Spark Connect disponible dans Apache Spark 3.4
Exécutez des applications Spark partout
par Allan Folting, Hyukjin Kwon, Xiao Li, Herman van Hövell, Stefania Leone, Martin Grund, Reynold Xin et Kris Mo
L'année dernière, Spark Connect a été introduit au Data and AI Summit. Dans le cadre de la version 3.4 d'Apache SparkTM récemment publiée, Spark Connect est maintenant généralement disponible. Nous avons également récemment réarchitecturé Databricks Connect pour qu'il soit basé sur Spark Connect. Cet article de blog explique ce qu'est Spark Connect, comment il fonctionne et comment l'utiliser.
Les utilisateurs peuvent désormais connecter des IDE, des notebooks et des applications de données modernes directement aux clusters Spark
Spark Connect introduit une architecture client-serveur découplée qui permet une connectivité à distance aux clusters Spark depuis n'importe quelle application, exécutée n'importe où. Cette séparation du client et du serveur permet aux applications de données modernes, aux IDE, aux notebooks et aux langages de programmation d'accéder à Spark de manière interactive.
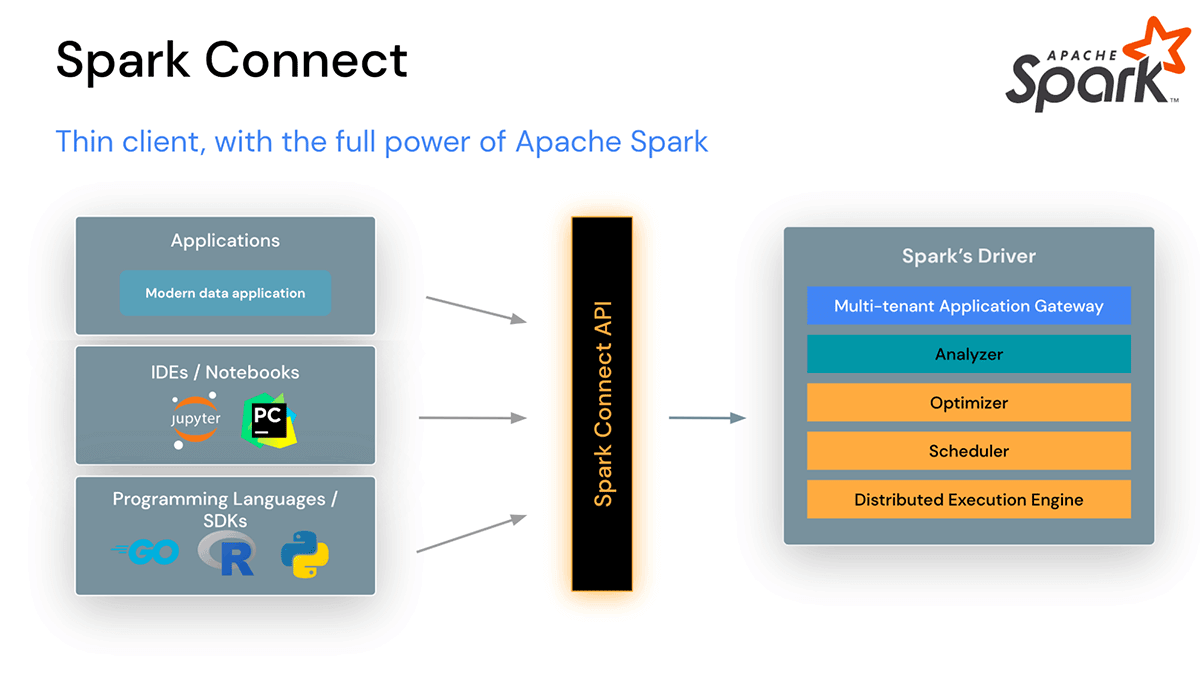
Spark Connect améliore la stabilité, les mises à niveau, le débogage et l'observabilité
Avec cette nouvelle architecture, Spark Connect atténue également les problèmes opérationnels courants :
Stabilité : Les applications qui consomment beaucoup de mémoire n'affecteront désormais que leur propre environnement, car elles peuvent s'exécuter dans leurs propres processus en dehors du cluster Spark. Les utilisateurs peuvent définir leurs propres dépendances dans l'environnement client et n'ont pas à se soucier des conflits de dépendances potentiels sur le pilote Spark.
Par exemple, si vous avez une application cliente qui récupère un grand ensemble de données de Spark pour analyse ou pour effectuer des transformations, cette application ne s'exécutera plus sur le pilote Spark. Cela signifie que si l'application utilise beaucoup de mémoire ou de cycles CPU, elle ne sera pas en concurrence pour les ressources avec d'autres applications sur le pilote Spark, ce qui pourrait potentiellement ralentir ou faire échouer ces autres applications, car elle s'exécute désormais dans son propre environnement séparé et dédié.
