Appliquer le chiffrement au niveau des colonnes et éviter la duplication des données avec les PII
Utilisation des bibliothèques de chiffrement Fernet, des UDF et des secrets Databricks pour sécuriser discrètement les données PII
par Keyuri Shah et Fred Kimball
Ceci est un article invité de Keyuri Shah, ingénieure logicielle principale, et Fred Kimball, ingénieur logiciel, Northwestern Mutual.
La protection des PII (informations personnelles identifiables) est très importante, car le nombre de violations de données et d'enregistrements contenant des informations sensibles exposées chaque jour est en augmentation. Pour éviter de devenir la prochaine victime et protéger les utilisateurs contre le vol d'identité et la fraude, nous devons intégrer plusieurs couches de sécurité des données et des informations.
Comme nous utilisons la plateforme Databricks, nous devons nous assurer que nous n'autorisons que les bonnes personnes à accéder aux informations sensibles. En utilisant une combinaison de bibliothèques de chiffrement Fernet, de fonctions définies par l'utilisateur (UDF) et de secrets Databricks, Northwestern Mutual a développé un processus pour chiffrer les informations PII et permettre uniquement à ceux qui en ont un besoin professionnel de les déchiffrer, sans étapes supplémentaires nécessaires pour le lecteur de données.
La nécessité de protéger les PII
La gestion de toute quantité de données client de nos jours nécessite presque certainement la protection des PII. C'est un risque majeur pour les organisations de toutes tailles, car des cas tels que la violation de données de Capital One ont entraîné le vol de millions d'enregistrements clients sensibles en raison d'une simple erreur de configuration. Bien que le chiffrement du périphérique de stockage et le masquage des colonnes au niveau de la table soient des mesures de sécurité efficaces, l'accès interne non autorisé à ces données sensibles constitue toujours une menace majeure. Par conséquent, nous avons besoin d'une solution qui empêche un utilisateur normal ayant un accès aux fichiers ou aux tables de récupérer des informations sensibles au sein de Databricks.
Cependant, nous avons également besoin que ceux qui ont un besoin professionnel de lire des informations sensibles puissent le faire. Nous ne voulons pas qu'il y ait de différence dans la façon dont chaque type d'utilisateur lit la table. Les lectures normales et déchiffrées doivent se faire sur le même objet Delta Lake pour simplifier la construction des requêtes pour l'analyse des données et la construction des rapports.
Construction du processus pour appliquer le chiffrement au niveau des colonnes
Compte tenu de ces exigences de sécurité, nous avons cherché à créer un processus sécurisé, discret et facile à gérer. Le diagramme ci-dessous donne un aperçu général des composants requis pour ce processus
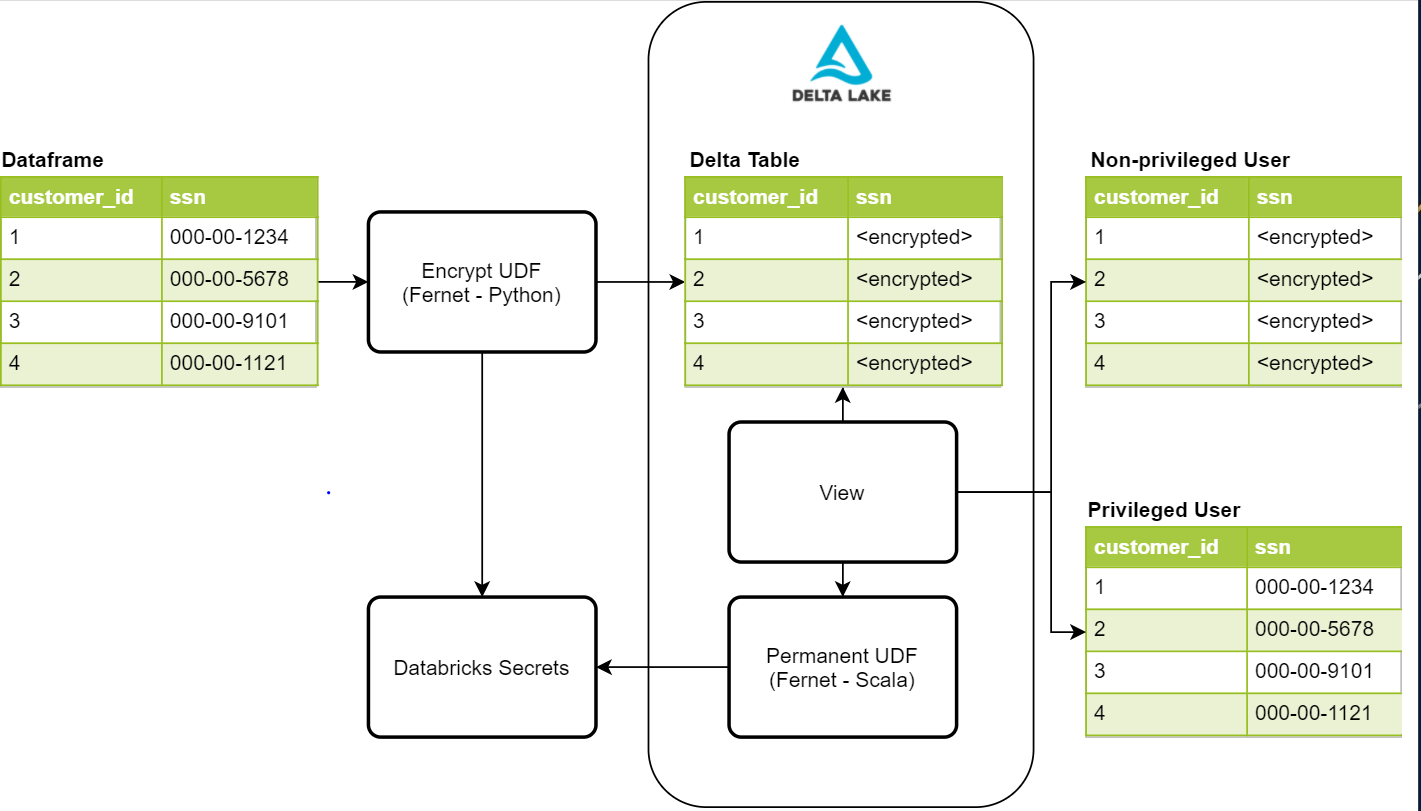
Écriture des PII protégées avec Fernet
La première étape de ce processus consiste à protéger les données en les chiffrant. Une solution possible est la bibliothèque Python Fernet. Fernet utilise le chiffrement symétrique, qui est construit avec plusieurs primitives cryptographiques standard. Cette bibliothèque est utilisée dans une UDF de chiffrement qui nous permettra de chiffrer n'importe quelle colonne donnée dans un dataframe. Pour stocker la clé de chiffrement, nous utilisons les secrets Databricks avec des contrôles d'accès en place pour permettre uniquement à notre processus d'ingestion de données d'y accéder. Une fois les données écrites dans nos tables Delta Lake, les colonnes PII contenant des valeurs telles que le numéro de sécurité sociale, le numéro de téléphone, le numéro de carte de crédit et d'autres identifiants seront impossibles à lire pour un utilisateur non autorisé.
