Créer des agents d'entreprise de pointe 90 fois moins chers grâce à l'optimisation automatisée des invites
Databricks Agent Bricks est une plateforme pour construire, évaluer et déployer des agents IA de niveau production pour les flux de travail d'entreprise. Notre objectif est d'aider les clients à atteindre le meilleur équilibre qualité-coût sur la frontière de Pareto pour leurs tâches spécifiques à leur domaine, et à améliorer continuellement leurs agents qui raisonnent sur leurs propres données. Pour soutenir cela, nous développons des benchmarks centrés sur l'entreprise et effectuons des évaluations empiriques sur des agents qui mesurent la précision et l'efficacité du service, reflétant les compromis réels auxquels les entreprises sont confrontées en production.
Dans notre boîte à outils plus large d'optimisation d'agents, cet article se concentre sur l'optimisation automatisée des invites, une technique qui exploite une recherche itérative et structurée guidée par des signaux de rétroaction de l'évaluation pour améliorer automatiquement les invites. Nous démontrons comment nous pouvons :
- Permettre aux modèles open-source de surpasser la qualité des modèles de pointe pour les tâches d'entreprise : en exploitant GEPA, une technique d'optimisation d'invites récemment publiée issue de la recherche de Databricks et de l'UC Berkeley, nous présentons comment gpt-oss-120b surpasse les modèles propriétaires de pointe Claude Sonnet 4 et Claude Opus 4.1 de ~3 % tout en étant environ 20 fois et 90 fois moins cher à servir, respectivement (voir le graphique de la frontière de Pareto ci-dessous).
- Améliorer encore davantage les modèles propriétaires de pointe : nous appliquons la même approche aux modèles propriétaires leaders, augmentant les performances de base de Claude Opus 4.1 et Claude Sonnet 4 de 6-7 % et atteignant de nouvelles performances de pointe.
- Offrir un compromis qualité-coût supérieur par rapport au SFT : l'optimisation automatisée des invites offre des performances égales ou supérieures au réglage fin supervisé (SFT), tout en réduisant les coûts de service de 20 %. Nous montrons également que l'optimisation des invites et le SFT peuvent fonctionner ensemble pour améliorer davantage les performances.
Dans les sections suivantes, nous aborderons
- comment nous évaluons les performances des agents IA sur l'extraction d'informations comme cas d'utilisation principal et pourquoi cela est important pour les flux de travail d'entreprise ;
- un aperçu du fonctionnement de l'optimisation des invites, les types d'avantages qu'elle peut apporter, en particulier dans les scénarios où le réglage fin n'est pas pratique, et les gains de performance sur notre pipeline d'évaluation ;
- pour mettre ces gains en contexte, nous mesurerons l'impact de l'optimisation des invites et analyserons l'économie derrière ces techniques ;
- la comparaison des performances avec le réglage fin supervisé (SFT), en soulignant le compromis qualité-coût supérieur de l'optimisation des invites ;
- les conclusions et les prochaines étapes, en particulier comment vous pouvez commencer à appliquer ces techniques directement avec Databricks Agent Bricks pour construire les meilleurs agents IA optimisés pour le déploiement en entreprise dans le monde réel.
Évaluation des derniers LLM sur IE Bench
