Un regard complet sur les dates et les horodatages dans Apache Spark™ 3.0
par Maxim Gekk, Wenchen Fan et Hyukjin Kwon
Apache Spark est un outil très populaire pour le traitement des données structurées et non structurées. Lorsqu'il s'agit de traiter des données structurées, il prend en charge de nombreux types de données de base, tels que integer, long, double, string, etc. Spark prend également en charge des types de données plus complexes, tels que Date et Timestamp, qui sont souvent difficiles à comprendre pour les développeurs. Dans cet article de blog, nous allons explorer en profondeur les types Date et Timestamp pour vous aider à comprendre pleinement leur comportement et comment éviter certains problèmes courants. En résumé, ce blog couvre quatre parties :
- La définition du type Date et du calendrier associé. Il couvre également le changement de calendrier dans Spark 3.0.
- La définition du type Timestamp et sa relation avec les fuseaux horaires. Il explique également le détail de la résolution du décalage horaire, et les subtils changements de comportement dans la nouvelle API de temps de Java 8, utilisée par Spark 3.0.
- Les API courantes pour construire des valeurs de date et d'horodatage dans Spark.
- Les pièges courants et les meilleures pratiques pour collecter des objets date et horodatage sur le driver Spark.
Date et calendrier
La définition d'une Date est très simple : c'est une combinaison des champs année, mois et jour, comme (année=2012, mois=12, jour=31). Cependant, les valeurs de l'année, du mois et du jour ont des contraintes, de sorte que la valeur de la date soit un jour valide dans le monde réel. Par exemple, la valeur du mois doit être comprise entre 1 et 12, la valeur du jour doit être comprise entre 1 et 28/29/30/31 (selon l'année et le mois), et ainsi de suite.
Ces contraintes sont définies par l'un des nombreux calendriers possibles. Certains ne sont utilisés que dans des régions spécifiques, comme le calendrier lunaire. Certains ne sont utilisés que dans l'histoire, comme le calendrier julien. À ce stade, le calendrier grégorien est la norme internationale de facto et est utilisé presque partout dans le monde à des fins civiles. Il a été introduit en 1582 et est également étendu pour prendre en charge les dates antérieures à 1582. Ce calendrier étendu est appelé le calendrier grégorien proleptique.
À partir de la version 3.0, Spark utilise le calendrier grégorien proleptique, qui est déjà utilisé par d'autres systèmes de données comme pandas, R et Apache Arrow. Avant Spark 3.0, il utilisait une combinaison des calendriers julien et grégorien : pour les dates antérieures à 1582, le calendrier julien était utilisé, pour les dates postérieures à 1582, le calendrier grégorien était utilisé. Ceci est hérité de l'ancienne API java.sql.Date, qui a été remplacée en Java 8 par java.time.LocalDate, qui utilise également le calendrier grégorien proleptique.
Notamment, le type Date ne prend pas en compte les fuseaux horaires.
Timestamp et fuseau horaire
Le type Timestamp étend le type Date avec de nouveaux champs : heure, minute, seconde (qui peut avoir une partie fractionnaire) et, avec un fuseau horaire global (défini par la session). Il définit un instant concret sur Terre. Par exemple, (année=2012, mois=12, jour=31, heure=23, minute=59, seconde=59.123456) avec le fuseau horaire de session UTC+01:00. Lors de l'écriture des valeurs d'horodatage dans des sources de données non textuelles comme Parquet, les valeurs sont simplement des instants (comme un horodatage en UTC) qui n'ont pas d'informations de fuseau horaire. Si vous écrivez et lisez une valeur d'horodatage avec un fuseau horaire de session différent, vous pouvez voir des valeurs différentes pour les champs heure/minute/seconde, mais il s'agit en réalité du même instant concret.
Les champs heure, minute et seconde ont des plages standard : 0-23 pour les heures et 0-59 pour les minutes et les secondes. Spark prend en charge les fractions de seconde avec une précision allant jusqu'à la microseconde. La plage valide pour les fractions est de 0 à 999 999 microsecondes.
