Sécurité de l'IA agentique : Nouveaux risques et contrôles dans le cadre de sécurité de l'IA Databricks (DASF v3.0)
35 nouveaux risques d'IA agentic et 6 contrôles d'atténuation pour les agents qui accèdent aux données, appellent des outils et exécutent des actions
par David Veuve, Omar Khawaja, Arun Pamulapati, Nishith Sinha et Caelin Kaplan
- Le Databricks AI Security Framework (DASF) couvre désormais l'IA Agentic comme 13ème composant système, ajoutant 35 nouveaux risques de sécurité techniques et 6 nouveaux contrôles d'atténuation pour aider les organisations à déployer des agents autonomes en toute confiance.
- Cette extension aborde les risques uniques liés à la mémoire, à la planification et à l'utilisation d'outils des agents, y compris les menaces introduites par le Model Context Protocol (MCP), la norme émergente pour connecter les agents aux outils d'entreprise.
- Le livre blanc DASF Agentic AI Extension et le compendium mis à jour sont disponibles dès maintenant. Téléchargez-les pour évaluer vos architectures d'agents, cartographier vos écosystèmes d'outils et mettre en œuvre des contrôles de défense en profondeur spécialement conçus pour l'autonomie.
Nous sommes ravis d'annoncer la publication du livre blanc sur l'Agentic AI Extension du Databricks AI Security Framework (DASF) ! Les clients Databricks déploient déjà des agents IA qui interrogent des bases de données, appellent des API externes, exécutent du code et se coordonnent avec d'autres agents. Nous entendons constamment les équipes responsables de ces déploiements poser des questions difficiles : que se passe-t-il lorsque l'IA peut faire des choses, pas seulement dire des choses ? C'est pourquoi nous avons étendu le DASF.
Avec cette mise à jour, nous introduisons de nouvelles directives pour sécuriser les agents IA autonomes :
- 35 nouveaux risques de sécurité pour les agents IA couvrant le raisonnement, la mémoire et l'utilisation des outils par les agents
- 6 nouveaux contrôles d'atténuation incluant le moindre privilège, le sandboxing et la supervision humaine