Extraction d'informations (IE) est une fonctionnalité principale d'Agent Bricks, convertissant des sources non structurées telles que des PDF ou des documents numérisés en enregistrements structurés. Malgré les progrès rapides des capacités d'IA générative, l'IE reste difficile à l'échelle de l'entreprise :
- Les documents sont longs et remplis de jargon spécifique au domaine
- Les schémas sont complexes, hiérarchiques et contiennent des ambiguïtés
- Les étiquettes sont souvent bruitées et incohérentes
- La tolérance opérationnelle à l'erreur d'extraction est faible
- Exigence d'une fiabilité élevée et d'une efficacité des coûts pour les charges de travail d'inférence à grande échelle
En conséquence, nous observons que les performances peuvent varier considérablement selon le domaine et la complexité de la tâche, de sorte que la construction des bons systèmes d'IA composés pour l'IE dans divers cas d'utilisation nécessite une évaluation approfondie des capacités variables des agents IA.
Pour explorer cela, nous avons développé IE Bench, une suite d'évaluation complète couvrant plusieurs domaines d'entreprise du monde réel tels que la finance, le droit, le commerce et la santé. Le benchmark reflète des défis complexes du monde réel, y compris des documents de plus de 100 pages, couvrant des entités d'extraction avec plus de 70 champs, et des schémas hiérarchiques avec plusieurs niveaux imbriqués. Nous rapportons les évaluations sur l'ensemble de test retenu du benchmark pour fournir une mesure fiable des performances réelles.
Nous avons benchmarké la dernière génération de modèles open-source servis via l'API Databricks Foundation Models, y compris la série nouvellement publiée gpt-oss, ainsi que les modèles propriétaires leaders de plusieurs fournisseurs, y compris la dernière famille GPT-5.1
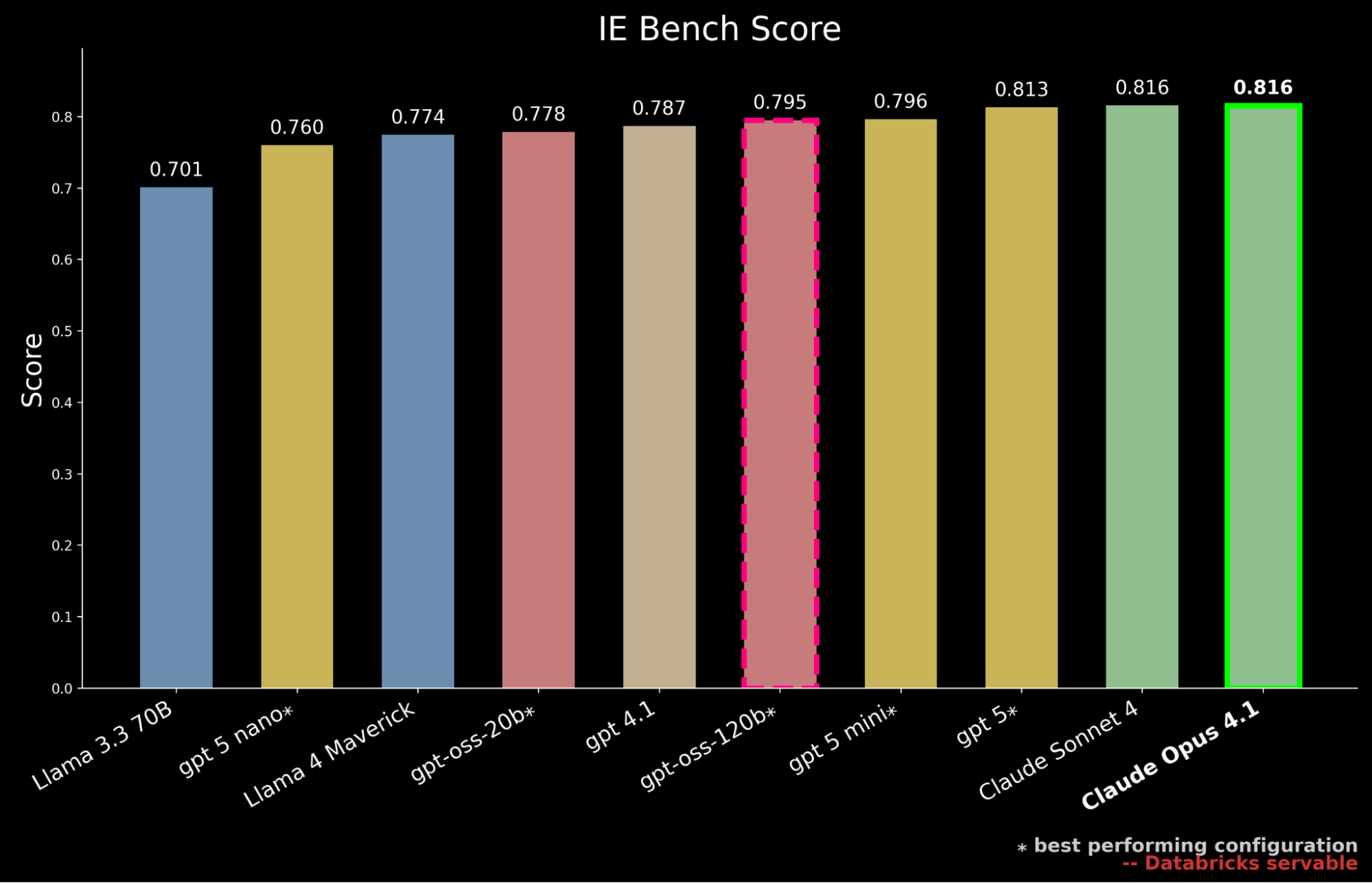
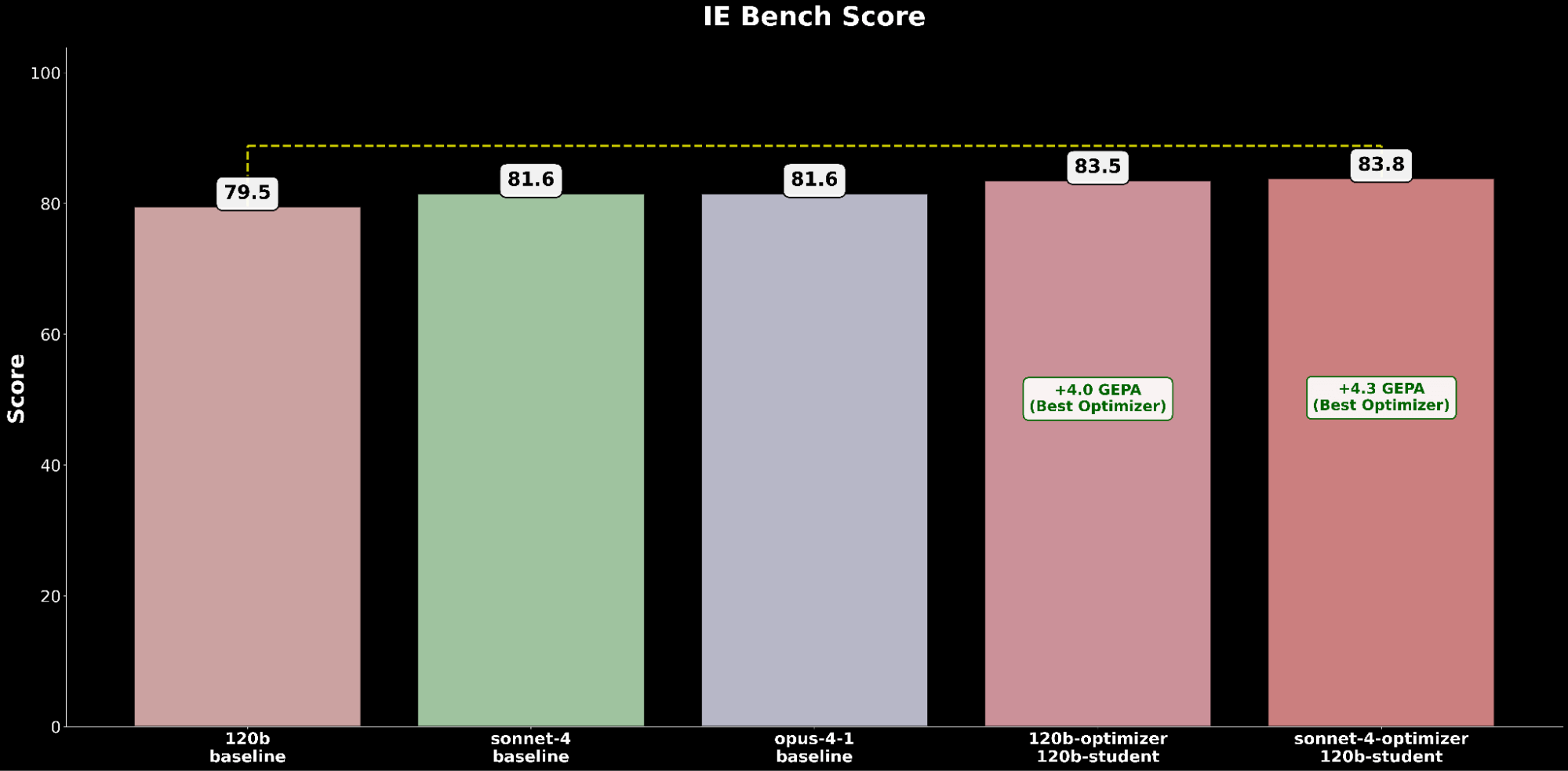
Nos résultats montrent que gpt-oss-120b est le modèle open-source le plus performant sur IE Bench, surpassant les performances précédentes de l'état de l'art open-source de Llama 4 Maverick de ~3 % tout en approchant le niveau de performance de gpt-5-mini, marquant une étape significative pour les modèles open-source. Cependant, il reste encore derrière les performances des modèles propriétaires de pointe, à la traîne par rapport à gpt-5, Claude Sonnet 4 et Claude Opus 4.1, qui obtient le score le plus élevé sur le benchmark.
Pourtant, dans les environnements d'entreprise, les performances doivent également être pondérées par le coût de service. Nous contextualisons davantage nos conclusions précédentes en soulignant que gpt-oss-120b égale les performances de gpt-5-mini tout en n'entraînant qu'environ 50 % du coût de service. 2 Les modèles propriétaires de pointe sont largement plus chers, avec gpt-5 à environ ~10 fois le coût de service de gpt-oss-120b, Claude Sonnet 4 à ~20 fois et Claude Opus 4.1 à ~90 fois.
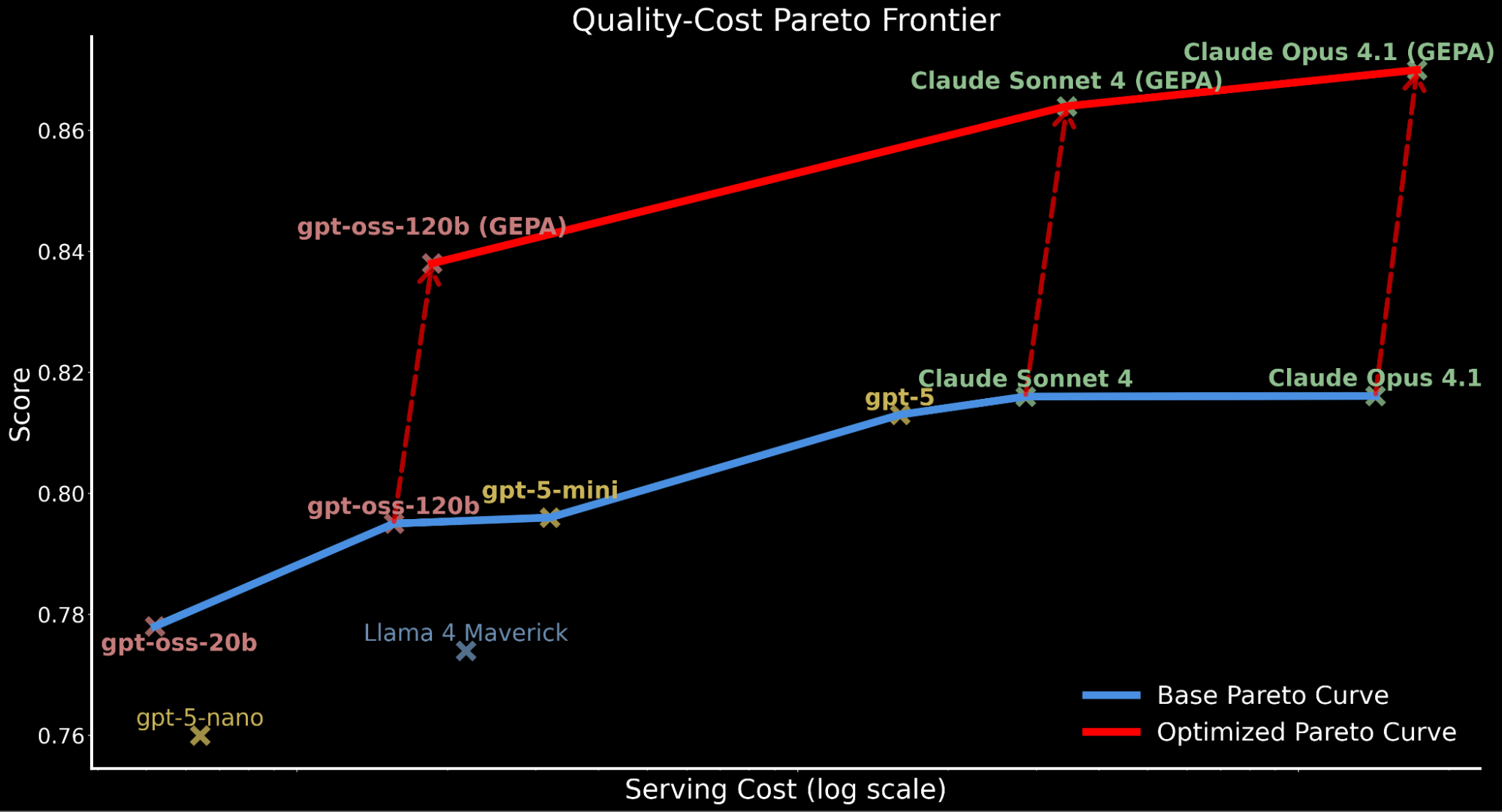
Pour illustrer le compromis qualité-coût entre les modèles, nous traçons la frontière de Pareto ci-dessous, représentant les performances de base pour tous les modèles avant toute amélioration.
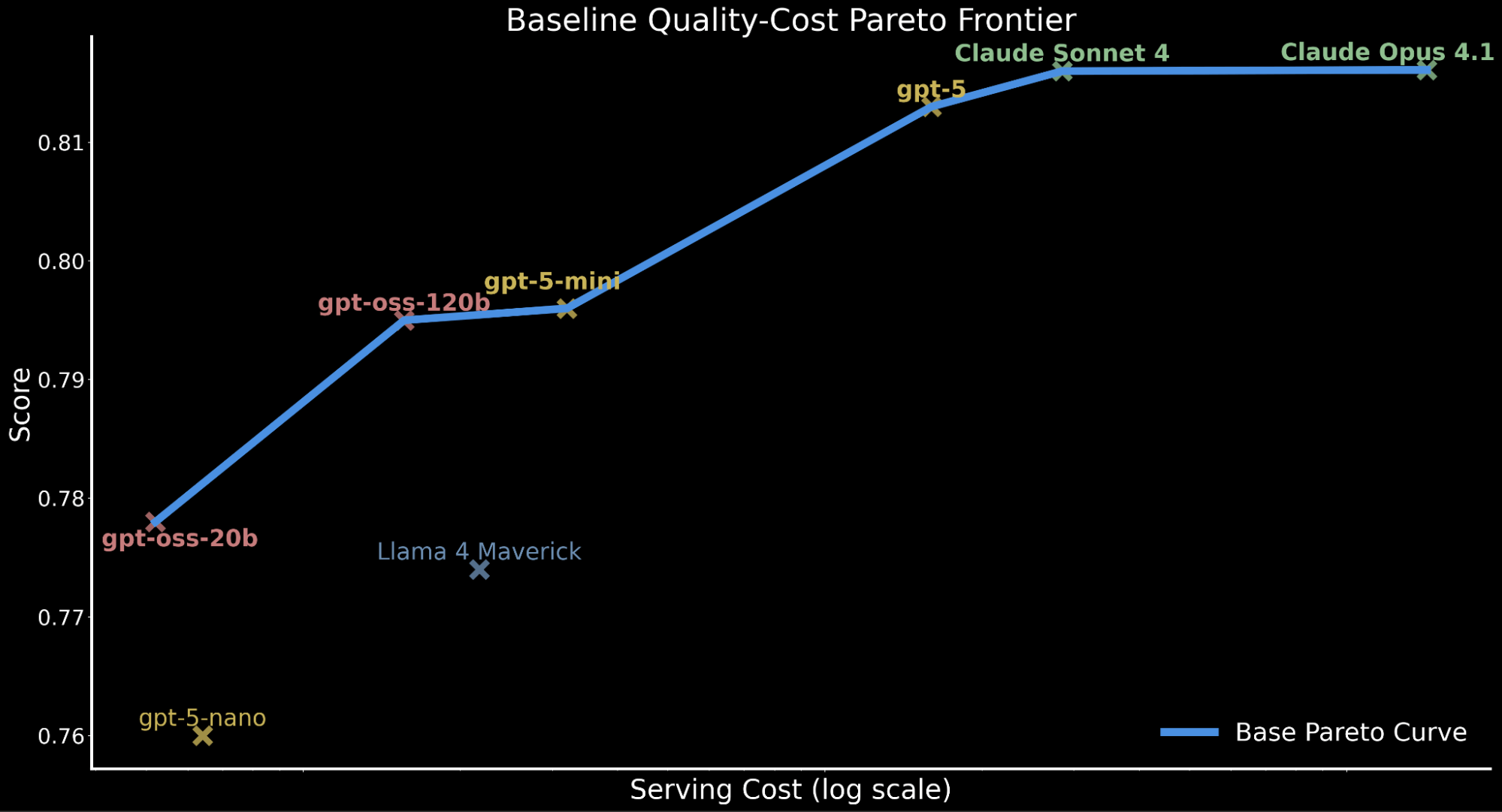
Ce compromis qualité-coût a des implications majeures pour les charges de travail d'entreprise nécessitant une inférence à grande échelle qui doivent tenir compte du budget de calcul et du débit de service tout en maintenant une précision performante.