À tout instant concret, nous pouvons observer de nombreuses valeurs différentes d'horloges murales, en fonction du fuseau horaire.
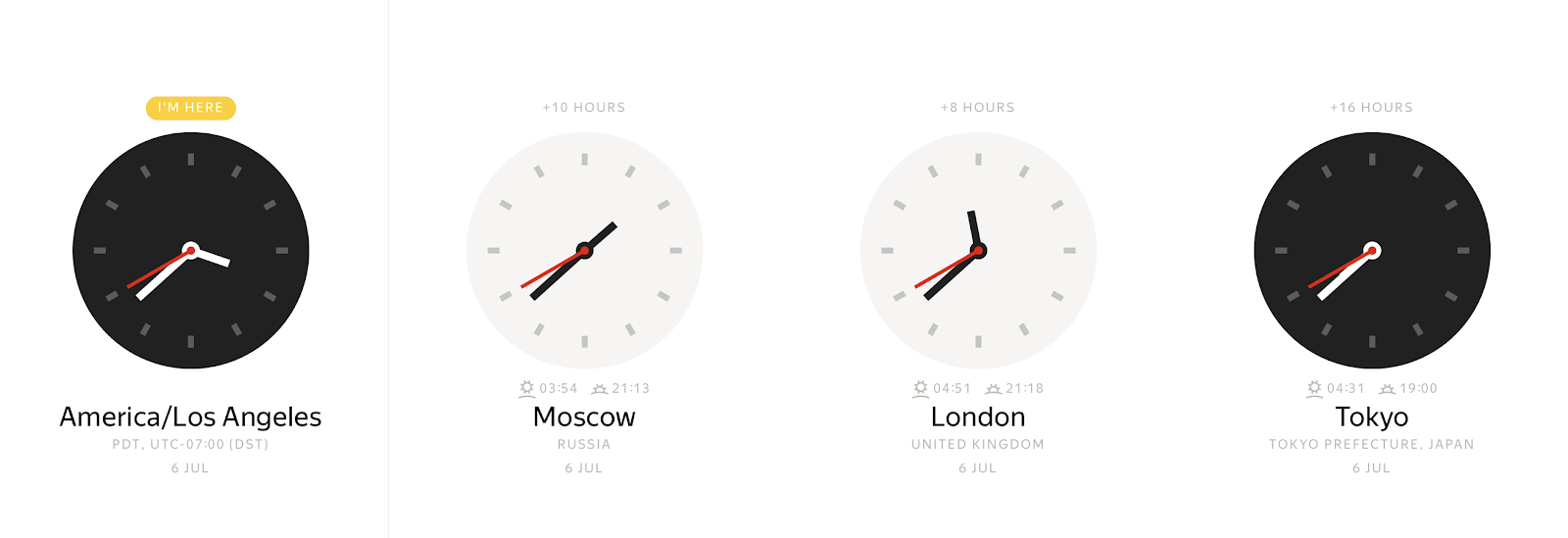
Et inversement, toute valeur sur les horloges murales peut représenter de nombreux instants différents. Le décalage horaire nous permet de lier sans ambiguïté un horodatage local à un instant. Généralement, les décalages horaires sont définis comme des décalages en heures par rapport au Greenwich Mean Time (GMT) ou UTC+0 (Temps Universel Coordonné). Une telle représentation des informations de fuseau horaire élimine l'ambiguïté, mais elle est peu pratique pour les utilisateurs finaux. Les utilisateurs préfèrent indiquer un emplacement autour du globe tel que America/Los_Angeles ou Europe/Paris.
Ce niveau d'abstraction supplémentaire par rapport aux décalages de fuseaux horaires facilite la vie mais pose ses propres problèmes. Par exemple, nous devons maintenant maintenir une base de données spéciale des fuseaux horaires pour mapper les noms de fuseaux horaires aux décalages. Comme Spark s'exécute sur la JVM, il délègue le mappage à la bibliothèque standard Java, qui charge les données de la base de données des fuseaux horaires de l'Internet Assigned Numbers Authority (IANA TZDB). De plus, le mécanisme de mappage de la bibliothèque standard Java présente certaines nuances qui influencent le comportement de Spark. Nous nous concentrons sur certaines de ces nuances ci-dessous.