- Conseils de sécurité pour les serveurs et clients d'outils du Model Context Protocol (MCP)
- Couverture des risques des systèmes multi-agents et des menaces de communication entre agents
Ensemble, ces ajouts aident les organisations à déployer des agents IA en toute sécurité tout en maintenant la gouvernance, l'observabilité et les contrôles de sécurité de défense en profondeur.
Cela porte le framework complet à 97 risques et 73 contrôles. Nous avons mis à jour le compendium DASF (feuille Google, Excel) pour inclure ces nouveaux risques et contrôles, en les faisant correspondre aux normes de l'industrie pour faciliter l'op�érationnalisation immédiate. Ces ajouts sont catalogués sous le nom de DASF v3.0 dans la colonne "DASF Revision".
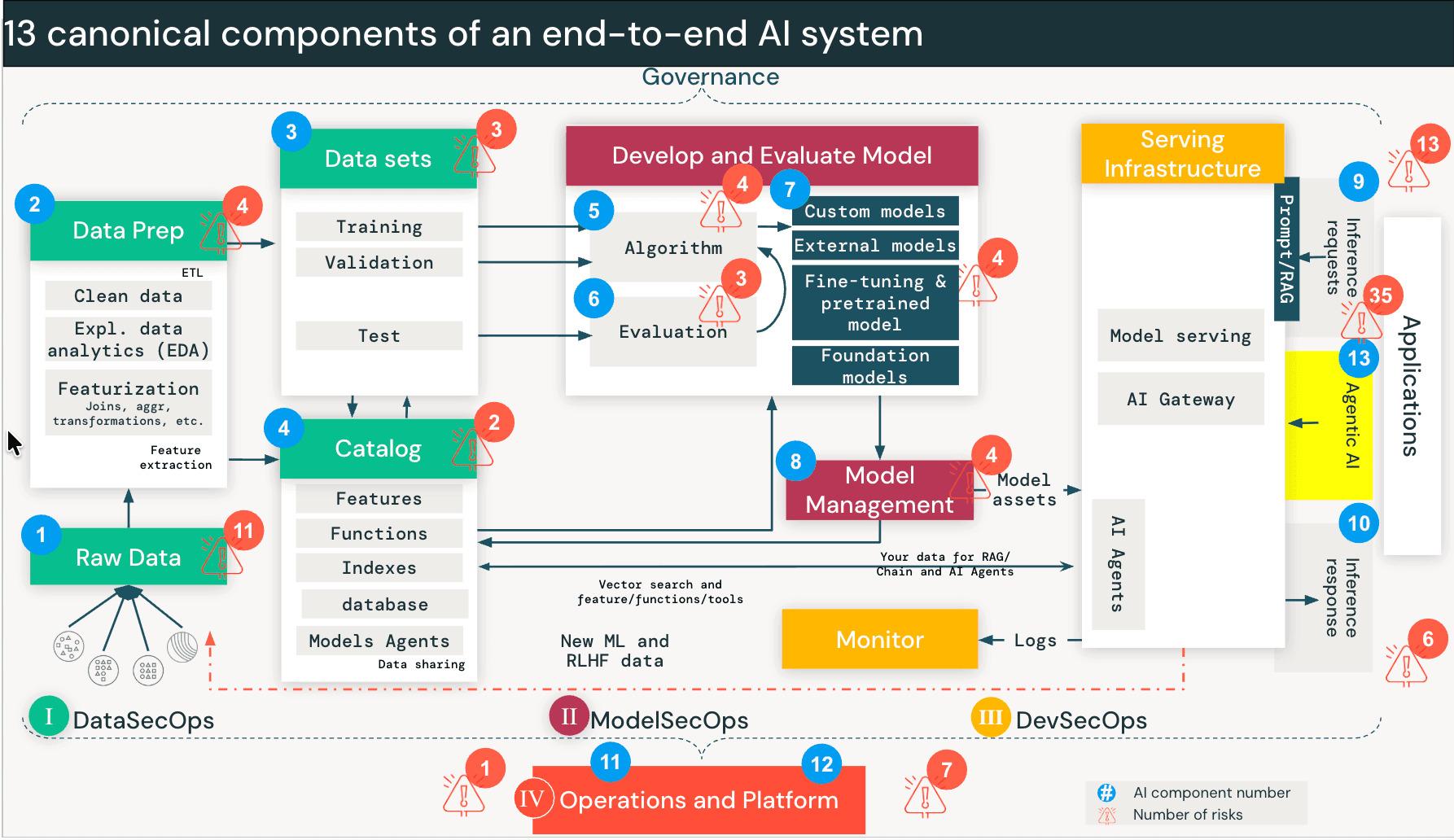
{kind=link}
Risques de sécurité lorsque les agents IA peuvent agir
Les systèmes IA traditionnels comme RAG fonctionnent principalement en mode lecture seule. Mais les agents IA peuvent effectuer des actions telles que l'interrogation de bases de données, l'appel d'API, l'exécution de code et l'interaction avec des outils externes.
Les agents fonctionnent différemment. Lorsqu'un utilisateur interagit avec un agent, le modèle lance une boucle : il décompose la requête en sous-tâches, choisit un outil (par exemple, "Interroger la base de données des ventes"), l'exécute, évalue le résultat et décide s'il faut appeler un autre outil ensuite. Cela continue jusqu'à ce que la tâche soit terminée. L'agent prend des décisions en temps réel sur les données auxquelles accéder et les outils à invoquer — des décisions qui étaient auparavant prises par des humains ou codées en dur dans la logique de l'application.
Cela crée une nouvelle classe de risque que nous appelons Découverte et Parcours. Un agent conçu pour trouver des solutions parcourra des chemins de données et des interfaces d'outils qui n'étaient jamais destinés à l'utilisateur demandeur. Il n'exploite pas un bug. Il fait exactement ce pour quoi il a été conçu. Mais sans contrôles appropriés, l'utilisateur hérite effectivement des autorisations de l'agent plutôt que des siennes.
