Organisation fonctionnelle de l'espace de travail sur Databricks
Essentiels d'administration Databricks : Blog 1/5
par Anindita Mahapatra et Greg Wood
Introduction
Ce blog est la première partie de notre série Admin Essentials, où nous aborderons les sujets importants pour ceux qui gèrent et maintiennent les environnements Databricks. Gardez un œil sur les blogs supplémentaires concernant la gouvernance des données, l'exploitation et l'automatisation, la gestion des utilisateurs et l'accessibilité, ainsi que le suivi et la gestion des coûts dans un avenir proche !
En 2020, Databricks a commencé à publier des aperçus privés de plusieurs fonctionnalités de plateforme connues collectivement sous le nom d'Enterprise 2.0 (ou E2) ; ces fonctionnalités ont fourni la prochaine itération de la plateforme Lakehouse, créant la scalabilité et la sécurité pour correspondre à la puissance et à la vitesse déjà disponibles sur Databricks. Lorsque Enterprise 2.0 a été rendu public, l'une des additions les plus attendues était la possibilité de créer plusieurs espaces de travail à partir d'un seul compte. Cette fonctionnalité a ouvert de nouvelles possibilités de collaboration, d'alignement organisationnel et de simplification. Comme nous l'avons constaté depuis, elle a cependant soulevé un certain nombre de questions. Sur la base de notre expérience avec des clients d'entreprise de toutes tailles, formes et secteurs d'activité, ce blog présentera des réponses et des meilleures pratiques aux questions les plus courantes concernant la gestion des espaces de travail au sein de Databricks ; à un niveau fondamental, cela se résume à une question simple : quand exactement un nouvel espace de travail doit-il être créé ? Plus précisément, nous mettrons en évidence les stratégies clés pour organiser vos espaces de travail et les meilleures pratiques pour chacune d'elles.
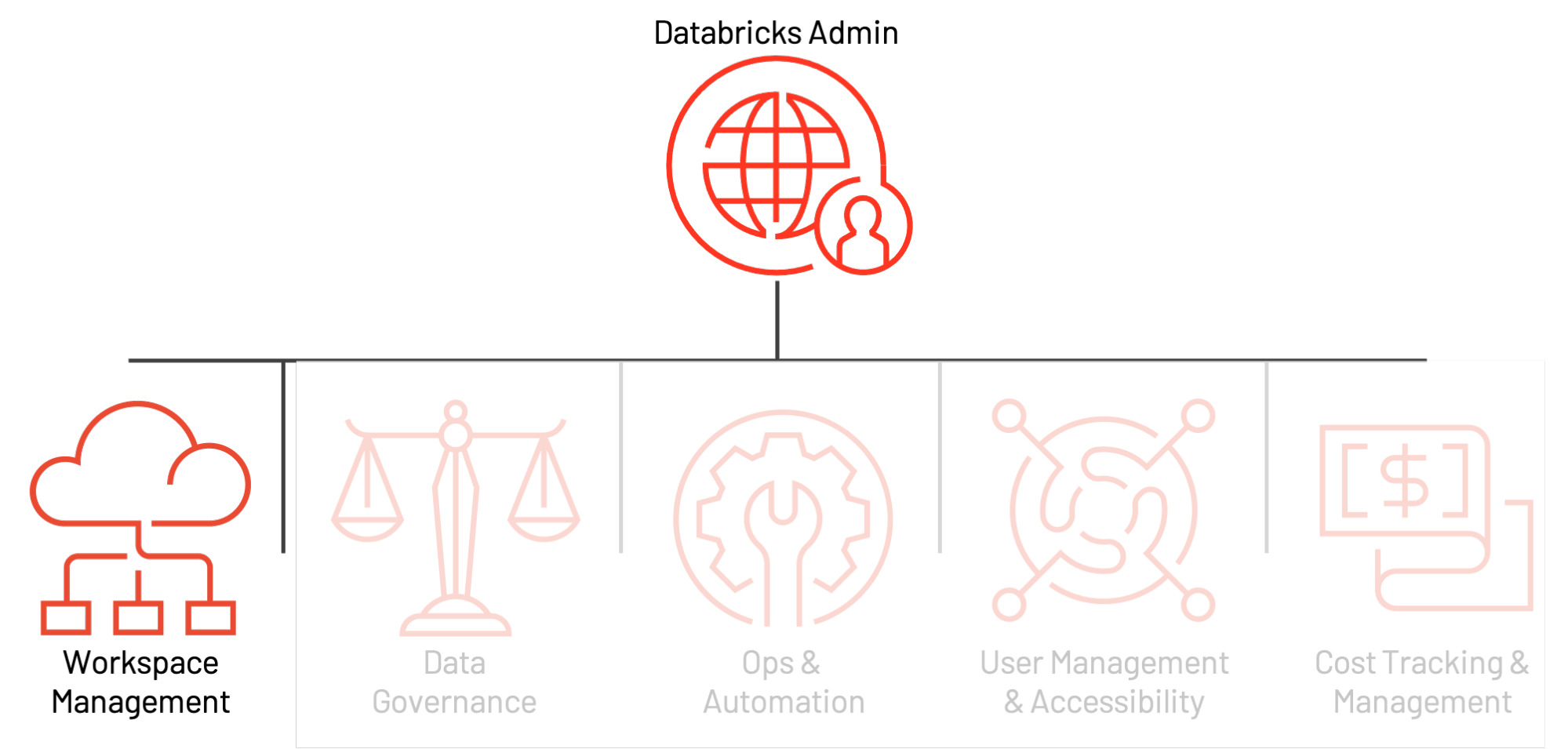
Bases de l'organisation de l'espace de travail
Bien que chaque fournisseur de cloud (AWS, Azure et GCP) ait une architecture sous-jacente différente, l'organisation des espaces de travail Databricks entre les clouds est similaire. La construction logique de plus haut niveau est un compte maître E2 (AWS) ou un objet d'abonnement (Azure Databricks/GCP). Dans AWS, nous provisionnons un seul compte E2 par organisation qui fournit une vue et un contrôle unifiés à tous les espaces de travail. De cette façon, votre activité d'administration est centralisée, avec la possibilité d'activer le SSO, les Journaux d'audit et Unity Catalog. Azure a relativement moins de restrictions sur la création d'objets d'abonnement de haut niveau ; cependant, nous recommandons toujours que le nombre d'abonnements de haut niveau utilisés pour créer des espaces de travail Databricks soit contrôlé autant que possible. Nous ferons référence à la construction de haut niveau comme un compte tout au long de ce blog, qu'il s'agisse d'un compte AWS E2 ou d'un abonnement GCP/Azure.
