Introduction des UDF Pandas pour PySpark
Comment exécuter votre code Python natif avec PySpark, rapidement.
par Li Jin
L’édition Gratuite remplace l’édition Communautaire, offrant des fonctionnalités améliorées sans frais. Commencez à utiliser l’édition Gratuite dès aujourd’hui.
NOTE : Spark 3.0 a introdui une nouvelle UDF pandas. Vous trouverez plus de détails dans l’article de blog suivant : Nouvelles UDF pandas et indications de type Python dans la prochaine version d’Apache Spark 3.0
Ceci est un article communautaire invité de Li Jin, ingénieur logiciel chez Two Sigma Investments, LP à New York. Cet article est également publié sur Two Sigma
Essayez ce notebook dans Databricks
MISE À JOUR : Cet article a été mis à jour le 22 février 2018 pour inclure certains changements.
Cet article présente les UDF pandas (aussi appelées UDF vectorisées) dans la prochaine version d’Apache Spark 2.3, qui améliore consiérablement les performances et la facilité d’utilisation des fonctions définies par l’utilisateur (UDF) en Python.
Au cours des dernières années, Python est devenu le langage par défaut pour les scientifiques des données. Des packages tels que pandas, numpy, statsmodel et scikit-learn ont été largement adoptés et sont devenus les outils courants. Dans le même temps, Apache Spark est devenu le standard de facto pour le traitement des big data. Pour permettre aux scientifiques des données de tirer parti de la valeur des big data, Spark a ajouté une API Python dans la version 0.7, avec la prise en charge des fonctions définies par l’utilisateur. Ces fonctions définies par l’utilisateur fonctionnent ligne par ligne, et souffrent donc d’une surcharge de sérialisation et d’invocation élevée. Par conséquent, de nombreux pipelines de données définissent des UDF en Java et Scala, puis les invoquent depuis Python.
Les UDF pandas basées sur Apache Arrow vous apportent le meilleur des deux mondes : la possibilité de définir des UDF performantes et à faible surcharge entièrement en Python.
Dans Spark 2.3, il y aura deux types d’UDF pandas : scalaire et groupé. Ensuite, nous illustrerons leur utilisation à l’aide de quatre exemples : Plus Un, Probabilité Cumulative, Soustraire la Moyenne, Régression Linéaire par Moindres Carrés Ordinaires.
UDF pandas scalaires
Les UDF pandas scalaires sont utilisées pour vectoriser les opérations scalaires. Pour définir une UDF pandas scalaire, utilisez simplement @pandas_udf pour annoter une fonction Python qui prend pandas.Series comme arguments et renvoie une autre pandas.Series de même taille. Ci-dessous, nous illustrons avec deux exemples : Plus Un et Probabilité Cumulative.
Plus Un
Calculer v + 1 est un exemple simple pour démontrer les différences entre les UDF ligne par ligne et les UDF pandas scalaires. Notez que les opérateurs de colonne intégrés peuvent être beaucoup plus rapides dans ce scénario.
Utilisation des UDF ligne par ligne :
Utilisation des UDF pandas :
Les exemples ci-dessus définissent une UDF ligne par ligne « plus_one » et une UDF pandas scalaire « pandas_plus_one » qui effectue le même calcul « plus un ». Les définitions d’UDF sont identiques, à l’exception des décorateurs de fonction : « udf » contre « pandas_udf ».
Dans la version ligne par ligne, la fonction définie par l’utilisateur prend un double « v » et renvoie le résultat de « v + 1 » sous forme de double. Dans la version pandas, la fonction définie par l’utilisateur prend une pandas.Series « v » et renvoie le résultat de « v + 1 » sous forme de pandas.Series. Comme « v + 1 » est vectorisé sur pandas.Series, la version pandas est beaucoup plus rapide que la version ligne par ligne.
Notez qu’il existe deux exigences importantes lors de l’utilisation des UDF pandas scalaires :
- Les séries d’entrée et de sortie doivent avoir la même taille.
- La manière dont une colonne est divisée en plusieurs
pandas.Seriesest interne à Spark, et par conséquent, le résultat de la fonction définie par l’utilisateur doit être indépendant du fractionnement.