Le trio mortel. Des recherches récentes dans l'industrie, y compris le "Agents Rule of Two" de Meta et des modèles similaires comme le "Lethal Trifecta" de Simon Willison, mettent en évidence les conditions dans lesquelles cela devient dangereux. Le profil de risque augmente lorsque trois conditions sont présentes simultanément :
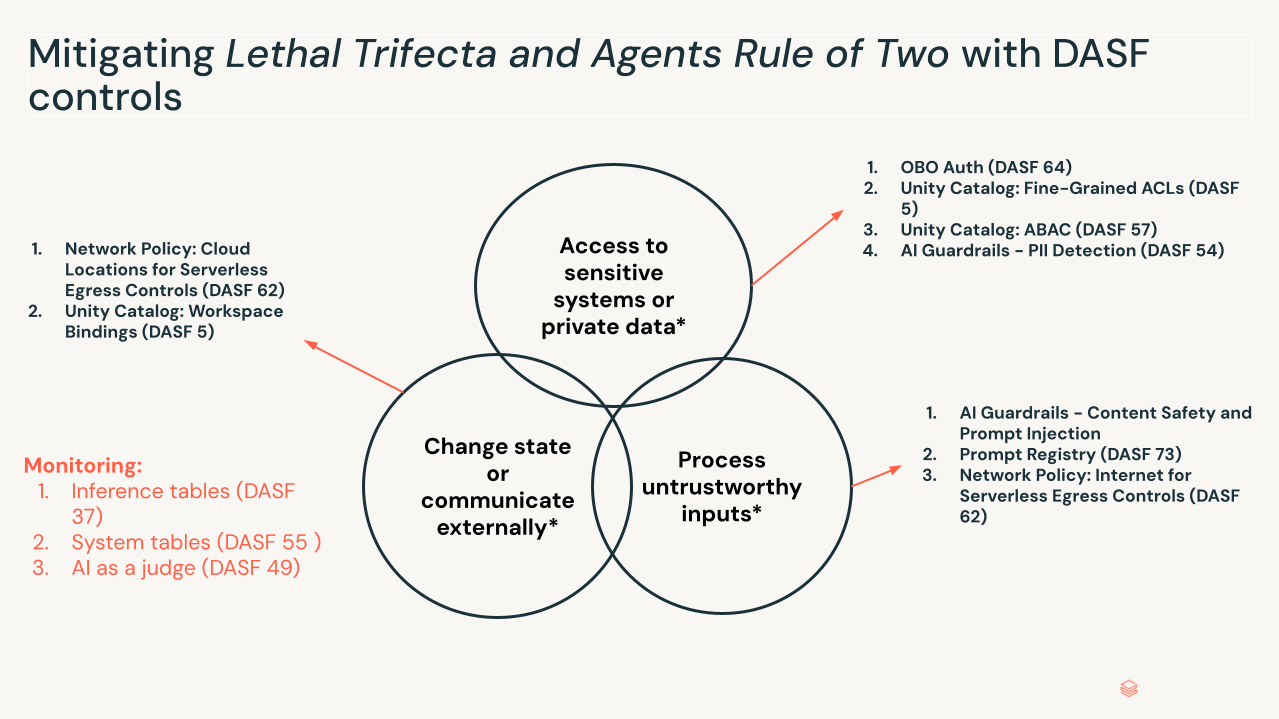
- Accès à des systèmes sensibles ou à des données privées : L'agent peut récupérer des données privées ou restreintes.
- Traitement d'entrées non fiables : L'agent traite des données provenant de l'extérieur de la frontière de confiance — invites utilisateur, sites web externes, e-mails entrants.
- Modification de l'état ou communication externe : L'agent peut modifier l'état via des outils ou des connexions MCP — envoi d'e-mails, exécution de SQL, modification de code.
Avec les trois en place, une injection d'invite indirecte intégrée dans des données non fiables peut détourner l'ensemble des capacités de l'agent, le transformant en un "délégué confus" qui effectue des actions autorisées avec une intention malveillante. Supprimez n'importe quel élément en réduisant les autorisations, en ajoutant un point de contrôle humain, en validant l'intention avant la sélection de l'outil et en brisant la chaîne d'attaque.