Cela motive notre exploration : Pouvons-nous pousser gpt-oss-120b à une qualité de pointe tout en préservant son efficacité économique ? Si oui, cela fournirait des performances de pointe sur la frontière de Pareto coût-qualité tout en étant servable pour l'adoption en entreprise chez Databricks.
Optimisation des modèles open-source pour surpasser les performances des modèles de pointe
Nous explorons l'optimisation automatique des invites comme méthode systématique pour améliorer les performances des modèles. L'ingénierie manuelle des invites peut apporter des gains, mais elle dépend généralement de l'expertise du domaine et de l'expérimentation par essais et erreurs. Cette complexité augmente dans les systèmes d'IA composés intégrant plusieurs appels LLM et outils externes qui doivent être optimisés ensemble, rendant le réglage manuel des invites impraticable à mettre à l'échelle ou à maintenir dans les pipelines de production.
L'optimisation des invites offre une approche différente, exploitant une recherche structurée guidée par des signaux de rétroaction pour améliorer automatiquement les invites. De tels optimiseurs sont indépendants du pipeline et sont capables d'optimiser conjointement plusieurs invites interdépendantes dans des pipelines multi-étapes, rendant ces techniques robustes et adaptables aux systèmes d'IA composés et aux tâches diverses.
Pour tester cela, nous appliquons des algorithmes d'optimisation automatique des invites, spécifiquement MIPROv2, SIMBA, et GEPA, un nouvel optimiseur d'invites issu de la recherche de Databricks et de l'UC Berkeley qui combine la réflexion basée sur le langage avec la recherche évolutive pour améliorer les systèmes d'IA. Nous appliquons ces algorithmes pour évaluer comment une invite optimisée peut combler l'écart entre le modèle open-source le plus performant, gpt-oss-120b, et les modèles propriétaires de pointe à source fermée.
Nous considérons les configurations suivantes d'optimiseurs d'invites automatiques dans notre exploration
Chaque technique d'optimisation de prompt s'appuie sur un modèle optimiseur pour affiner différents aspects du prompt pour un modèle étudiant cible. Selon l'algorithme, le modèle optimiseur peut générer des exemples few-shot à partir de traces bootstrappées pour appliquer l'apprentissage en contexte et/ou proposer et améliorer les instructions de la tâche par le biais d'algorithmes de recherche qui effectuent une réflexion itérative en utilisant des retours pour muter et sélectionner de meilleurs prompts au cours des essais d'optimisation. Ces informations sont distillées en prompts améliorés que le modèle étudiant utilisera lors de l'inférence au moment du service. Bien que le même LLM puisse être utilisé pour les deux rôles, nous expérimentons également l'utilisation d'un modèle « plus performant » comme modèle optimiseur pour explorer si des conseils de meilleure qualité peuvent améliorer davantage les performances du modèle étudiant.
