TAO : Utiliser le calcul au moment des tests pour entraîner des LLM efficaces sans données étiquetées
Les grands modèles de langage sont difficiles à adapter aux nouvelles tâches d'entreprise. Le prompting est sujet aux erreurs et n'apporte que des gains de qualité limités, tandis que le fine-tuning nécessite de grandes quantités de données humaines étiquetées qui ne sont pas disponibles pour la plupart des tâches d'entreprise. Aujourd'hui, nous introduisons une nouvelle méthode de réglage de modèle qui ne nécessite que des données d'utilisation non étiquetées, permettant aux entreprises d'améliorer la qualité et le coût de l'IA en utilisant simplement les données qu'elles possèdent déjà. Notre méthode, Test-time Adaptive Optimization (TAO), exploite le calcul au moment du test (tel que popularisé par o1 et R1) et l'apprentissage par renforcement (RL) pour apprendre à un modèle à mieux accomplir une tâche en se basant uniquement sur les exemples d'entrée passés, ce qui signifie qu'il s'adapte à un budget de calcul de réglage réglable, et non à l'effort d'étiquetage humain. Crucialement, bien que TAO utilise le calcul au moment du test, il l'utilise dans le cadre du processus pour entraîner un modèle ; ce modèle exécute ensuite la tâche directement avec de faibles coûts d'inférence (c'est-à-dire qu'il ne nécessite pas de calcul supplémentaire au moment de l'inférence). Étonnamment, même sans données étiquetées, TAO peut atteindre une meilleure qualité de modèle que le fine-tuning traditionnel, et il peut amener des modèles open source peu coûteux comme Llama à la qualité de modèles propriétaires coûteux comme GPT-4o et o3-mini.
TAO fait partie du programme de notre équipe de recherche sur l'intelligence des données — le problème de faire exceller l'IA dans des domaines spécifiques en utilisant les données que les entreprises possèdent déjà. Avec TAO, nous obtenons trois résultats passionnants :
- Sur des tâches d'entreprise spécialisées telles que la réponse aux questions sur les documents et la génération de SQL, TAO surpasse le fine-tuning traditionnel sur des milliers d'exemples étiquetés. Il amène des modèles open source efficaces comme Llama 8B et 70B à une qualité similaire à celle de modèles coûteux comme GPT-4o et o3-mini1 sans avoir besoin d'étiquettes.
- Nous pouvons également utiliser le TAO multi-tâches pour améliorer un LLM de manière générale sur de nombreuses tâches. Sans utiliser d'étiquettes, TAO améliore les performances de Llama 3.3 70B de 2,4 % sur un benchmark d'entreprise général.
- L'augmentation du budget de calcul de TAO au moment du réglage produit une meilleure qualité de modèle avec les mêmes données, tandis que les coûts d'inférence du modèle réglé restent les mêmes.
La Figure 1 montre comment TAO améliore les modèles Llama sur trois tâches d'entreprise : FinanceBench, DB Enterprise Arena et BIRD-SQL (en utilisant le dialecte Databricks SQL)². Bien qu'ayant seulement accès aux entrées LLM, TAO surpasse le fine-tuning traditionnel (FT) avec des milliers d'exemples étiquetés et amène Llama dans la même gamme que les modèles propriétaires coûteux.