Dans un compte de haut niveau, plusieurs espaces de travail peuvent être créés. Le maximum recommandé d'espaces de travail par compte est compris entre 20 et 50 sur Azure, avec une limite stricte sur AWS. Cette limite découle de la surcharge administrative qui résulte d'un nombre croissant d'espaces de travail : la gestion de la collaboration, de l'accès et de la sécurité sur des centaines d'espaces de travail peut devenir une tâche extrêmement difficile, même avec des processus d'automatisation exceptionnels. Ci-dessous, nous présentons un modèle d'objet de haut niveau d'un compte Databricks.
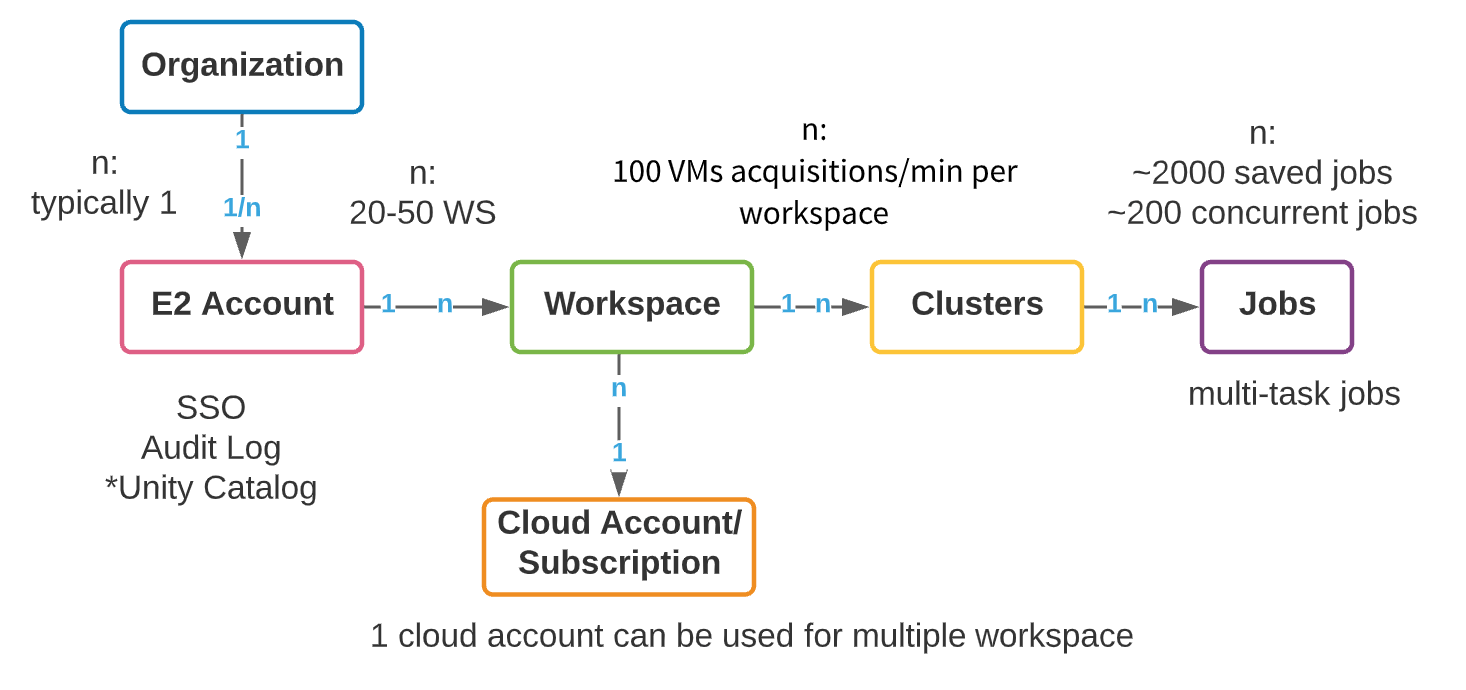
Les entreprises doivent créer des ressources dans leur compte cloud pour répondre aux exigences de multi-location. La création de comptes cloud et d'espaces de travail distincts pour chaque nouveau cas d'utilisation présente des avantages évidents : facilité de suivi des coûts, isolation des données et des utilisateurs, et un rayon d'impact plus faible en cas d'incidents de sécurité. Cependant, la prolifération des comptes entraîne son propre ensemble de complexités – la gouvernance, la gestion des métadonnées et la surcharge de collaboration augmentent avec le nombre de comptes. La clé, bien sûr, est l'équilibre. Ci-dessous, nous examinerons d'abord quelques considérations générales pour l'organisation des espaces de travail d'entreprise ; ensuite, nous examinerons deux stratégies courantes d'isolation des espaces de travail que nous observons chez nos clients : basées sur les LOB (Lignes d'activité) et basées sur les produits. Chacune a ses forces, ses faiblesses et ses complexités que nous discuterons avant de donner les meilleures pratiques.
