Exécution adaptative des requêtes : Accélérer Spark SQL à l'exécution
par Wenchen Fan, Herman van Hövell et MaryAnn Xue
Lisez Rise of the Data Lakehouse pour découvrir pourquoi les lakehouses sont l'architecture de données de l'avenir avec le père du data warehouse, Bill Inmon.
Il s'agit d'un effort d'ingénierie conjoint entre l'équipe d'ingénierie Databricks Apache Spark — Wenchen Fan, Herman van Hovell et MaryAnn Xue — et l'équipe d'ingénierie Intel —Ke Jia, Haifeng Chen et Carson Wang.
Consultez le notebook AQE pour tester la solution décrite ci-dessous ou plongez dans le fonctionnement interne de la Databricks Lakehouse Platform
Au fil des ans, des efforts considérables et continus ont été déployés pour améliorer l'optimiseur de requêtes et le planificateur de Spark SQL afin de générer des plans d'exécution de requêtes de haute qualité. L'une des améliorations les plus importantes est le framework d'optimisation basé sur les coûts qui collecte et exploite diverses statistiques de données (par exemple, le nombre de lignes, le nombre de valeurs distinctes, les valeurs NULL, les valeurs max/min, etc.) pour aider Spark à choisir de meilleurs plans. Des exemples de ces techniques d'optimisation basées sur les coûts incluent le choix du bon type de jointure (jointure de hachage par diffusion vs jointure par fusion de tri), la sélection du bon côté de construction dans une jointure de hachage, ou l'ajustement de l'ordre des jointures dans une jointure multi-voies. Cependant, des statistiques obsolètes et des estimations de cardinalité imparfaites peuvent conduire à des plans de requêtes sous-optimaux. L'exécution adaptative des requêtes, nouvelle dans la prochaine version d'Apache SparkTM 3.0 et disponible dans Databricks Runtime 7.0, vise désormais à résoudre ces problèmes en réoptimisant et en ajustant les plans de requêtes en fonction des statistiques d'exécution collectées pendant l'exécution de la requête.
Le framework d'exécution adaptative des requêtes (AQE)
L'une des questions les plus importantes pour l'exécution adaptative des requêtes est de savoir quand réoptimiser. Les opérateurs Spark sont souvent pipelinés et exécutés dans des processus parallèles. Cependant, un shuffle ou une diffusion interrompt ce pipeline. Nous appelons ces points des points de matérialisation et utilisons le terme "étapes de requête" pour désigner les sous-sections délimitées par ces points de matérialisation dans une requête. Chaque étape de requête matérialise son résultat intermédiaire et l'étape suivante ne peut progresser que si tous les processus parallèles exécutant la matérialisation sont terminés. Cela offre une opportunité naturelle de réoptimisation, car c'est à ce moment que les statistiques de données sur toutes les partitions sont disponibles et que les opérations successives n'ont pas encore commencé.
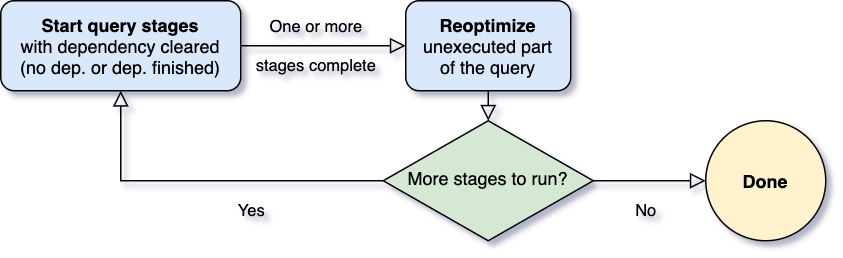
Lorsque la requête démarre, le framework d'exécution adaptative des requêtes lance d'abord toutes les étapes feuilles — les étapes qui ne dépendent d'aucune autre étape. Dès qu'une ou plusieurs de ces étapes terminent leur matérialisation, le framework les marque comme terminées dans le plan de requête physique et met à jour le plan de requête logique en conséquence, avec les statistiques d'exécution récupérées des étapes terminées. Sur la base de ces nouvelles statistiques, le framework exécute ensuite l'optimiseur (avec une liste sélectionnée de règles d'optimisation logique), le planificateur physique, ainsi que les règles d'optimisation physique, qui incluent les règles physiques régulières et les règles spécifiques à l'exécution adaptative, telles que la coalescence des partitions, la gestion des jointures déséquilibrées, etc. Maintenant que nous avons un plan de requête nouvellement optimisé avec quelques étapes terminées, le framework d'exécution adaptative recherchera et exécutera de nouvelles étapes de requête dont les étapes enfants ont toutes été matérialisées, et répétera le processus d'exécution-réoptimisation-exécution ci-dessus jusqu'à ce que la requête entière soit terminée.