Depuis Java 8, le JDK a exposé une nouvelle API pour la manipulation des dates et des heures et la résolution des décalages horaires, et Spark a migré vers cette nouvelle API dans la version 3.0. Bien que le mappage des noms de fuseaux horaires aux décalages provienne de la même source, IANA TZDB, il est implémenté différemment dans Java 8 et supérieur par rapport à Java 7.
À titre d'exemple, examinons un horodatage antérieur à 1883 dans le fuseau horaire 
America/Los_Angeles : 1883-11-10 00:00:00. Cette année se distingue des autres car le 18 novembre 1883, tous les chemins de fer nord-américains sont passés à un nouveau système d'heure standard qui a dès lors régi leurs horaires.
En utilisant l'API de temps Java 7, nous pouvons obtenir le décalage horaire de l'horodatage local comme -08:00 :
Les fonctions de l'API Java 8 renvoient un résultat différent :
Avant le 18 novembre 1883, l'heure de la journée était une affaire locale, et la plupart des villes utilisaient une forme d'heure solaire locale, maintenue par une horloge bien connue (sur un clocher d'église, par exemple, ou dans la vitrine d'un bijoutier). C'est pourquoi nous voyons un décalage horaire aussi étrange.
L'exemple montre que les fonctions Java 8 sont plus précises et prennent en compte les données historiques de l'IANA TZDB. Après être passé à l'API de temps Java 8, Spark 3.0 a bénéficié automatiquement de l'amélioration et est devenu plus précis dans la résolution des décalages horaires.
Comme nous l'avons mentionné précédemment, Spark 3.0 est également passé au calendrier grégorien proleptique pour le type date. Il en va de même pour le type horodatage. La norme ISO SQL:2016 déclare que la plage valide pour les horodatages est de 0001-01-01 00:00:00 à 9999-12-31 23:59:59.999999. Spark 3.0 est entièrement conforme à la norme et prend en charge tous les horodatages de cette plage. Comparé à Spark 2.4 et versions antérieures, nous devrions souligner les sous-plages suivantes :
0001-01-01 00:00:00..1582-10-03 23:59:59.999999. Spark 2.4 utilise le calendrier julien et n'est pas conforme à la norme. Spark 3.0 corrige le problème et applique le calendrier grégorien proleptique dans les opérations internes sur les horodatages telles que l'obtention de l'année, du mois, du jour, etc. En raison des différents calendriers, certaines dates qui existent dans Spark 2.4 n'existent pas dans Spark 3.0. Par exemple, 1000-02-29 n'est pas une date valide car 1000 n'est pas une année bissextile dans le calendrier grégorien. De plus, Spark 2.4 résout incorrectement le nom du fuseau horaire en décalages de fuseaux horaires pour cette plage d'horodatages.1582-10-04 00:00:00..1582-10-14 23:59:59.999999. Il s'agit d'une plage valide d'horodatages locaux dans Spark 3.0, contrairement à Spark 2.4 où de tels horodatages n'existaient pas.1582-10-15 00:00:00..1899-12-31 23:59:59.999999. Spark 3.0 résout correctement les décalages horaires en utilisant les données historiques de l'IANA TZDB. Comparé à Spark 3.0, Spark 2.4 peut résoudre incorrectement les décalages horaires à partir des noms de fuseaux horaires dans certains cas, comme nous l'avons montré dans l'exemple ci-dessus.1900-01-01 00:00:00..2036-12-31 23:59:59.999999. Spark 3.0 et Spark 2.4 sont conformes à la norme SQL ANSI et utilisent le calendrier grégorien pour les opérations de date et d'heure, comme l'obtention du jour du mois.2037-01-01 00:00:00..9999-12-31 23:59:59.999999. Spark 2.4 peut résoudre de manière incorrecte les décalages de fuseaux horaires et en particulier les décalages d'heure d'été en raison d'un bug JDK #8073446. Spark 3.0 ne souffre pas de ce défaut.
