Prévisions de séries temporelles à granularité fine à grande échelle avec Facebook Prophet et Apache Spark
par Bilal Obeidat, Bryan Smith et Brenner Heintz
Essayez ce notebook de prévision de séries chronologiques dans notre Solution Accelerator pour la prévision de la demande.
Les avancées en matière de prévision de séries chronologiques permettent aux détaillants de générer des prévisions de demande plus fiables. Le défi consiste maintenant à produire ces prévisions en temps voulu et à un niveau de granularité qui permette à l'entreprise d'apporter des ajustements précis aux stocks de produits. En tirant parti de Apache Spark™ et de Facebook Prophet, de plus en plus d'entreprises confrontées à ces défis constatent qu'elles peuvent surmonter les limites de scalabilité et de précision des solutions passées.
Dans cet article, nous discuterons de l'importance de la prévision de séries chronologiques, visualiserons des exemples de données de séries chronologiques, puis construirons un modèle simple pour montrer l'utilisation de Facebook Prophet. Une fois que vous serez à l'aise pour construire un modèle unique, nous combinerons Prophet avec la puissance d'Apache Spark™ pour vous montrer comment entraîner des centaines de modèles à la fois, nous permettant ainsi de créer des prévisions précises pour chaque combinaison produit-magasin individuelle à un niveau de granularité rarement atteint jusqu'à présent.
La prévision précise et rapide est plus importante que jamais
L'amélioration de la vitesse et de la précision des analyses de séries chronologiques afin de mieux prévoir la demande de produits et services est essentielle au succès des détaillants. Si trop de produits sont placés dans un magasin, l'espace en rayon et en réserve peut être limité, les produits peuvent expirer, et les détaillants peuvent voir leurs ressources financières immobilisées dans les stocks, les empêchant de profiter des nouvelles opportunités générées par les fabricants ou des changements dans les habitudes de consommation. Si trop peu de produits sont placés dans un magasin, les clients peuvent ne pas être en mesure d'acheter les produits dont ils ont besoin. Ces erreurs de prévision entraînent non seulement une perte immédiate de revenus pour le détaillant, mais avec le temps, la frustration des consommateurs peut pousser les clients vers les concurrents.
Les nouvelles attentes exigent des méthodes et des modèles de prévision de séries chronologiques plus précis
Pendant un certain temps, les systèmes de planification des ressources d'entreprise (ERP) et les solutions tierces ont fourni aux détaillants des capacités de prévision de la demande basées sur des modèles de séries chronologiques simples. Mais avec les avancées technologiques et la pression accrue dans le secteur, de nombreux détaillants cherchent à dépasser les modèles linéaires et les algorithmes plus traditionnels qui leur étaient historiquement accessibles.
De nouvelles capacités, telles que celles fournies par Facebook Prophet, émergent de la communauté de la science des données, et les entreprises recherchent la flexibilité d'appliquer ces modèles d'apprentissage automatique à leurs besoins de prévision de séries chronologiques.
![]()
Ce mouvement loin des solutions de prévision traditionnelles oblige les détaillants et autres à développer une expertise interne non seulement dans les complexités de la prévision de la demande, mais aussi dans la distribution efficace du travail nécessaire pour générer des centaines de milliers, voire des millions, de modèles d'apprentissage automatique en temps voulu. Heureusement, nous pouvons utiliser Spark pour distribuer l'entraînement de ces modèles, ce qui permet de prédire non seulement la demande globale de produits et services, mais aussi la demande unique pour chaque produit dans chaque emplacement.
Visualisation de la saisonnalité de la demande dans les données de séries chronologiques
Pour démontrer l'utilisation de Prophet afin de générer des prévisions de demande granulaires pour des magasins et des produits individuels, nous utiliserons un ensemble de données publiquement disponible sur Kaggle. Il se compose de 5 ans de données de ventes quotidiennes pour 50 articles individuels dans 10 magasins différents.