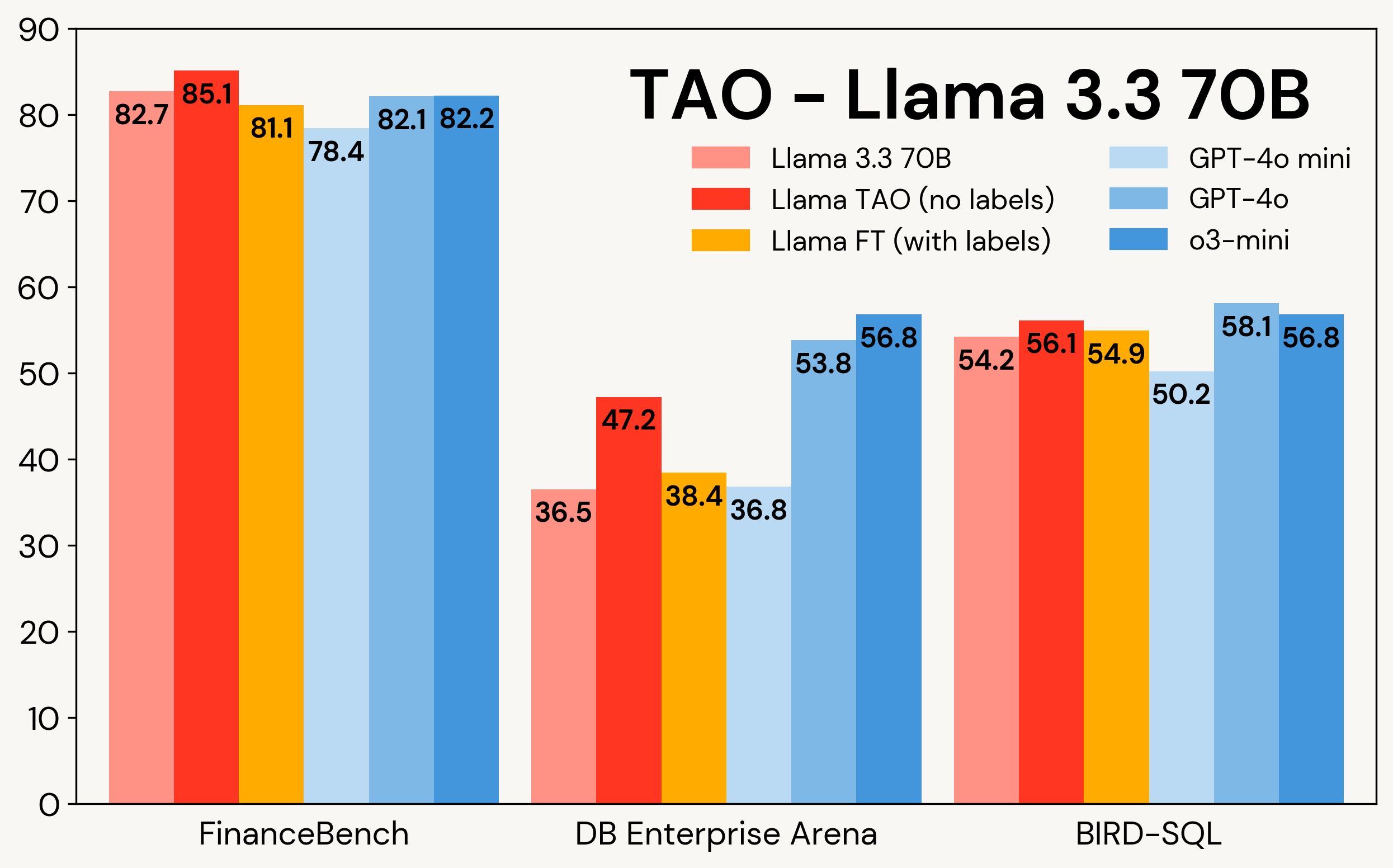
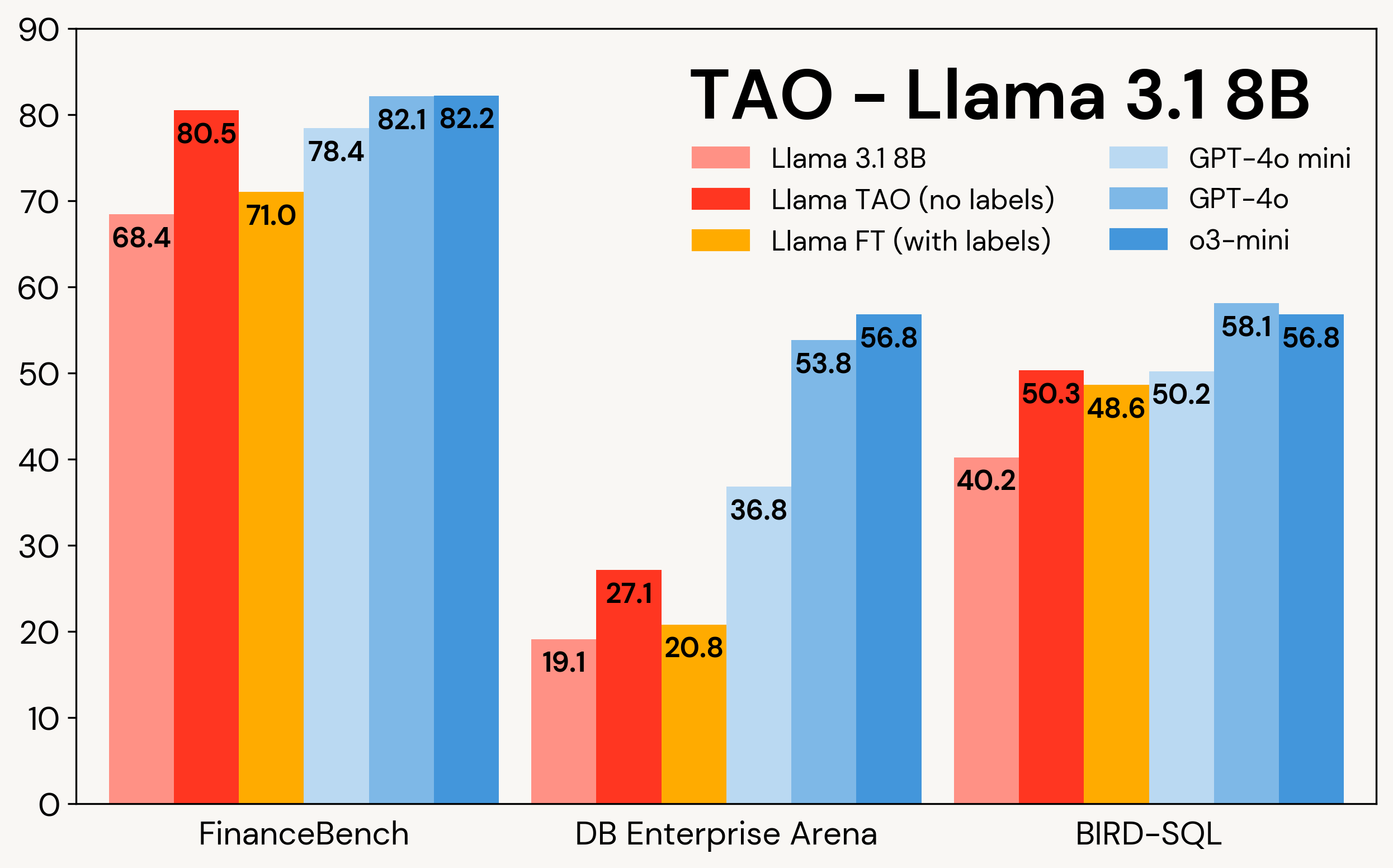
Figure 1 : TAO sur Llama 3.1 8B et Llama 3.3 70B sur trois benchmarks d'entreprise. TAO entraîne des améliorations substantielles de la qualité, surpassant le fine-tuning et défiant les LLM propriétaires coûteux.
TAO est maintenant disponible en avant-première pour les clients Databricks qui souhaitent régler Llama, et il alimentera plusieurs produits à venir. Remplissez ce formulaire pour exprimer votre intérêt à l'essayer sur vos tâches dans le cadre de l'avant-première privée. Dans cet article, nous décrivons plus en détail le fonctionnement de TAO et nos résultats avec.
Comment fonctionne TAO ? Utilisation du calcul au moment du test et de l'apprentissage par renforcement pour régler les modèles
Au lieu de nécessiter des données de sortie annotées par des humains, l'idée clé de TAO est d'utiliser le calcul au moment du test pour qu'un modèle explore des réponses plausibles pour une tâche, puis d'utiliser l'apprentissage par renforcement pour mettre à jour un LLM en évaluant ces réponses. Ce pipeline peut être mis à l'échelle en utilisant le calcul au moment du test, au lieu d'un effort humain coûteux, pour augmenter la qualité. De plus, il peut facilement être personnalisé en utilisant des informations spécifiques à la tâche (par exemple, des règles personnalisées). Étonnamment, l'application de cette mise à l'échelle avec des modèles open source de haute qualité conduit dans de nombreux cas à de meilleurs résultats que les étiquettes humaines.