Un autre aspect de la mise en correspondance des noms de fuseaux horaires avec les décalages est le chevauchement des horodatages locaux qui peut se produire en raison de l'heure d'été (DST) ou du passage à un autre décalage de fuseau horaire. Par exemple, le 3 novembre 2019, 02:00:00, les horloges ont été reculées d'une heure à 01:00:00. L'horodatage local 
2019-11-03 01:30:00 America/Los_Angeles peut être mis en correspondance soit avec 2019-11-03 01:30:00 UTC-08:00, soit avec 2019-11-03 01:30:00 UTC-07:00. Si vous ne spécifiez pas le décalage et vous contentez de définir le nom du fuseau horaire (par exemple, '2019-11-03 01:30:00 America/Los_Angeles'), Spark 3.0 prendra le décalage le plus précoce, correspondant généralement à l'heure d'été. Le comportement diffère de Spark 2.4 qui prend le décalage d'hiver. En cas de saut, où les horloges avancent, il n'y a pas de décalage valide. Pour un changement typique d'heure d'été d'une heure, Spark déplacera ces horodatages vers le prochain horodatage valide correspondant à l'heure d'été.
Comme nous pouvons le constater d'après les exemples ci-dessus, la mise en correspondance des noms de fuseaux horaires avec les décalages est ambiguë et n'est pas univoque. Dans les cas où cela est possible, nous recommandons de spécifier les décalages exacts des fuseaux horaires lors de la création des horodatages, par exemple timestamp '2019-11-03 01:30:00 UTC-07:00'.
Éloignons-nous de la mise en correspondance des noms de zones avec les décalages et examinons la norme SQL ANSI. Elle définit deux types d'horodatages :
TIMESTAMP WITHOUT TIME ZONEouTIMESTAMP- Horodatage local sous la forme (ANNÉE, MOIS, JOUR, HEURE, MINUTE, SECONDE). Ces types d'horodatages ne sont liés à aucun fuseau horaire et sont en réalité des horodatages de l'heure locale.TIMESTAMP WITH TIME ZONE- Horodatage zoné sous la forme (ANNÉE, MOIS, JOUR, HEURE, MINUTE, SECONDE, HEURE_FUSEAU_HORAIRE, MINUTE_FUSEAU_HORAIRE). Les horodatages représentent un instant dans le fuseau horaire UTC + un décalage de fuseau horaire (en heures et minutes) associé à chaque valeur.
Le décalage de fuseau horaire d'un TIMESTAMP WITH TIME ZONE n'affecte pas le point temporel physique que représente l'horodatage, car celui-ci est entièrement représenté par l'instant UTC donné par les autres composantes de l'horodatage. Au lieu de cela, le décalage de fuseau horaire affecte uniquement le comportement par défaut d'une valeur d'horodatage pour l'affichage, l'extraction de composantes de date/heure (par exemple, EXTRACT) et d'autres opérations qui nécessitent de connaître un fuseau horaire, comme l'ajout de mois à un horodatage.
Spark SQL définit le type d'horodatage comme TIMESTAMP WITH SESSION TIME ZONE, qui est une combinaison des champs (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, SESSION TZ) où le champ YEAR à SECOND identifie un instant dans le fuseau horaire UTC, et où SESSION TZ est pris de la configuration SQL spark.sql.session.timeZone. Le fuseau horaire de la session peut être défini comme :
- Décalage de zone
'(+|-)HH:mm'. Cette forme nous permet de définir un point temporel physique sans ambiguïté. - Nom du fuseau horaire sous la forme d'un identifiant de région
'area/city', tel que'America/Los_Angeles'. Cette forme d'information de fuseau horaire souffre de certains des problèmes que nous avons décrits ci-dessus, comme le chevauchement des horodatages locaux. Cependant, chaque instant UTC est associé sans ambiguïté à un décalage de fuseau horaire pour tout identifiant de région, et par conséquent, chaque horodatage avec un fuseau horaire basé sur un identifiant de région peut être converti sans ambiguïté en un horodatage avec un décalage de zone.