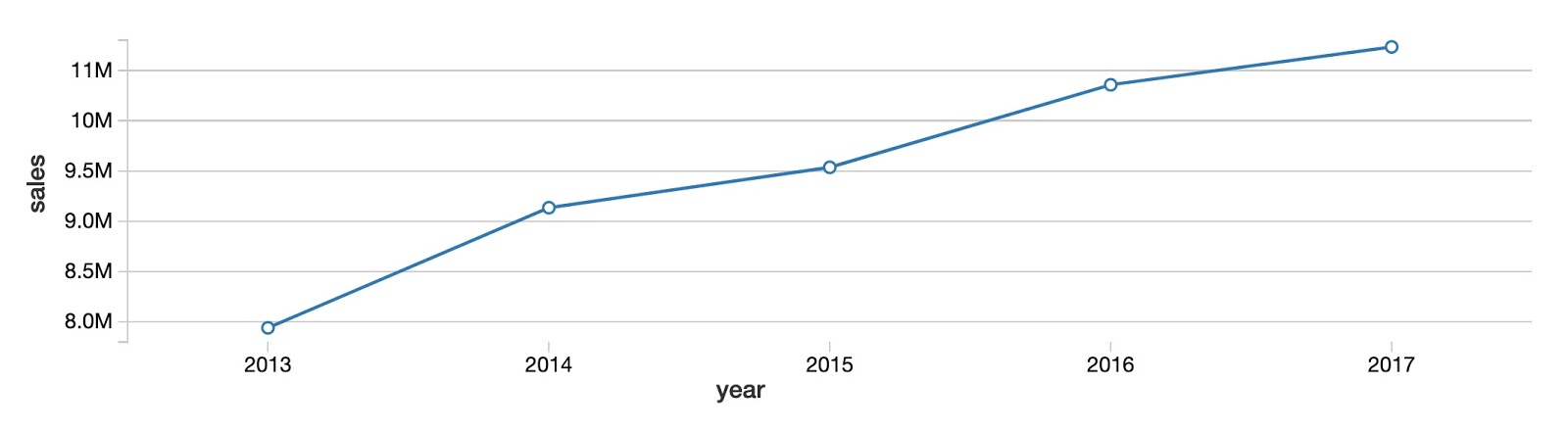
Pour commencer, examinons la tendance générale des ventes annuelles pour tous les produits et tous les magasins. Comme vous pouvez le voir, les ventes totales de produits augmentent d'année en année sans signe clair de convergence vers un plateau.
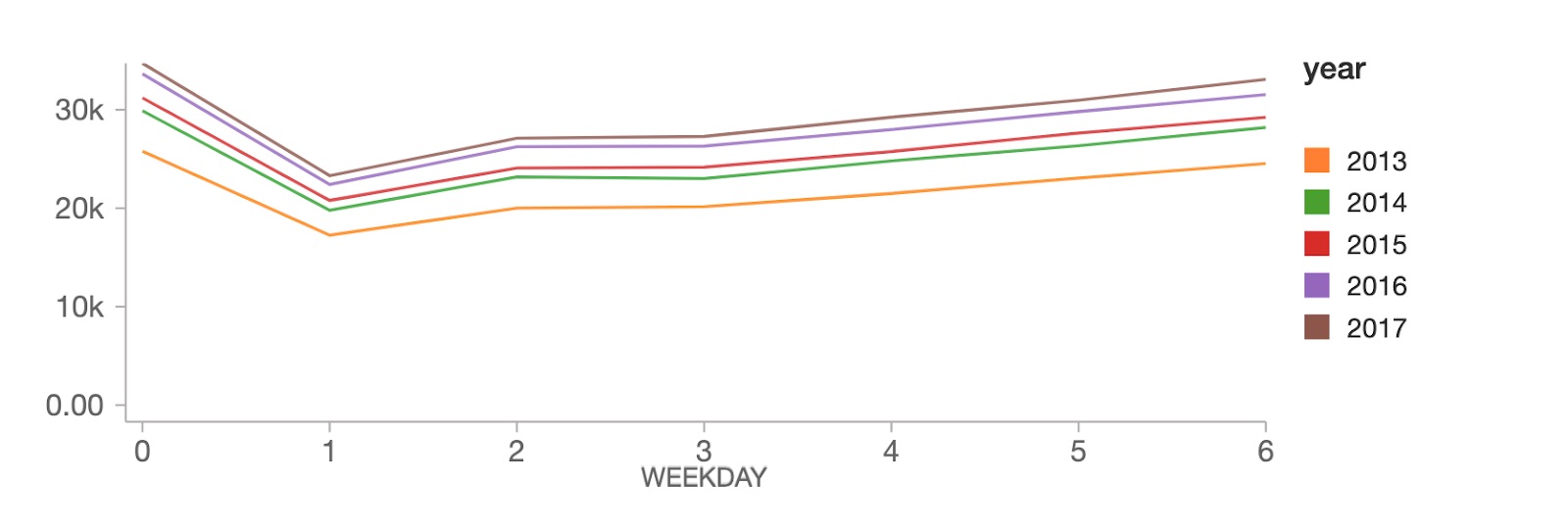
Au niveau hebdomadaire, les ventes atteignent un pic le dimanche (jour de la semaine 0), suivies d'une forte baisse le lundi (jour de la semaine 1), puis augmentent régulièrement tout au long du reste de la semaine.