Dans Spark 3.0, le framework AQE est livré avec trois fonctionnalités :
- Fusion dynamique des partitions de shuffle
- Changement dynamique des stratégies de jointure
- Optimisation dynamique des jointures déséquilibrées
Les sections suivantes détailleront ces trois fonctionnalités.
Fusion dynamique des partitions de shuffle
Lors de l'exécution de requêtes dans Spark pour traiter de très grandes quantités de données, le shuffle a généralement un impact très important sur les performances des requêtes, entre autres choses. Le shuffle est un opérateur coûteux car il doit déplacer des données sur le réseau, de sorte que les données sont redistribuées d'une manière requise par les opérateurs en aval.
Une propriété clé du shuffle est le nombre de partitions. Le nombre optimal de partitions dépend des données, mais les tailles de données peuvent varier considérablement d'une étape à l'autre, d'une requête à l'autre, ce qui rend ce nombre difficile à régler :
- S'il y a trop peu de partitions, la taille des données de chaque partition peut être très grande, et les tâches de traitement de ces grandes partitions peuvent devoir déborder sur le disque (par exemple, lorsqu'un tri ou une agrégation est impliqué) et, par conséquent, ralentir la requête.
- S'il y a trop de partitions, la taille des données de chaque partition peut être très petite, et il y aura beaucoup de petites récupérations de données réseau pour lire les blocs de shuffle, ce qui peut également ralentir la requête en raison du modèle d'E/S inefficace. Avoir un grand nombre de tâches impose également une charge supplémentaire au planificateur de tâches Spark.
Pour résoudre ce problème, nous pouvons définir un nombre relativement important de partitions de shuffle au début, puis combiner les partitions adjacentes petites en partitions plus grandes à l'exécution en examinant les statistiques des fichiers de shuffle.
Par exemple, disons que nous exécutons la requête SELECT max(i)FROM tbl GROUP BY j. Les données d'entrée tbl sont plutôt petites, il n'y a donc que deux partitions avant le regroupement. Le nombre initial de partitions de shuffle est défini sur cinq, donc après le regroupement local, les données partiellement regroupées sont mélangées dans cinq partitions. Sans AQE, Spark démarrera cinq tâches pour effectuer l'agrégation finale. Cependant, il y a trois partitions très petites ici, et ce serait un gaspillage de démarrer une tâche distincte pour chacune d'elles.
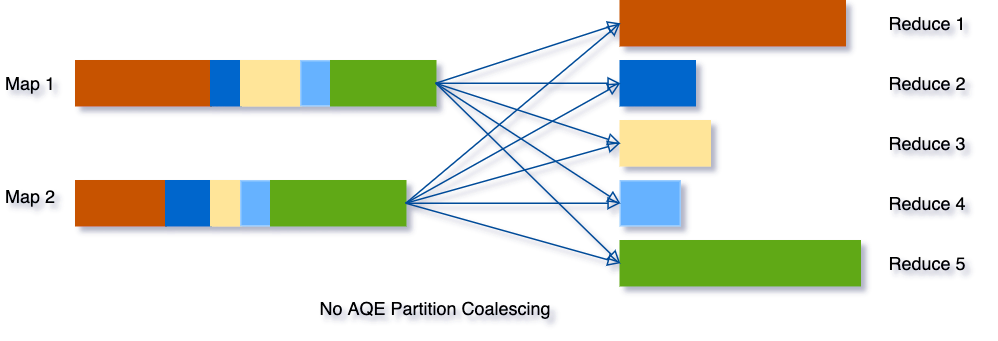
Au lieu de cela, AQE fusionne ces trois petites partitions en une seule et, par conséquent, l'agrégation finale ne nécessite plus que trois tâches au lieu de cinq.

Changement dynamique des stratégies de jointure
Spark prend en charge un certain nombre de stratégies de jointure, parmi lesquelles la jointure de hachage par diffusion est généralement la plus performante si un côté de la jointure peut tenir en mémoire. Et pour cette raison, Spark planifie une jointure de hachage par diffusion si la taille estimée d'une relation de jointure est inférieure au seuil de diffusion. Mais un certain nombre de choses peuvent rendre cette estimation de taille erronée — comme la présence d'un filtre très sélectif — ou la relation de jointure étant une série d'opérateurs complexes autres qu'un simple scan.
