Évaluation des modèles dans MLflow
par Mark Zhang
De nombreux data scientists et ingénieurs ML utilisent aujourd'hui MLflow pour gérer leurs modèles. MLflow est une plateforme open-source qui permet aux utilisateurs de gouverner tous les aspects du cycle de vie ML, y compris, mais sans s'y limiter, l'expérimentation, la reproductibilité, le déploiement et le registre de modèles. Une étape critique lors du développement de modèles ML est l'évaluation de leurs performances sur de nouveaux jeux de données.
Motivation
Pourquoi évaluons-nous les modèles ?
L'évaluation des modèles fait partie intégrante du cycle de vie ML. Elle permet aux data scientists de mesurer, interpréter et expliquer les performances de leurs modèles. Elle accélère le délai de développement des modèles en fournissant des informations sur comment et pourquoi les modèles performent comme ils le font. En particulier, à mesure que la complexité des modèles ML augmente, la capacité d'observer et de comprendre rapidement les performances des modèles ML est essentielle dans un parcours de développement ML réussi.
État de l'évaluation des modèles dans MLflow
Actuellement, de nombreux utilisateurs évaluent les performances de leurs modèles MLflow de la saveur de modèle python_function (pyfunc) via l'API mlflow.evaluate, qui prend en charge l'évaluation des modèles de classification et de régression. Elle calcule et enregistre un ensemble de métriques de performance spécifiques à la tâche, de tracés de performance de modèle et d'explications de modèle sur le serveur MLflow Tracking.
Pour évaluer les modèles MLflow par rapport à des métriques personnalisées non incluses dans l'ensemble de métriques d'évaluation intégrées, les utilisateurs devraient définir un plugin d'évaluateur de modèle personnalisé. Cela impliquerait de créer une classe d'évaluateur personnalisée qui implémente l'interface ModelEvaluator, puis d'enregistrer un point d'entrée d'évaluateur dans le cadre d'un plugin MLflow. Cette rigidité et cette complexité pourraient être rédhibitoires pour les utilisateurs.
Selon une enquête interne auprès des clients, 75 % des répondants déclarent utiliser fréquemment ou toujours des métriques spécialisées axées sur les affaires en plus des métriques de base comme la précision et la perte. Les data scientists utilisent souvent ces métriques personnalisées car elles sont plus descriptives des objectifs commerciaux (par exemple, le taux de conversion) et contiennent des heuristiques supplémentaires non capturées par la prédiction du modèle elle-même.
Dans ce blog, nous présentons un moyen simple et pratique d'évaluer les modèles MLflow sur des métriques personnalisées définies par l'utilisateur. Avec cette fonctionnalité, un data scientist peut facilement intégrer cette logique à l'étape d'évaluation du modèle et déterminer rapidement le modèle le plus performant sans analyse en aval supplémentaire.
*Note : Dans MLflow 2.4, mlflow.evaluate est étendu pour prendre en charge les modèles LLM de texte, de résumé de texte et de questions-réponses
Utilisation
Métriques intégrées
MLflow intègre un ensemble de métriques couramment utilisées pour la performance et l'explication des modèles pour les modèles de classification et de régression. L'évaluation des modèles sur ces métriques est simple. Il suffit de créer un jeu de données d'évaluation contenant les données de test et les cibles, puis d'appeler mlflow.evaluate.
Selon le type de modèle, différentes métriques sont calculées. Référez-vous à la section Comportement de l'évaluateur par défaut sous la documentation de l'API de mlflow.evaluate pour les informations les plus récentes concernant les métriques intégrées.
Exemple
Voici un exemple simple d'évaluation d'un modèle MLflow de classification avec des métriques intégrées.
