Annonce du clustering liquide automatique
Mise en page des données optimisée pour des requêtes jusqu'à 10 fois plus rapides
par Cindy Jiang, Supun Nakandala, Naga Raju Bhanoori, Eric Liang et Parimarjan Negi
- Le regroupement liquide automatique, optimisé par Predictive Optimization, sélectionne automatiquement les clés de regroupement pour améliorer continuellement les performances des requêtes et réduire les coûts.
- Des processus de sélection robustes et une surveillance continue maintiennent l'optimisation des tables.
- Le coût total de possession (TCO) est minimisé en évaluant automatiquement si les gains de performance l'emportent sur les coûts.
Nous sommes ravis d'annoncer la préversion publique du clustering liquide automatique, alimenté par Predictive Optimization. Cette fonctionnalité applique et met à jour automatiquement les colonnes de clustering liquide sur les tables gérées par Unity Catalog, améliorant les performances des requêtes et réduisant les coûts.
Le clustering liquide automatique simplifie la gestion des données en éliminant le besoin de réglages manuels. Auparavant, les équipes de données devaient concevoir manuellement la disposition des données spécifique pour chacune de leurs tables. Désormais, Predictive Optimization exploite la puissance d'Unity Catalog pour surveiller et analyser vos données et vos modèles de requêtes.
Pour activer le clustering liquide automatique, configurez vos tables UC gérées non partitionnées ou liquides en définissant le paramètre CLUSTER BY AUTO.
Une fois activé, Predictive Optimization analyse la manière dont vos tables sont interrogées et sélectionne intelligemment les clés de clustering les plus efficaces en fonction de votre charge de travail. Il regroupe ensuite la table automatiquement, garantissant que les données sont organisées pour des performances de requête optimales. Tout moteur lisant à partir de la table Delta bénéficie de ces améliorations, ce qui entraîne des requêtes considérablement plus rapides. De plus, à mesure que les modèles de requêtes changent, Predictive Optimization ajuste dynamiquement le schéma de clustering, éliminant complètement le besoin de réglages manuels ou de décisions de disposition des données lors de la configuration de vos tables Delta.
Au cours de la préversion privée, des dizaines de clients ont testé le clustering liquide automatique et ont obtenu d'excellents résultats. Beaucoup ont apprécié sa simplicité et ses gains de performance, certains l'utilisant déjà pour leurs tables gold et prévoyant de l'étendre à toutes leurs tables Delta.
Les clients en préversion comme Healthrise ont signalé une amélioration significative des performances des requêtes avec le clustering liquide automatique :
« Nous avons déployé le clustering liquide automatique sur toutes nos tables gold. Depuis, nos requêtes sont jusqu'à 10 fois plus rapides. Toutes nos charges de travail sont devenues beaucoup plus efficaces sans aucun travail manuel nécessaire pour concevoir la disposition des données ou exécuter la maintenance. » —Li Zou, Principal Data Engineer, Brian Allee, Director, Data Services | Technology & Analytics, Healthrise