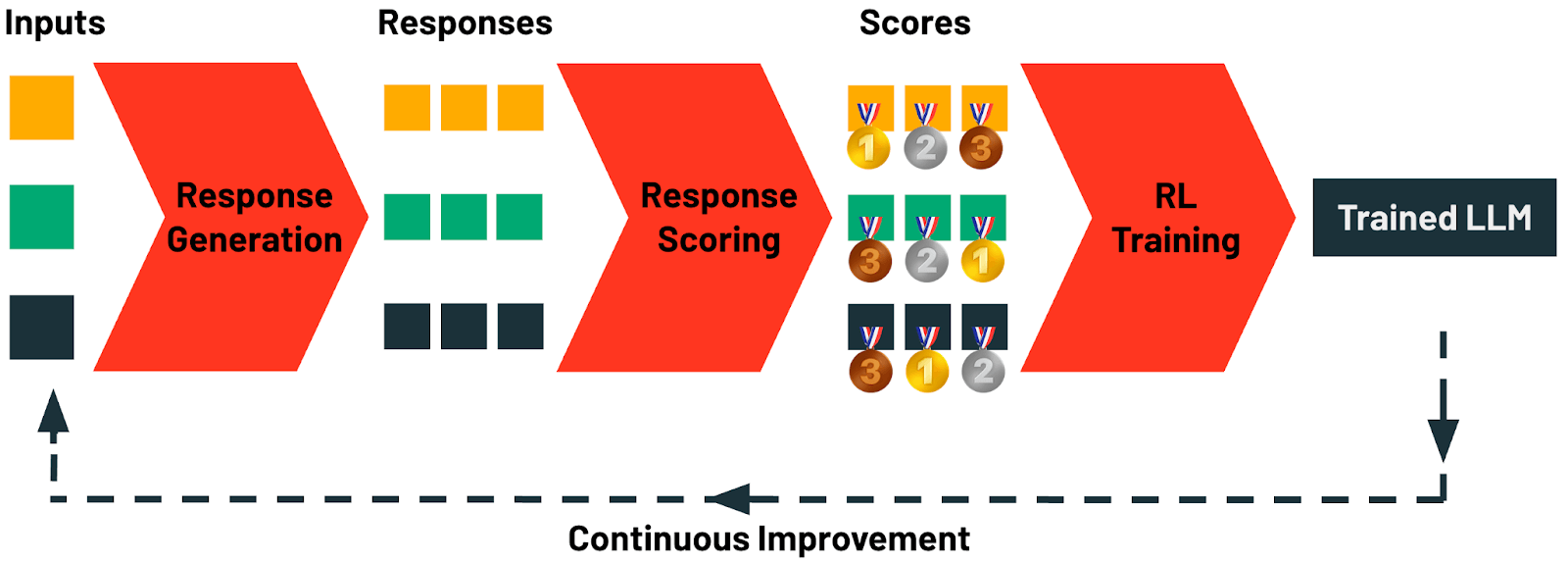
Plus précisément, TAO comprend quatre étapes :
- Génération de réponses : Cette étape commence par la collecte d'exemples de prompts ou de requêtes pour une tâche. Sur Databricks, ces prompts peuvent être collectés automatiquement à partir de n'importe quelle application d'IA à l'aide de notre passerelle IA. Chaque prompt est ensuite utilisé pour générer un ensemble diversifié de réponses candidates. Un riche spectre de stratégies de génération peut être appliqué ici, allant du simple prompting en chaîne de pensée à des techniques de raisonnement et de prompting structuré sophistiquées.
- Évaluation des réponses : Dans cette étape, les réponses générées sont systématiquement évaluées. Les méthodologies d'évaluation comprennent une variété de stratégies, telles que la modélisation de récompense, l'évaluation basée sur les préférences, ou la vérification spécifique à la tâche utilisant des juges LLM ou des règles personnalisées. Cette étape garantit que chaque réponse générée est quantitativement évaluée pour sa qualité et son alignement avec les critères.
- Entraînement par apprentissage par renforcement (RL) : Dans la dernière étape, une approche basée sur le RL est appliquée pour mettre à jour le LLM, guidant le modèle à produire des sorties étroitement alignées avec les réponses bien notées identifiées à l'étape précédente. Grâce à ce processus d'apprentissage adaptatif, le modèle affine ses prédictions pour améliorer la qualité.
- Amélioration continue : Les seules données dont TAO a besoin sont des exemples d'entrées LLM. Les utilisateurs créent naturellement ces données en interagissant avec un LLM. Dès que votre LLM est déployé, vous commencez à générer des données d'entraînement pour la prochaine itération de TAO. Sur Databricks, votre LLM peut s'améliorer à mesure que vous l'utilisez, grâce à TAO.
Crucialement, bien que TAO utilise le calcul au moment du test, il l'utilise pour entraîner un modèle qui exécute ensuite une tâche directement avec de faibles coûts d'inférence. Cela signifie que les modèles produits par TAO ont le même coût et la même vitesse d'inférence que le modèle d'origine - considérablement moins que les modèles de calcul au moment du test comme o1, o3 et R1. Comme nos résultats le montrent, les modèles open source efficaces entraînés avec TAO peuvent rivaliser avec les principaux modèles propriétaires en termes de qualité.