En nous appuyant sur nos découvertes antérieures concernant gpt-oss-120b comme modèle open-source leader sur IE Bench, nous le considérons comme notre modèle étudiant de référence pour explorer des améliorations supplémentaires.
Lors de l'optimisation de gpt-oss-120b, nous considérons deux configurations :
- gpt-oss-120b (optimiseur) → gpt-oss-120b (étudiant)
- Claude Sonnet 4 (optimiseur) → gpt-oss-120b (étudiant)
Étant donné que Claude Sonnet 4 obtient des performances de pointe sur IE Bench par rapport à gpt-oss-120b, et qu'il est relativement moins cher que Claude Opus 4.1 avec des performances similaires, nous explorons l'hypothèse selon laquelle l'application d'un modèle optimiseur plus puissant peut produire de meilleures performances pour gpt-oss-120b.
Nous évaluons chaque configuration à travers les techniques d'optimisation et comparons avec la référence gpt-oss-120b respective :
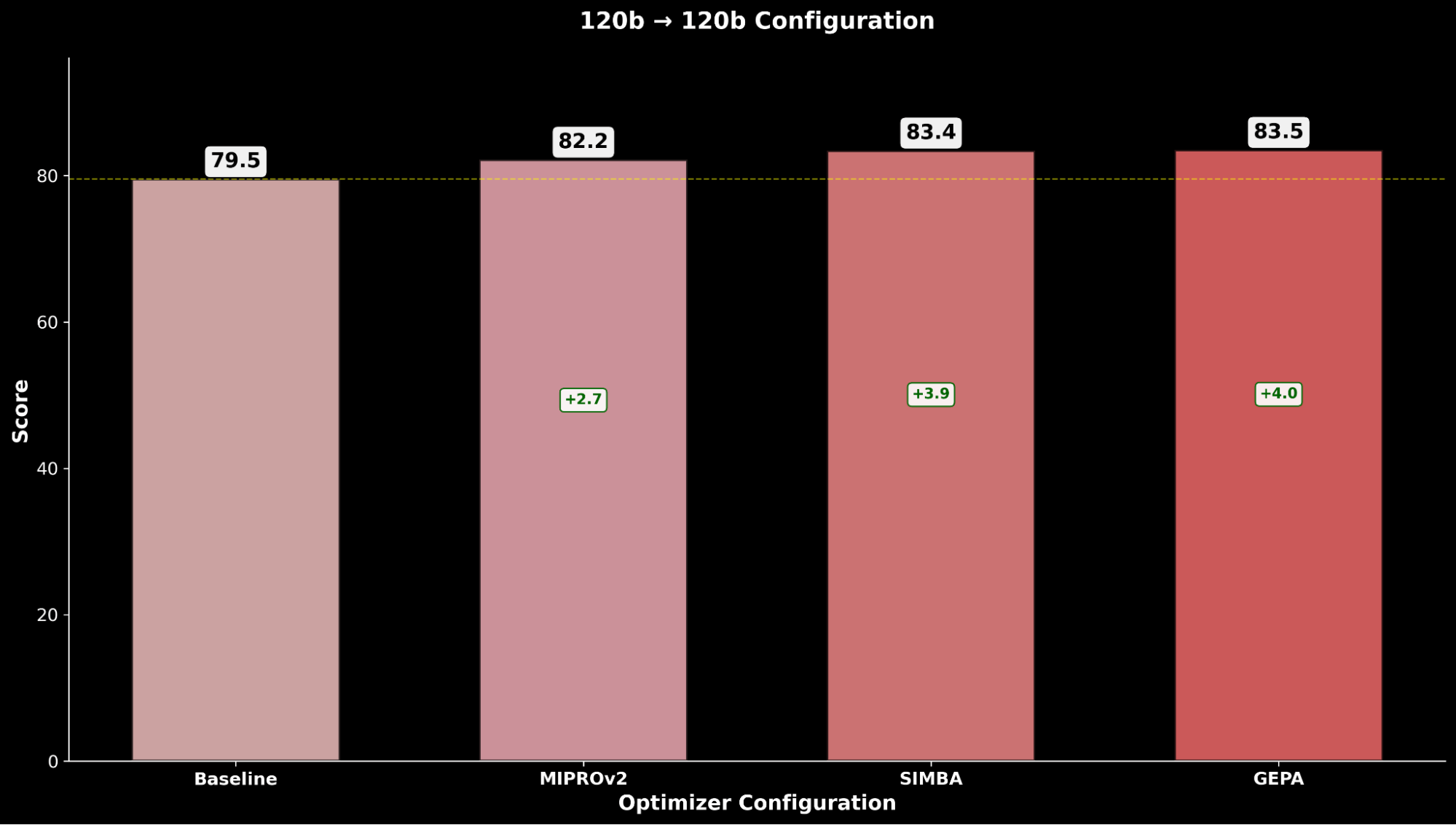
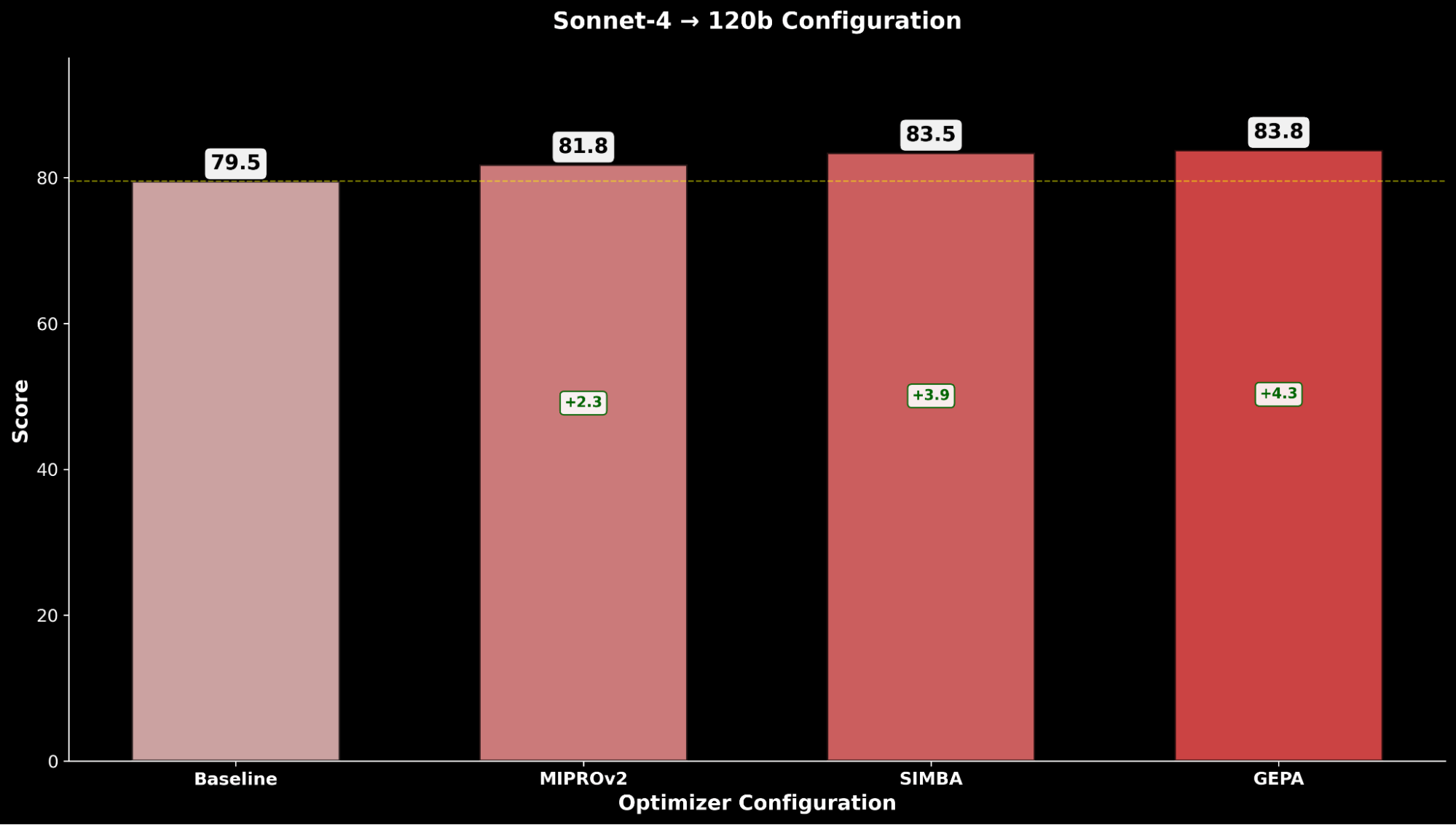
Sur IE Bench, nous constatons que l'optimisation de gpt-oss-120b avec Claude Sonnet 4 comme modèle optimiseur obtient l'amélioration la plus significative par rapport aux performances de référence de gpt-oss-120b, avec une amélioration notable de +4,3 points par rapport à la référence et une amélioration de +0,3 point par rapport à l'optimisation de gpt-oss-120b avec lui-même comme modèle optimiseur, soulignant l'avantage de l'utilisation d'un modèle optimiseur plus puissant.
Nous comparons la configuration gpt-oss-120b optimisée par GEPA la plus performante aux modèles Claude de pointe :
La configuration gpt-oss-120b optimisée surpasse les performances de référence de Claude Opus 4.1 de +2,2 points absolus, soulignant les avantages de l'optimisation automatique des prompts pour permettre à un modèle open-source de surpasser les modèles propriétaires leaders sur les capacités IE.
Optimiser les modèles de pointe pour élever davantage le plafond de performance
Compte tenu de l'importance de l'optimisation automatique des prompts, nous explorons si l'application du même principe aux modèles de pointe Claude Sonnet 4 et Claude Opus 4.1 peut repousser davantage le plafond de performance réalisable pour IE Bench.
Lors de l'optimisation de chaque modèle propriétaire, nous considérons les configurations suivantes :
- Claude Sonnet 4 (optimiseur) → Claude Sonnet 4 (étudiant)
- Claude Opus 4.1 (optimiseur) → Claude Opus 4.1 (étudiant)
Nous avons choisi de considérer les configurations par défaut du modèle optimiseur, car ces modèles définissent déjà la frontière de performance.
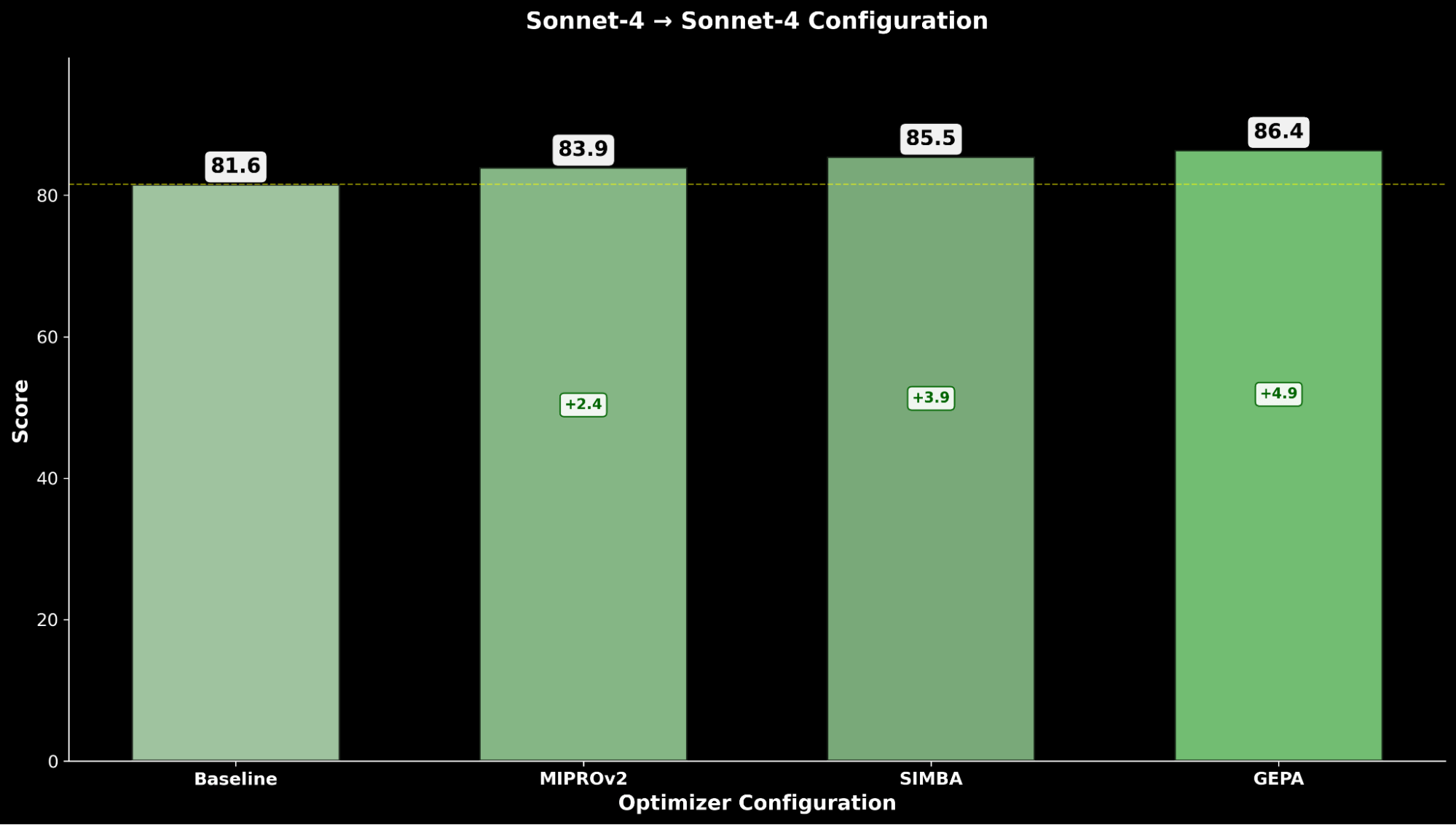
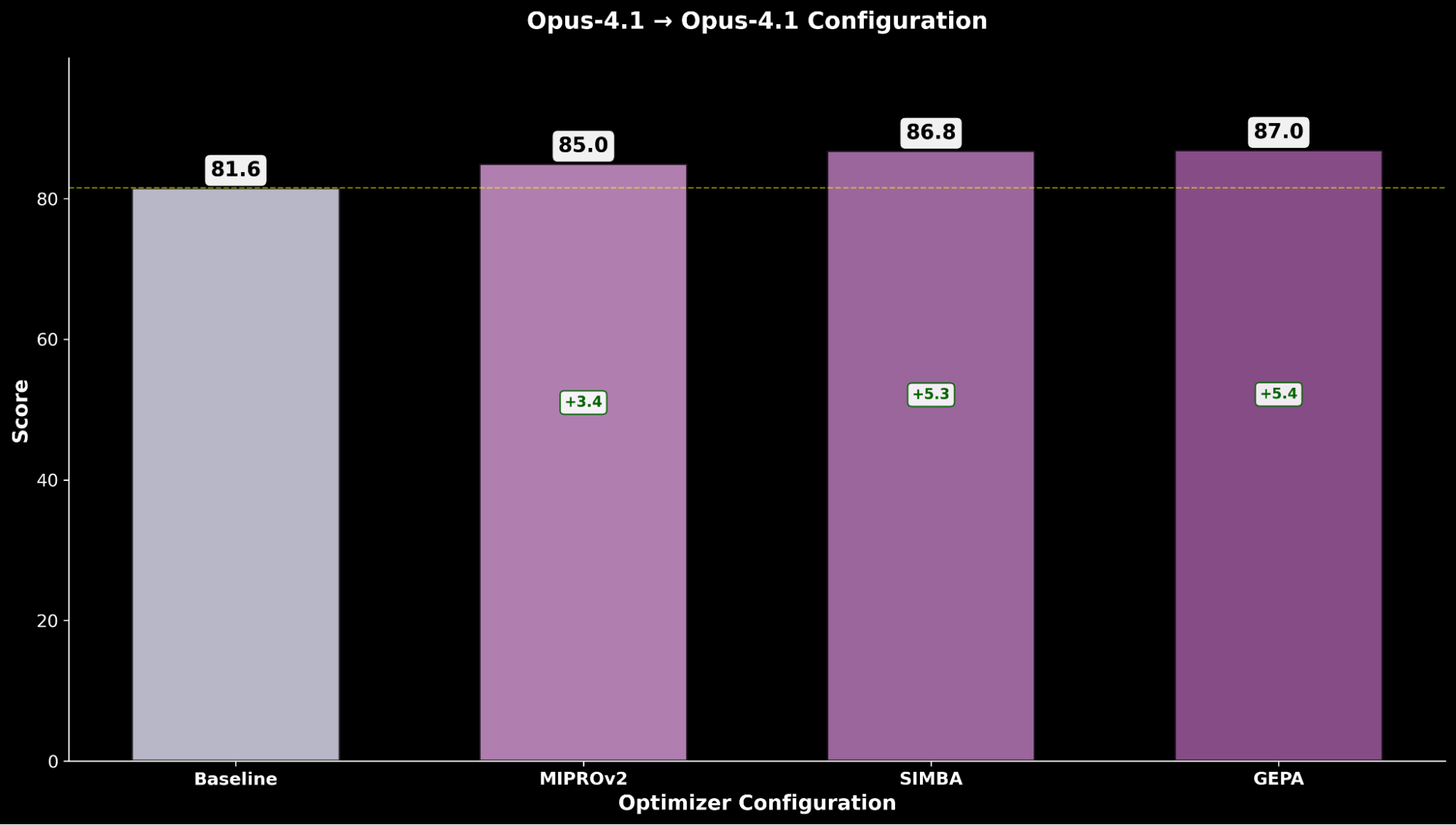
L'optimisation de Claude Sonnet 4 permet une amélioration de +4,8 par rapport à la performance de référence, tandis que Claude Opus 4.1 optimisé atteint la meilleure performance globale, avec une amélioration significative de +6,4 points par rapport à la performance de pointe précédente.