Mise à niveau : Par le passé, la mise à niveau de Spark était extrêmement fastidieuse, car toutes les applications du même cluster Spark devaient être mises à niveau en même temps que le cluster. Avec Spark Connect, les applications peuvent être mises à niveau indépendamment du serveur, grâce à la séparation du client et du serveur. Cela rend la mise à niveau beaucoup plus facile, car les organisations n'ont pas à apporter de modifications à leurs applications clientes lors de la mise à niveau de Spark.
Débogabilité et observabilité : Spark Connect permet le débogage interactif pas à pas pendant le développement directement depuis votre IDE préféré. De même, les applications peuvent être surveillées à l'aide des métriques natives et des bibliothèques de journalisation du framework de l'application.
Par exemple, vous pouvez déboguer interactivement une application cliente Spark Connect dans Visual Studio Code, inspecter des objets et exécuter des commandes de débogage pour tester et corriger les problèmes dans votre code.
Comment fonctionne Spark Connect
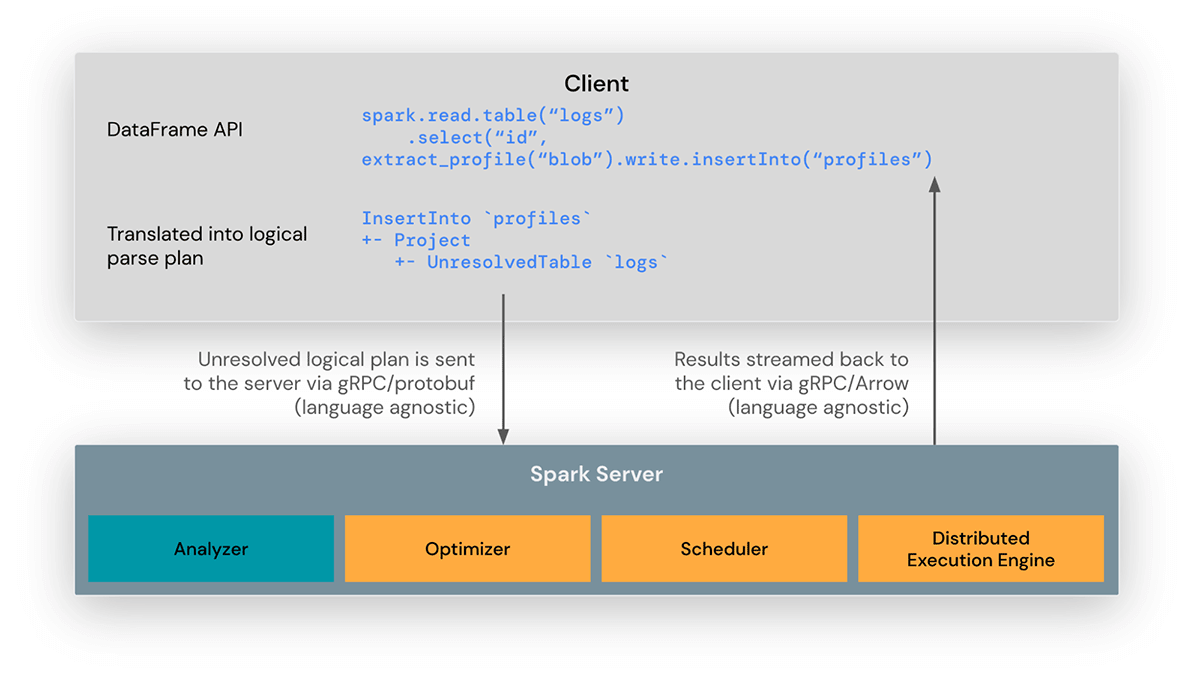
La bibliothèque cliente Spark Connect est conçue pour simplifier le développement d'applications Spark. C'est une API légère qui peut être intégrée partout : dans les serveurs d'applications, les IDE, les notebooks et les langages de programmation. L'API Spark Connect s'appuie sur l'API DataFrame de Spark en utilisant des plans logiques non résolus comme protocole indépendant du langage entre le client et le pilote Spark.
Le client Spark Connect traduit les opérations DataFrame en plans logiques non résolus qui sont encodés à l'aide de protocol buffers. Ceux-ci sont envoyés au serveur en utilisant le framework gRPC.