D'abord, importez les bibliothèques nécessaires
Ensuite, nous divisons le jeu de données, ajustons le modèle et créons notre jeu de données d'évaluation
Enfin, nous démarrons une exécution MLflow et appelons mlflow.evaluate
Nous pouvons trouver les métriques et artefacts enregistrés dans l'interface utilisateur MLflow :
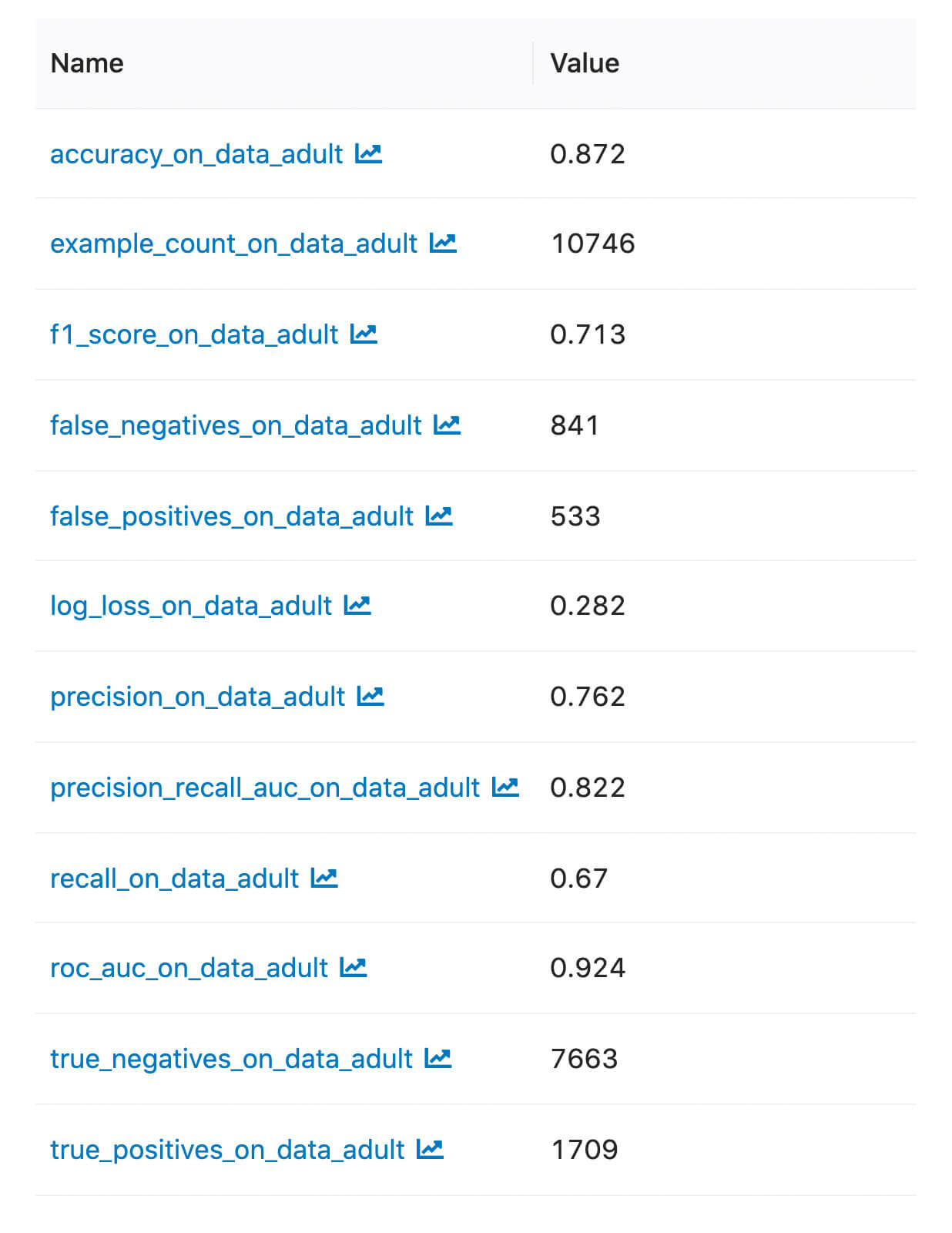
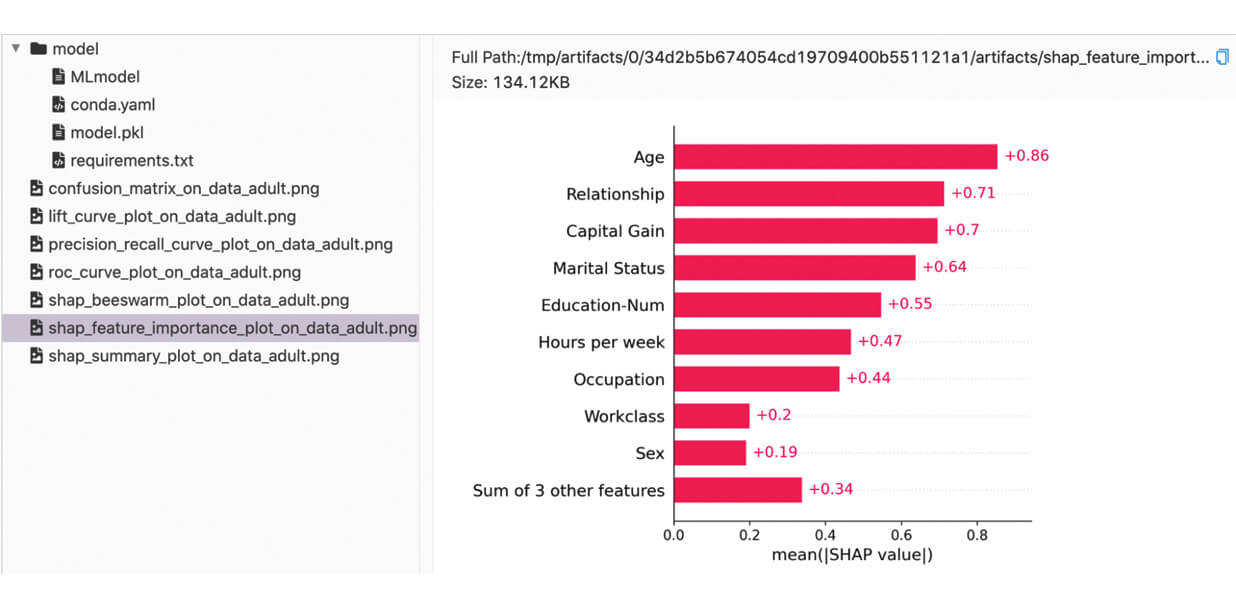
Métriques personnalisées
Pour évaluer un modèle par rapport à des métriques personnalisées, il suffit de passer une liste de fonctions de métriques personnalisées à l'API mlflow.evaluate.
Exigences de définition de fonction
Les fonctions de métriques personnalisées doivent accepter deux paramètres requis et un paramètre optionnel dans l'ordre suivant :
eval_df: un DataFrame Pandas ou Spark contenant une colonnepredictionet une colonnetarget.Par exemple, si la sortie du modèle est un vecteur de trois nombres, alors le DataFrame
eval_dfressemblerait à ceci :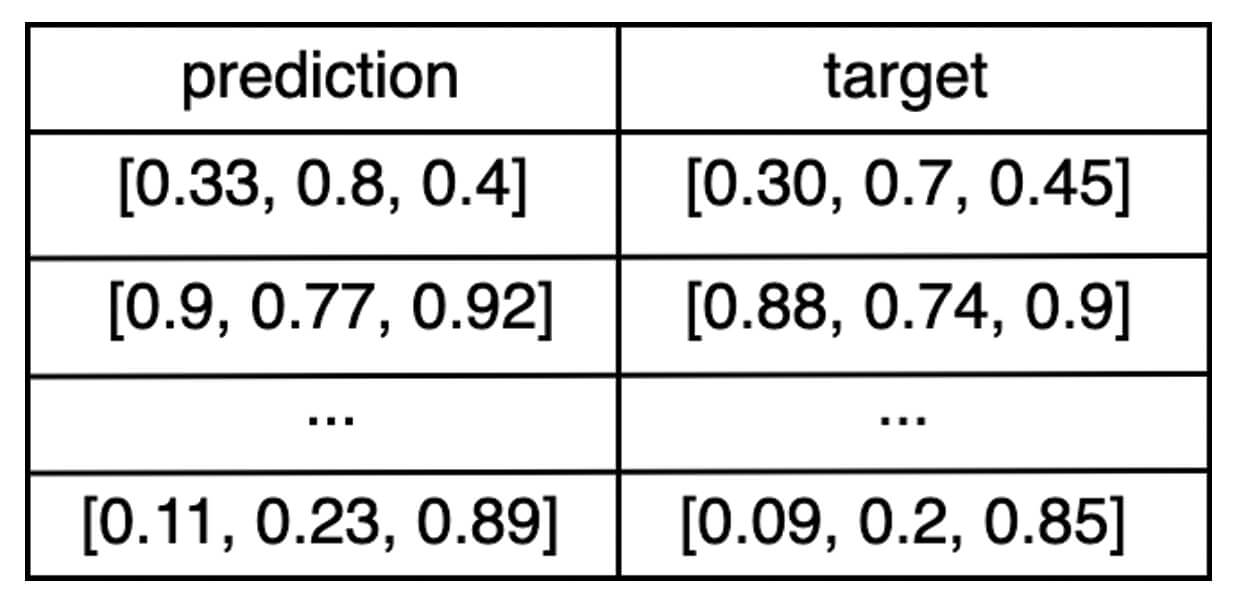