Comment l'extension est organisée
Les 35 nouveaux risques et 6 contrôles sont organisés autour de trois sous-composants qui correspondent au fonctionnement réel des agents :
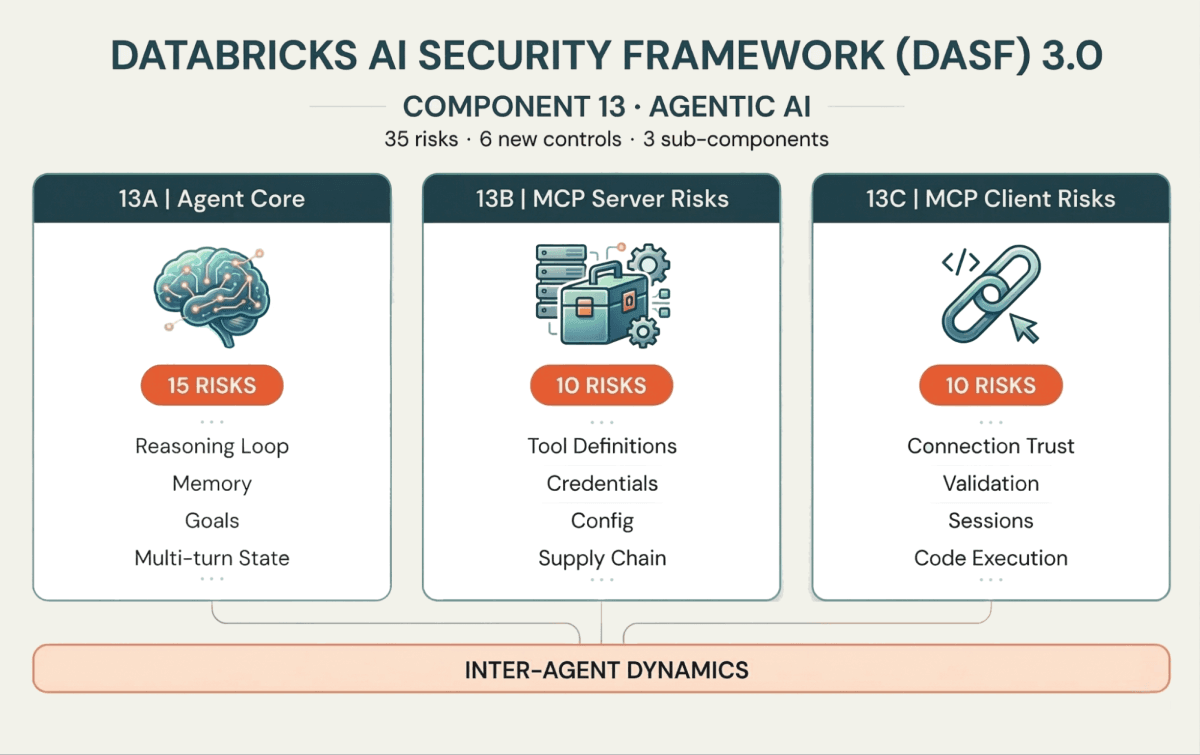
13A : Le Noyau de l'Agent (cerveau et mémoire)
Ces risques ciblent la boucle de raisonnement de l'agent. Le Pollution de la Mémoire (Risque 13.1) introduit un contexte faux qui altère les décisions actuelles ou futures. La Rupture d'Intention et Manipulation d'Objectif (Risque 13.6) contraint l'agent à s'écarter de son objectif. Et comme les agents fonctionnent dans des boucles multi-tours, les Attaques en Cascade d'Hallucination (Risque 13.5) peuvent aggraver une erreur mineure sur plusieurs itérations pour aboutir à une action destructive.
13B : Risques du Serveur MCP (l'interface de l'outil)
Les agents interagissent avec des systèmes externes via des outils, de plus en plus standardisés via le Model Context Protocol (MCP). Côté serveur, les attaquants peuvent déployer la Pollution d'Outil (Risque 13.18) — injectant un comportement malveillant dans les définitions d'outils — ou exploiter l'Injection d'Invite (Risque 13.16) dans les descriptions d'outils pour contourner les contrôles de sécurité.
13C : Risques du Client MCP (la couche de connexion)
Côté client, si l'agent se connecte à un Serveur Malveillant (Risque 13.26) ou ne parvient pas à valider les réponses du serveur, il risque une Exécution de Code Côté Client (Risque 13.32) ou une Fuite de Données (Risque 13.30). À mesure que l'adoption du MCP augmente, la sécurisation de la frontière client-serveur devient aussi importante que la sécurisation du raisonnement de l'agent.
