Modélisation visuelle des données avec erwin Data Modeler par Quest sur la plateforme Databricks Lakehouse
Modélisation des données avec erwin sur Databricks
par Vani Mishra, Abhishek Dey, Leo Mao, Soham Bhatt et Pradeep Anandapu
Ceci est un article collaboratif entre Databricks et Quest Software. Nous remercions Vani Mishra, Directrice de la gestion de produits chez Quest Software, pour ses contributions.
Modélisation des données avec erwin Data Modeler
Alors que les clients modernisent leur parc de données pour Databricks, ils consolident divers data marts et EDW dans une architecture lakehouse évolutive unique qui prend en charge l'ETL, la BI et l'IA. Généralement, l'une des premières étapes de ce parcours commence par faire le point sur les modèles de données existants des systèmes hérités, puis en les rationalisant et en les convertissant dans les zones Bronze, Silver et Gold de l'architecture Databricks Lakehouse. Un outil de modélisation de données robuste capable de visualiser, concevoir, déployer et standardiser les actifs de données du lakehouse simplifie grandement le parcours de conception et de migration du lakehouse, tout en accélérant les aspects de gouvernance des données.
Nous sommes ravis d'annoncer notre partenariat et l'intégration d'erwin Data Modeler par Quest avec la Databricks Lakehouse Platform pour répondre à ces besoins. Les data modelers peuvent désormais modéliser et visualiser les structures de données du lakehouse avec erwin Data Modeler pour créer des modèles de données logiques et physiques afin d'accélérer la migration vers Databricks. Les data modelers et architectes peuvent rapidement ré-ingénierer ou reconstruire des bases de données et leurs tables et vues sous-jacentes sur Databricks. Vous pouvez désormais accéder facilement à erwin Data Modeler depuis Databricks Partner Connect !
Voici quelques-unes des raisons principales pour lesquelles les outils de modélisation de données comme erwin Data Modeler sont importants :
- Meilleure compréhension des données : les outils de modélisation de données fournissent une représentation visuelle des structures de données complexes, ce qui permet aux parties prenantes de mieux comprendre les relations entre les différents éléments de données.
- Précision et cohérence accrues : les outils de modélisation de données peuvent aider à garantir que les bases de données sont conçues avec précision et cohérence, réduisant ainsi le risque d'erreurs et d'incohérences dans les données.
- Faciliter la collaboration : avec les outils de modélisation de données, plusieurs parties prenantes peuvent collaborer à la conception d'une base de données, garantissant que tout le monde est sur la même longueur d'onde et que le schéma résultant r�épond aux besoins de toutes les parties prenantes.
- Meilleures performances de la base de données : des bases de données correctement conçues peuvent améliorer les performances des applications qui en dépendent, conduisant à un traitement des données plus rapide et plus efficace.
- Maintenance plus facile : avec une base de données bien conçue, les tâches de maintenance comme l'ajout de nouveaux éléments de données ou la modification de ceux existants deviennent plus faciles et moins sujettes aux erreurs.
- Gouvernance des données, intelligence des données et gestion des métadonnées améliorées.
Dans ce blog, nous allons démontrer trois scénarios sur la façon dont erwin Data Modeler peut être utilisé avec Databricks :
- Le premier scénario concerne une équipe qui souhaite créer un nouveau schéma relationnel d'entité (ERD) basé sur la documentation de l'équipe métier. L'objectif est de créer un diagramme d'entité pour le modèle logique qu'une unité commerciale comprendra et appliquera les relations, définitions et règles métier telles qu'appliquées dans le système. Sur la base de ce modèle logique, nous allons également construire un modèle physique pour Databricks.
- Dans le deuxième scénario, l'unité commerciale construit un modèle de données visuel en effectuant une ingénierie inversée à partir de son environnement Databricks actuel, afin de comprendre les définitions métier, les relations et les perspectives de gouvernance, afin de collaborer avec l'équipe de reporting et de gouvernance.
- Dans le troisième scénario, l'équipe d'architectes de plateforme consolide ses divers entrepôts de données d'entreprise (EDW) et data marts tels qu'Oracle, SQL Server, Teradata, MongoDB, etc. dans la plateforme Databricks Lakehouse et construit un modèle maître consolidé.
Une fois la création de l'ERD terminée, nous vous montrerons comment générer un fichier DDL/SQL pour l'équipe de conception physique de Databricks.