Considérations générales sur l'organisation de l'espace de travail
Lors de la conception de votre stratégie d'espace de travail, la première chose que nous voyons souvent les clients aborder est les choix organisationnels de macro-niveau ; cependant, il existe de nombreuses décisions de niveau inférieur qui sont tout aussi importantes ! Nous avons compilé les plus pertinentes ci-dessous.
Une approche simple à trois espaces de travail
Bien que nous passions la majeure partie de ce blog à parler de la manière de diviser vos espaces de travail pour une efficacité maximale, il existe une catégorie entière de clients Databricks pour lesquels un seul espace de travail unifié par environnement est plus que suffisant ! En fait, cela est devenu de plus en plus pratique avec l'essor de fonctionnalités telles que Repos, Unity Catalog, les pages d'accueil basées sur les personas, etc. Dans de tels cas, nous recommandons toujours la séparation des espaces de travail de Développement, de Staging et de Production à des fins de validation et d'assurance qualité. Cela crée un environnement idéal pour les petites entreprises ou les équipes qui privilégient l'agilité à la complexité.
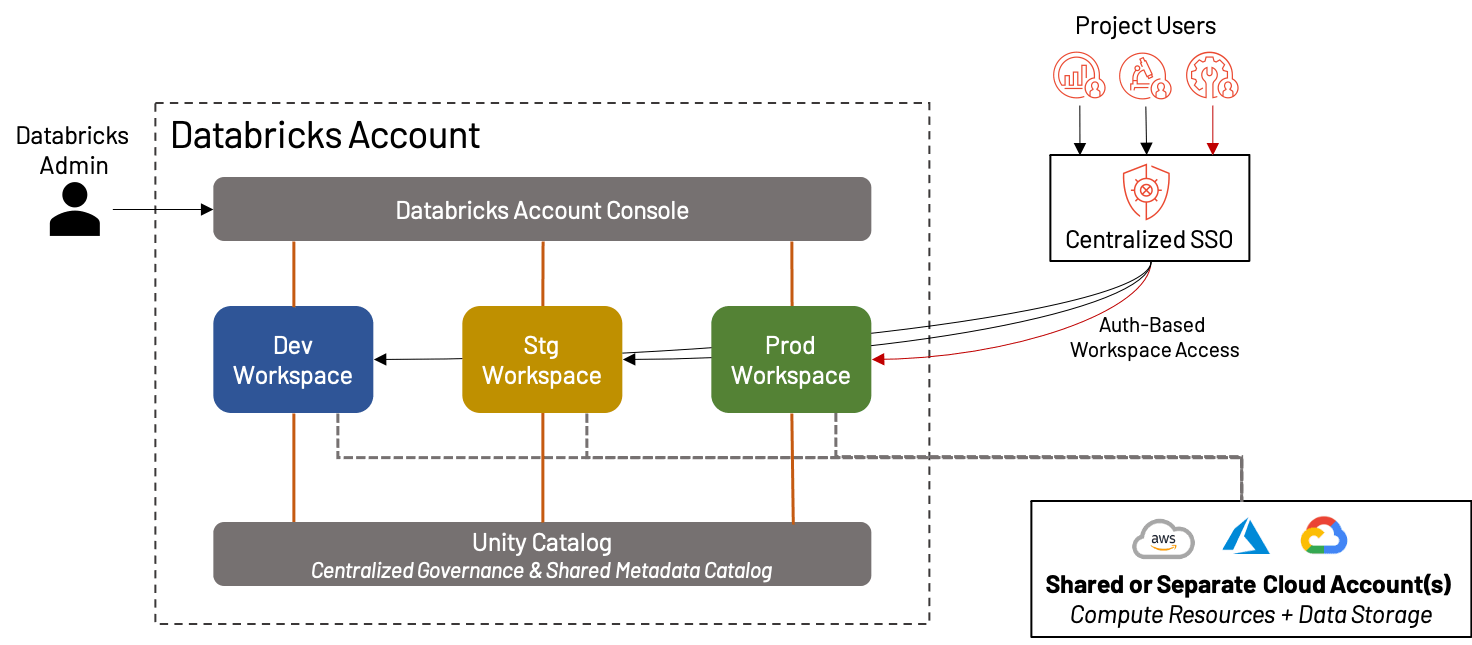
Les avantages et les inconvénients de la création d'un seul ensemble d'espaces de travail sont les suivants :
+ Il n'y a aucun souci de désordre interne de l'espace de travail, de mélange d'actifs, ou de dilution des coûts/de l'utilisation entre plusieurs projets/équipes ; tout est dans le même environnement
+ La simplicité de l'organisation signifie une surcharge administrative réduite
- Pour les organisations plus importantes, un seul espace de travail dev/stg/prd est intenable en raison des limites de la plateforme, du désordre, de l'incapacité à isoler les données et des préoccupations de gouvernance
Si un seul ensemble d'espaces de travail semble être la bonne approche pour vous, les meilleures pratiques suivantes vous aideront à maintenir votre Lakehouse en bon état de fonctionnement :
- Définissez un processus standardisé pour pousser le code entre les différents environnements ; comme il n'y a qu'un seul ensemble d'environnements, cela peut être plus simple qu'avec d'autres approches. Tirez parti de fonctionnalités telles que Repos et Secrets et d'outils externes qui favorisent de bons processus CI/CD pour vous assurer que vos transitions se déroulent automatiquement et en douceur.