Démarrage avec un modèle simple de prévision de séries chronologiques sur Facebook Prophet
Comme illustré dans les graphiques ci-dessus, nos données montrent une tendance claire à la hausse des ventes d'une année sur l'autre, ainsi que des modèles saisonniers annuels et hebdomadaires. Ce sont ces modèles qui se chevauchent dans les données que Prophet est conçu pour traiter.
Facebook Prophet suit l'API scikit-learn, il devrait donc être facile à prendre en main pour toute personne ayant de l'expérience avec sklearn. Nous devons fournir un pandas DataFrame à 2 colonnes en entrée : la première colonne est la date et la seconde est la valeur à prédire (dans notre cas, les ventes). Une fois nos données dans le bon format, la construction d'un modèle est facile :
Maintenant que nous avons ajusté notre modèle aux données, utilisons-le pour construire une prévision sur 90 jours. Dans le code ci-dessous, nous définissons un ensemble de données qui comprend à la fois les dates historiques et 90 jours supplémentaires, en utilisant la méthode make_future_dataframe de Prophet :
Et voilà ! Nous pouvons maintenant visualiser comment nos données réelles et prédites s'alignent, ainsi qu'une prévision pour l'avenir en utilisant la méthode .plot intégrée de Prophet. Comme vous pouvez le constater, les modèles de demande hebdomadaires et saisonniers que nous avons illustrés précédemment se reflètent en fait dans les résultats prévisionnels.
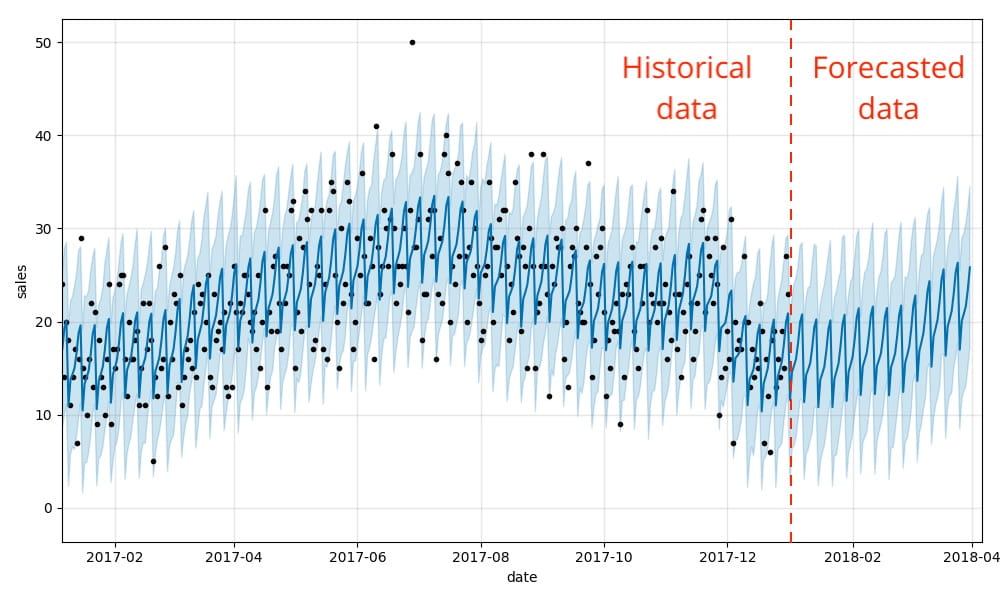
Cette visualisation est un peu chargée. Bartosz Mikulski propose une excellente explication qui vaut la peine d'être consultée. En bref, les points noirs représentent nos données réelles, la ligne bleu foncé représente nos prédictions et la bande bleu clair représente notre intervalle d'incertitude (95%).
Entraînement de centaines de modèles de prévision de séries chronologiques en parallèle avec Prophet et Spark
Maintenant que nous avons démontré comment construire un modèle unique de prévision de séries chronologiques, nous pouvons utiliser la puissance d'Apache Spark pour multiplier nos efforts. Notre objectif est de générer non pas une prévision pour l'ensemble des données, mais des centaines de modèles et de prévisions pour chaque combinaison produit-magasin, ce qui serait incroyablement long à réaliser en tant qu'opération séquentielle.
La construction de modèles de cette manière pourrait permettre à une chaîne de supermarchés, par exemple, de créer une prévision précise de la quantité de lait qu'elle devrait commander pour son magasin de Sandusky, différente de la quantité nécessaire dans son magasin de Cleveland, en fonction de la demande différente dans ces emplacements.
Comment utiliser les DataFrames Spark pour distribuer le traitement des données de séries chronologiques
Les scientifiques des données relèvent fréquemment le défi de former un grand nombre de modèles à l'aide d'un moteur de traitement de données distribué tel qu'Apache Spark. En tirant parti d'un cluster Spark, les nœuds de travail individuels du cluster peuvent former un sous-ensemble de modèles en parallèle avec d'autres nœuds de travail, ce qui réduit considérablement le temps total nécessaire pour former l'ensemble de la collection de modèles de séries chronologiques.
