, para evitar daños o consejos peligrosos.
- Sondeos de privacidad: examinar el modelo en función de las normas y regulaciones de privacidad de datos, como el RGPD o la HIPAA. Estas sondas evalúan si el modelo revela indebidamente información personal o sensible en sus resultados o si podría ser manipulado para extraer dichos datos.
- Controlabilidad: Probar la facilidad con la que los operadores humanos pueden intervenir o controlar los resultados y comportamientos del modelo.