- Établissez et examinez régulièrement les groupes de fournisseurs d'identité qui sont mappés aux actifs Databricks ; comme ces groupes sont le principal moteur de l'autorisation des utilisateurs dans cette stratégie, il est crucial qu'ils soient exacts et qu'ils correspondent aux ressources de données et de calcul sous-jacentes appropriées. Par exemple, la plupart des utilisateurs n'ont probablement pas besoin d'accéder à l'espace de travail de production ; seule une petite poignée d'ingénieurs ou d'administrateurs peuvent avoir les autorisations.
- Surveillez votre utilisation et connaissez les limites de ressources Databricks ; si l'utilisation de votre espace de travail ou le nombre d'utilisateurs commence à augmenter, vous devrez peut-être envisager d'adopter une stratégie d'organisation d'espace de travail plus élaborée pour éviter les limites par espace de travail. Exploitez le marquage des ressources dans la mesure du possible afin de suivre les coûts et les métriques d'utilisation.
Utilisation des espaces de travail sandbox
Dans toutes les stratégies mentionnées dans cet article, un environnement sandbox est une bonne pratique pour permettre aux utilisateurs d'incuber et de développer des travaux moins formels, mais potentiellement précieux. De manière critique, ces environnements sandbox doivent équilibrer la liberté d'explorer des données réelles avec la protection contre l'impact involontaire (ou intentionnel) des charges de travail de production. Une bonne pratique courante pour de tels espaces de travail est de les héberger dans un compte cloud entièrement séparé ; cela limite considérablement le rayon d'impact des utilisateurs dans l'espace de travail. Dans le même temps, la mise en place de garde-fous simples (tels que les politiques de cluster, la limitation de l'accès aux données aux ensembles de données « de jeu » ou nettoyés, et la fermeture de la connectivité sortante dans la mesure du possible) signifie que les utilisateurs peuvent avoir une liberté relative pour faire (presque) tout ce qu'ils veulent sans avoir besoin d'une supervision constante de l'administrateur. Enfin, la communication interne est tout aussi importante ; si les utilisateurs créent involontairement une application incroyable dans le Sandbox qui attire des milliers d'utilisateurs, ou s'attendent à un support de niveau production pour leur travail dans cet environnement, ces économies administratives s'évaporeront rapidement.
Les bonnes pratiques pour les espaces de travail sandbox incluent :
- Utilisez un compte cloud distinct qui ne contient pas de données sensibles ou de production.
- Mettez en place des garde-fous simples afin que les utilisateurs puissent avoir une liberté relative sur l'environnement sans avoir besoin de la supervision de l'administrateur.
- Communiquez clairement que l'environnement sandbox est « en libre-service ».
Isolation et sensibilité des données
Les données sensibles prennent de plus en plus d'importance parmi nos clients dans tous les secteurs ; les données qui étaient autrefois limitées aux prestataires de soins de santé ou aux processeurs de cartes de crédit deviennent maintenant la source pour comprendre l'analyse des patients ou le sentiment des clients, analyser les marchés émergents, positionner de nouveaux produits, et presque tout ce que vous pouvez imaginer. Cette richesse de données comporte un risque élevé, avec des menaces croissantes de violations de données ; pour cette raison, il est important de garder les données sensibles séparées et protégées, quelle que soit la stratégie organisationnelle que vous choisissez. Databricks fournit plusieurs moyens de protéger les données sensibles (telles que les ACL et le partage sécurisé), et combiné avec les outils du fournisseur cloud, peut rendre le Lakehouse que vous construisez aussi peu risqué que possible. Certaines des meilleures pratiques en matière d'isolation et de sensibilité des données incluent :
- Comprenez vos besoins uniques en matière de sécurité des données ; c'est le point le plus important. Chaque entreprise a des données différentes, et vos données dicteront votre gouvernance.
- Appliquez des politiques et des contrôles à la fois au niveau du stockage et au niveau du metastore. Les politiques S3 et les ACL ADLS doivent toujours être appliquées selon le principe du moindre privilège. Exploitez Unity Catalog pour appliquer une couche de contrôle supplémentaire sur l'accès aux données.
- Séparez vos données sensibles des données non sensibles, à la fois logiquement et physiquement ; de nombreux clients utilisent des comptes cloud entièrement séparés (et des espaces de travail Databricks) pour les données sensibles et non sensibles.
DR et sauvegarde régionale
La reprise après sinistre (DR) est un sujet vaste et important, que vous utilisiez AWS, Azure ou GCP ; nous ne couvrirons pas tout dans ce blog, mais nous nous concentrerons plutôt sur la manière dont les considérations DR et régionales s'intègrent dans la conception des espaces de travail. Dans ce contexte, DR implique la création et la maintenance d'un espace de travail dans une région distincte de l'espace de travail de production standard.
