Les colonnes d'identité pour générer des clés substituts sont maintenant disponibles dans un Lakehouse près de chez vous !
par Franco Patano
Qu'est-ce qu'une colonne d'identité ?
Une colonne d'identité est une colonne dans une base de données qui génère automatiquement un numéro d'identification unique pour chaque nouvelle ligne de données. Ce numéro n'est pas lié au contenu de la ligne.
Les colonnes d'identité sont une forme de clés substituts. Dans les entrepôts de données, il est courant d'utiliser une clé supplémentaire, appelée clé substitut, pour identifier de manière unique chaque ligne et suivre les modifications des données au fil du temps. De plus, il est recommandé d'utiliser des clés substituts plutôt que des clés naturelles. Les clés substituts sont générées par le système et ne dépendent pas de plusieurs champs pour identifier l'unicité de la ligne.
Ainsi, les colonnes d'identité sont utilisées pour créer des clés substituts, qui peuvent servir de clés primaires et étrangères dans les modèles dimensionnels pour les entrepôts de données et les data marts. Comme on le voit ci-dessous, ces clés sont les colonnes qui relient différentes tables entre elles dans un modèle dimensionnel traditionnel comme un schéma en étoile.
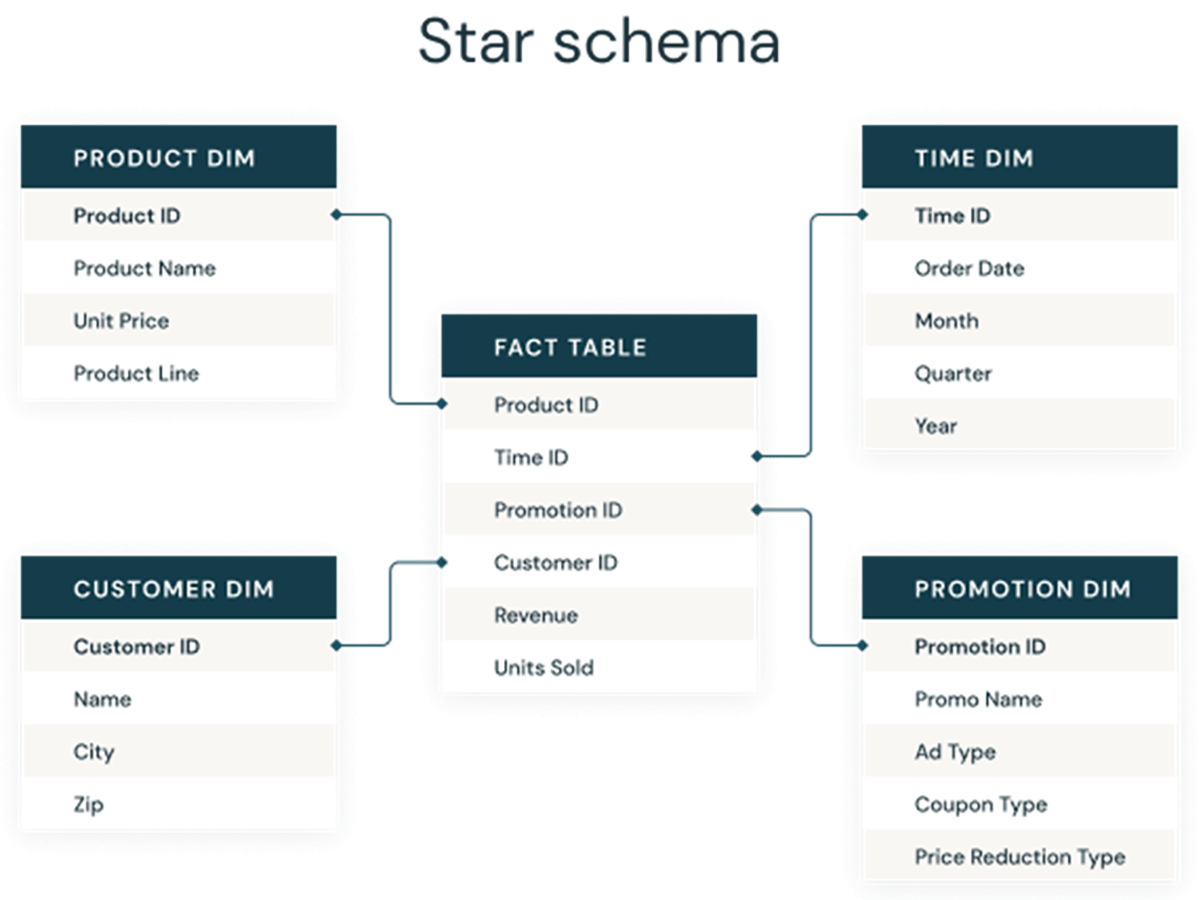
Approches traditionnelles pour générer des clés substituts sur les lacs de données
La plupart des technologies Big Data utilisent le parallélisme, c'est-à-dire la capacité de diviser une tâche en plusieurs parties qui peuvent être effectuées en même temps, pour améliorer les performances. Aux débuts des lacs de données, il n'y avait pas de moyen simple de créer des séquences uniques sur un groupe de machines. Cela a conduit certains ingénieurs de données à utiliser des méthodes moins fiables pour générer des clés substituts sans fonctionnalité appropriée, telles que :
monotonically_increasing_id(),row_number(),Rank OVER,ZipWithIndex(),ZipWithUniqueIndex(),- Hash de ligne avec
hash(),et - Hash de ligne avec
md5().
