Partie 1 : Implémentation de l'intégration et du déploiement continus (CI/CD) sur Databricks à l'aide des notebooks Databricks et d'Azure DevOps
par Michael Shtelma et Piotr Majer
Le code discuté se trouve ici.
Ceci est la première partie d'une série de deux articles de blog qui montrent comment configurer et construire des solutions MLOps de bout en bout sur Databricks avec des notebooks et l'API Repos. Cet article présente un framework CI/CD sur Databricks, basé sur les notebooks. Le pipeline s'intègre à l'écosystème Microsoft Azure DevOps pour la partie Intégration Continue (CI) et à l'API Repos pour la Livraison Continue (CD). Dans le second article, nous montrerons comment exploiter la fonctionnalité de l'API Repos pour implémenter un cycle de vie CI/CD complet sur Databricks et l'étendre à une solution MLOps complète.
CI/CD avec Databricks Repos
Heureusement, avec la nouvelle fonctionnalité fournie par Databricks Repos et l'API Repos, nous sommes maintenant bien équipés pour couvrir tous les aspects clés du contrôle de version, des tests et des pipelines qui sous-tendent les approches MLOps. Databricks Repos permet de cloner des dépôts Git entiers dans Databricks et, à l'aide de l'API Repos, nous pouvons automatiser ce processus en clonant d'abord un dépôt Git, puis en sélectionnant la branche qui nous intéresse. Les praticiens ML peuvent maintenant utiliser une structure de dépôt bien connue des IDE pour structurer leur projet, en s'appuyant sur des notebooks ou des fichiers .py pour l'implémentation des modules (avec la prise en charge de formats de fichiers arbitraires dans Repos prévue sur la feuille de route). Par conséquent, l'ensemble du projet est contrôlé par un outil de votre choix (Github, Gitlab, Azure Repos pour n'en nommer que quelques-uns) et s'intègre très bien aux pipelines CI/CD courants. L'API Databricks Repos nous permet de mettre à jour un dépôt (projet Git extrait comme dépôt dans Databricks) vers la dernière version d'une branche Git spécifique.
Les équipes peuvent suivre le cycle classique de Git flow ou GitHub flow pendant le développement. L'ensemble du dépôt Git peut être extrait avec Databricks Repos. Les utilisateurs pourront utiliser et modifier les notebooks ainsi que les fichiers Python simples ou d'autres types de fichiers texte avec prise en charge de fichiers arbitraires. Cela nous permet d'utiliser une structure de projet classique, en important des modules à partir de fichiers Python et en les combinant avec des notebooks :
- Développer des fonctionnalités individuelles dans une branche de fonctionnalité et tester à l'aide de tests unitaires (par exemple, notebooks implémentés).
- Pousser les modifications vers la branche de fonctionnalité, où le pipeline CI/CD exécutera le test d'intégration.
- Les pipelines CI/CD sur Azure DevOps peuvent déclencher l'API Databricks Repos pour mettre à jour ce projet de test vers la dernière version.
- Les pipelines CI/CD déclenchent le job de test d'intégration via l'API Jobs. Les tests d'intégration peuvent être implémentés comme un simple notebook qui exécutera d'abord les pipelines que nous souhaitons tester avec des configurations de test. Cela peut être fait simplement en exécutant un notebook approprié avec l'exécution des modules correspondants ou en déclenchant le vrai job en utilisant l'API Jobs.
- Examiner les résultats pour marquer l'ensemble de l'exécution du test comme réussie ou échouée.
Examinons maintenant comment nous pouvons implémenter l'approche décrite ci-dessus. À titre d'exemple de flux de travail, nous nous concentrerons sur les données provenant de la compétition Kaggle Lending Club. Similaire à de nombreuses institutions financières, nous souhaitons comprendre et prédire les données de revenus individuels, par exemple, pour évaluer le score de crédit d'une demande. Pour ce faire, nous analysons diverses caractéristiques et attributs des candidats, allant de la profession actuelle, de la propriété immobilière, de l'éducation aux données de localisation, du statut marital et de l'âge. C'est l'information qu'une banque a collectée (par exemple, lors de demandes de crédit antérieures) et elle est maintenant utilisée pour entraîner un modèle de régression.