Pour résoudre ce problème, AQE re-planifie désormais la stratégie de jointure à l'exécution en fonction de la taille la plus précise de la relation de jointure. Comme on peut le voir dans l'exemple suivant, le côté droit de la jointure s'avère beaucoup plus petit que l'estimation et également suffisamment petit pour être diffusé, donc après la réoptimisation AQE, la jointure par fusion de tri planifiée statiquement est maintenant convertie en une jointure de hachage par diffusion.
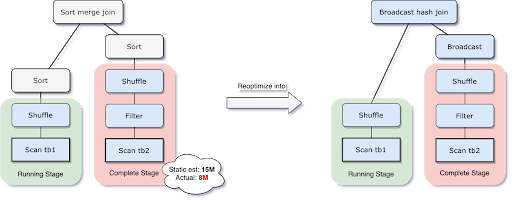
Pour la jointure de hachage par diffusion convertie à l'exécution, nous pouvons optimiser davantage le shuffle régulier en un shuffle localisé (c'est-à-dire, un shuffle qui lit par mapper plutôt que par réducteur) pour réduire le trafic réseau.
Optimisation dynamique des jointures déséquilibrées
Le déséquilibre des données se produit lorsque les données sont réparties de manière inégale entre les partitions du cluster. Un déséquilibre sévère peut dégrader considérablement les performances des requêtes, en particulier avec les jointures. L'optimisation des jointures déséquilibrées d'AQE détecte automatiquement ce déséquilibre à partir des statistiques des fichiers de shuffle. Elle divise ensuite les partitions déséquilibrées en sous-partitions plus petites, qui seront jointes respectivement à la partition correspondante de l'autre côté.
Prenons cet exemple de table A joignant la table B, dans laquelle la table A a une partition A0 significativement plus grande que ses autres partitions.
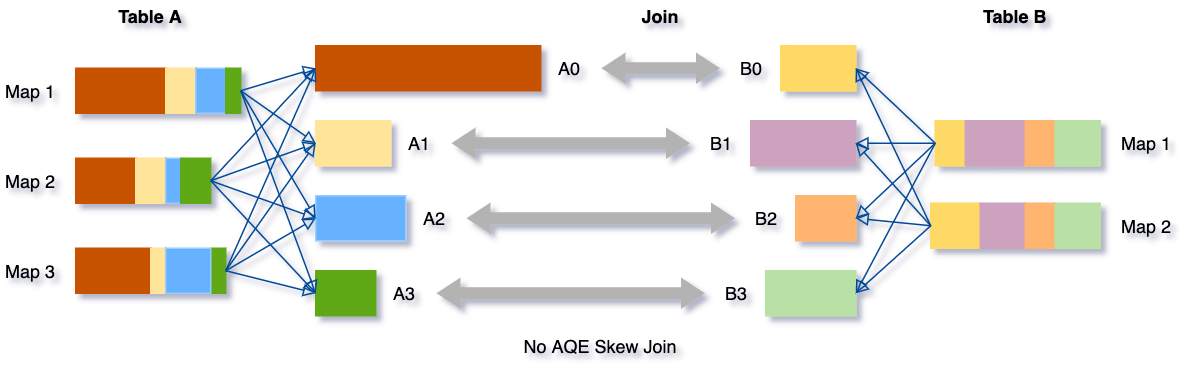
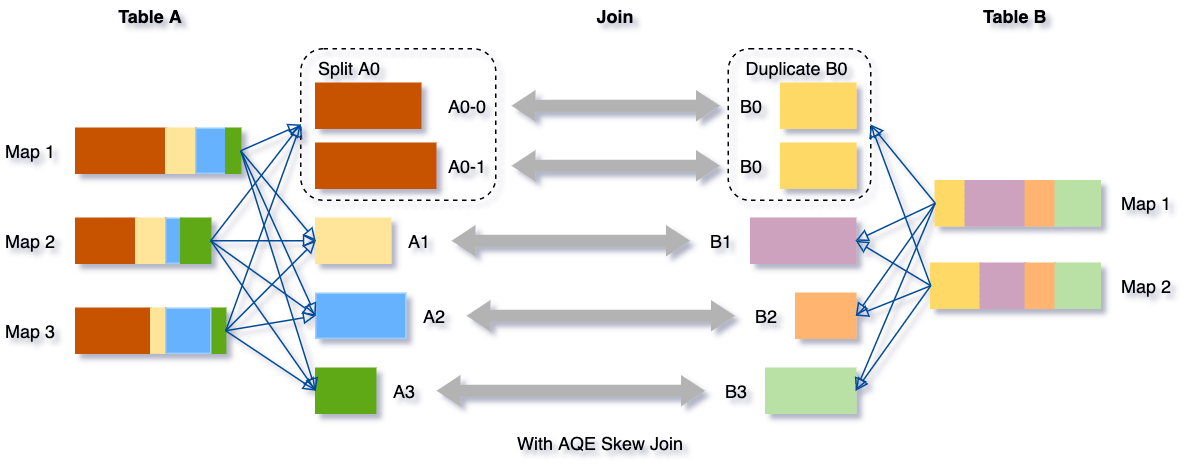
Sans cette optimisation, quatre tâches exécuteraient la jointure par tri fusion avec une tâche prenant beaucoup plus de temps. Après cette optimisation, cinq tâches exécuteront la jointure, mais chaque tâche prendra à peu près le même temps, ce qui se traduira par de meilleures performances globales.