Scénario #1 : Créer un nouveau modèle de données logique et physique à implémenter dans Databricks
La première étape consistera à sélectionner un modèle logique/physique comme montré ici :
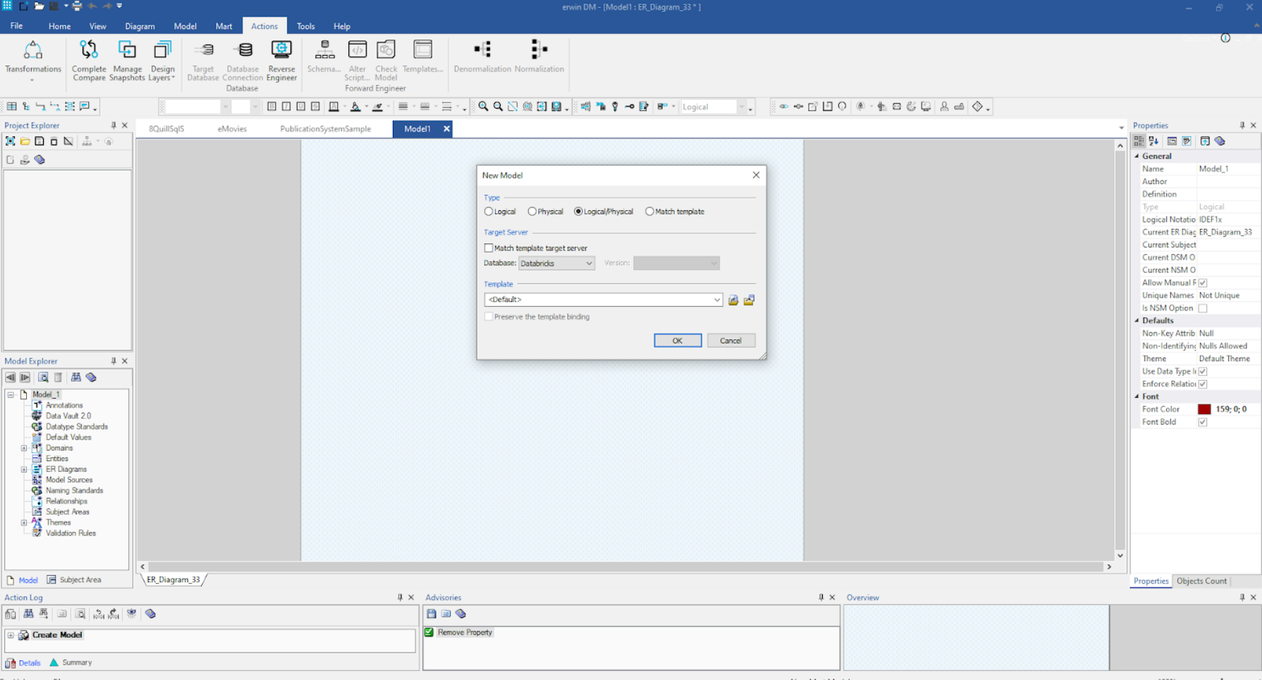
Une fois sélectionné, vous pouvez commencer à construire vos entités, attributs, relations, définitions et autres détails dans ce modèle.
La capture d'écran ci-dessous montre un exemple de modèle avancé :
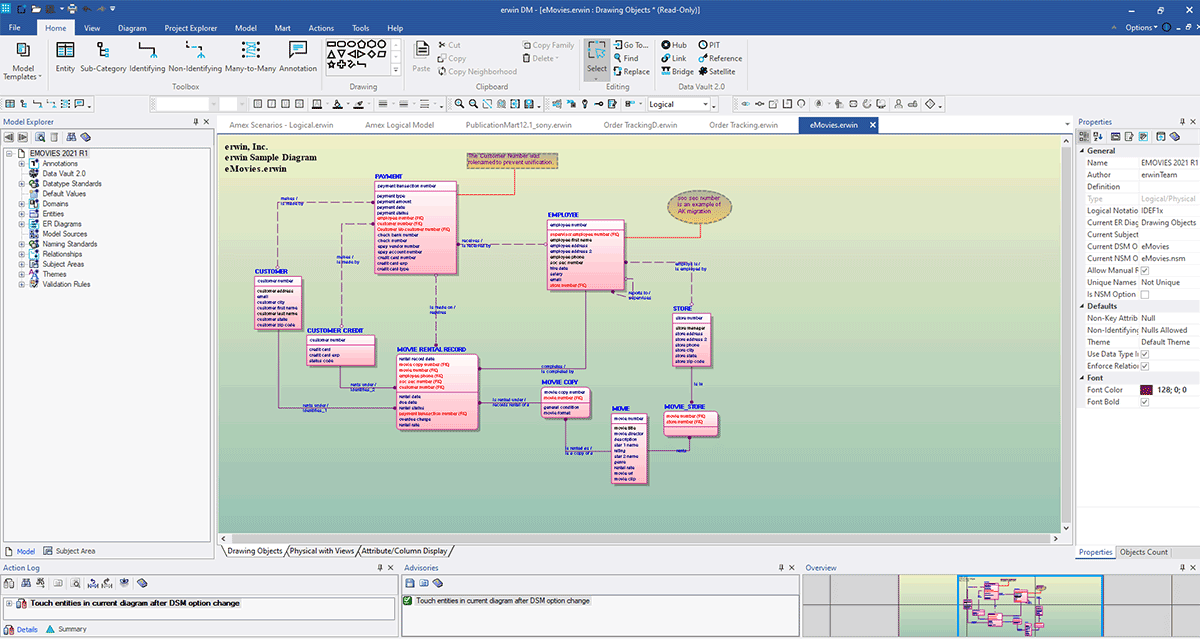
Ici, vous pouvez construire votre modèle et documenter les détails selon vos besoins. Pour en savoir plus sur l'utilisation d'erwin Data Modeler, consultez leur documentation d'aide en ligne : aide.