De plus, nous savons que notre activité évolue dynamiquement et qu'il y a un grand volume de nouvelles observations chaque jour. Avec l'ingestion régulière de nouvelles données, le réentraînement du modèle est crucial. Par conséquent, l'accent est mis sur l'automatisation complète des jobs de réentraînement ainsi que sur le pipeline de déploiement continu. Pour garantir des résultats de haute qualité et un pouvoir prédictif élevé d'un modèle nouvellement entraîné, nous ajoutons une étape d'évaluation après chaque job entraîné. Ici, le modèle ML est évalué sur un ensemble de données organisé et comparé à la version de production actuellement déployée. Par conséquent, la promotion du modèle ne peut avoir lieu que si la nouvelle itération a un pouvoir prédictif élevé.
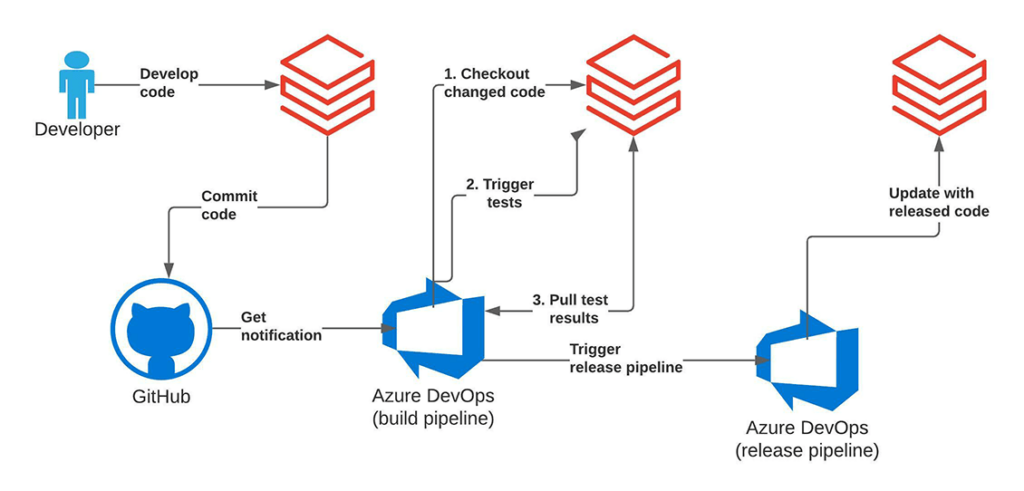
Comme un projet est activement développé et travaillé, les tests entièrement automatisés du nouveau code et la promotion à l'étape suivante du cycle de vie utilisent le framework Azure DevOps pour l'évaluation unitaire/d'intégration lors des requêtes push/pull. Les tests sont orchestrés via le framework Azure DevOps et exécutés sur la plateforme Databricks. Cela couvre la partie CI du processus, garantissant une couverture de test élevée de notre base de code, minimisant la supervision humaine.
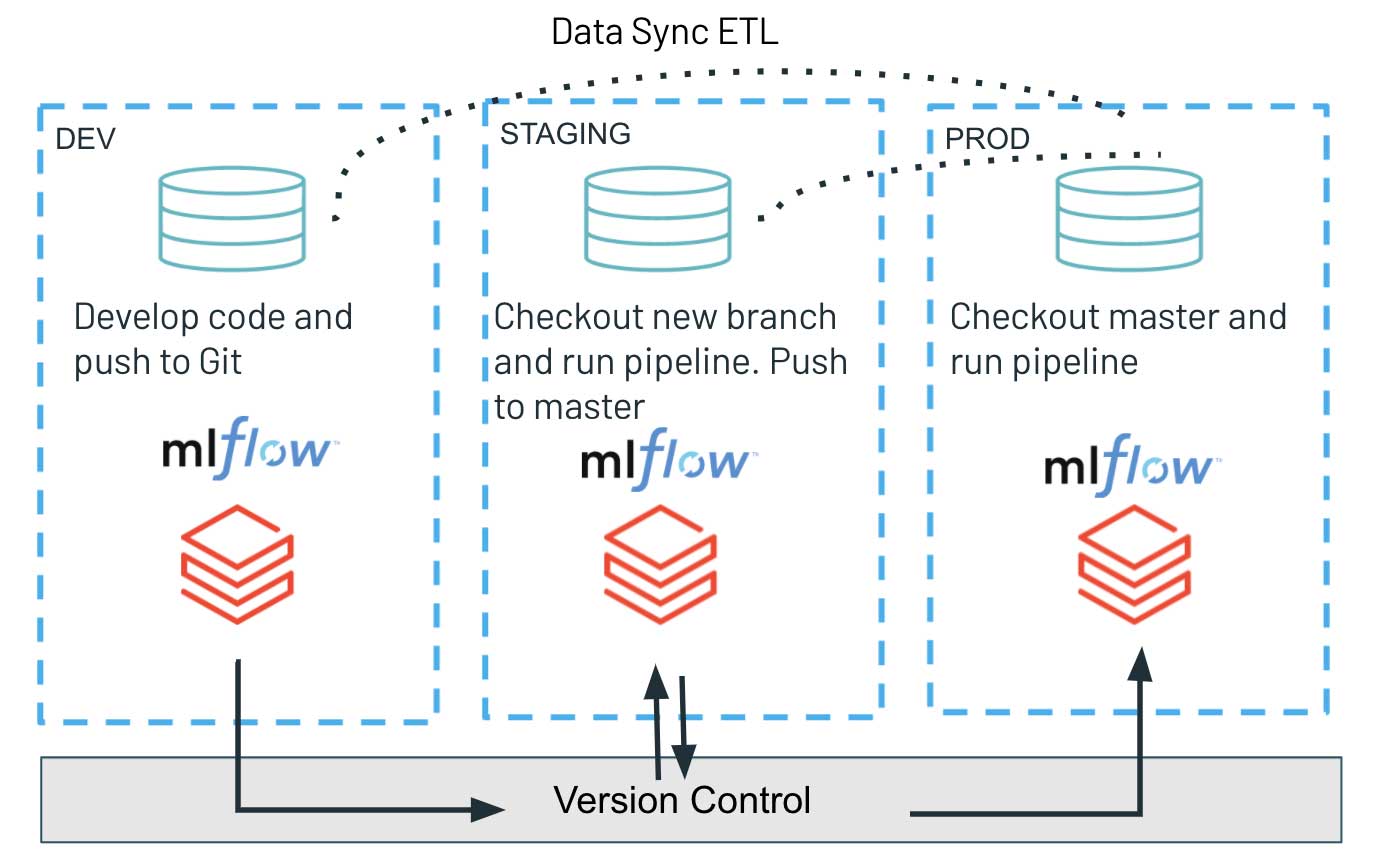
La partie livraison continue repose entièrement sur l'API Repos, où nous utilisons l'interface programmatique pour extraire la dernière version de notre code dans la branche Git et déployer les scripts les plus récents pour exécuter la charge de travail. Cela nous permet de simplifier le processus de déploiement des artefacts et de promouvoir facilement la version de code testée de l'environnement de développement à travers les environnements de staging et de production. Une telle architecture garantit l'isolation complète des différents environnements et est généralement privilégiée dans les