Probabilité Cumulative
Cet exemple montre une utilisation plus pratique de l’UDF pandas scalaire : le calcul de la probabilité cumulative d’une valeur dans une distribution normale N(0,1) en utilisant le package scipy.
stats.norm.cdf fonctionne à la fois sur une valeur scalaire et sur une pandas.Series, et cet exemple peut également être écrit avec les UDF ligne par ligne. Comme dans l’exemple précédent, la version pandas s’exécute beaucoup plus rapidement, comme le montre la section « Comparaison des performances ».
UDF pandas groupées par mappage
Les utilisateurs de Python sont très familiers avec le schéma « split-apply-combine » en analyse de données. Les UDF pandas groupées par mappage sont conçues pour ce scénario, et elles opèrent sur toutes les données d’un groupe, par exemple, « pour chaque date, appliquer cette opération ».
Les UDF pandas groupées par mappage divisent d’abord un DataFrame Spark en groupes en fonction des conditions spécifiées dans l’opérateur groupby, appliquent une fonction définie par l’utilisateur (pandas.DataFrame -> pandas.DataFrame) à chaque groupe, combinent et renvoient les résultats sous forme d’un nouveau DataFrame Spark.
Les UDF pandas groupées par mappage utilisent le même décorateur de fonction pandas_udf que les UDF pandas scalaires, mais elles présentent quelques différences :
- Entrée de la fonction définie par l’utilisateur :
- Scalaire :
pandas.Series - Groupé par mappage :
pandas.DataFrame
- Scalaire :
- Sortie de la fonction définie par l’utilisateur :
- Scalaire :
pandas.Series - Groupé par mappage :
pandas.DataFrame
- Scalaire :
- Sémantique de regroupement :
- Scalaire : pas de sémantique de regroupement
- Groupé par mappage : définie par la clause « groupby »
- Taille de sortie :
- Scalaire : identique à la taille d’entrée
- Groupé par mappage : toute taille
- Types de retour dans le décorateur de fonction :
- Scalaire : un
DataTypequi spécifie le type de lapandas.Seriesretournée - Groupé par mappage : un
StructTypequi spécifie le nom et le type de chaque colonne dupandas.DataFrameretourné
- Scalaire : un
Ensuite, parcourons deux exemples pour illustrer les cas d’utilisation des UDF pandas groupées par mappage.
Soustraire la Moyenne
Cet exemple montre une utilisation simple des UDF pandas groupées par mappage : soustraire la moyenne de chaque valeur du groupe.
Dans cet exemple, nous soustrayons la moyenne de v de chaque valeur de v pour chaque groupe. La sémantique de regroupement est définie par la fonction « groupby », c’est-à-dire que chaque pandas.DataFrame d’entrée de la fonction définie par l’utilisateur a la même valeur « id ». Le schéma d’entrée et de sortie de cette fonction définie par l’utilisateur est le même, nous passons donc « df.schema » au décorateur pandas_udf pour spécifier le schéma.
Les UDF pandas groupées par mappage peuvent également être appelées en tant que fonctions Python autonomes sur le pilote. Ceci est très utile pour le débogage, par exemple :
Dans l’exemple ci-dessus, nous convertissons d’abord un petit sous-ensemble de DataFrame Spark en un pandas.DataFrame, puis nous exécutons subtract_mean en tant que fonction Python autonome sur celui-ci. Après avoir vérifié la logique de la fonction, nous pouvons appeler l’UDF avec Spark sur l’ensemble des données.
Régression Linéaire par Moindres Carrés Ordinaires
Le dernier exemple montre comment exécuter une régression linéaire OLS pour chaque groupe à l’aide de statsmodels. Pour chaque groupe, nous calculons le beta b = (b1, b2) pour X = (x1, x2) selon le modèle statistique Y = bX + c.
Cet exemple montre que les UDF Pandas groupées par mappage peuvent être utilisées avec n'importe quelle fonction Python arbitraire : pandas.DataFrame -> pandas.DataFrame. Le pandas.DataFrame retourné peut avoir un nombre de lignes et de colonnes différent de celui de l'entrée.