En agrégeant les résultats des expériences, nous observons une tendance constante : l'optimisation automatisée des invites génère des gains de performance substantiels sur la performance de référence de tous les modèles.
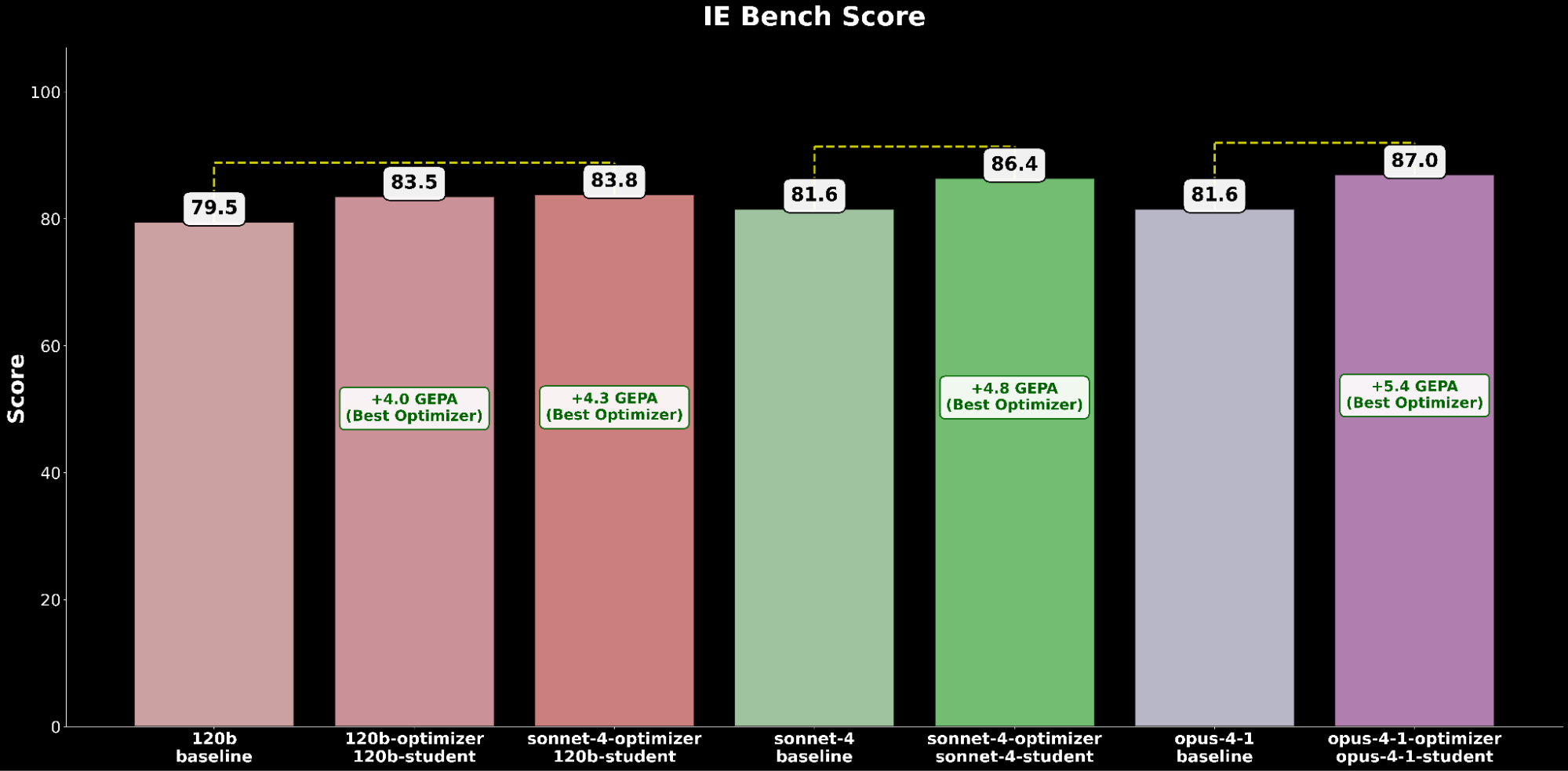
Dans les évaluations des modèles open-source et closed-source, nous constatons systématiquement que GEPA est l'optimiseur le plus performant, suivi de SIMBA, puis de MIPRO, ce qui permet d'obtenir des gains de qualité significatifs grâce à l'optimisation automatisée des invites.
Cependant, en termes de coût, nous observons que GEPA a une surcharge d'exécution relativement plus élevée (car l'exploration de l'optimisation peut nécessiter jusqu'à 3 fois plus d'appels LLM (~2-3 heures) que MIPRO et SIMBA (~1 heure))3 lors de cette analyse empirique de IE Bench. Nous prenons donc en compte l'efficacité coût et mettons à jour notre frontière de Pareto qualité-coût, en incluant les performances des modèles optimisés.
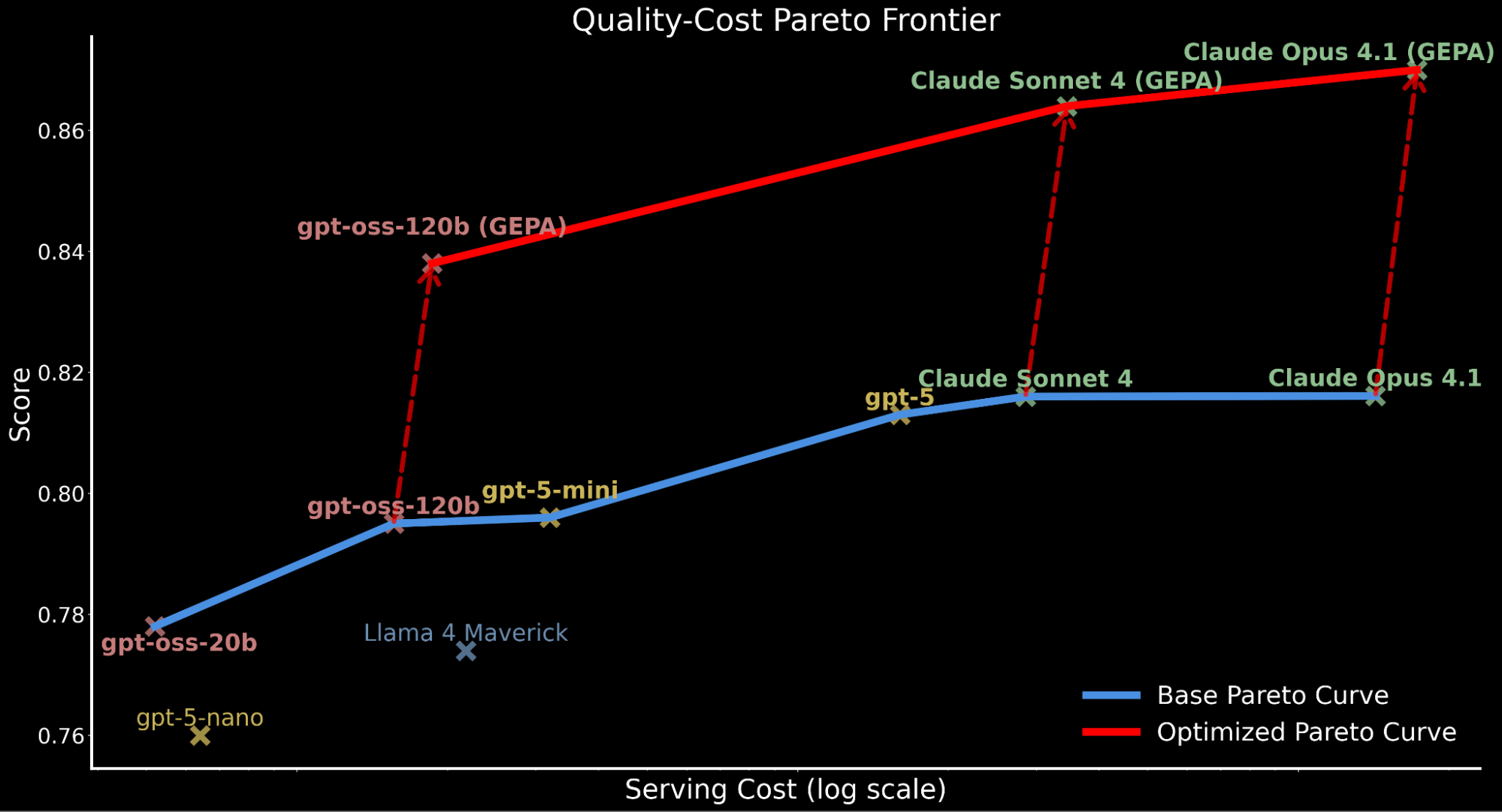
Nous soulignons comment l'application de l'optimisation automatisée des invites déplace l'ensemble de la courbe de Pareto vers le haut, établissant une nouvelle efficacité de pointe :
- gpt-oss-120b optimisé par GEPA surpasse la performance de référence de Claude Sonnet 4 et Claude Opus 4.1 tout en étant 22x et 90x moins cher.