Par défaut, le fuseau horaire de la session est défini sur le fuseau horaire par défaut de la machine virtuelle Java.
TIMESTAMP WITH SESSION TIME ZONE de Spark diffère de :
TIMESTAMP WITHOUT TIME ZONE, car une valeur de ce type peut correspondre à plusieurs instants temporels physiques, mais toute valeur deTIMESTAMP WITH SESSION TIME ZONEest un instant temporel physique concret. Le type SQL peut être émulé en utilisant un décalage de fuseau horaire fixe dans toutes les sessions, par exemple UTC+0. Dans ce cas, nous pourrions considérer les horodatages à UTC comme des horodatages locaux.TIMESTAMP WITH TIME ZONE, car selon la norme SQL, les valeurs de colonne de ce type peuvent avoir des décalages de fuseaux horaires différents. Cela n'est pas pris en charge par Spark SQL.
Nous devrions noter que les horodatages associés à un fuseau horaire global (d'une portée de session) ne sont pas une nouveauté de Spark SQL. Les SGBDR tels qu'Oracle fournissent également un type similaire pour les horodatages : TIMESTAMP WITH LOCAL TIME ZONE.
Construction de dates et d'horodatages
Spark SQL fournit quelques méthodes pour construire des valeurs de date et d'horodatage :
- Constructeurs par défaut sans paramètres :
CURRENT_TIMESTAMP()etCURRENT_DATE(). - À partir d'autres types primitifs Spark SQL, tels que
INT,LONGetSTRING. - À partir de types externes comme
datetimePython ou les classes Javajava.time.LocalDate/Instant. - Désérialisation à partir de sources de données CSV, JSON, Avro, Parquet, ORC ou autres.
La fonction MAKE_DATE introduite dans Spark 3.0 prend trois paramètres : YEAR, MONTH de l'année et DAY du mois, et crée une valeur DATE. Tous les paramètres d'entrée sont implicitement convertis en type INT lorsque cela est possible. La fonction vérifie que les dates résultantes sont des dates valides dans le calendrier grégorien proleptique, sinon elle renvoie NULL. Par exemple, en PySpark :
Pour afficher le contenu du DataFrame, appelons l'action show(), qui convertit les dates en chaînes sur les exécuteurs et transfère les chaînes au pilote pour les afficher sur la console :
De même, nous pouvons créer des valeurs d'horodatage via les fonctions MAKE_TIMESTAMP. Comme MAKE_DATE, elle effectue la même validation pour les champs de date, et accepte en outre les champs d'heure HOUR (0-23), MINUTE (0-59) et SECOND (0-60). SECOND a le type Decimal(précision = 8, échelle = 6) car les secondes peuvent être fournies avec une partie fractionnaire jusqu'à la précision de la microseconde. Par exemple, en PySpark :
Comme nous l'avons fait pour les dates, affichons le contenu du DataFrame ts en utilisant l'action show(). De manière similaire, show() convertit les horodatages en chaînes, mais prend maintenant en compte le fuseau horaire de la session défini par la configuration SQL spark.sql.session.timeZone. Nous le verrons dans les exemples suivants.
Spark ne peut pas créer le dernier horodatage car cette date n'est pas valide : 2019 n'est pas une année bissextile.