Scénario #2 : Ingénierie inversée d'un modèle de données à partir de la Databricks Lakehouse Platform
L'ingénierie inversée d'un modèle de données consiste à créer un modèle de données à partir d'une base de données ou d'un script existant. L'outil de modélisation crée une représentation graphique des objets de base de données sélectionnés et des relations entre ces objets. Cette représentation graphique peut être un modèle logique ou physique.
Nous allons nous connecter à Databricks depuis erwin Data Modeler via Partner Connect :
Options de connexion :
| Paramètre | Description | Informations supplémentaires |
|---|---|---|
| Type de connexion | Spécifie le type de connexion que vous souhaitez utiliser. Sélectionnez Utiliser une source de données ODBC pour vous connecter à l'aide de la source de données ODBC que vous avez définie. Sélectionnez Utiliser une connexion JDBC pour vous connecter à l'aide de JDBC. | |
| Source de données ODBC | Spécifie la source de données à laquelle vous souhaitez vous connecter. La liste déroulante affiche les sources de données définies sur votre ordinateur. | Cette option n'est disponible que lorsque le Type de connexion est défini sur Utiliser une source de données ODBC. |
| Lancer l'administrateur ODBC. | Spécifie si vous souhaitez démarrer le logiciel d'administration ODBC et afficher la boîte de dialogue Sélectionner une source de données. Vous pouvez ensuite sélectionner une source de données précédemment définie ou en créer une. | Cette option n'est disponible que lorsque le Type de connexion est défini sur Utiliser une source de données ODBC. |
| Chaîne de connexion | Spécifie la chaîne de connexion basée sur votre instance JDBC dans le format suivant : jdbc:spark://<server-hostname>:443/default;transportMode=http;ssl=1;httpPath=<http-path> | Cette option n'est disponible que lorsque le Type de connexion est défini sur Utiliser une connexion JDBC. Par exemple : jdbc:spark://<url>.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/<workspaceid>/xxxx |
La capture d'écran ci-dessous montre la connectivité JDBC via erwin DataModeler au Databricks SQL Warehouse.