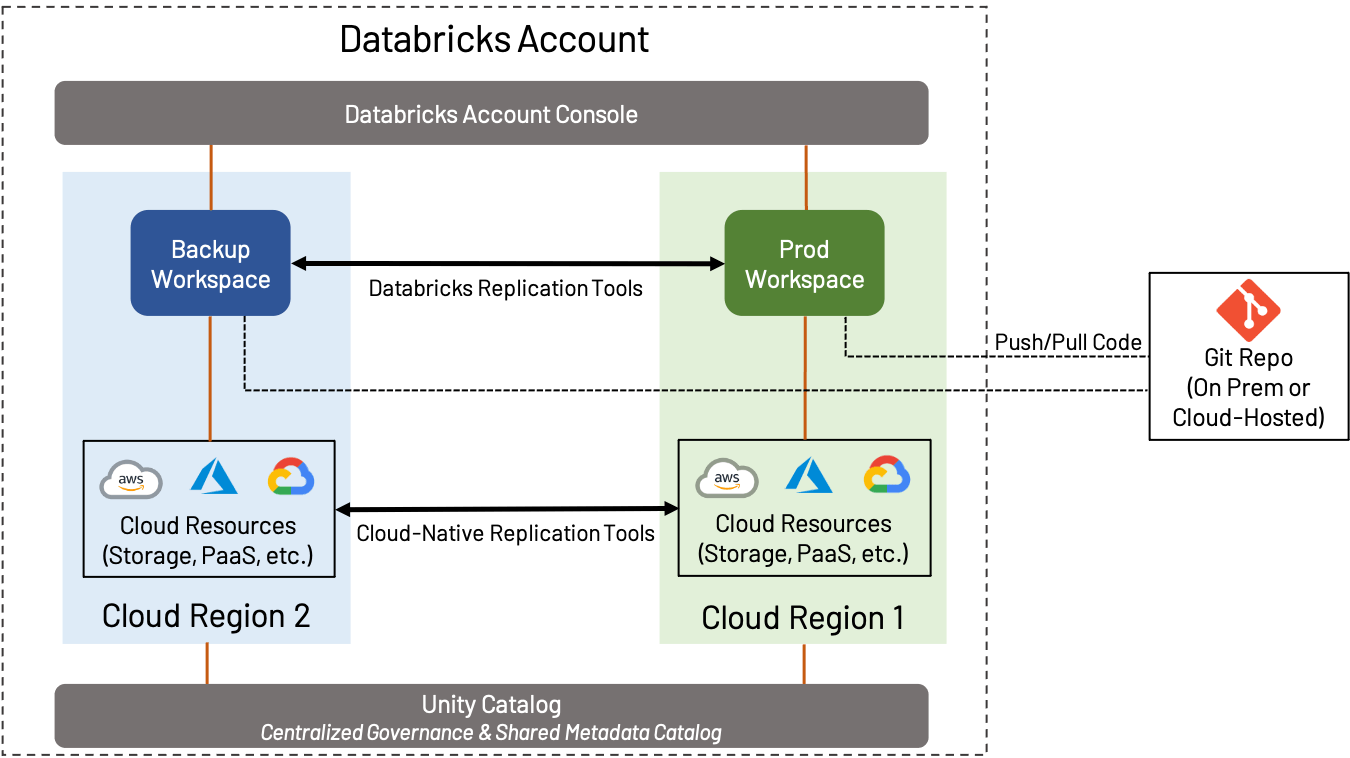
La stratégie DR peut varier considérablement en fonction des besoins de l'entreprise. Par exemple, certains clients préfèrent maintenir une configuration active-active, où tous les actifs d'un espace de travail sont constamment répliqués vers un espace de travail secondaire ; cela offre le maximum de redondance, mais implique également une complexité et un coût (le transfert constant de données entre régions et la réplication et déduplication d'objets est un processus compliqué). D'un autre côté, certains clients préfèrent faire le minimum nécessaire pour assurer la continuité des activités ; un espace de travail secondaire peut contenir très peu jusqu'à ce que le basculement se produise, ou peut être sauvegardé uniquement occasionnellement. Déterminer le bon niveau de basculement est crucial.
Quel que soit le niveau de DR que vous choisissez de mettre en œuvre, nous recommandons ce qui suit :
- Stockez le code dans un référentiel Git de votre choix, soit sur site, soit dans le cloud, et utilisez des fonctionnalités telles que Repos pour le synchroniser avec Databricks dans la mesure du possible.
- Dans la mesure du possible, utilisez Delta Lake en conjonction avec Deep Clone pour répliquer les données ; cela offre un moyen facile et open-source de sauvegarder efficacement les données.
- Utilisez les outils natifs du cloud fournis par votre fournisseur de cloud pour sauvegarder des éléments tels que les données non stockées dans Delta Lake, les bases de données externes, les configurations, etc.
- Utilisez des outils tels que Terraform pour sauvegarder des objets tels que les notebooks, les tâches, les secrets, les clusters et d'autres objets d'espace de travail.
Rappelez-vous : Databricks est responsable de la maintenance de l'infrastructure régionale des espaces de travail dans le plan de contrôle, mais vous êtes responsable de vos actifs spécifiques à l'espace de travail, ainsi que de l'infrastructure cloud sur laquelle reposent vos tâches de production.
Isolation par ligne de métier (LOB)
Nous abordons maintenant l'organisation réelle des espaces de travail dans un contexte d'entreprise. L'isolation des projets basée sur les LOB découle de la manière traditionnelle de considérer les ressources informatiques du point de vue de l'entreprise – elle comporte également de nombreuses forces (et faiblesses) traditionnelles de l'alignement centré sur les LOB. En tant que tel, pour de nombreuses grandes entreprises, cette approche de la gestion des espaces de travail sera naturelle.
Dans une stratégie d'espace de travail basée sur les LOB, chaque unité fonctionnelle d'une entreprise recevra un ensemble d'espaces de travail ; traditionnellement, cela inclura les espaces de travail de développement, de staging et de production, bien que nous ayons vu des clients avec jusqu'à 10 étapes intermédiaires, chacune potentiellement avec son propre espace de travail (non recommandé) ! Le code est écrit et testé en DEV, puis promu (via l'automatisation CI/CD) en STG, et atterrit finalement en PRD, où il s'exécute comme une tâche planifiée jusqu'à être déprécié. Le type d'environnement et le LOB indépendant sont les principales raisons d'initier un nouvel espace de travail dans ce modèle ; le faire pour chaque cas d'utilisation ou produit de données peut être excessif.