Bien entendu, la formation de modèles sur un cluster de nœuds de travail (ordinateurs) nécessite davantage d'infrastructure cloud, et cela a un coût. Mais avec la disponibilité facile des ressources cloud à la demande, les entreprises peuvent rapidement provisionner les ressources dont elles ont besoin, former leurs modèles et libérer ces ressources tout aussi rapidement, ce qui leur permet d'atteindre une évolutivité massive sans engagements à long terme envers des actifs physiques.
Le mécanisme clé pour obtenir le traitement distribué des données dans Spark est le DataFrame. En chargeant les données dans un DataFrame Spark, les données sont distribuées sur les workers du cluster. Cela permet à ces workers de traiter des sous-ensembles de données en parallèle, réduisant ainsi le temps total nécessaire pour effectuer notre travail.
Bien sûr, chaque worker doit avoir accès au sous-ensemble de données dont il a besoin pour faire son travail. En regroupant les données sur des valeurs clés, dans ce cas sur des combinaisons de magasin et d'article, nous rassemblons toutes les données de séries chronologiques pour ces valeurs clés sur un nœud de travail spécifique.
Nous partageons le code groupBy ici pour souligner comment il nous permet de former de nombreux modèles en parallèle efficacement, bien qu'il n'entre en jeu que lorsque nous configurons et appliquons une UDF à nos données dans la section suivante.
Tirer parti de la puissance des fonctions définies par l'utilisateur pandas (UDF)
Avec nos données de séries chronologiques correctement regroupées par magasin et par article, nous devons maintenant former un modèle unique pour chaque groupe. Pour ce faire, nous pouvons utiliser une fonction définie par l'utilisateur pandas (UDF), qui nous permet d'appliquer une fonction personnalisée à chaque groupe de données de notre DataFrame.
Cette UDF formera non seulement un modèle pour chaque groupe, mais générera également un ensemble de résultats représentant les prédictions de ce modèle. Mais alors que la fonction formera et prédira sur chaque groupe du DataFrame indépendamment des autres, les résultats renvoyés par chaque groupe seront commodément collectés dans un seul DataFrame résultant. Cela nous permettra de générer des prévisions au niveau magasin-article mais de présenter nos résultats aux analystes et aux gestionnaires sous la forme d'un seul jeu de données de sortie.
Comme vous pouvez le voir dans le code Python abrégé ci-dessous, la création de notre UDF est relativement simple. L'UDF est instanciée avec la méthode pandas_udf qui identifie le schéma des données qu'elle retournera et le type de données qu'elle s'attend à recevoir. Immédiatement après, nous définissons la fonction qui effectuera le travail de l'UDF.
Dans la définition de la fonction, nous instancions notre modèle, le configurons et l'ajustons aux données qu'il a reçues. Le modèle fait une prédiction, et ces données sont renvoyées comme sortie de la fonction.
Maintenant, pour tout rassembler, nous utilisons la commande groupBy que nous avons discutée précédemment pour nous assurer que notre jeu de données est correctement partitionné en groupes représentant des combinaisons spécifiques de magasin et d'article. Nous appliquons ensuite simplement l'UDF à notre DataFrame, permettant à l'UDF d'ajuster un modèle et de faire des prédictions sur chaque regroupement de données.
Le jeu de données renvoyé par l'application de la fonction à chaque groupe est mis à jour pour refléter la date à laquelle nous avons généré nos prédictions. Cela nous aidera à suivre les données générées lors des différentes exécutions de modèles lorsque nous mettrons finalement notre fonctionnalité en production.
Prochaines étapes
Nous avons maintenant construit un modèle de prévision de séries chronologiques pour chaque combinaison magasin-article. À l'aide d'une requête SQL, les analystes peuvent visualiser les prévisions personnalisées pour chaque produit. Dans le graphique ci-dessous, nous avons tracé la demande projetée pour le produit n° 1 sur 10 magasins. Comme vous pouvez le voir, les prévisions de demande varient d'un magasin à l'autre, mais le schéma général est cohérent dans tous les magasins, comme on pourrait s'y attendre.
À mesure que de nouvelles données de ventes arrivent, nous pouvons générer efficacement de nouvelles prévisions et les ajouter à nos structures de table existantes, permettant aux analystes de mettre à jour les attentes de l'entreprise à mesure que les conditions évoluent.
Pour en savoir plus, regardez le webinaire à la demande intitulé Comment Starbucks prévoit la demande à grande échelle avec Facebook Prophet et Azure Databricks et consultez notre Solution Accelerator pour la prévision de la demande.

(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.