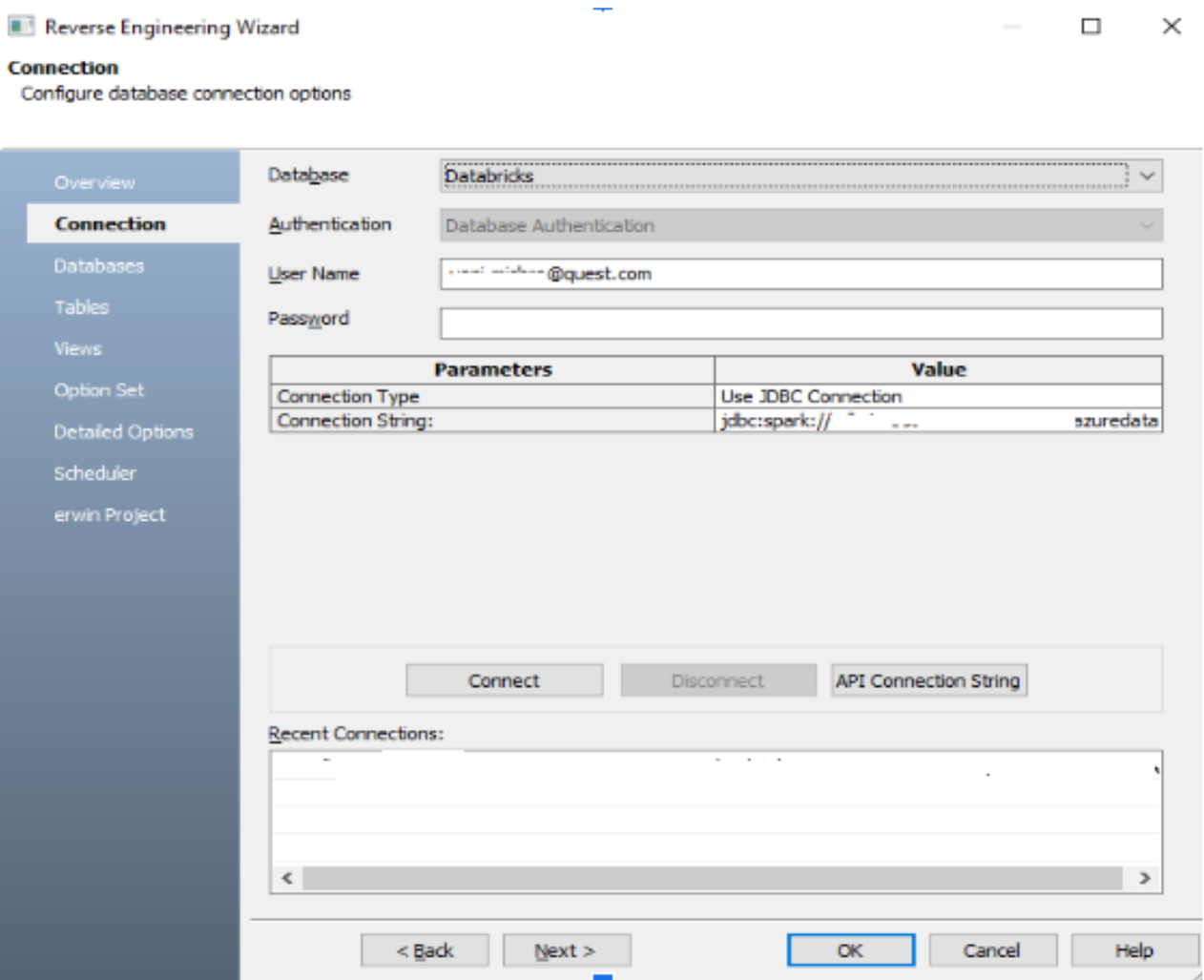
Il nous permet de visualiser toutes les bases de données disponibles et de sélectionner celle dans laquelle nous voulons construire notre modèle ERD, comme montré ci-dessous.
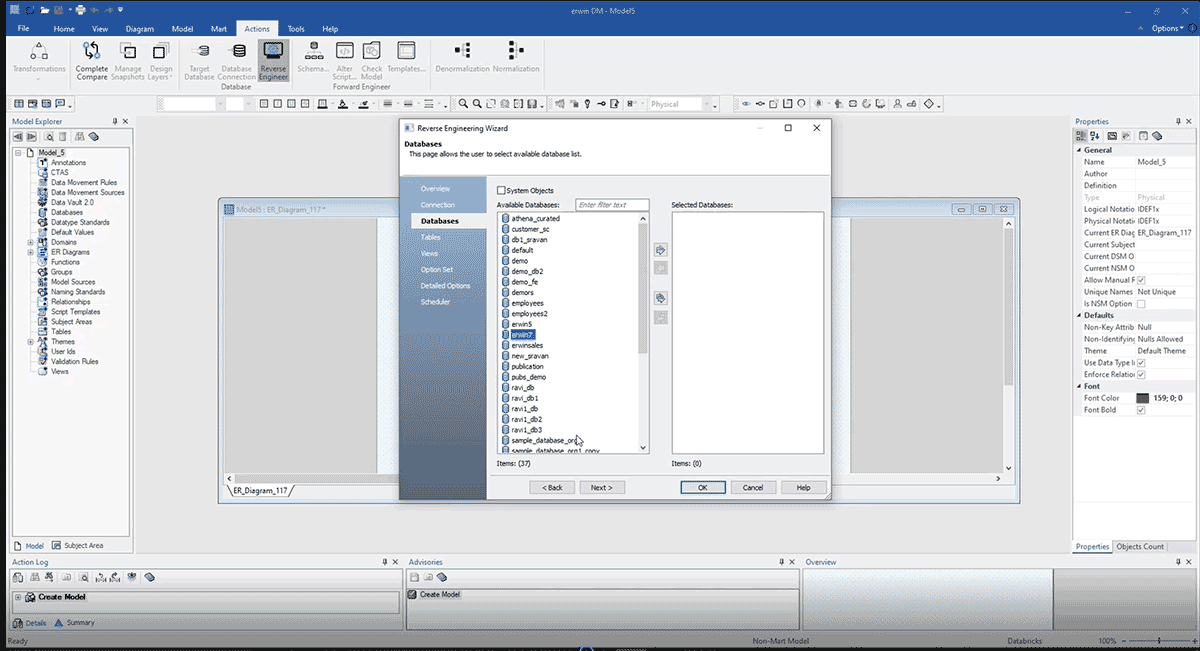
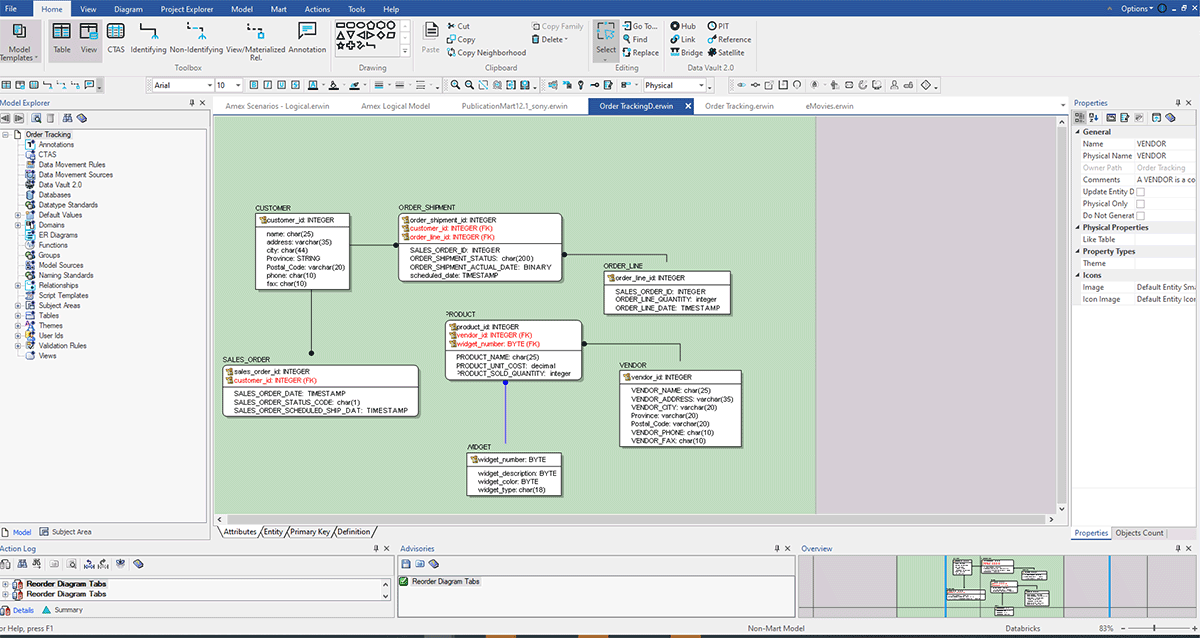
La capture d'écran ci-dessus montre un ERD construit après une ingénierie inversée depuis Databricks avec la méthode ci-dessus. Voici quelques avantages de l'ingénierie inversée d'un modèle de données :
- Meilleure compréhension des systèmes existants : en effectuant une ingénierie inversée d'un système existant, vous pouvez mieux comprendre son fonctionnement et comment ses différents composants interagissent. Cela vous aide à identifier les problèmes potentiels ou les domaines à améliorer.
- Économies : l'ingénierie inversée peut vous aider à identifier les inefficacités d'un système existant, entraînant des économies en optimisant les processus ou en identifiant les domaines de ressources gaspillées.
- Gain de temps : l'ingénierie inversée peut vous faire gagner du temps en vous permettant de réutiliser du code ou des structures de données existantes au lieu de repartir de zéro.
- Meilleure documentation : l'ingénierie inversée peut vous aider à créer une documentation précise et à jour pour un système existant, ce qui peut être utile pour la maintenance et le développement futur.