TAO offre une nouvelle méthode puissante dans la boîte à outils pour le réglage des modèles d'IA. Contrairement à l'ingénierie de prompt, qui est lente et sujette aux erreurs, et au fine-tuning, qui nécessite la production d'étiquettes humaines coûteuses et de haute qualité, TAO permet aux ingénieurs IA d'obtenir d'excellents résultats en fournissant simplement des exemples d'entrées représentatifs de leur tâche.
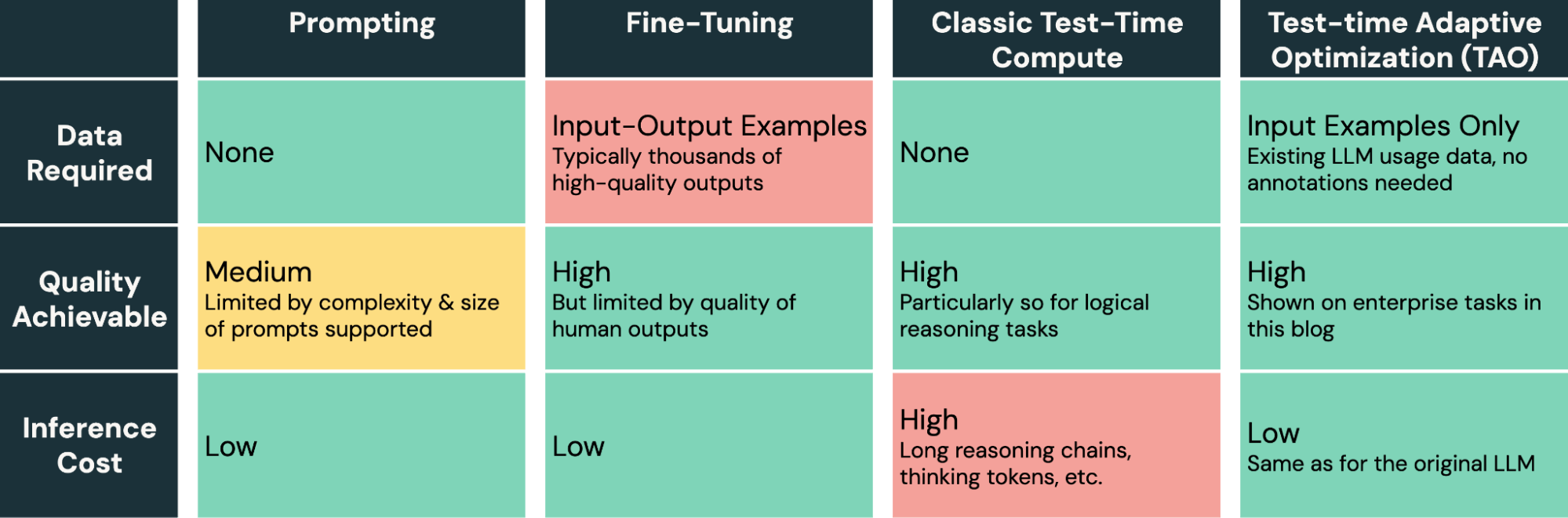
TAO est une méthode très flexible qui peut être personnalisée si nécessaire, mais notre implémentation par défaut dans Databricks fonctionne bien prête à l'emploi sur diverses tâches d'entreprise. Au cœur de notre implémentation se trouvent de nouvelles techniques d'apprentissage par renforcement et de modélisation de récompense que notre équipe a développées, permettant à TAO d'apprendre par exploration, puis de régler le modèle sous-jacent à l'aide du RL. Par exemple, l'un des ingrédients qui alimentent TAO est un modèle de récompense personnalisé que nous avons entraîné pour les tâches d'entreprise, DBRM, capable de produire des signaux d'évaluation précis sur un large éventail de tâches.
Amélioration des performances des tâches avec TAO
Dans cette section, nous approfondissons la manière dont nous avons utilisé TAO pour régler les LLM sur des tâches d'entreprise spécialisées. Nous avons sélectionné trois benchmarks représentatifs, y compris des benchmarks open source populaires et des benchmarks internes que nous avons développés dans le cadre de notre Domain Intelligence Benchmark Suite (DIBS).

Pour chaque tâche, nous avons évalué plusieurs approches :
- Utilisation d'un modèle Llama open source (Llama 3.1-8B ou Llama 3.3-70B) tel quel.
