La puissance de RLVR : entraînement d'un modèle de raisonnement SQL de premier plan sur Databricks
Une recette simple pour le raisonnement en entreprise
Mise à jour : Vous pouvez en savoir plus sur nos résultats dans notre nouveau rapport technique disponible ici sur arXiv.
Mise à jour (12 août 2025) : Notre modèle entraîné avec RLVR atteint désormais les meilleures performances sur Bird Bench dans la catégorie globale de modèle unique lorsqu'il est combiné avec l'auto-cohérence ! Nous surpassons les résultats de modèle unique avec et sans auto-cohérence (plusieurs appels LLM autorisés). Ci-dessous, nous avons discuté de la manière dont nous avions obtenu le meilleur modèle dans la catégorie modèle unique avec un seul appel LLM (c'est-à-dire sans auto-cohérence). Cela montre que la puissance de l'entraînement RLVR et l'utilisation de stratégies de calcul au moment du test telles que l'auto-cohérence peuvent être combinées de manière élégante. RLVR et le meilleur de N sont déployés auprès de nos clients dans Agent Bricks.
Chez Databricks, nous utilisons l'apprentissage par renforcement (RL) pour développer des modèles de raisonnement pour les problèmes auxquels nos clients sont confrontés ainsi que pour nos produits, tels que le Databricks Assistant et AI/BI Genie. Ces tâches incluent la génération de code, l'analyse de données, l'intégration des connaissances organisationnelles, l'évaluation spécifique au domaine et l'extraction d'informations (IE) à partir de documents. Des tâches comme le codage ou l'extraction d'informations ont souvent des récompenses vérifiables -- l'exactitude peut être vérifiée directement (par exemple, réussite des tests, correspondance des étiquettes). Cela permet l'apprentissage par renforcement sans modèle de récompense appris, connu sous le nom de RLVR (apprentissage par renforcement avec récompenses vérifiables). Dans d'autres domaines, un modèle de récompense personnalisé peut être requis -- ce que Databricks prend également en charge. Dans ce billet, nous nous concentrons sur le cadre RLVR.
À titre d'exemple de la puissance de RLVR, nous avons appliqué notre pile d'entraînement à un benchmark académique populaire en science des données appelé BIRD. Ce benchmark étudie la tâche de transformation d'une requête en langage naturel en code SQL qui s'exécute sur une base de données. C'est un problème important pour les utilisateurs de Databricks, permettant aux experts non-SQL de dialoguer avec leurs données. C'est aussi une tâche difficile où même les meilleurs LLM propriétaires ne fonctionnent pas bien immédiatement. Bien que BIRD ne capture pas entièrement la complexité du monde réel de cette tâche ni la pleine étendue des produits réels comme Databricks AI/BI Genie (Figure 1), sa popularité nous permet de mesurer l'efficacité de RLVR pour la science des données sur un benchmark bien compris.