Vous remarquerez peut-être que nous n'avons fourni aucune information de fuseau horaire dans l'exemple ci-dessus. Dans ce cas, Spark prend un fuseau horaire de la configuration SQL spark.sql.session.timeZone et l'applique aux invocations de fonction. Vous pouvez également choisir un fuseau horaire différent en le passant comme dernier paramètre de MAKE_TIMESTAMP. Voici un exemple en PySpark :
Comme le montre l'exemple, Spark prend en compte les fuseaux horaires spécifiés mais ajuste tous les horodatages locaux au fuseau horaire de la session. Les fuseaux horaires d'origine transmis à la fonction MAKE_TIMESTAMP seront perdus car le type TIMESTAMP WITH SESSION TIME ZONE suppose que toutes les valeurs appartiennent à un seul fuseau horaire, et il ne stocke même pas de fuseau horaire pour chaque valeur. Selon la définition de TIMESTAMP WITH SESSION TIME ZONE, Spark stocke les horodatages locaux dans le fuseau horaire UTC et utilise le fuseau horaire de la session lors de l'extraction des champs de date/heure ou de la conversion des horodatages en chaînes de caractères.
De plus, les horodatages peuvent être construits à partir du type LONG par transtypage. Si une colonne LONG contient le nombre de secondes depuis l'époque 1970-01-01 00:00:00Z, elle peut être transtypée vers le type TIMESTAMP de Spark SQL :
Malheureusement, cette approche ne nous permet pas de spécifier la partie fractionnaire des secondes. À l'avenir, Spark SQL fournira des fonctions spéciales pour créer des horodatages à partir de secondes, millisecondes et microsecondes depuis l'époque : timestamp_seconds(), timestamp_millis() et timestamp_micros().
Une autre façon est de construire des dates et des horodatages à partir de valeurs de type STRING. Nous pouvons créer des littéraux en utilisant des mots-clés spéciaux :
ou par transtypage que nous pouvons appliquer à toutes les valeurs d'une colonne :
Les chaînes d'horodatage d'entrée sont interprétées comme des horodatages locaux dans le fuseau horaire spécifié ou dans le fuseau horaire de la session si un fuseau horaire est omis dans la chaîne d'entrée. Les chaînes avec des motifs inhabituels peuvent être converties en horodatage en utilisant la fonction to_timestamp(). Les motifs pris en charge sont décrits dans Motifs de date et heure pour le formatage et l'analyse :
La fonction se comporte de manière similaire à CAST si vous ne spécifiez aucun motif.
Pour des raisons d'utilisabilité, Spark SQL reconnaît les valeurs de chaîne spéciales dans toutes les méthodes ci-dessus qui acceptent une chaîne et renvoient un horodatage et une date :
- epoch est un alias pour date '1970-01-01' ou horodatage
'1970-01-01 00:00:00Z' - now est l'horodatage ou la date actuelle dans le fuseau horaire de la session. Dans une seule requête, il produit toujours le même résultat.
- today est le début de la date actuelle pour le type
TIMESTAMPou juste la date actuelle pour le typeDATE. - tomorrow est le début du jour suivant pour les horodatages ou juste le jour suivant pour le type
DATE. - yesterday est le jour précédent le jour actuel ou son début pour le type
TIMESTAMP.
Par exemple :
L'une des grandes fonctionnalités de Spark est la création de Datasets à partir de collections existantes d'objets externes côté driver, et la création de colonnes de types correspondants. Spark convertit les instances de types externes en représentations internes sémantiquement équivalentes. PySpark permet de créer un Dataset avec des colonnes DATE et TIMESTAMP à partir de collections Python, par exemple :
PySpark convertit les objets datetime Python en représentations internes Spark SQL côté driver en utilisant le fuseau horaire système, qui peut être différent des paramètres du fuseau horaire de la session Spark spark.sql.session.timeZone. Les valeurs internes ne contiennent pas d'informations sur le fuseau horaire d'origine. Les opérations futures sur les dates et horodatages parallélisés prendront en compte uniquement le fuseau horaire des sessions Spark SQL, conformément à la définition du type TIMESTAMP WITH SESSION TIME ZONE.
De la même manière que nous l'avons démontré ci-dessus pour les collections Python, Spark reconnaît les types suivants comme types de date et heure externes dans les API Java/Scala :
- java.sql.Date et java.time.LocalDate comme types externes pour le type DATE de Spark SQL
- java.sql.Timestamp et java.time.Instant pour le type TIMESTAMP.