Lecture des données protégées à partir d'une vue avec une UDF personnalisée
Une fois que nous avons écrit et protégé les données sensibles, nous avons besoin d'un moyen pour les utilisateurs privilégiés de lire ces données. La première chose à faire est de créer une UDF permanente à ajouter à l'instance Hive exécutée sur Databricks. Pour qu'une UDF soit permanente, elle doit être écrite en Scala. Heureusement, Fernet dispose également d'une implémentation Scala que nous pouvons utiliser pour nos lectures déchiffrées. Cette UDF accède également au même secret que nous avons utilisé lors de l'écriture chiffrée pour effectuer le déchiffrement, et, dans ce cas, elle est ajoutée à la configuration Spark du cluster. Cela nous oblige à ajouter des contrôles d'accès au cluster pour les utilisateurs privilégiés et non privilégiés afin de contrôler leur accès à la clé. Une fois l'UDF créée, nous pouvons l'utiliser dans nos définitions de vues pour que les utilisateurs privilégiés voient les données déchiffrées.
Actuellement, nous avons deux objets de vue pour un seul jeu de données, un pour les utilisateurs privilégiés et un pour les utilisateurs non privilégiés. La vue pour les utilisateurs non privilégiés n'a pas l'UDF, ils verront donc les valeurs PII sous forme chiffrée. L'autre vue pour les utilisateurs privilégiés a l'UDF, ils peuvent donc voir les valeurs déchiffrées en texte brut pour leurs besoins professionnels. L'accès à ces vues est également contrôlé par les contrôles d'accès aux tables fournis par Databricks.
Dans un avenir proche, nous voulons tirer parti d'une nouvelle fonctionnalité Databricks appelée fonctions de vue dynamiques. Ces fonctions de vue dynamiques nous permettront d'utiliser une seule vue et de retourner facilement les valeurs chiffrées ou déchiffrées en fonction du groupe Databricks dont ils sont membres. Cela réduira le nombre d'objets que nous créons dans notre Delta Lake et simplifiera nos règles de contrôle d'accès aux tables.
Chaque implémentation permet aux utilisateurs de faire leur développement ou leur analyse sans se soucier de savoir s'ils doivent déchiffrer les valeurs lues à partir de la vue et n'autorise l'accès qu'à ceux qui en ont un besoin professionnel.
Avantages de cette méthode de chiffrement au niveau des colonnes
En résumé, les avantages de l'utilisation de ce processus sont les suivants :
- Le chiffrement peut être effectué à l'aide de bibliothèques Python ou Scala existantes
- Les données PII sensibles bénéficient d'une couche de sécurité supplémentaire lors du stockage dans Delta Lake
- Le même objet Delta Lake est utilisé par les utilisateurs ayant tous les niveaux d'accès audit objet
- Les analystes ne sont pas gênés, qu'ils soient autorisés ou non à lire les PII
Pour un exemple de ce à quoi cela peut ressembler, le notebook suivant peut fournir quelques conseils :
Ressources supplémentaires :
Bibliothèques Fernet
Créer une UDF permanente
Fonctions de vue dynamiques
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.