- Fine-tuning sur Llama. Pour ce faire, nous avons utilisé ou créé de grands ensembles de données d'entrée-sortie réalistes avec des milliers d'exemples, ce qui est généralement nécessaire pour obtenir de bonnes performances avec le fine-tuning. Ceux-ci comprenaient :
- 7200 questions synthétiques sur des documents SEC pour FinanceBench.
- 4800 entrées écrites par des humains pour DB Enterprise Arena.
- 8137 exemples de l'ensemble d'entraînement BIRD-SQL, modifiés pour correspondre au dialecte Databricks SQL.
- TAO sur Llama, en utilisant uniquement les exemples d'entrée de nos ensembles de données de fine-tuning, mais pas les sorties, et en utilisant notre modèle de récompense DBRM axé sur l'entreprise. DBRM lui-même n'est pas entraîné sur ces benchmarks.
- LLM propriétaires de haute qualité – GPT 4o-mini, GPT 4o et o3-mini.
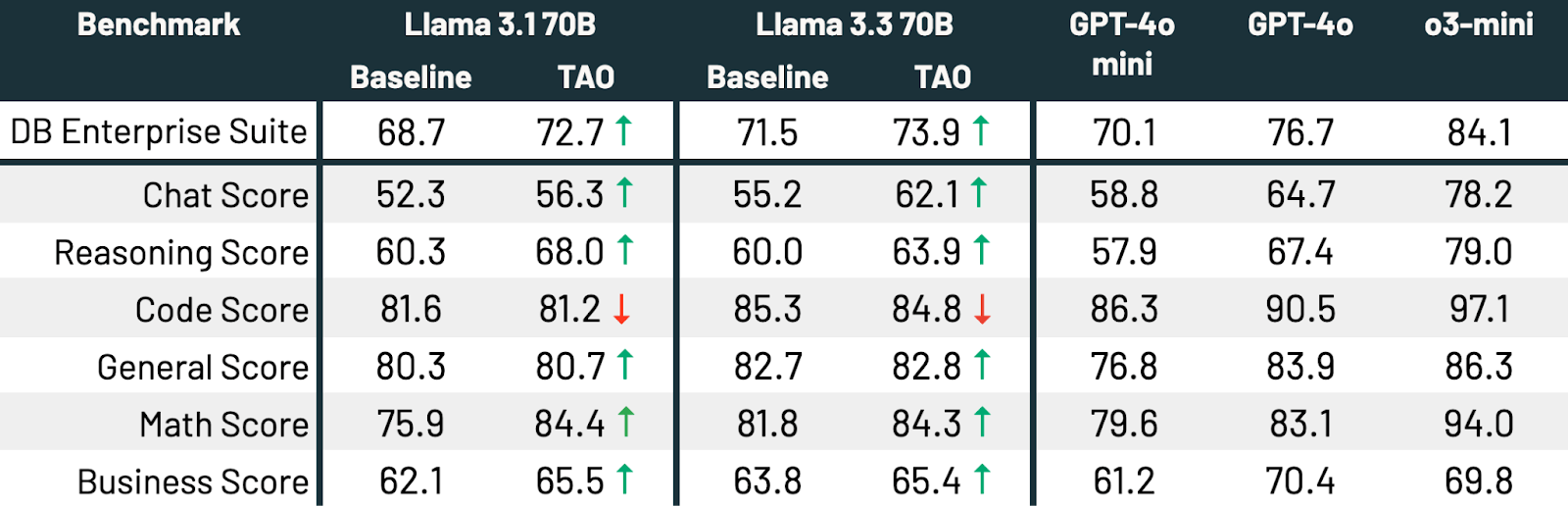
Comme le montre le Tableau 3, sur les trois benchmarks et les deux modèles Llama, TAO améliore significativement les performances de base de Llama, dépassant même celles du fine-tuning.