- Migration simplifiée : L'ingénierie inverse vous aide à comprendre les structures et les relations des données dans un système existant, ce qui facilite la migration des données vers un nouveau système ou une nouvelle base de données.
Dans l'ensemble, l'ingénierie inverse est précieuse et constitue une étape fondamentale pour la modélisation des données. L'ingénierie inverse permet une compréhension approfondie d'un système existant et de ses composants, un accès contrôlé au processus de conception de l'entreprise, une transparence totale tout au long du cycle de vie de la modélisation, des améliorations de l'efficacité, des gains de temps et d'argent, et une meilleure documentation qui conduit à de meilleurs objectifs de gouvernance.
Scénario n°3 : Migrer les modèles de données existants vers Databricks.
Les scénarios ci-dessus supposent que vous travaillez avec une seule source de données, mais la plupart des entreprises disposent de différents data marts et EDW pour répondre à leurs besoins de reporting. Imaginez que votre entreprise corresponde à cette description et qu'elle entreprenne de créer un Databricks Lakehouse pour consolider ses plateformes de données dans le cloud en une plateforme unifiée pour la BI et l'IA. Dans ce cas, il sera facile d'utiliser erwin Data Modeler pour convertir vos modèles de données existants d'un EDW hérité vers un modèle de données Databricks. Dans l'exemple ci-dessous, un modèle de données créé pour un EDW comme SQL Server, Oracle ou Teradata peut maintenant être implémenté dans Databricks en modifiant la base de données cible pour Databricks.
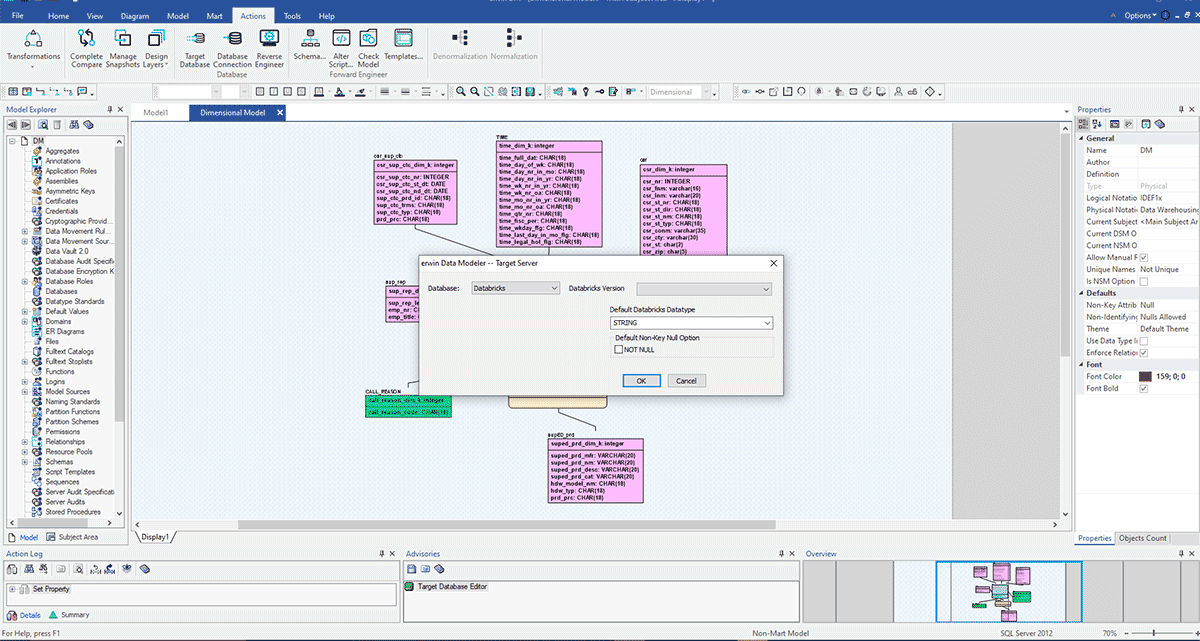
Comme vous pouvez le voir dans la zone cerclée, ce modèle est conçu pour SQL Server. Nous allons maintenant convertir ce modèle et migrer son déploiement vers Databricks en changeant le serveur cible. Ce type de conversion facile de vos modèles de données aide les organisations à migrer rapidement et en toute sécurité les modèles de données des bases de données héritées ou sur site vers le cloud et à gouverner ces jeux de données tout au long de leur cycle de vie.