builtin_metrics: un dictionnaire contenant les métriques intégréesPar exemple, pour un modèle de régression,
builtin_metricsressemblerait à ceci :- (Optionnel)
artifacts_dir: chemin vers un répertoire temporaire qui peut être utilisé par la fonction de métrique personnalisée pour stocker temporairement les artefacts produits avant de les enregistrer dans MLflow.Par exemple, notez que cela sera différent selon la configuration spécifique de l'environnement. Par exemple, sur MacOS, cela ressemblerait à ceci :
Si des artefacts de fichiers sont stockés ailleurs qu'à
artifacts_dir, assurez-vous qu'ils persistent jusqu'à la fin de l'exécution demlflow.evaluate.
Exigences de la valeur de retour
La fonction doit retourner un dictionnaire représentant les métriques produites et peut éventuellement retourner un second dictionnaire représentant les artefacts produits. Pour les deux dictionnaires, la clé de chaque entrée représente le nom de la métrique ou de l'artefact correspondant.
Bien que chaque métrique doive être un scalaire, il existe diverses façons de définir des artefacts :
- Le chemin d'accès à un fichier artefact
- La représentation sous forme de chaîne d'un objet JSON
- Un DataFrame pandas
- Un tableau numpy
- Une figure matplotlib
- D'autres objets seront tentés d'être sérialisés avec le protocole par défaut
Consultez la documentation de mlflow.evaluate pour des détails de définition plus approfondis.
Exemple
Examinons un exemple concret qui utilise des métriques personnalisées. Pour cela, nous allons créer un modèle jouet à partir du jeu de données California Housing.
Ensuite, configurons notre jeu de données et notre modèle
Voici la partie intéressante : définir notre fonction de métriques personnalisées, et un artefact personnalisé ! !
Enfin, pour tout relier, nous allons démarrer une exécution MLflow et appeler mlflow.evaluate :
Les métriques et artefacts personnalisés enregistrés peuvent être trouvés aux côtés des métriques et artefacts par défaut. Les régions encadrées en rouge montrent les métriques et artefacts personnalisés enregistrés sur la page d'exécution.