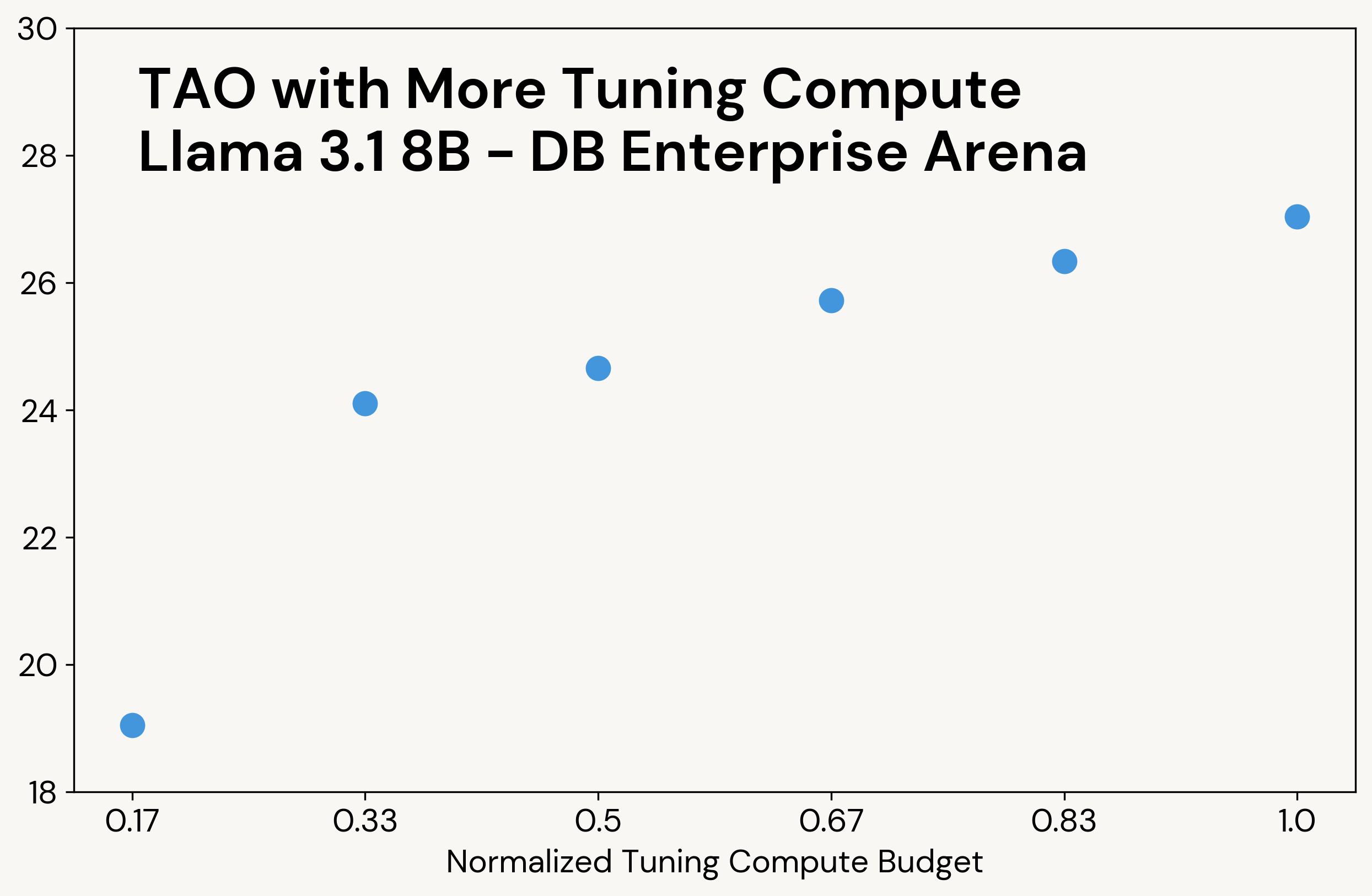
À l'instar du calcul classique en temps de test, TAO produit des résultats de meilleure qualité lorsqu'il a accès à plus de ressources de calcul (voir la Figure 3 pour un exemple). Contrairement au calcul en temps de test, cependant, ce calcul supplémentaire n'est utilisé que pendant la phase de réglage ; le LLM final a le même coût d'inférence que le LLM d'origine. Par exemple, o3-mini produit 5 à 10 fois plus de tokens de sortie que les autres modèles sur nos tâches, ce qui entraîne un coût d'inférence proportionnellement plus élevé, tandis que TAO a le même coût d'inférence que le modèle Llama d'origine.
Améliorer l'intelligence multitâche avec TAO
Jusqu'à présent, nous avons utilisé TAO pour améliorer les LLM sur des tâches individuelles et spécifiques, telles que la génération de SQL. Cependant, à mesure que les agents deviennent plus complexes, les entreprises ont de plus en plus besoin de LLM capables d'effectuer plusieurs tâches. Dans cette section, nous montrons comment TAO peut améliorer globalement les performances du modèle sur une gamme de tâches d'entreprise.