environnements de sécurité accrue. Les différentes étapes : développement, staging et production ne partagent que le système de contrôle de version, minimisant les interférences potentielles avec les charges de travail de production hautement critiques. Dans le même temps, le travail exploratoire et l'innovation sont découplés car l'environnement de développement peut avoir des contrôles d'accès plus souples.
Implémenter un pipeline CI/CD en utilisant Azure DevOps et Databricks
Dans le dépôt de code suivant, nous avons implémenté le projet ML avec un pipeline CI/CD alimenté par Azure DevOps. Dans ce projet, nous utilisons des notebooks pour la préparation des données et l'entraînement du modèle.
Voyons comment nous pouvons tester ces notebooks sur Databricks. Azure DevOps est un framework très populaire pour les flux de travail CI/CD complets disponibles sur Azure. Pour plus d'informations, veuillez consulter l'aperçu des fonctionnalités fournies et les intégrations continues avec Databricks.
Nous utilisons le pipeline Azure DevOps sous forme de fichier YAML. Le pipeline traite les notebooks Databricks comme de simples fichiers Python, nous pouvons donc les exécuter dans notre pipeline CI/CD. Nous avons placé un fichier YAML pour notre pipeline CI/CD Azure dans azure-pipelines.yml. La partie la plus intéressante de ce fichier est un appel à l'API Databricks Repos pour mettre à jour l'état du projet CI/CD sur Databricks et un appel à l'API Databricks Jobs pour déclencher l'exécution du job de test d'intégration. Nous avons développé ces deux éléments dans le script/notebook deploy.py. Nous pouvons l'appeler de la manière suivante dans le pipeline Azure DevOps :
Les variables d'environnement DATABRICKS_HOST et DATABRICKS_TOKEN sont nécessaires au package databricks_cli pour nous authentifier auprès de l'espace de travail Databricks que nous utilisons. Ces variables peuvent être gérées via les groupes de variables Azure DevOps.