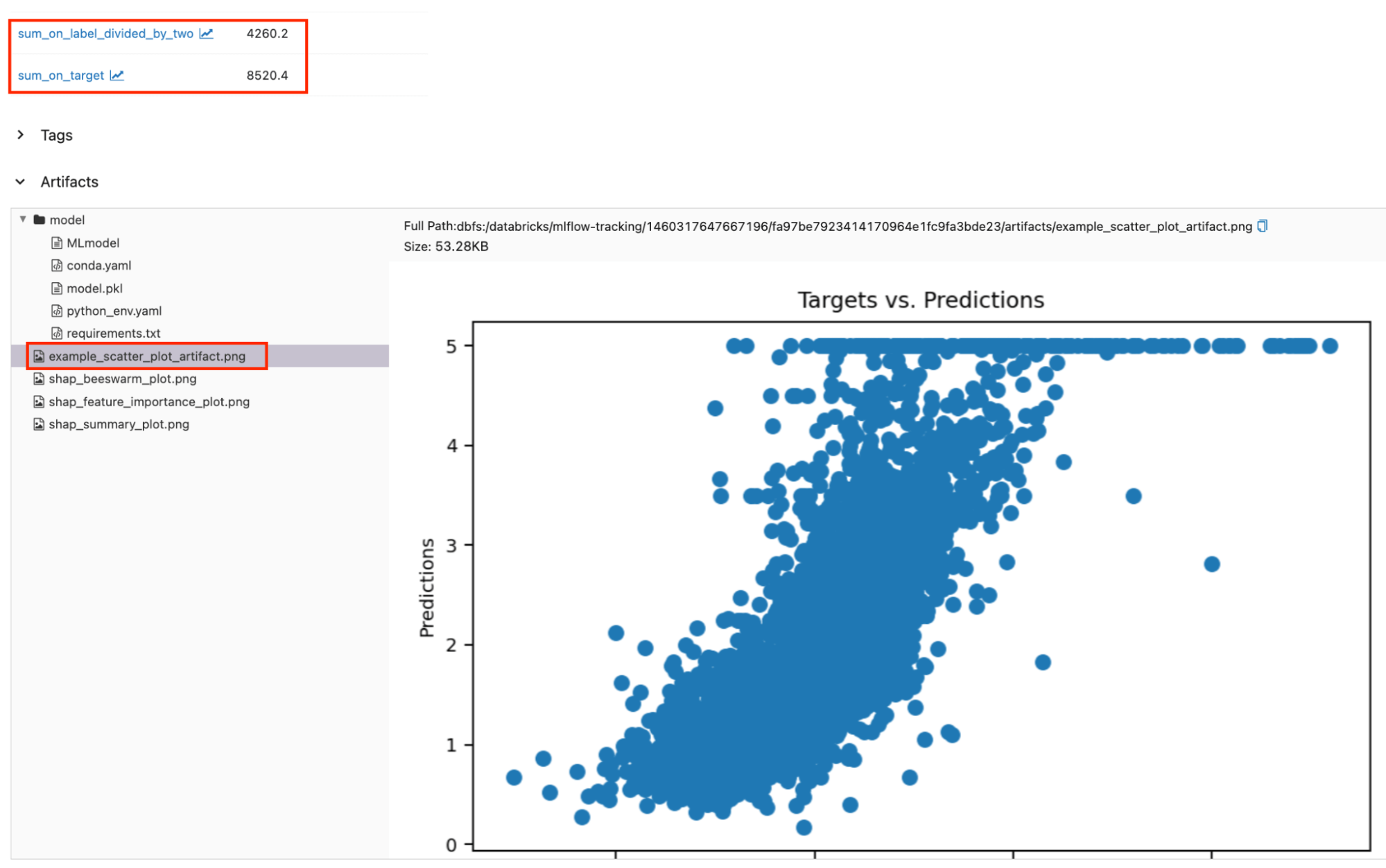
Accès aux résultats d'évaluation par programme
Jusqu'à présent, nous avons exploré les résultats d'évaluation pour les métriques intégrées et personnalisées dans l'interface utilisateur MLflow. Cependant, nous pouvons également y accéder par programme via l'objet EvaluationResult retourné par mlflow.evaluate. Continuons notre exemple de métriques personnalisées ci-dessus et voyons comment nous pouvons accéder à ses résultats d'évaluation par programme. (En supposant que result est notre instance EvaluationResult à partir d'ici).