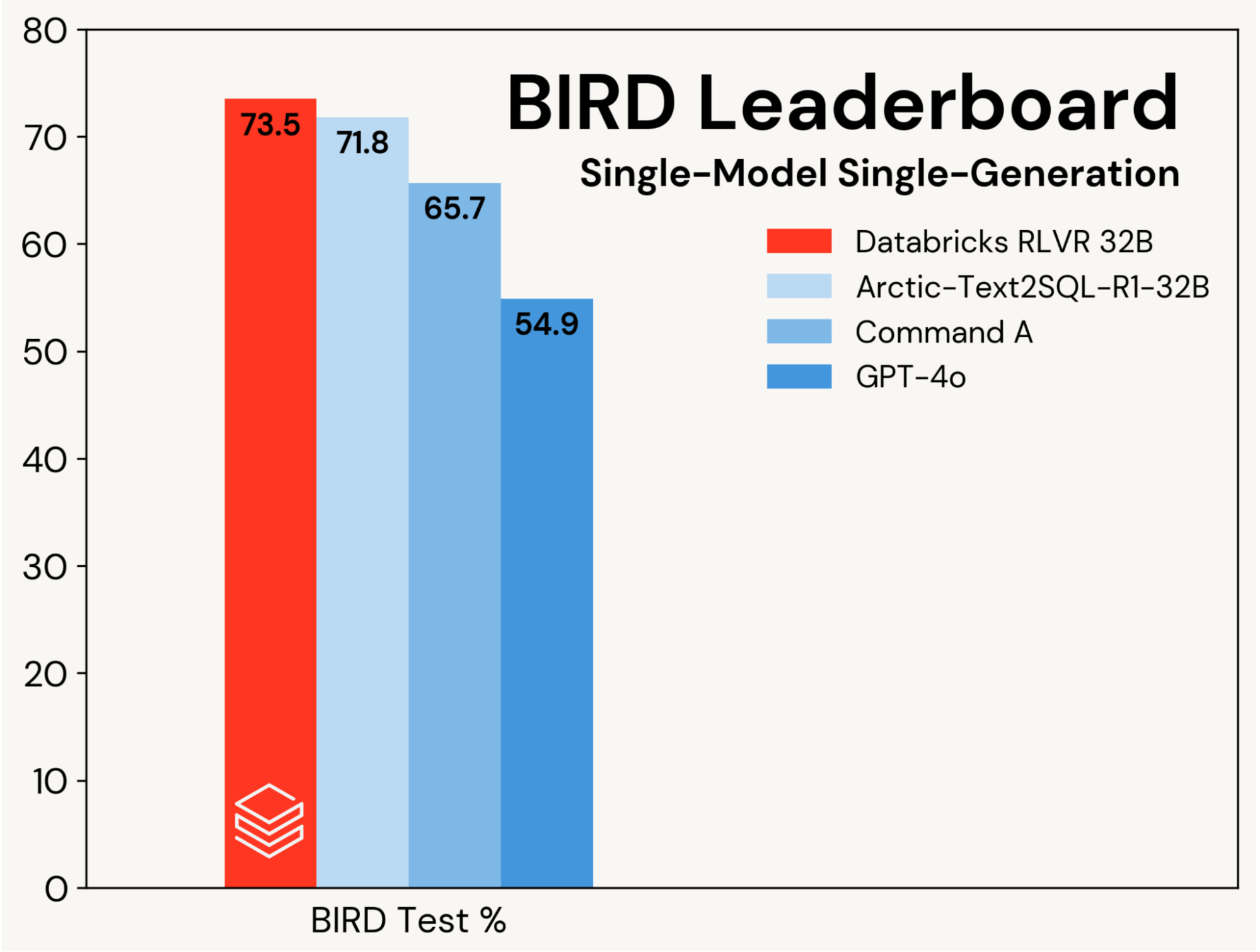
Nous nous concentrons sur l'amélioration d'un modèle de codage SQL de base à l'aide de RLVR, en isolant ces gains des améliorations dues aux conceptions d'agents. Les progrès sont mesurés sur la piste modèle unique, génération unique du classement BIRD (c'est-à-dire sans auto-cohérence), qui évalue sur un ensemble de test privé.
Nous avons établi une nouvelle précision de test de pointe de 73,5 % sur ce benchmark. Nous l'avons fait en utilisant notre pile RLVR standard et en entraînant uniquement sur l'ensemble d'entraînement BIRD. Le meilleur score précédent sur cette piste était de 71,8 %[1], obtenu en augmentant l'ensemble d'entraînement BIRD avec des données supplémentaires et en utilisant un LLM propriétaire (GPT-4o). Notre score est considérablement meilleur que celui du modèle de base d'origine et des LLM propriétaires (voir Figure 2). Ce résultat met en évidence la simplicité et la généralité de RLVR : nous avons atteint ce score avec des données standard et les composants RL standard que nous déployons dans Agent Bricks, et nous l'avons fait lors de notre première soumission à BIRD. RLVR est une base puissante que les développeurs d'IA devraient considérer chaque fois que suffisamment de données d'entraînement sont disponibles.
Nous avons construit notre soumission sur l'ensemble de développement BIRD. Nous avons constaté que Qwen 2.5 32B Coder Instruct était le meilleur point de départ. Nous avons affiné ce modèle en utilisant à la fois Databricks TAO – une méthode RL hors ligne, et notre pile RLVR. Cette approche, associée à une sélection minutieuse des invites et des modèles, a suffi à nous placer en tête du benchmark BIRD. Ce résultat est une démonstration publique des mêmes techniques que nous utilisons pour améliorer les produits Databricks populaires comme AI/BI Genie et Assistant et pour aider nos clients à créer des agents en utilisant Agent Bricks.
Nos résultats soulignent la puissance de RLVR et l'efficacité de notre pile d'entraînement. Les clients Databricks ont également rapporté d'excellents résultats en utilisant notre pile dans leurs domaines de raisonnement. Nous pensons que cette recette est puissante, composable et largement applicable à une gamme de tâches. Si vous souhaitez prévisualiser RLVR sur Databricks, contactez-nous ici.
1Voir Tableau 1 dans https://arxiv.org/pdf/2505.20315
Auteurs : Alnur Ali, Ashutosh Baheti, Jonathan Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Kumar Misra, Jose Javier Gonzalez Ortiz, Krista Opsahl-Ong
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.