Comparaison des performances
Enfin, nous souhaitons présenter une comparaison des performances entre les UDF ligne par ligne et les UDF Pandas. Nous avons effectué des micro-benchmarks pour trois des exemples ci-dessus (plus un, probabilité cumulative et soustraction de la moyenne).
Configuration et méthodologie
Nous avons exécuté le benchmark sur un cluster Spark à nœud unique sur Databricks Community Edition.
Détails de la configuration :
Données : Un DataFrame de 10 millions de lignes avec une colonne Int et une colonne Double
Cluster : 6.0 Go de mémoire, 0.88 cœurs, 1 DBU
Databricks runtime version : Dernière RC (4.0, Scala 2.11)
Pour l'implémentation détaillée du benchmark, consultez le Notebook Pandas UDF.
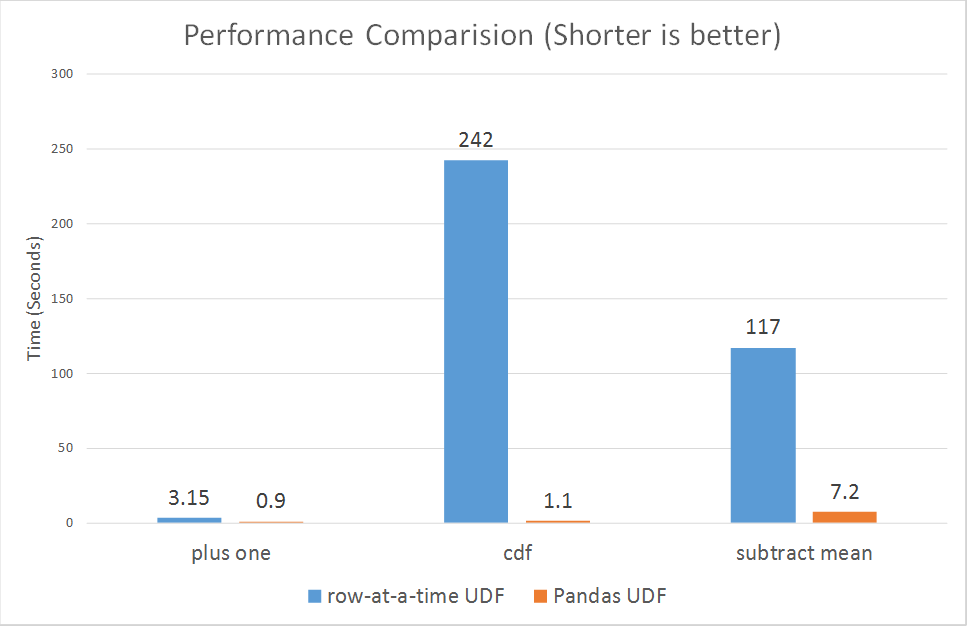
Comme le montrent les graphiques, les UDF Pandas sont beaucoup plus performantes que les UDF ligne par ligne, avec des gains allant de 3x à plus de 100x.
Conclusion et travaux futurs
La prochaine version de Spark 2.3 pose les bases pour améliorer considérablement les capacités et les performances des fonctions définies par l'utilisateur en Python. À l'avenir, nous prévoyons d'introduire la prise en charge des UDF Pandas dans les agrégations et les fonctions de fenêtre. Les travaux connexes peuvent être suivis dans SPARK-22216.
Les UDF Pandas sont un excellent exemple de l'effort communautaire de Spark. Nous tenons à remercier Bryan Cutler, Hyukjin Kwon, Jeff Reback, Liang-Chi Hsieh, Leif Walsh, Li Jin, Reynold Xin, Takuya Ueshin, Wenchen Fan, Wes McKinney, Xiao Li et bien d'autres pour leurs contributions. Enfin, un merci spécial à la communauté Apache Arrow pour avoir rendu ce travail possible.
Et ensuite ?
Vous pouvez essayer le notebook Pandas UDF et cette fonctionnalité est maintenant disponible dans le cadre de la bêta de Databricks Runtime 4.0.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.