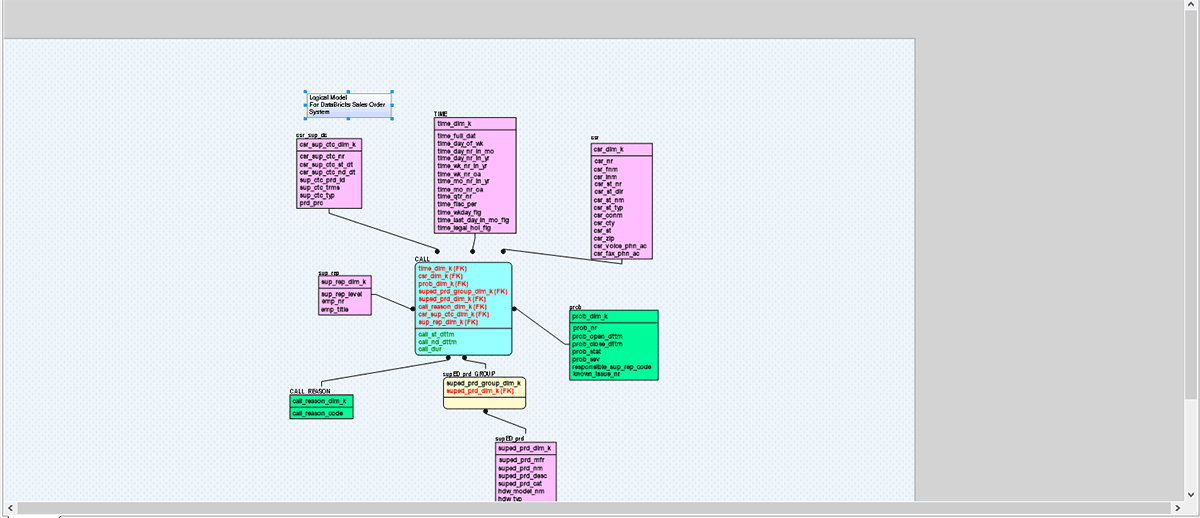
Dans l'image ci-dessus, nous avons essayé de convertir un modèle de données hérité basé sur SQL Server vers Databricks en quelques étapes simples. Ce type de chemin de migration facile permet aux organisations de migrer rapidement et en toute sécurité leurs données et leurs actifs vers Databricks, encourage la collaboration à distance et améliore la sécurité.
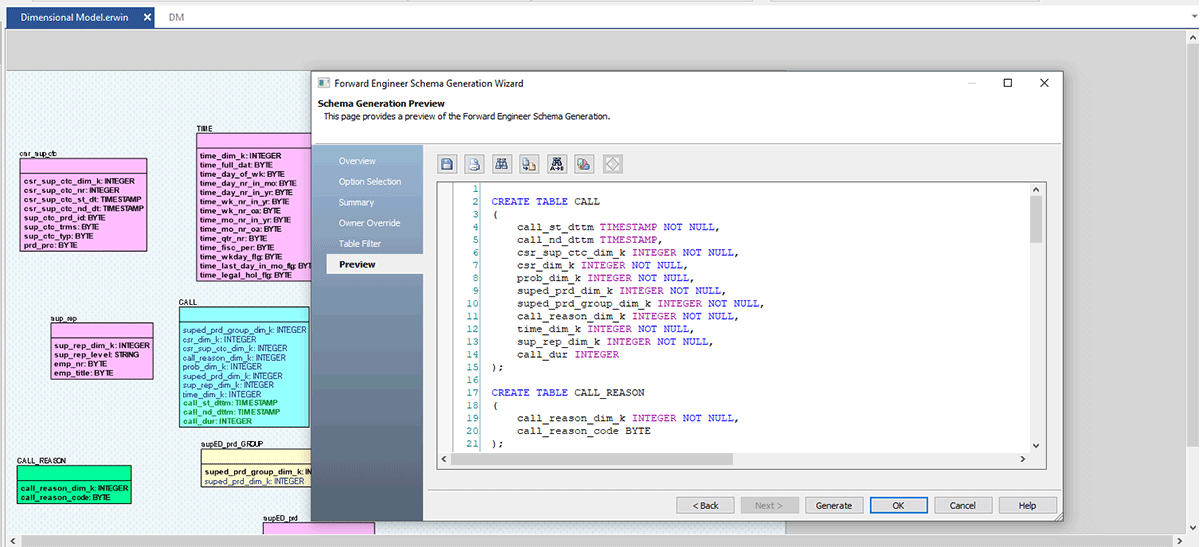
Passons maintenant à notre dernière partie ; une fois que le modèle ER est prêt et approuvé par l'équipe d'architecture de données, vous pouvez rapidement générer un fichier .sql à partir d'erwin DM ou vous connecter à Databricks et effectuer une ingénierie directe de ce modèle vers Databricks.
