Présentation des profils de données dans le Notebook Databricks
Simplifier l'analyse exploratoire des données
par Edward Gan, Moonsoo Lee et Austin Ford
Avant qu'un scientifique des données puisse rédiger un rapport sur l'analytique ou entraîner un modèle d'apprentissage automatique (ML), il doit comprendre la structure et le contenu de ses données. Cette analyse exploratoire des données est itérative, chaque étape du cycle impliquant souvent les mêmes techniques de base : visualisation des distributions de données et calcul de statistiques récapitulatives comme le nombre de lignes, le nombre de valeurs nulles, la moyenne, les fréquences des éléments, etc. Malheureusement, la génération manuelle de ces visualisations et statistiques est fastidieuse et sujette aux erreurs, en particulier pour les grands ensembles de données. Pour relever ce défi et simplifier l'analyse exploratoire des données, nous introduisons des capacités de profilage de données dans le Notebook Databricks.
Profilage des données dans le Notebook
Les équipes de données travaillant sur un cluster exécutant DBR 9.1 ou une version plus récente disposent de deux méthodes pour générer des profils de données dans le Notebook : via l'interface utilisateur de sortie de cellule et via la bibliothèque dbutils. Lors de la visualisation du contenu d'un DataFrame à l'aide de la fonction d'affichage Databricks (AWS|Azure|Google) ou des résultats d'une requête SQL, les utilisateurs verront un onglet « Profil de données » à droite de l'onglet « Tableau » dans la sortie de la cellule. Le clic sur cet onglet exécutera automatiquement une nouvelle commande qui générera un profil des données du DataFrame. Le profil comprendra des statistiques récapitulatives pour les colonnes numériques, de chaîne et de date, ainsi que des histogrammes des distributions de valeurs pour chaque colonne. Notez que cette commande profilera l'ensemble du jeu de données dans le DataFrame ou les résultats de la requête SQL, pas seulement la partie affichée dans le tableau (qui peut être tronquée).
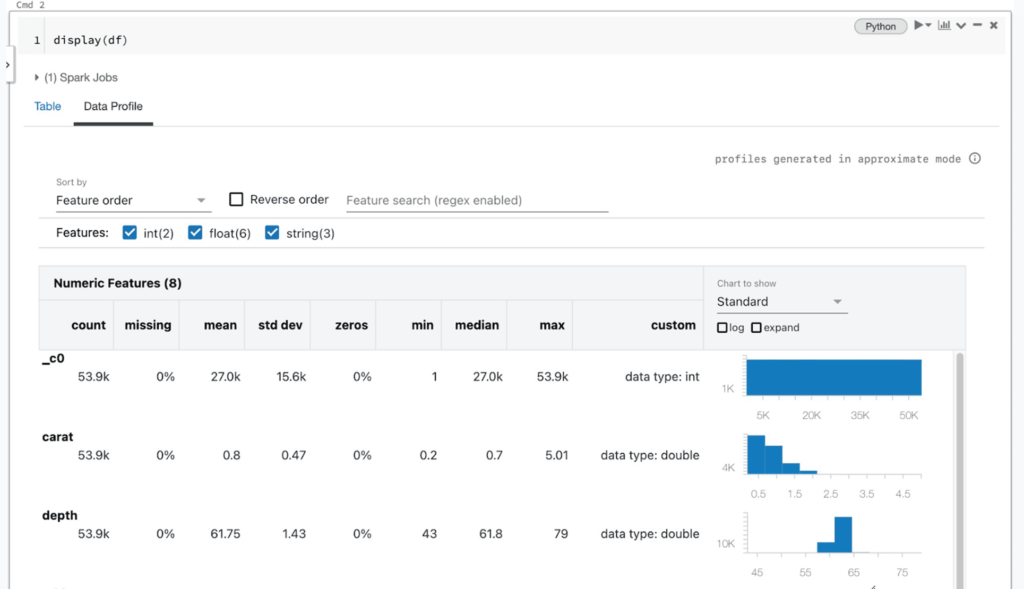
En coulisses, l'interface utilisateur du notebook émet une nouvelle commande pour calculer un profil de données, qui est implémentée via une requête Apache Spark™ générée automatiquement pour chaque jeu de données. Cette fonctionnalité est également disponible via l'API dbutils en Python, Scala et R, en utilisant la commande dbutils.data.summarize(df). Pour plus d'informations, consultez la documentation (AWS|Azure|Google).
Essayez les profils de données dès aujourd'hui en prévisualisant les DataFrames dans les notebooks Databricks !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.