Dynamiques inter-agents
Les agents communiqueront de plus en plus entre eux. Cela crée des risques de Pollution de la Communication entre Agents (Risque 13.12) et d'Agents Rebelles dans les Systèmes Multi-Agents (Risque 13.13) — des agents qui opèrent en dehors des limites de surveillance, un problème qui s'aggrave avec l'échelle.
Contrôles pour sécuriser les agents IA et les systèmes autonomes
Le DASF a toujours été axé sur la défense en profondeur. Mais lorsqu'un système IA peut agir, les contrôles d'accès en lecture seule ne suffisent pas. Les nouveaux contrôles abordent directement ce problème :
- Moindre privilège pour les outils (DASF 5, DASF 57, DASF 64) : Les agents ont besoin d'autorisations granulaires limitées à leur tâche immédiate, limitant le rayon d'impact de la même manière que RBAC et ABAC limitent ceux d'un humain. Ce n'est pas parce qu'un agent peut appeler l'outil de métriques RH qu'il devrait le faire lorsqu'il répond à une requête de vente.
- Supervision humaine (DASF 66) : Pour les actions à enjeux élevés, exiger une vérification humaine avant l'exécution de l'outil. La conception du contrôle tient compte de la fatigue d'approbation — si vous submergez le réviseur humain, vous avez créé une nouvelle vulnérabilité, pas résolu un problème.
- Sandboxing et isolation (DASF 34, DASF 62) : Le code généré par l'agent s'exécute dans des environnements éphémères et isolés. Si un agent décide d'écrire et d'exécuter un script, cette exécution ne devrait pas avoir accès au système plus large et aux connexions sortantes vers des destinations inconnues.
- Passerelle IA et garde-fous (DASF 54) : Les agents ont besoin de protections contre les scénarios où un agent est manipulé pour divulguer des données qu'il ne devrait pas. Les interactions des agents via une passerelle et des garde-fous tels que la surveillance, le filtrage de sécurité et la détection PII doivent être appliquées. Ces garde-fous peuvent être appliqués à l'entrée ou à la sortie d'un agent (ou aux deux). Il est également tout aussi important de surveiller ce qui est réellement renvoyé par l'agent.
- Observabilité de la pensée (DASF 65) : La journalisation standard indique ce qui s'est passé. Le traçage agentique capture le pourquoi — les étapes de planification, le raisonnement de sélection d'outils, la chaîne de pensée qui a conduit à une action. Sans cela, vous ne pouvez pas auditer les décisions d'un agent ni détecter quand son raisonnement a été compromis.
Pour les clients Databricks, le compendium met en correspondance ces contrôles avec les capacités de la plateforme, notamment la gouvernance Unity Catalog pour l'accès aux données des agents, le Agent Bricks Framework, les garde-fous AI Gateway, et les paramètres de sécurité de AI Search.
Construit avec la communauté
Cette extension reflète les commentaires des réviseurs et des contributeurs de Databricks et de la communauté de la sécurité, y compris les équipes d'Atlassian, Experian et ComplyLeft. Nous nous sommes également largement appuyés sur les travaux de MITRE ATLAS, OWASP, NIST et de la Cloud Security Alliance — le compendium mis à jour met en correspondance les 97 risques et 73 contrôles avec ces normes industrielles.
Commencez
Téléchargez le livre blanc DASF Agentic AI Extension pour un traitement complet des 35 nouveaux risques d'IA agentique et des 6 nouveaux contrôles, et récupérez le compendium mis à jour (Google Sheet, Excel) qui met désormais en correspondance les risques et contrôles agentiques aux côtés du DASF original. Utilisez ces ressources pour :
- Évaluer vos architectures d'agents actuelles par rapport au modèle de risque d'IA agentique.
- Mettre en correspondance vos écosystèmes d'outils — y compris les serveurs et clients MCP — avec les vecteurs de menaces identifiés.
- Implémenter les contrôles recommandés pour garantir que vos agents fonctionnent dans des limites sûres et gouvernées.
Pour un contexte plus approfondi, lisez le livre blanc DASF complet et explorez la documentation du Agent Bricks Framework pour voir comment ces contrôles fonctionnent sur la plateforme.
Contactez votre équipe de compte Databricks ou envoyez-nous un e-mail à dasf@databricks.com pour nous faire part de vos commentaires — ce framework appartient autant à la communauté qu'à nous.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.