Dans cette expérience, nous avons rassemblé 175 000 invites reflétant un ensemble diversifié de tâches d'entreprise, notamment le codage, les mathématiques, la réponse aux questions, la compréhension de documents et le chat. Nous avons ensuite exécuté TAO sur Llama 3.1 70B et Llama 3.3 70B. Enfin, nous avons testé une suite de tâches pertinentes pour les entreprises, qui comprend des benchmarks LLM populaires (par exemple, Arena Hard, LiveBench, GPQA Diamond, MMLU Pro, HumanEval, MATH) et des benchmarks internes dans plusieurs domaines pertinents pour les entreprises.
TAO améliore significativement les performances des deux modèles[t][u]. Llama 3.3 70B et Llama 3.1 70B s'améliorent respectivement de 2,4 et 4,0 points de pourcentage. TAO rapproche significativement Llama 3.3 70B de GPT-4o sur les tâches d'entreprise[v][w]. Tout cela est réalisé sans coût d'étiquetage humain, juste avec des données d'utilisation représentatives des LLM et notre implémentation de production de TAO. La qualité s'améliore sur tous les sous-scores, sauf le codage, où les performances sont statiques.
Utiliser TAO en pratique
TAO est une méthode de réglage puissante qui fonctionne étonnamment bien sur de nombreuses tâches en tirant parti du calcul en temps de test. Pour l'utiliser avec succès sur vos propres tâches, vous aurez besoin de :
- Sufficient exemples d'entrées pour votre tâche (plusieurs milliers), collectés à partir d'une application d'IA déployée (par exemple, questions envoyées à un agent) ou générés synthétiquement.
- Une méthode de notation suffisamment précise : pour les clients Databricks, un outil puissant ici est notre modèle de récompense personnalisé, DBRM, qui alimente notre implémentation de TAO, mais vous pouvez augmenter DBRM avec des règles de notation ou des vérificateurs personnalisés s'ils sont applicables à votre tâche.
Une bonne pratique qui permettra à TAO et à d'autres méthodes d'amélioration de modèle est de créer un cercle vertueux de données pour vos applications d'IA. Dès que vous déployez une application d'IA, vous pouvez collecter des entrées, des sorties de modèle et d'autres événements via des services tels que Databricks Inference Tables. Vous pouvez ensuite utiliser uniquement les entrées pour exécuter TAO. Plus les gens utilisent votre application, plus vous aurez de données pour l'affiner, et - grâce à TAO - meilleur sera votre LLM.
Conclusion et démarrage sur Databricks
Dans ce blog, nous avons présenté Test-time Adaptive Optimization (TAO), une nouvelle technique de réglage de modèle qui obtient des résultats de haute qualité sans avoir besoin de données étiquetées. Nous avons développé TAO pour relever un défi majeur que nous avons constaté chez nos clients d'entreprise : ils manquaient des données étiquetées nécessaires au fine-tuning standard. TAO utilise le calcul en temps de test et l'apprentissage par renforcement pour améliorer les modèles en utilisant les données que les entreprises possèdent déjà, telles que des exemples d'entrées, ce qui permet d'améliorer facilement la qualité de toute application d'IA déployée et de réduire les coûts en utilisant des modèles plus petits. TAO est une méthode très flexible qui montre la puissance du calcul en temps de test pour le développement d'IA spécialisé, et nous pensons qu'elle donnera aux développeurs un nouvel outil puissant et simple à utiliser aux côtés du prompting et du fine-tuning.
Les clients Databricks utilisent déjà TAO sur Llama en avant-première privée. Remplissez ce formulaire pour exprimer votre intérêt à l'essayer sur vos tâches dans le cadre de l'avant-première privée. TAO est également intégré dans plusieurs de nos futures mises à jour et lancements de produits d'IA - restez à l'écoute !
¹ Auteurs : Raj Ammanabrolu, Ashutosh Baheti, Jonathan Chang, Xing Chen, Ta-Chung Chi, Brian Chu, Brandon Cui, Erich Elsen, Jonathan Frankle, Ali Ghodsi, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Misra, Jose Javier Gonzalez Ortiz, Sean Owen, Mihir Patel, Mansheej Paul, Cory Stephenson, Alex Trott, Ziyi Yang, Matei Zaharia, Andy Zhang, Ivan Zhou
² Nous utilisons o3-mini-medium tout au long de ce blog.
³ Il s'agit du benchmark BIRD-SQL modifié pour le dialecte et les produits SQL de Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.