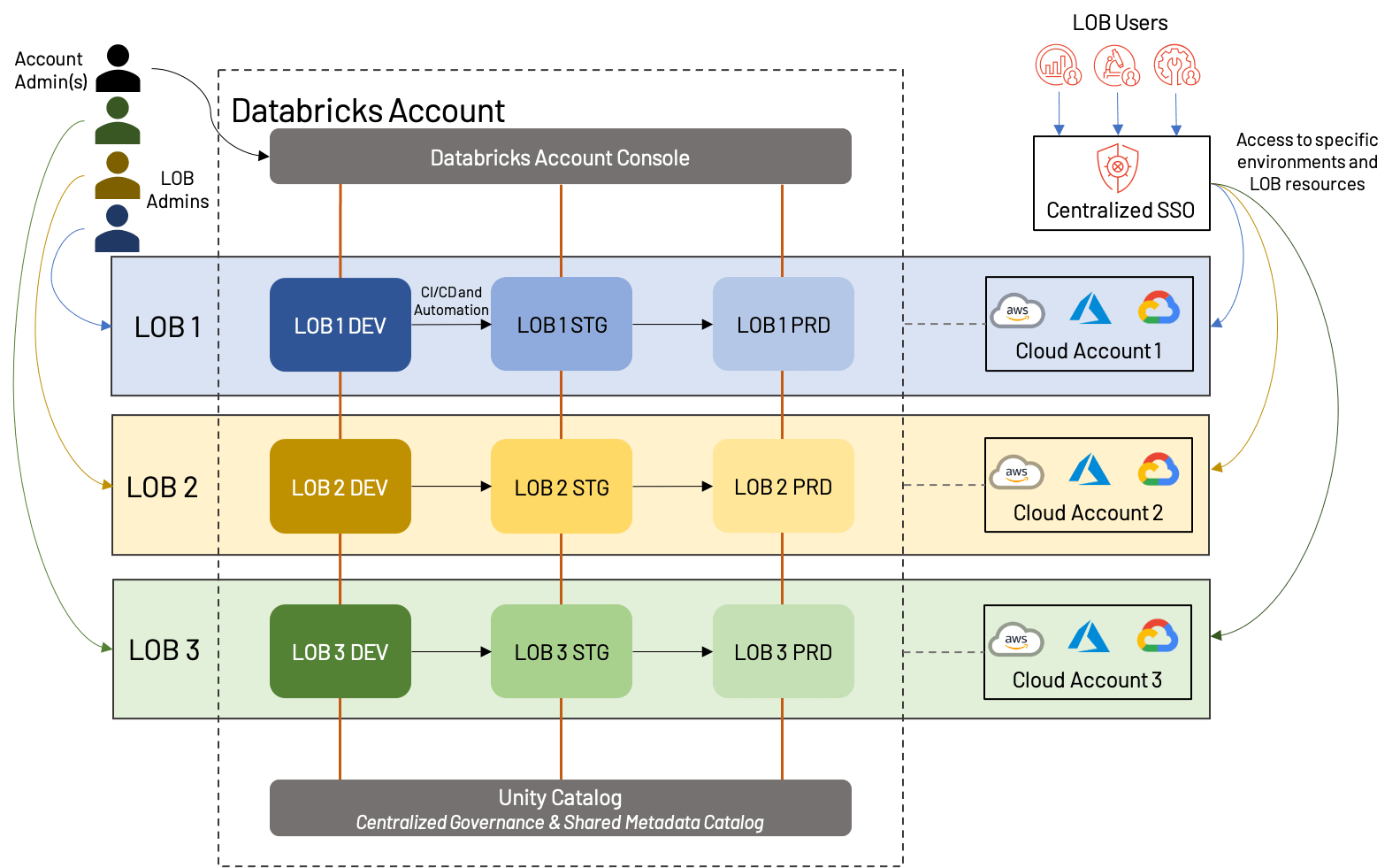
Le diagramme ci-dessus montre une façon potentielle dont l'espace de travail basé sur les LOB peut être structuré ; dans ce cas, chaque LOB a un compte cloud séparé avec un espace de travail dans chaque environnement (dev/stg/prd) et a également un administrateur dédié. Fait important, tous ces espaces de travail relèvent du même compte Databricks et exploitent le même Unity Catalog. Certaines variations incluraient le partage de comptes cloud (et potentiellement des ressources sous-jacentes telles que les VPC et les services cloud), l'utilisation d'un compte cloud dev/stg/prd séparé, ou la création de metastores externes séparés pour chaque LOB. Ce sont toutes des approches raisonnables qui dépendent fortement des besoins de l'entreprise.
Dans l'ensemble, l'approche LOB présente un certain nombre d'avantages, ainsi que quelques inconvénients :
+Les actifs de chaque LOB peuvent être isolés, tant du point de vue du cloud que de celui de l'espace de travail ; cela simplifie le reporting/l'analyse des coûts, et rend l'espace de travail moins encombré.
+Une division claire des utilisateurs et des rôles améliore la gouvernance globale du Lakehouse et réduit le risque global.
+L'automatisation de la promotion entre les environnements crée un processus efficace et à faible surcharge.
-Une planification préalable est nécessaire pour garantir que les processus inter-LOB sont standardisés et que le compte Databricks global n'atteindra pas les limites de la plateforme.
-L'automatisation et les processus administratifs nécessitent des spécialistes pour leur mise en place et leur maintenance.