- Pour les clients qui privilégient la qualité au coût, Claude Opus 4.1 optimisé par GEPA offre de nouvelles performances de pointe, soulignant les gains puissants pour les modèles de pointe qui ne peuvent pas être affinés.
- Nous attribuons l'augmentation du coût total de service des modèles optimisés par GEPA aux invites plus longues et plus détaillées par rapport à l'invite de référence produite par l'optimisation.
En appliquant des optimisations automatisées des invites aux agents, nous présentons une solution qui respecte les principes fondamentaux d'Agent Bricks : haute performance et efficacité des coûts.
Comparaison avec SFT
Le réglage fin supervisé (SFT) est souvent considéré comme la méthode par défaut pour améliorer les performances des modèles, mais comment se compare-t-il à l'optimisation automatisée des invites ?
Pour répondre à cette question, nous avons mené une expérience sur un sous-ensemble de IE Bench, en choisissant gpt 4.1 pour évaluer les performances de SFT et de l'optimisation automatisée des invites (Nous excluons gpt-oss et gpt-5 de ces comparaisons car les modèles n'étaient pas disponibles au moment de l'évaluation).
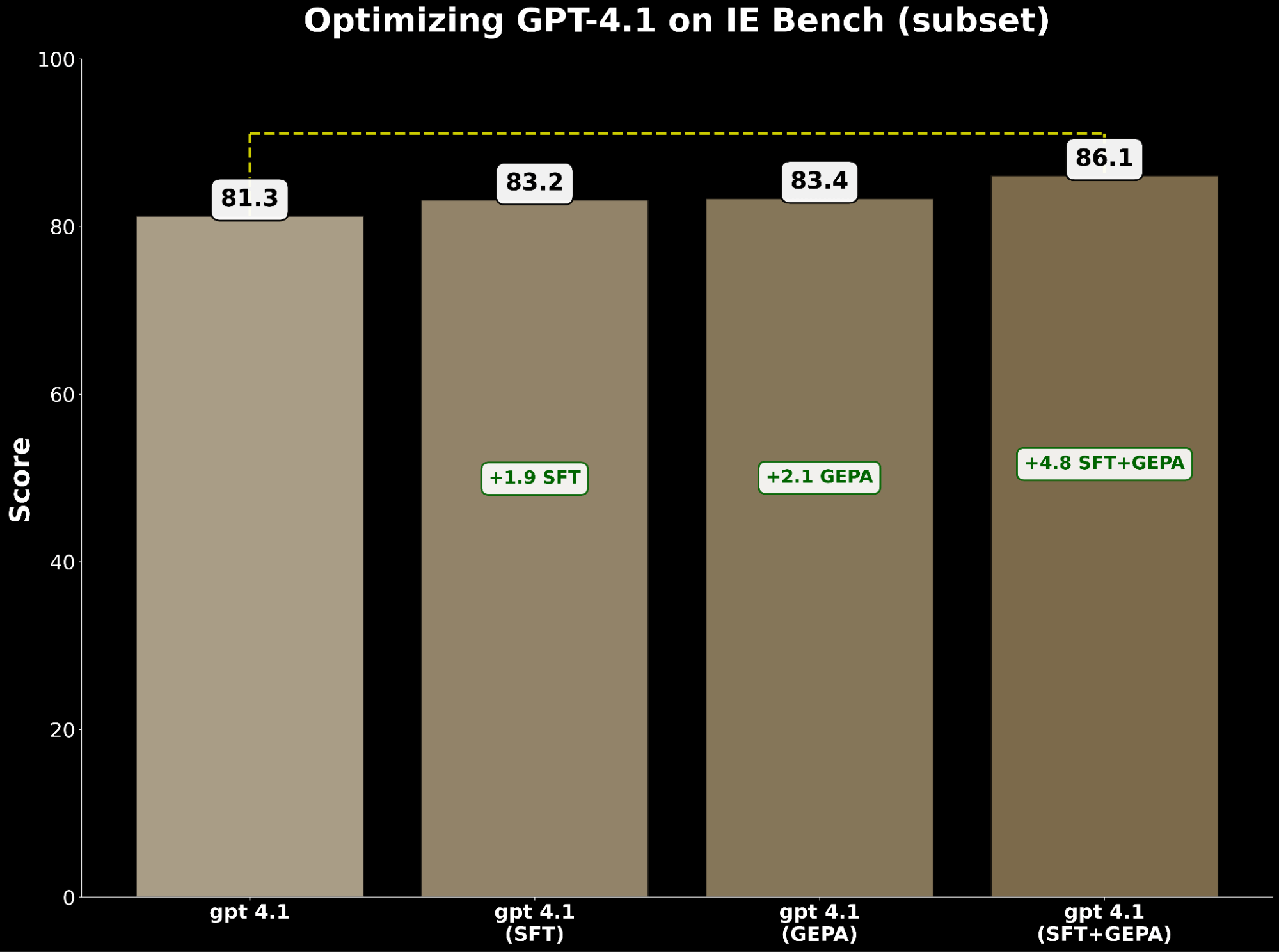
SFT et l'optimisation des invites améliorent indépendamment gpt-4.1. Spécifiquement :
- SFT gpt-4.1 a gagné +1,9 points par rapport à la référence.
- gpt-4.1 optimisé par GEPA a gagné +2,1 points, dépassant légèrement SFT.
Cela démontre que l'optimisation des invites peut égaler, voire surpasser, les améliorations du réglage fin supervisé.
Inspirés par BetterTogether, une technique qui consiste à alterner l'optimisation des invites et le réglage fin des poids du modèle pour améliorer les performances des LLM, nous appliquons GEPA en plus de SFT et obtenons un gain de +4,8 points par rapport à la référence, soulignant le fort potentiel de combinaison de ces techniques.
