Accélération de l'inférence LLM avec la mise en cache des invites pour les modèles open-source sur Databricks
Inférence LLM OSS plus rapide et sécurisée avec la mise en cache des invites.
par Pei-Lun Liao, Asfandyar Qureshi, Roshan Regula, Bruce Fontaine, James Thomas et Chenyang Yu
- La mise en cache des invites réutilise les préfixes d'invites répétés pour que les LLM s'exécutent plus rapidement. Elle réduit la latence et augmente le débit automatiquement.
- Databricks prend désormais en charge la mise en cache des invites pour les modèles open-source dans les charges de travail par lots, de paiement à l'utilisation et de débit provisionné. Aucune configuration n'est requise.
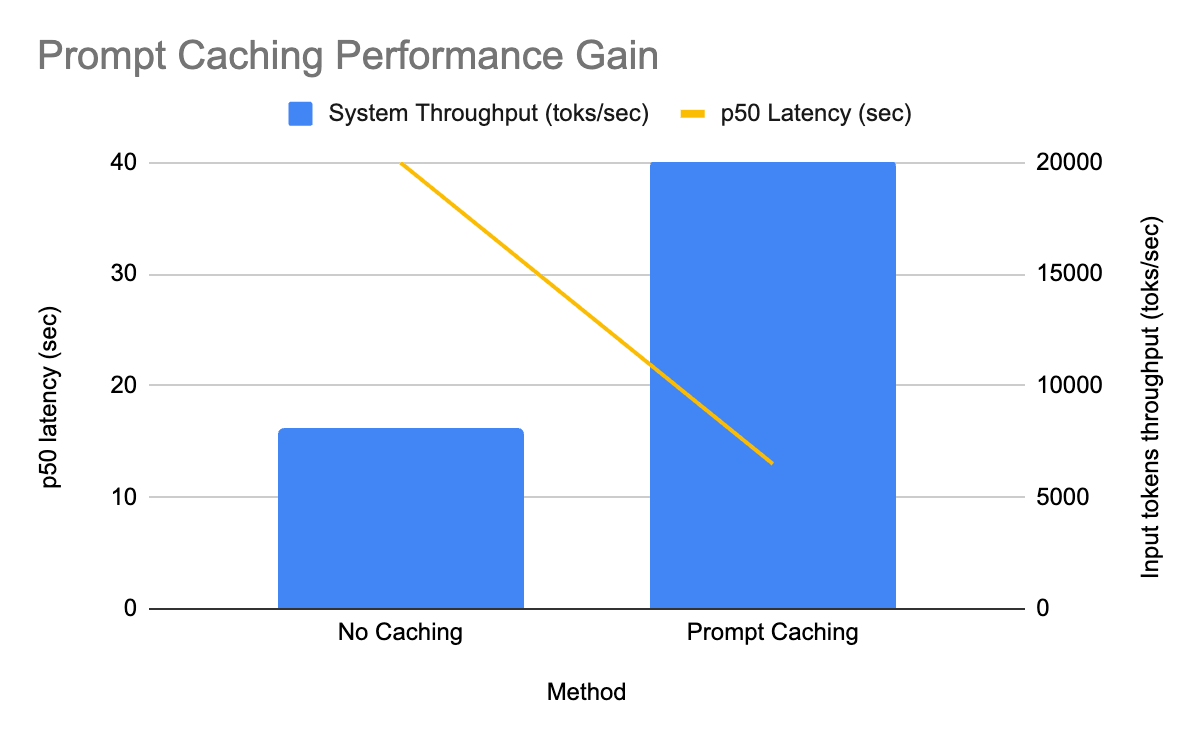
- En production sur GPT-OSS, la mise en cache des invites a augmenté le débit de 2,5x et réduit la latence P50 de 3x.
Pourquoi la mise en cache des invites est importante
L'inférence des grands modèles de langage (LLM) implique souvent des invites répétées — pensez à la même invite système ou d'instruction apparaissant dans des milliers de requêtes. Retraiter ce préfixe identique pour chaque appel gaspille des cycles de calcul, augmente la latence et accroît les coûts.
La mise en cache des invites élimine cette redondance, offrant :
- Latence réduite – la phase de préremplissage peut être ignorée en cas de succès de la mise en cache.
- Débit accru – plus de jetons sont traités par unité de modèle.
La mise en cache des invites peut être une technique puissante pour améliorer la qualité d'un modèle dans des domaines spécifiques sans compromettre le débit de jetons du modèle. Les requêtes peuvent partager une grande invite système spécifique au domaine, le coût de calcul de cette invite partagée étant amorti sur toutes ces requêtes. Les modèles de pointe, tels que Claude, utilisent des invites système qui font des milliers de jetons sous le capot. De plus, dans nos recherches récemment publiées, nous avons montré que l'optimisation automatisée des invites permet aux modèles open-source de surpasser la qualité des modèles de pointe pour les tâches d'entreprise.
Disponibilité des fonctionnalités
Databricks fournit déjà une mise en cache des invites intégrée pour les modèles propriétaires (GPT, Gemini, Claude). Nous avons maintenant étendu cette capacité aux modèles open-weights qui alimentent nos API de modèles fondamentaux (FMAPIs) pour les charges de travail d'inférence par lots, de paiement à l'utilisation et de débit provisionné. Elle s'applique également à tous les services de niveau supérieur alimentés par un modèle fondamental, par exemple, Agent Bricks, Genie, AI Functions.
La mise en cache des invites est désormais prise en charge pour les modèles OSS suivants hébergés sur Databricks :
- GPT‑OSS 20B et 120B
- Gemma 3 12B
- Llama 3.1 8B affiné (via le service PEFT)
- Llama 3.1 8B et 3.3 70B
Nous continuerons à déployer cette fonctionnalité sur nos autres modèles. La sécurité est une préoccupation de premier ordre chez Databricks. Les caches d'invites sont isolés, résident uniquement dans la mémoire volatile et ne sont jamais persistants. Fait important, la mise en cache est implicite : les clients n'ont rien à configurer, notre système est conçu pour exécuter automatiquement la mise en cache et la réutilisation des invites afin d'améliorer le débit.
Impact réel : inférence par lots sur GPT OSS
Nous avons d'abord déployé la mise en cache des invites sur nos modèles GPT‑OSS et avons immédiatement constaté des gains mesurables dans l'un des pipelines d'inférence par lots de production à grande échelle :
- Le débit de jetons d'entrée par réplique a été multiplié par 2,5
- La latence P50 a été réduite de 3x
- Tout cela avec un taux de succès de cache relativement faible de 30 %
Conclusion
En réutilisant automatiquement les caches KV pour les invites identiques, Databricks vous permet d'exécuter des LLM open-source plus rapidement, de manière plus rentable et avec une plus grande sécurité, le tout sans nécessiter de configuration supplémentaire. Que vous serviez des conversations en temps réel, traitiez par lots de grandes collections de documents ou construisiez des agents IA, la mise en cache des invites peut transformer un bon pipeline d'inférence en un excellent pipeline. Essayez-la lors de votre prochaine implémentation de modèle OSS et observez l'augmentation des métriques de performance.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.