En tant que meilleures pratiques, nous recommandons ce qui suit à ceux qui construisent des Lakehouses basés sur les LOB :
- Adoptez un modèle d'accès basé sur le moindre privilège en utilisant un contrôle d'accès granulaire pour les utilisateurs et les environnements ; en général, très peu d'utilisateurs devraient avoir un accès en production, et les interactions avec cet environnement devraient être automatisées et hautement contrôlées. Capturez ces utilisateurs et groupes dans votre fournisseur d'identité et synchronisez-les avec le Lakehouse.
- Comprenez et planifiez les limites du fournisseur de cloud et de la plateforme Databricks ; celles-ci incluent, par exemple, le nombre d'espaces de travail, la limitation du débit des API sur ADLS, la limitation des flux Kinesis, etc.
- Utilisez un metastore/catalogue standardisé avec de solides contrôles d'accès dans la mesure du possible ; cela permet la réutilisation des actifs sans compromettre l'isolation. Unity Catalog permet des contrôles granulaires sur les tables et les actifs de l'espace de travail, y compris des objets tels que les expériences MLflow.
- Exploitez le partage de données autant que possible pour partager des données en toute sécurité entre les LOB sans avoir à dupliquer les efforts.
Isolation des produits de données
Que faisons-nous lorsque les LOB doivent collaborer de manière interfonctionnelle, ou lorsqu'un simple modèle dev/stg/prd ne correspond pas aux cas d'utilisation de notre LOB ? Nous pouvons abandonner une partie de la formalité d'une structure stricte de Lakehouse basée sur les LOB et adopter une approche légèrement plus moderne ; nous appelons cela l'isolation des espaces de travail par Produit de Données. Le concept est qu'au lieu d'isoler strictement par LOB, nous isolons plutôt par projets de haut niveau, en donnant à chacun un environnement de production. Nous mélangeons également des environnements de développement partagés pour éviter la prolifération des espaces de travail et simplifier la réutilisation des actifs.
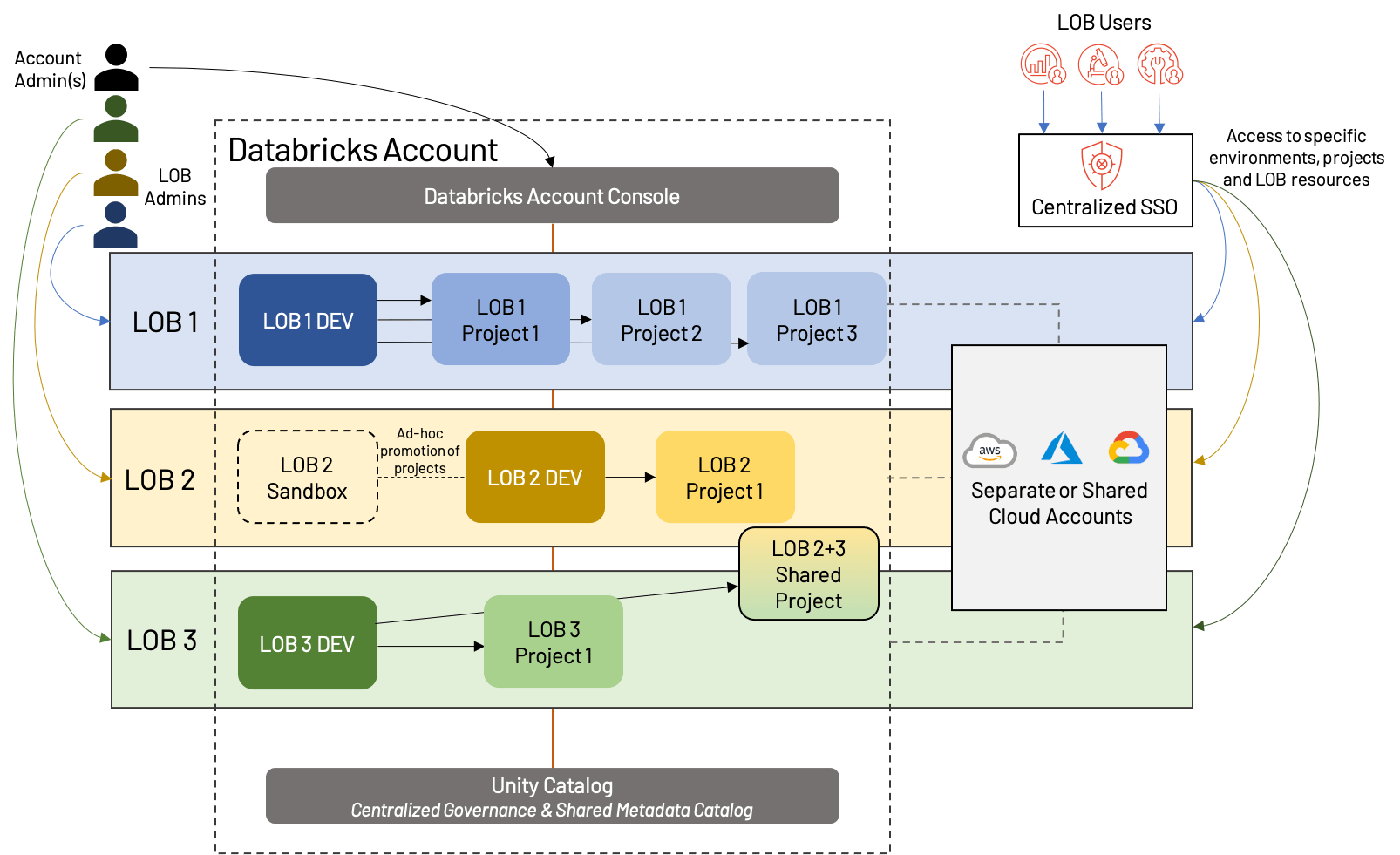
À première vue, cela ressemble à l'isolation basée sur les LOB ci-dessus, mais il y a quelques distinctions importantes :
- Un espace de travail de développement partagé, avec des espaces de travail séparés pour chaque projet de haut niveau (ce qui signifie que chaque LOB peut avoir un nombre différent d'espaces de travail au total)
- La présence d'espaces de travail sandbox, qui sont spécifiques à un LOB et offrent plus de liberté et moins d'automatisation que les espaces de travail de développement traditionnels
- Le partage de ressources et/ou d'espaces de travail ; cela est également possible dans les architectures basées sur les LOB, mais est souvent compliqué par une séparation plus rigide
Cette approche partage bon nombre des mêmes forces et faiblesses que l'isolation basée sur les LOB, mais offre plus de flexibilité et souligne la valeur des projets dans le Lakehouse moderne. De plus en plus, nous voyons cela devenir la « norme d'excellence » en matière d'organisation des espaces de travail, correspondant au mouvement de la technologie d'un moteur de coûts à un générateur de valeur. Comme toujours, les besoins de l'entreprise peuvent entraîner de légères déviations par rapport à cette architecture type, telles que des environnements dev/stg/prd dédiés pour des projets particulièrement importants, des projets inter-LOB, une ségrégation plus ou moins importante des ressources cloud, etc. Quelle que soit la structure exacte, nous suggérons les meilleures pratiques suivantes :
- Partagez les données et les ressources autant que possible ; bien que la ségrégation de l'infrastructure et des espaces de travail soit utile pour la gouvernance et le suivi, la prolifération des ressources devient rapidement un fardeau. Une analyse minutieuse préalable aidera à identifier les domaines de réutilisation.