Nous pouvons accéder à l'ensemble des métriques calculées via le dictionnaire result.metrics contenant à la fois le nom et les valeurs scalaires des métriques. Le contenu de result.metrics devrait ressembler à ceci :
De même, l'ensemble des artefacts est accessible via le dictionnaire result.artifacts. Les valeurs de chaque entrée sont un objet EvaluationArtifact. result.artifacts devrait ressembler à ceci :
Notebooks d'exemple
Sous le capot
Le schéma ci-dessous illustre le fonctionnement interne :
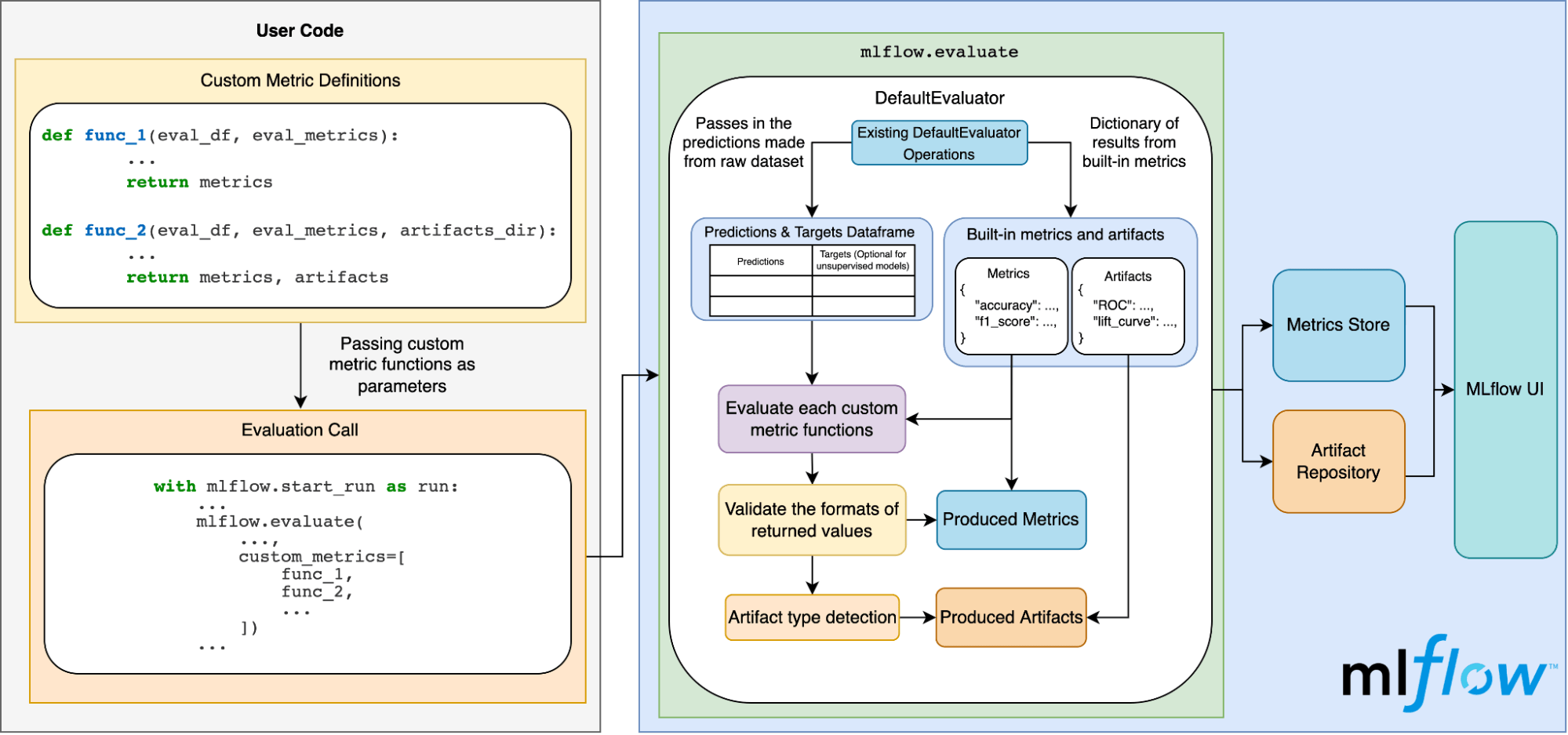
Conclusion
Dans cet article de blog, nous avons abordé :
- L'importance de l'évaluation des modèles et ce qui est actuellement pris en charge dans MLflow.
- Pourquoi il est important pour les utilisateurs de MLflow d'avoir un moyen simple d'intégrer des métriques personnalisées dans leurs modèles MLflow.
- Comment évaluer des modèles avec des métriques par défaut.
- Comment évaluer des modèles avec des métriques personnalisées.
- Comment MLflow gère l'évaluation des modèles en coulisses.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.