Il y a une différence entre les types java.sql.* et java.time.*. Les types java.time.LocalDate et java.time.Instant ont été ajoutés dans Java 8, et les types sont basés sur le calendrier grégorien proleptique — le même calendrier qui est utilisé par Spark à partir de la version 3.0. Les types java.sql.Date et java.sql.Timestamp ont un autre calendrier sous-jacent — le calendrier hybride (Julien + Grégorien depuis 1582-10-15), qui est le même que le calendrier hérité utilisé par les versions de Spark antérieures à 3.0. En raison des différents systèmes de calendrier, Spark doit effectuer des opérations supplémentaires lors des conversions vers les représentations internes de Spark SQL, et rebaser les dates/horodatages d'entrée d'un calendrier à un autre. L'opération de rebasage a une légère surcharge pour les horodatages modernes après l'année 1900, et elle peut être plus significative pour les anciens horodatages.
L'exemple ci-dessous montre la création d'horodatages à partir de collections Scala. Dans le premier exemple, nous construisons un objet java.sql.Timestamp à partir d'une chaîne. La méthode valueOf interprète les chaînes d'entrée comme un horodatage local dans le fuseau horaire JVM par défaut, qui peut être différent du fuseau horaire de la session Spark. Si vous avez besoin de construire des instances de java.sql.Timestamp ou java.sql.Date dans un fuseau horaire spécifique, nous vous recommandons de consulter java.text.SimpleDateFormat (et sa méthode setTimeZone) ou java.util.Calendar.
De même, nous pouvons créer une colonne DATE à partir de collections de java.sql.Date ou java.LocalDate. La parallélisation des instances de java.LocalDate est totalement indépendante du fuseau horaire de la session Spark ou du fuseau horaire par défaut de la JVM, mais nous ne pouvons pas en dire autant de la parallélisation des instances de java.sql.Date. Il y a des nuances :
- Les instances de
java.sql.Datereprésentent des dates locales dans le fuseau horaire JVM par défaut sur le driver - Pour des conversions correctes vers les valeurs Spark SQL, le fuseau horaire JVM par défaut sur le driver et les exécuteurs doit être le même.
Pour éviter tout problème lié au calendrier et au fuseau horaire, nous recommandons les types Java 8 java.LocalDate/Instant comme types externes pour la parallélisation des collections Java/Scala d'horodatages ou de dates.
Collecte des dates et des horodatages
L'opération inverse de la parallélisation consiste à collecter les dates et les horodatages des exécuteurs vers le driver et à renvoyer une collection de types externes. Pour l'exemple ci-dessus, nous pouvons ramener le DataFrame vers le driver via l'action collect() :
Spark transfère les valeurs internes des colonnes de dates et d'horodatages sous forme d'instants de temps dans le fuseau horaire UTC des exécuteurs vers le pilote, et effectue les conversions en objets datetime Python dans le fuseau horaire système sur le pilote, sans utiliser le fuseau horaire de la session Spark SQL. collect() est différent de l'action show() décrite dans la section précédente. show() utilise le fuseau horaire de la session lors de la conversion des horodatages en chaînes de caractères, et collecte les chaînes résultantes sur le pilote.
Dans les API Java et Scala, Spark effectue les conversions suivantes par défaut :
- Les valeurs
DATEde Spark SQL sont converties en instances dejava.sql.Date. - Les horodatages sont convertis en instances de
java.sql.Timestamp.
Ces deux conversions sont effectuées dans le fuseau horaire JVM par défaut sur le pilote. Ainsi, pour obtenir les mêmes champs date-heure que ceux que nous pouvons obtenir via Date.getDay(), getHour(), etc. et via les fonctions Spark SQL DAY, HOUR, le fuseau horaire JVM par défaut sur le pilote et le fuseau horaire de la session sur les exécuteurs doivent être identiques.