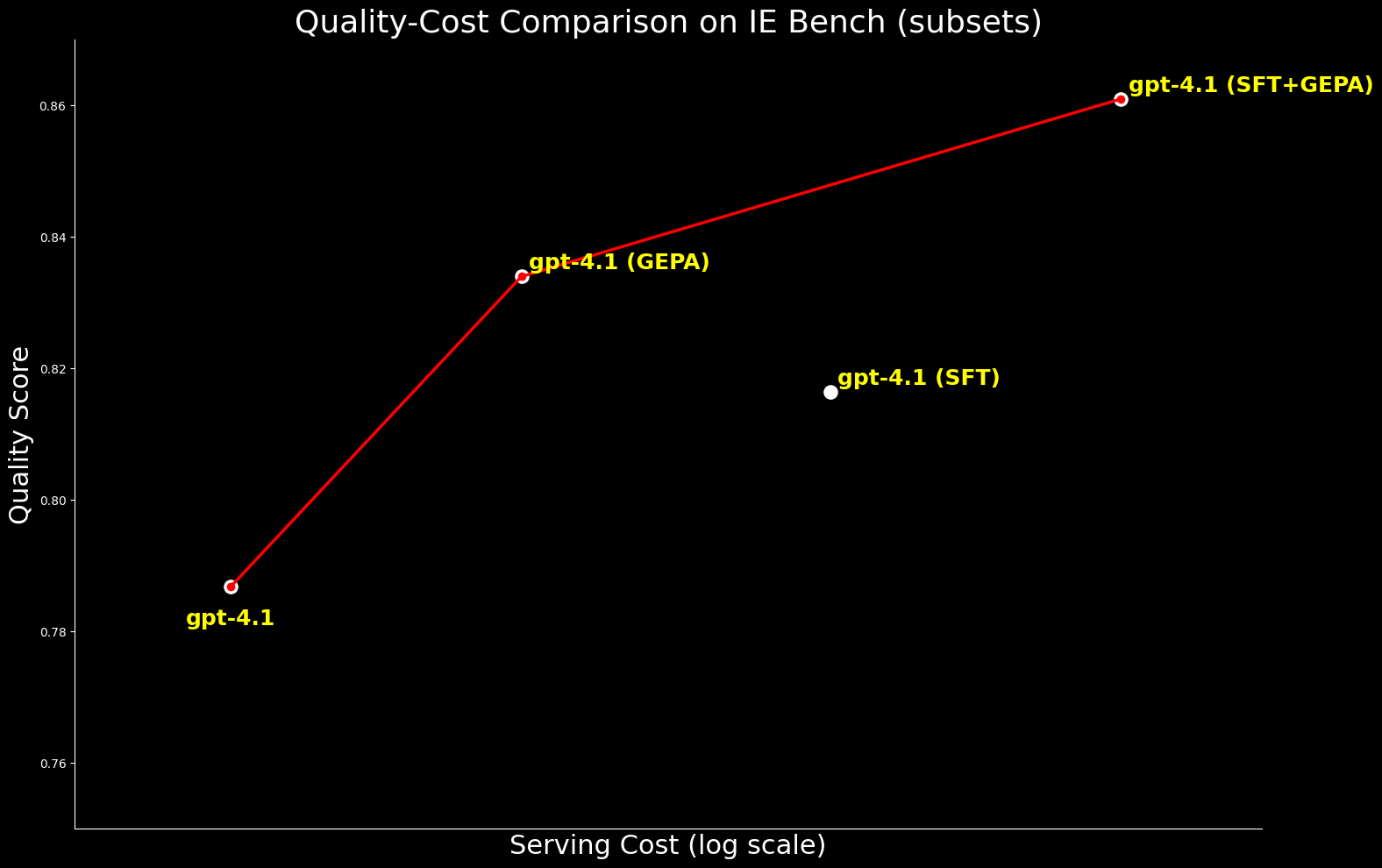
D'un point de vue coût, gpt-4.1 optimisé par GEPA coûte environ 20 % moins cher à servir que gpt-4.1 optimisé par SFT, tout en offrant une meilleure qualité. Cela montre que GEPA offre un équilibre qualité-coût supérieur à SFT. De plus, nous pouvons maximiser la qualité absolue en combinant GEPA avec SFT, ce qui donne une performance supérieure de 2,7 % à celle de SFT seul, mais avec un coût de service environ 22 % plus élevé.4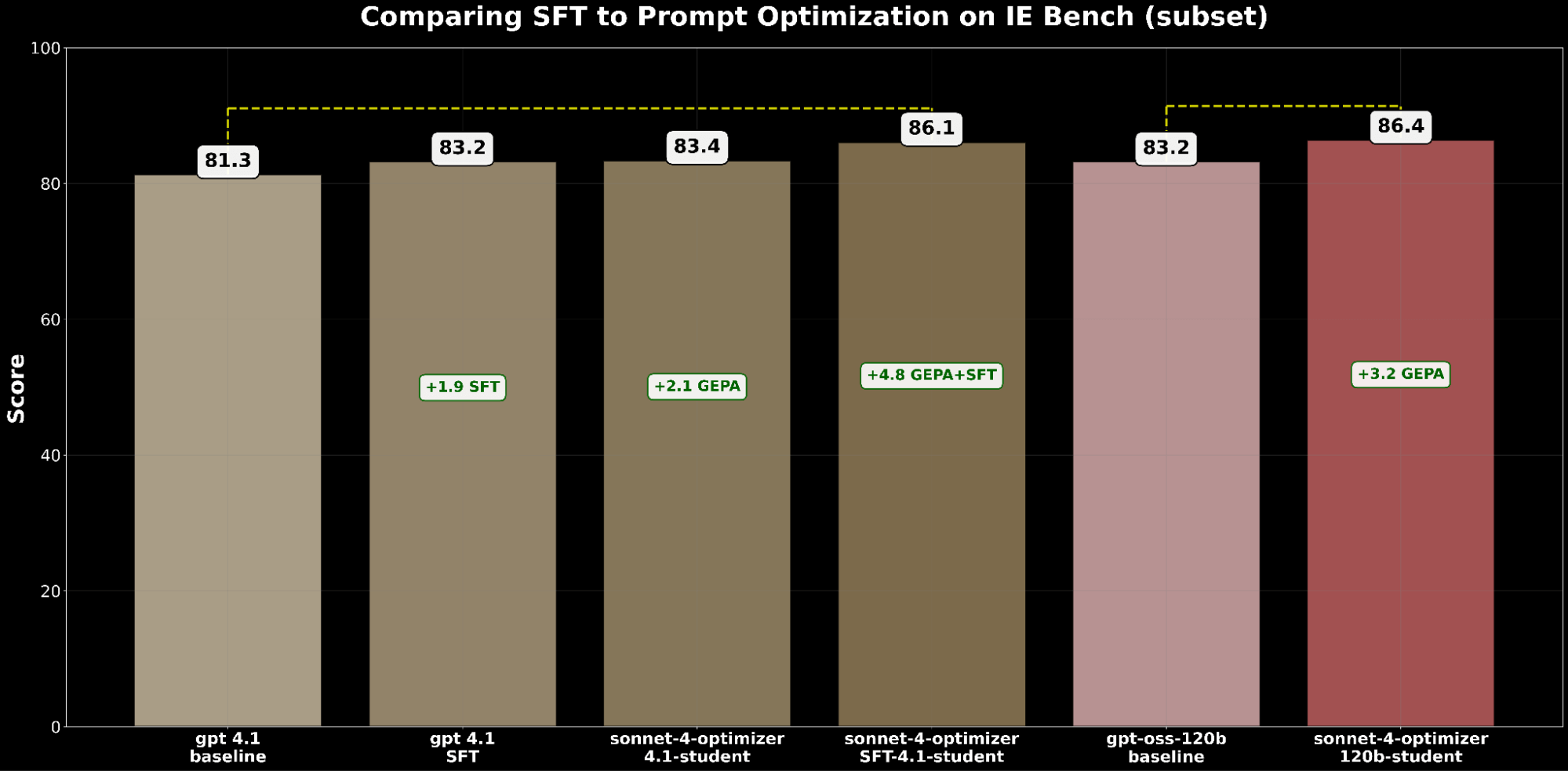
Nous avons étendu la comparaison à gpt-oss-120b pour examiner la frontière qualité-coût. Bien que gpt-4.1 optimisé par SFT+GEPA s'approche de la performance de gpt-oss-120b optimisé par GEPA (à 0,3 % près), ce dernier offre la même qualité à un coût de service 15 fois inférieur, ce qui le rend beaucoup plus pratique et attrayant pour un déploiement à grande échelle.

Ensemble, ces comparaisons soulignent les gains de performance importants permis par l'optimisation GEPA, qu'elle soit utilisée seule ou en combinaison avec SFT. Elles soulignent également l'efficacité exceptionnelle en termes de qualité-coût de gpt-oss-120b lorsqu'il est optimisé avec GEPA.
Coût de cycle de vie
Pour évaluer l'optimisation en termes réels, nous considérons le coût de cycle de vie pour les clients. L'objectif de l'optimisation n'est pas seulement d'améliorer la précision, mais aussi de produire un agent efficace capable de traiter les requêtes en production. Il est donc essentiel d'examiner à la fois le coût d'optimisation et le coût de service d'un grand volume de requêtes.
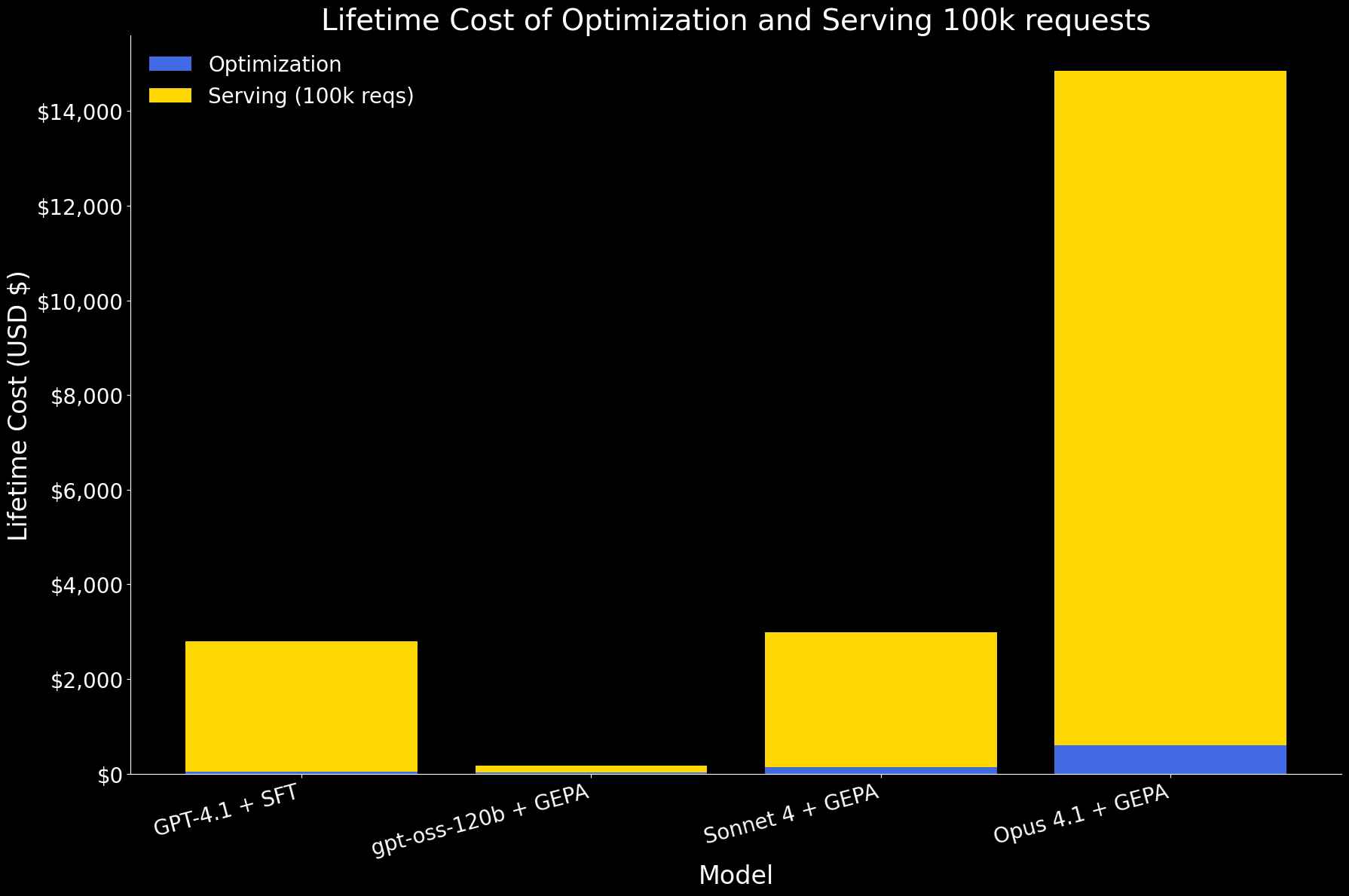
Dans le premier graphique ci-dessous, nous montrons le coût de cycle de vie de l'optimisation d'un agent et du service de 100 000 requêtes, ventilé en composantes d'optimisation et de service. À cette échelle, le service domine le coût global. Parmi les modèles :
- gpt-oss-120b avec GEPA est de loin le plus efficace, avec des coûts d'un ordre de grandeur inférieur pour l'optimisation et le service.