Le point de terminaison Spark Connect intégré au pilote Spark reçoit et traduit les plans logiques non résolus en opérateurs de plan logique Spark. C'est similaire à l'analyse d'une requête SQL, où les attributs et les relations sont analysés et un plan d'analyse initial est construit. À partir de là, le processus d'exécution standard de Spark entre en jeu, garantissant que Spark Connect tire parti de toutes les optimisations et améliorations de Spark. Les résultats sont renvoyés en flux vers le client via gRPC sous forme de lots de résultats encodés en Apache Arrow.
Comment utiliser Spark Connect
À partir de Spark 3.4, Spark Connect est disponible et prend en charge les applications PySpark et Scala. Nous allons parcourir un exemple de connexion à un serveur Apache Spark avec Spark Connect depuis une application cliente en utilisant la bibliothèque cliente Spark Connect.
Lorsque vous écrivez des applications Spark, la seule fois où vous devez tenir compte de Spark Connect est lorsque vous créez des sessions Spark. Tout le reste de votre code est exactement le même qu'auparavant.
Pour utiliser Spark Connect, vous pouvez simplement définir une variable d'environnement (SPARK_REMOTE) que votre application peut utiliser, sans apporter de modifications au code, ou vous pouvez inclure explicitement Spark Connect dans votre code lors de la création de sessions Spark.
Jetons un coup d'œil à un exemple de notebook Jupyter. Dans ce notebook, nous créons une session Spark Connect vers un cluster Spark local, créons un DataFrame PySpark et affichons les 10 principaux artistes musicaux par nombre d'auditeurs.
Dans cet exemple, nous spécifions explicitement que nous voulons utiliser Spark Connect en définissant la propriété remote lors de la création de notre session Spark (SparkSession.builder.remote...).
Code de notebook Jupyter utilisant Spark Connect
Vous pouvez télécharger l'ensemble de données utilisé dans l'exemple ici : Popularité des artistes musicaux | Kaggle
Comme illustré dans l'exemple suivant, Spark Connect facilite également le passage d'un cluster Spark à un autre, par exemple lors du développement et des tests sur un cluster Spark local, puis du déplacement de votre code en production sur un cluster distant.
Dans cet exemple, nous définissons la variable d'environnement TEST_ENV pour déterminer quel cluster Spark et quel emplacement de données notre application utilisera, afin de ne pas avoir à apporter de modifications au code pour passer de nos clusters de test, de staging et de production.
Passage d'un cluster Spark à un autre à l'aide d'une variable d'environnement
Pour en savoir plus sur l'utilisation de Spark Connect, consultez les pages Vue d'ensemble de Spark Connect et Démarrage rapide de Spark Connect.
Databricks Connect est basé sur Spark Connect
Depuis Databricks Runtime 13.0, Databricks Connect est désormais basé sur Spark Connect open-source. Avec cette architecture « v2 », Databricks Connect devient un client léger, simple et facile à utiliser. Il peut être intégré partout pour se connecter à Databricks : dans les IDE, les notebooks et toute application, permettant aux clients et partenaires de créer de nouvelles expériences utilisateur (interactives) basées sur votre Databricks Lakehouse. C'est très simple à utiliser : les utilisateurs intègrent simplement la bibliothèque Databricks Connect dans leurs applications et se connectent à leur Databricks Lakehouse.
API prises en charge dans Apache Spark 3.4
PySpark : Dans Spark 3.4, Spark Connect prend en charge la plupart des API PySpark, y compris les DataFrames, les fonctions et les colonnes. Les API PySpark prises en charge sont étiquetées « Prend en charge Spark Connect » dans la documentation de référence des API afin que vous puissiez vérifier si les API que vous utilisez sont disponibles avant de migrer votre code existant vers Spark Connect.
Scala : Dans Spark 3.4, Spark Connect prend en charge la plupart des API Scala, y compris les Datasets, les fonctions et les colonnes.
La prise en charge du streaming sera bientôt disponible et nous sommes impatients de collaborer avec la communauté pour fournir davantage d'API pour Spark Connect dans les prochaines versions de Spark.
Spark Connect dans Apache Spark 3.4 ouvre l'accès à Spark depuis n'importe quelle application basée sur des DataFrames/DataSets en PySpark et Scala et pose les bases pour la prise en charge d'autres langages de programmation à l'avenir.
Grâce à un développement simplifié des applications clientes, une contention de mémoire atténuée sur le pilote Spark, une gestion indépendante des dépendances pour les applications clientes, des mises à niveau indépendantes du client et du serveur, un débogage pas à pas dans l'IDE, et une journalisation et des métriques légères côté client, Spark Connect rend l'accès à Spark omniprésent.
Pour en savoir plus sur Spark Connect et commencer, visitez les pages Vue d'ensemble de Spark Connect et Démarrage rapide de Spark Connect.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.