Similairement à la création de dates/horodatages à partir de java.sql.Date/Timestamp, Spark 3.0 effectue un rebasage du calendrier grégorien proleptique vers le calendrier hybride (julien + grégorien). Cette opération est presque gratuite pour les dates modernes (après 1582) et les horodatages (après 1900), mais elle peut entraîner une surcharge pour les dates et horodatages anciens.
Nous pouvons éviter ces problèmes liés au calendrier et demander à Spark de renvoyer des types java.time, qui ont été ajoutés depuis Java 8. Si nous définissons la configuration SQL spark.sql.datetime.java8API.enabled sur true, l'action Dataset.collect() renverra :
java.time.LocalDatepour le typeDATEde Spark SQLjava.time.Instantpour le typeTIMESTAMPde Spark SQL
Désormais, les conversions ne souffrent plus des problèmes liés au calendrier car les types Java 8 et Spark SQL 3.0 sont tous deux basés sur le calendrier grégorien proleptique. L'action collect() ne dépend plus du fuseau horaire JVM par défaut. Les conversions d'horodatage ne dépendent plus du tout du fuseau horaire. Concernant la conversion de date, elle utilise le fuseau horaire de la session à partir de la configuration SQL spark.sql.session.timeZone. Par exemple, regardons un Dataset avec des colonnes DATE et TIMESTAMP, définissons le fuseau horaire JVM par défaut sur Europe/Moscow, mais le fuseau horaire de la session sur America/Los_Angeles.
L'action show() affiche l'horodatage dans le fuseau horaire de la session America/Los_Angeles, mais si nous collectons le Dataset, il sera converti en java.sql.Timestamp et affiché dans Europe/Moscow par la méthode toString :
En fait, l'horodatage local 2020-07-01 00:00:00 correspond à 2020-07-01T07:00:00Z en UTC. Nous pouvons l'observer si nous activons l'API Java 8 et collectons le Dataset :
L'objet java.time.Instant peut être converti ultérieurement en n'importe quel horodatage local indépendamment du fuseau horaire JVM global. C'est l'un des avantages de java.time.Instant par rapport à java.sql.Timestamp. Le premier nécessite de modifier le réglage global de la JVM, ce qui influence les autres horodatages sur la même JVM. Par conséquent, si vos applications traitent des dates ou des horodatages dans différents fuseaux horaires, et que les applications ne doivent pas entrer en conflit les unes avec les autres lors de la collecte de données vers le pilote via l'API Java/Scala Dataset.collect(), nous recommandons de passer à l'API Java 8 en utilisant la configuration SQL spark.sql.datetime.java8API.enabled.
Conclusion
Dans cet article de blog, nous avons décrit les types DATE et TIMESTAMP de Spark SQL. Nous avons montré comment construire des colonnes de dates et d'horodatages à partir d'autres types Spark SQL primitifs et de types Java externes, et comment collecter des colonnes de dates et d'horodatages vers le pilote sous forme de types Java externes. Depuis la version 3.0, Spark est passé du calendrier hybride, qui combine les calendriers julien et grégorien, au calendrier grégorien proleptique (voir SPARK-26651 pour plus de détails). Cela a permis à Spark d'éliminer de nombreux problèmes tels que ceux que nous avons démontrés précédemment. Pour la compatibilité ascendante avec les versions précédentes, Spark renvoie toujours les horodatages et les dates dans le calendrier hybride (java.sql.Date et java.sql.Timestamp) à partir des actions de type collect. Pour éviter les problèmes de résolution de calendrier et de fuseau horaire lors de l'utilisation des actions collect Java/Scala, l'API Java 8 peut être activée via la configuration SQL spark.sql.datetime.java8API.enabled. Essayez-la dès aujourd'hui gratuitement sur Databricks dans le cadre de notre Databricks Runtime 7.0.

Livre O'Reilly Learning Spark
La 2ème édition gratuite inclut des mises à jour sur Spark 3.0, notamment les nouveaux type hints Python pour les Pandas UDF, la nouvelle implémentation des dates/heures, etc.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.