Gains de performance TPC-DS grâce à AQE
Lors de nos expériences utilisant les données et les requêtes TPC-DS, l'exécution adaptative des requêtes a permis d'accélérer les performances des requêtes jusqu'à 8 fois et 32 requêtes ont bénéficié d'une accélération de plus de 1,1 fois. Vous trouverez ci-dessous un graphique des 10 requêtes TPC-DS ayant le plus d'amélioration de performance grâce à AQE.
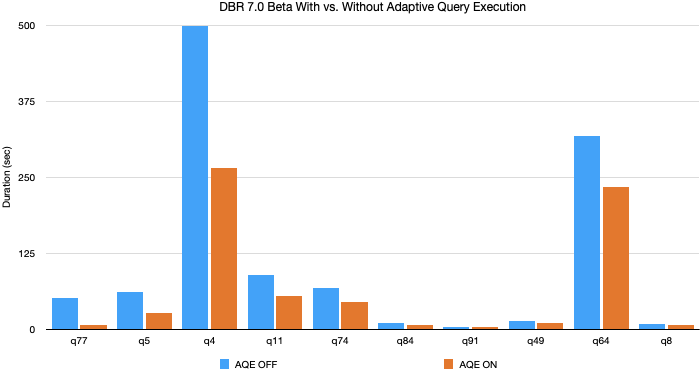
La plupart de ces améliorations proviennent de la coalescence dynamique des partitions et de la commutation dynamique de stratégie de jointure, car les données TPC-DS générées aléatoirement ne présentent pas de déséquilibre. Pourtant, nous avons constaté des améliorations encore plus importantes dans les charges de travail de production où les trois fonctionnalités d'AQE sont utilisées.
Activation d'AQE
AQE peut être activé en définissant la configuration SQL spark.sql.adaptive.enabled sur true (par défaut false dans Spark 3.0), et s'applique si la requête remplit les critères suivants :
- Ce n'est pas une requête de streaming
- Elle contient au moins un échange (généralement lorsqu'il y a une opération de jointure, d'agrégation ou de fenêtre) ou une sous-requête
En rendant l'optimisation des requêtes moins dépendante des statistiques statiques, AQE a résolu l'une des plus grandes difficultés de l'optimisation basée sur le coût de Spark : l'équilibre entre le coût de collecte des statistiques et la précision de l'estimation. Pour obtenir la meilleure précision d'estimation et le meilleur résultat de planification, il est généralement nécessaire de maintenir des statistiques détaillées et à jour, dont certaines sont coûteuses à collecter, comme les histogrammes de colonnes, qui peuvent être utilisés pour améliorer l'estimation de la sélectivité et de la cardinalité ou pour détecter le déséquilibre des données. AQE a largement éliminé le besoin de telles statistiques ainsi que l'effort de réglage manuel. De plus, AQE a rendu l'optimisation des requêtes SQL plus résiliente à la présence de fonctions définies par l'utilisateur (UDF) arbitraires et aux changements imprévisibles des jeux de données, par exemple, une augmentation ou une diminution soudaine de la taille des données, un déséquilibre de données fréquent et aléatoire, etc. Il n'est plus nécessaire de « connaître » vos données à l'avance. AQE identifiera les données et améliorera le plan de requête pendant l'exécution de la requête, augmentant les performances des requêtes pour une analyse plus rapide et les performances du système.
Apprenez-en davantage sur Spark 3.0 dans notre webinaire de présentation. Essayez AQE dans Spark 3.0 dès aujourd'hui gratuitement sur Databricks dans le cadre de notre Databricks Runtime 7.0.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.