Suivez les captures d'écran ci-dessous, qui expliquent le processus étape par étape pour créer un fichier DDL ou un modèle de base de données pour Databricks.
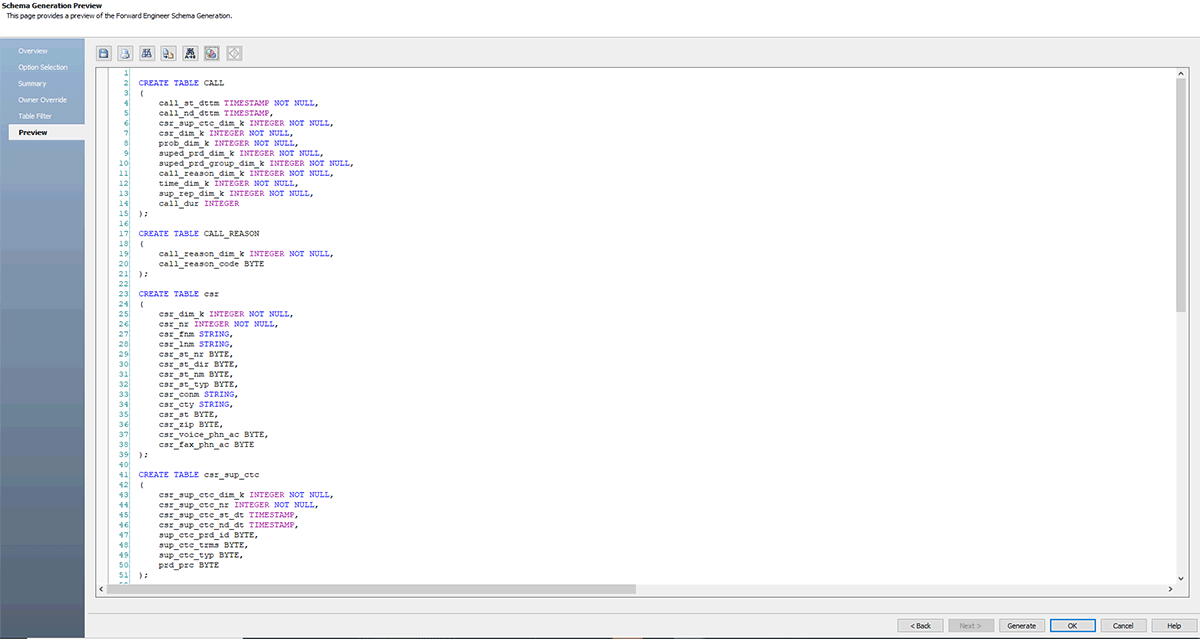
erwin Data Modeler Mart prend également en charge GitHub. Cette prise en charge permet à votre équipe DevOps de contrôler vos scripts dans les dépôts de contrôle de source d'entreprise de votre choix. Désormais, avec la prise en charge de Git, vous pouvez facilement collaborer avec les développeurs et suivre les flux de travail de contrôle de version.
Conclusion
Dans ce blog, nous avons démontré la facilité avec laquelle il est possible de créer, d'effectuer une ingénierie inverse ou une ingénierie directe de modèles de données à l'aide d'erwin Data Modeler et de créer des modèles de données visuels pour migrer vos définitions de table vers Databricks et d'effectuer une ingénierie inverse de modèles de données pour la gouvernance des données et la création de couches sémantiques.
Ce type de pratique de modélisation des données est l'élément clé pour ajouter de la valeur à votre :
- Pratique de gouvernance des données
- Réduction des coûts et obtention d'un délai de mise sur le marché plus rapide pour vos données et métadonnées
- Compréhension et amélioration des résultats commerciaux et de leurs métadonnées associées
- Réduction des complexités et des risques
- Amélioration de la collaboration entre l'équipe informatique et les parties prenantes de l'entreprise
- Meilleure documentation
- Enfin, un chemin facile pour migrer des bases de données héritées vers la plateforme Databricks
Commencez à utiliser erwin depuis Databricks Partner Connect.
Essayez Databricks gratuitement pendant 14 jours.
Essayez erwin Data modeler
** erwin DM 12.5 sera bientôt disponible avec la prise en charge d'Unity Catalog de Databricks où vous pourrez visualiser vos clés primaires et étrangères.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.