Bien que ces fonctions soient capables de faire le travail dans certaines circonstances, elles sont souvent accompagnées de nombreux avertissements et mises en garde concernant le remplissage épars des séquences, les problèmes de performance à grande échelle et les problèmes de transactions concurrentes.
Les bases de données sont capables de générer des séquences depuis longtemps, pour générer des clés substituts afin d'identifier de manière unique une ligne de données avec l'aide d'un gestionnaire de transactions centralisé. Cependant, les implémentations typiques nécessitent des verrous et des validations transactionnelles, qui peuvent être difficiles à gérer.
Les colonnes d'identité sur Delta Lake facilitent la génération de clés substituts
Les colonnes d'identité résolvent les problèmes mentionnés ci-dessus et fournissent une solution simple et performante pour générer des clés substituts. Delta Lake est le premier protocole de lac de données à permettre les colonnes d'identité pour la génération de clés substituts.
Delta Lake prend désormais en charge la création de colonnes IDENTITY qui peuvent générer automatiquement des numéros d'identification uniques et auto-incrémentés lors du chargement de nouvelles lignes. Bien que ces numéros d'identification puissent ne pas être consécutifs, Delta fait de son mieux pour maintenir l'écart aussi petit que possible. Vous pouvez utiliser cette fonctionnalité pour créer facilement des clés substituts pour vos charges de travail d'entreposage de données.
Comment créer une clé substitut avec une colonne d'identité en utilisant SQL et Delta Lake
[Recommandé] Générer toujours en tant qu'identité
La création d'une colonne d'identité en SQL est aussi simple que la création d'une table Delta Lake. Lors de la déclaration de vos colonnes, ajoutez un nom de colonne appelé id, ou tout autre nom de votre choix, avec un type de données BIGINT, puis entrez GENERATED ALWAYS AS IDENTITY.
Désormais, chaque fois que vous effectuez une opération sur cette table où vous insérez des données, omettez cette colonne de l'insertion, et Delta Lake générera automatiquement une valeur unique pour la colonne IDENTITY pour chaque ligne insérée dans la table Delta Lake.
Voici un exemple simple d'utilisation des colonnes d'identité dans Delta Lake :
À l'avenir, la colonne d'identité intitulée "id" s'incrémentera automatiquement chaque fois que vous insérerez de nouveaux enregistrements dans la table. Vous pouvez ensuite insérer de nouvelles données comme ceci :
Notez comment la colonne de clé substitut intitulée "id" est absente de la partie INSERT de l'instruction. Delta Lake remplira les clés substituts lorsqu'il écrira la table dans le stockage objet cloud (par exemple, AWS S3, Azure Data Lake Storage ou Google Cloud Storage). Apprenez-en davantage dans la documentation.
Générer par DEFAULT
Il existe également l'option GENERATED BY DEFAULT AS IDENTITY, qui permet de remplacer l'insertion d'identité, alors que l'option ALWAYS ne peut pas être remplacée.
Il y a quelques mises en garde à garder à l'esprit lors de l'adoption de cette nouvelle fonctionnalité. Les colonnes d'identité ne peuvent pas être ajoutées aux tables existantes ; les tables devront être recréées avec la nouvelle colonne d'identité ajoutée. Pour ce faire, créez simplement une nouvelle DDL de table avec la colonne d'identité, et insérez les colonnes existantes dans la nouvelle table, et des clés substituts seront générées pour la nouvelle table.
Commencez dès aujourd'hui avec les colonnes d'identité et Delta Lake sur Databricks SQL
Les colonnes d'identité sont maintenant GA (Généralement Disponibles) dans Databricks Runtime 10.4+ et dans Databricks SQL 2022.17+. Avec les colonnes d'identité, vous pouvez désormais permettre à toutes vos charges de travail d'entreposage de données de bénéficier de l'architecture Lakehouse, accélérée par Photon. Essayez les colonnes d'identité sur Databricks SQL dès aujourd'hui.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.