- Même lorsque vous ne partagez pas extensivement entre les projets, utilisez un metastore partagé tel que Unity Catalog, et des bases de code partagées (via, par exemple, Repos) lorsque cela est possible.
- Utilisez Terraform (ou des outils similaires) pour automatiser le processus de création, de gestion et de suppression des espaces de travail et de l'infrastructure cloud.
- Offrez de la flexibilité aux utilisateurs via des environnements sandbox, mais assurez-vous qu'ils disposent de garde-fous appropriés pour limiter la taille des clusters, l'accès aux données, etc.
Résumé
Pour tirer pleinement parti de tous les avantages du Lakehouse et soutenir la croissance et la maintenabilité futures, il convient de planifier la disposition des espaces de travail. D'autres artefacts associés qui doivent être pris en compte lors de cette conception comprennent un registre de modèles centralisé, une base de code et un catalogue pour faciliter la collaboration sans compromettre la sécurité. Pour résumer certaines des meilleures pratiques mises en évidence dans cet article, nos principaux points à retenir sont énumérés ci-dessous :
Meilleure Pratique #1 : Minimisez le nombre de comptes de haut niveau (tant au niveau du fournisseur de cloud que de Databricks) autant que possible, et créez un espace de travail uniquement lorsque la séparation est nécessaire pour des contraintes de conformité, d'isolement ou géographiques. En cas de doute, restez simple !
Meilleure Pratique #2 : Décidez d'une stratégie d'isolation qui vous offrira une flexibilité à long terme sans complexité excessive. Soyez réaliste quant à vos besoins et mettez en œuvre des directives strictes avant de commencer à intégrer des charges de travail à votre Lakehouse ; en d'autres termes, mesurez deux fois, coupez une fois !
Meilleure Pratique #3 : Automatisez vos processus cloud. Cela couvre tous les aspects de votre infrastructure (dont beaucoup seront abordés dans les prochains articles de blog !), y compris l'authentification unique/SCIM, l'Infrastructure-as-Code avec un outil tel que Terraform, les pipelines CI/CD et les Repos, la sauvegarde cloud et la surveillance (en utilisant des outils natifs au cloud et tiers).
Meilleure Pratique #4 : Envisagez d'établir une équipe COE (Center of Excellence) pour la gouvernance centrale d'une stratégie d'entreprise, où les aspects répétables d'un pipeline de données et d'apprentissage automatique sont mis en modèle et automatisés afin que différentes équipes de données puissent utiliser des capacités en libre-service avec suffisamment de garde-fous en place. L'équipe COE est souvent un hub léger mais essentiel pour les équipes de données et devrait se considérer comme un facilitateur, en maintenant la documentation, les procédures opérationnelles normalisées, les guides pratiques et les FAQ pour éduquer les autres utilisateurs.
Meilleure Pratique #5 : Le Lakehouse offre un niveau de gouvernance que le Data Lake n'offre pas ; profitez-en ! Évaluez vos besoins en matière de conformité et de gouvernance comme l'une des premières étapes de la mise en place de votre Lakehouse, et exploitez les fonctionnalités fournies par Databricks pour minimiser les risques. Cela inclut la livraison des journaux d'audit, la conformité HIPAA et PCI (le cas échéant), des contrôles d'exfiltration appropriés, l'utilisation des ACL et des contrôles utilisateurs, et un examen régulier de tout ce qui précède.
Nous publierons d'autres articles de blog sur les meilleures pratiques d'administration dans un avenir proche, sur des sujets allant de la gouvernance des données à la gestion des utilisateurs. En attendant, contactez votre équipe de compte Databricks si vous avez des questions sur la gestion des espaces de travail, ou si vous souhaitez en savoir plus sur les meilleures pratiques de la plateforme Databricks Lakehouse !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.