- GPT 4.1 avec SFT et Sonnet 4 avec GEPA ont un coût de cycle de vie similaire.
- Opus 4.1 avec GEPA est le plus cher, principalement en raison de son prix de service élevé.
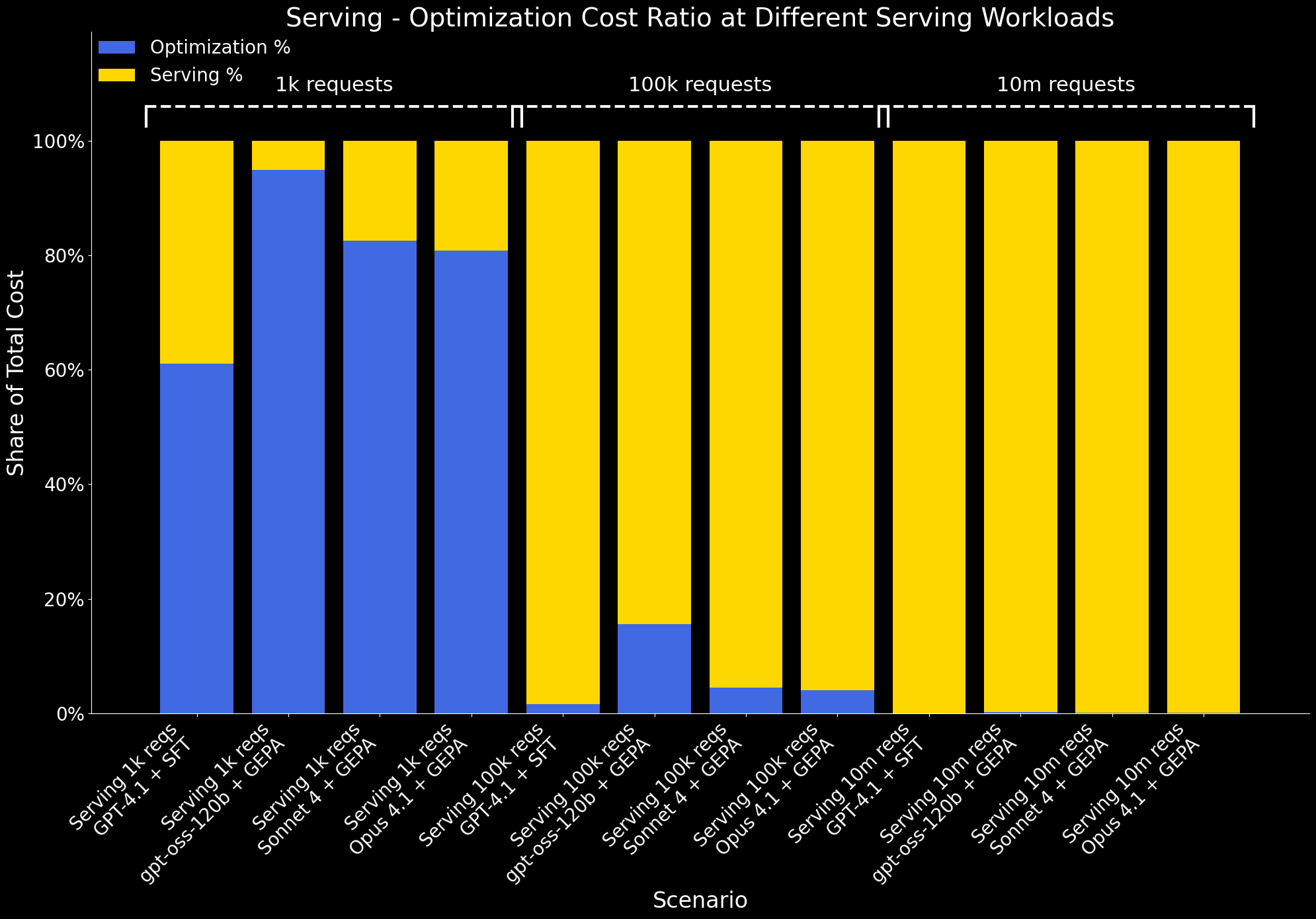
Nous examinons également comment le ratio du coût d'optimisation par rapport au coût de service évolue à différentes échelles de charge de travail :
- Pour 1 000 requêtes, les coûts de service sont minimes, donc l'optimisation représente une grande partie du coût total.
- À 100 000 requêtes, les coûts de service augmentent considérablement et la surcharge d'optimisation est amortie. À cette échelle, l'avantage de l'optimisation – meilleure performance à moindre coût de service – l'emporte clairement sur son coût unique.
- À 10 millions de requêtes, les coûts d'optimisation deviennent négligeables par rapport aux coûts de service et ne sont plus visibles sur le graphique.
Résumé
Dans cet article de blog, nous avons démontré que l'optimisation automatisée des invites est un levier puissant pour améliorer les performances des LLM dans les tâches d'IA d'entreprise :
- Nous avons développé IE Bench, une suite d'évaluation complète couvrant des domaines réels et capturant des défis complexes d'extraction d'informations.
- En appliquant l'optimisation automatisée des invites GEPA, nous augmentons les performances du modèle open-source leader gpt-oss-120b pour surpasser les performances du modèle propriétaire de pointe Claude Opus 4.1 de ~3 % tout en étant 90 fois moins cher à servir.
- La même technique s'applique aux modèles propriétaires de pointe, améliorant Claude Sonnet 4 et Claude Opus 4.1 de 6-7 %.
- Par rapport au réglage fin supervisé (SFT), l'optimisation GEPA offre un compromis qualité-coût supérieur pour une utilisation en entreprise. Elle offre des performances égales ou supérieures à SFT tout en réduisant les coûts de service de 20 %.
- L'analyse du coût de cycle de vie montre qu'en cas de service à grande échelle (par exemple, 100 000 requêtes), la surcharge d'optimisation unique est rapidement amortie, et les avantages dépassent largement le coût. Notamment, GEPA sur gpt-oss-120b offre un coût de cycle de vie inférieur d'un ordre de grandeur par rapport aux autres modèles de pointe, ce qui en fait un choix très attrayant pour les agents d'IA d'entreprise.
Ensemble, nos résultats montrent que l'optimisation des invites déplace la frontière de Pareto qualité-coût pour les systèmes d'IA d'entreprise, améliorant à la fois les performances et l'efficacité.
L'optimisation automatisée des invites, ainsi que les publications précédentes TAO, RLVR et ALHF, sont désormais disponibles dans Agent Bricks. Le principe fondamental d'Agent Bricks est d'aider les entreprises à créer des agents qui raisonnent avec précision sur vos données et atteignent une qualité et une efficacité de coût de pointe sur des tâches spécifiques au domaine. En unifiant l'évaluation, l'optimisation automatisée et le déploiement gouverné, Agent Bricks permet à vos agents de s'adapter à vos données et à vos tâches, d'apprendre des retours d'information et de s'améliorer continuellement sur vos tâches spécifiques au domaine d'entreprise. Nous encourageons les clients à essayer l'extraction d'informations et d'autres capacités d'Agent Bricks pour optimiser les agents pour vos propres cas d'utilisation d'entreprise.
1 Pour les séries de modèles gpt-oss et gpt-5, nous suivons les meilleures pratiques du format Harmony d'OpenAI qui insère le schéma JSON cible dans le message du développeur pour générer une sortie structurée.
Nous analysons également les différents efforts de raisonnement pour la série gpt-oss (faible, moyen, élevé) et la série gpt-5 (minimal, faible, moyen, élevé), et rapportons les meilleures performances de chaque modèle sur tous les efforts de raisonnement.
2 Pour les estimations de coûts de service, nous utilisons les prix publiés sur les plateformes des fournisseurs de modèles (OpenAI et Anthropic pour les modèles propriétaires) et d'Artificial Analysis pour les modèles open-source. Les coûts sont calculés en appliquant ces prix aux distributions de jetons d'entrée et de sortie observées dans IE Bench, ce qui nous donne le coût total de service pour chaque modèle.
3 Le temps d'exécution réel de l'optimisation automatisée des invites est difficile à estimer, car il dépend de nombreux facteurs. Voici une estimation approximative basée sur notre expérience empirique.
4 Nous estimons le coût de service de SFT gpt-4.1 en utilisant les prix des modèles affinés publiés par OpenAI. Pour les modèles optimisés GEPA, nous calculons le coût de service en fonction de l'utilisation des jetons d'entrée et de sortie mesurée des invites optimisées.
Auteurs : Arnav Singhvi, Ivan Zhou, Erich Elsen, Krista Opsahl-Ong, Michael Bendersky, Matei Zaharia, Xing Chen, Omar Khattab, Xiangrui Meng, Simon Favreau-Lessard
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.