Examinons maintenant le script deploy.py. Dans le script, nous utilisons l'API databricks_cli pour travailler avec l'API Databricks Jobs. Tout d'abord, nous devons créer un client API :
Après cela, nous pouvons créer un nouveau dépôt temporaire sur Databricks pour notre projet et extraire la dernière révision de notre dépôt nouvellement créé :
Ensuite, nous pouvons lancer l'exécution du job de test d'intégration sur Databricks :
Enfin, nous attendons la fin du job et examinons le résultat :
Utilisation de plusieurs espaces de travail
L'utilisation de l'API Databricks Repos pour l'intégration et le déploiement continus (CI/CD) peut être particulièrement utile pour les équipes qui recherchent une isolation complète entre leurs environnements de développement/staging et de production. La nouvelle fonctionnalité permet aux équipes de données, via le code source sur Databricks, de déployer la base de code mise à jour et les artefacts d'une charge de travail via une interface de commande simple sur plusieurs environnements. La possibilité de récupérer programmatiquement la dernière base de code dans le système de contrôle de version garantit un processus de publication simple et rapide.
Pour les pratiques MLOps, il existe de nombreuses considérations importantes sur la bonne configuration architecturale entre les différents environnements. Dans cette étude, nous nous concentrons uniquement sur le paradigme de l'isolation complète, qui couvrirait également plusieurs instances MLflow associées au développement/staging/production. Dans cette optique, les modèles entraînés dans un environnement de développement ne seraient pas poussés à l'étape suivante car les objets sérialisés sont chargés via un seul registre de modèles commun. Le seul artefact déployé est la nouvelle base de code du pipeline d'entraînement qui est publiée et exécutée dans l'environnement STAGING, résultant en un nouveau modèle entraîné et enregistré avec MLflow.
Ce principe de non-partage, associé à une gestion stricte des autorisations sur les environnements de production/staging, mais à des modèles d'accès plus souples en développement, permet un développement logiciel robuste et de haute qualité. Simultanément, il offre une plus grande liberté dans l'instance de développement, accélérant l'innovation et l'expérimentation au sein de l'équipe de données.
Résumé
Dans ce billet de blog, nous avons présenté une approche de bout en bout pour les pipelines CI/CD sur Databricks en utilisant des projets basés sur des notebooks. Ce flux de travail est basé sur la fonctionnalité de l'API Repos qui permet non seulement aux équipes de données de structurer et de versionner leurs projets de manière plus pratique, mais simplifie également grandement la mise en œuvre et l'exécution des outils CI/CD. Nous avons présenté une architecture dans laquelle tous les environnements opérationnels sont entièrement isolés, garantissant un haut niveau de sécurité pour les charges de travail de production alimentées par ML.
Les pipelines CI/CD sont alimentés par un framework de choix et s'intègrent en douceur à la plateforme Databricks Unified Analytics Platform, déclenchant l'exécution du code et le provisionnement de l'infrastructure de bout en bout. L'API Repos simplifie radicalement non seulement la gestion des versions, la structuration du code et la partie développement du cycle de vie d'un projet, mais aussi la livraison continue, permettant de déployer les artefacts de production et le code entre les environnements. C'est une amélioration importante qui ajoute à l'efficacité et à la scalabilité globales de Databricks et améliore considérablement l'expérience des développeurs de logiciels.
Le code discuté peut être trouvé ici.
Références :
- https://www.databricks.com/blog/2021/06/23/need-for-data-centric-ml-platforms.html
- Continuous Delivery for Machine Learning, Martin Fowler, https://martinfowler.com/articles/cd4ml.html,
- Overview of MLOps, https://www.kdnuggets.com/2021/03/overview-mlops.htm Introducing Azure DevOps, https://azure.microsoft.com/en-us/blog/introducing-azure-devops/
- Continuous integration and delivery on Azure Databricks using Azure DevOps, https://docs.microsoft.com/en-us/azure/databricks/dev-tools/ci-cd/ci-cd-azure-devops
- Lending club Kaggle data set https://www.kaggle.com/wordsforthewise/lending-club
- Repos for Git integration https://docs.databricks.com/repos.html
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.