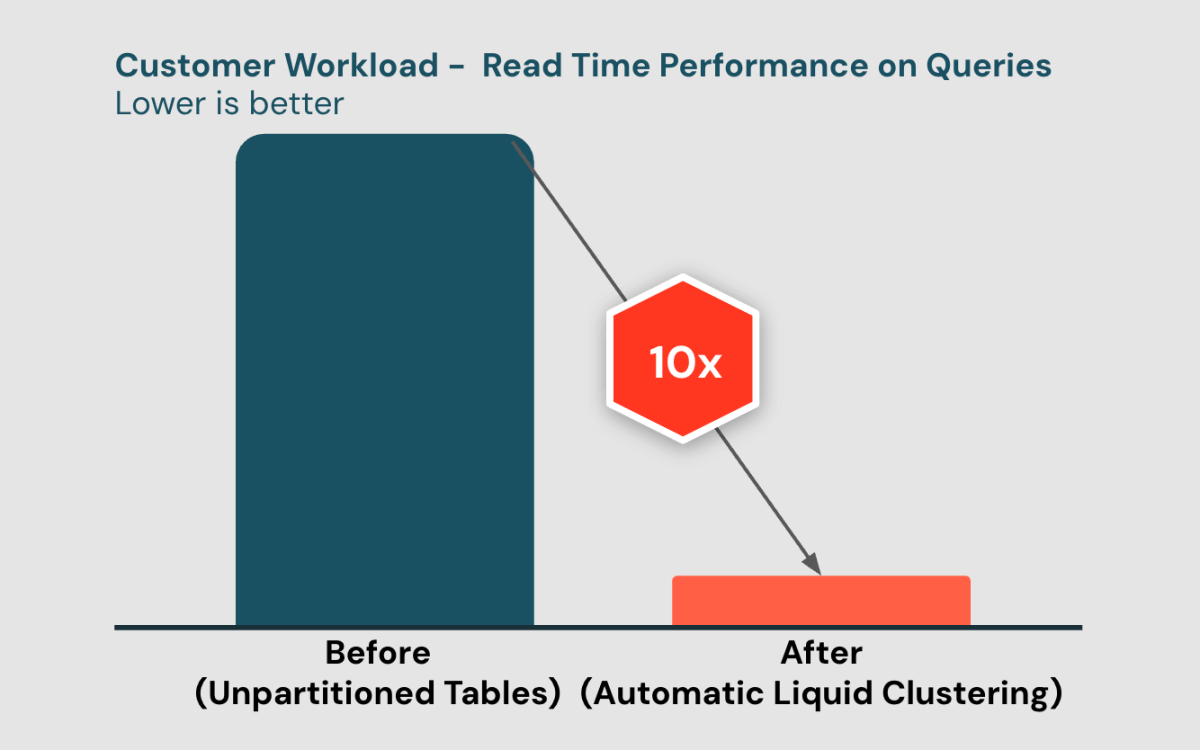
Choisir la meilleure disposition des données est un problème complexe
Appliquer la meilleure disposition des données à vos tables améliore considérablement les performances des requêtes et l'efficacité des coûts. Traditionnellement, avec le partitionnement, les clients ont eu du mal à concevoir la bonne stratégie de partitionnement pour éviter les déséquilibres de données et les conflits de concurrence. Pour améliorer davantage les performances, les clients peuvent utiliser ZORDER en plus du partitionnement, mais ZORDER est coûteux et encore plus compliqué à gérer.
Liquid Clustering simplifie considérablement les décisions relatives à la disposition des données et offre la flexibilité de redéfinir les clés de clustering sans réécriture de données. Les clients doivent seulement choisir les clés de clustering en se basant purement sur les modèles d'accès aux requêtes, sans avoir à se soucier de la cardinalité, de l'ordre des clés, de la taille des fichiers, des déséquilibres de données potentiels, de la concurrence et des futurs changements de modèles d'accès. Nous avons travaillé avec des milliers de clients qui ont bénéficié de meilleures performances de requêtes avec Liquid Clustering, et nous avons maintenant plus de 3000 clients actifs mensuels écrivant plus de 200 Po de données vers des tables clusterisées liquides par mois.
Cependant, même avec les avancées de Liquid Clustering, vous devez toujours choisir les colonnes à regrouper en fonction de la manière dont vous interrogez votre table. Les équipes de données doivent déterminer :
- Quelles tables bénéficieront du clustering liquide ?
- Quelles sont les meilleures colonnes de clustering pour cette table ?
- Et si mes modèles de requêtes changent à mesure que les besoins de l'entreprise évoluent ?
De plus, au sein d'une organisation, les ingénieurs de données doivent souvent travailler avec plusieurs consommateurs en aval pour comprendre comment les tables sont interrogées, tout en suivant l'évolution des modèles d'accès et des schémas. Ce défi devient exponentiellement plus complexe à mesure que votre volume de données augmente avec davantage de besoins analytiques.
Comment le clustering liquide automatique fait évoluer votre disposition de données
Avec le clustering liquide automatique, Databricks s'occupe de toutes les décisions relatives à la disposition des données pour vous – de la création de la table, au regroupement de vos données et à l'évolution de votre disposition des données – vous permettant de vous concentrer sur l'extraction d'informations de vos données.
Voyons le clustering liquide automatique en action avec une table d'exemple.
Considérez une table example_tbl, qui est fréquemment interrogée par date et ID client. Elle contient des données des 5 et 6 février et des ID clients A à F. Sans aucune configuration de disposition des données, les données sont stockées dans l'ordre d'insertion, ce qui donne la disposition suivante :
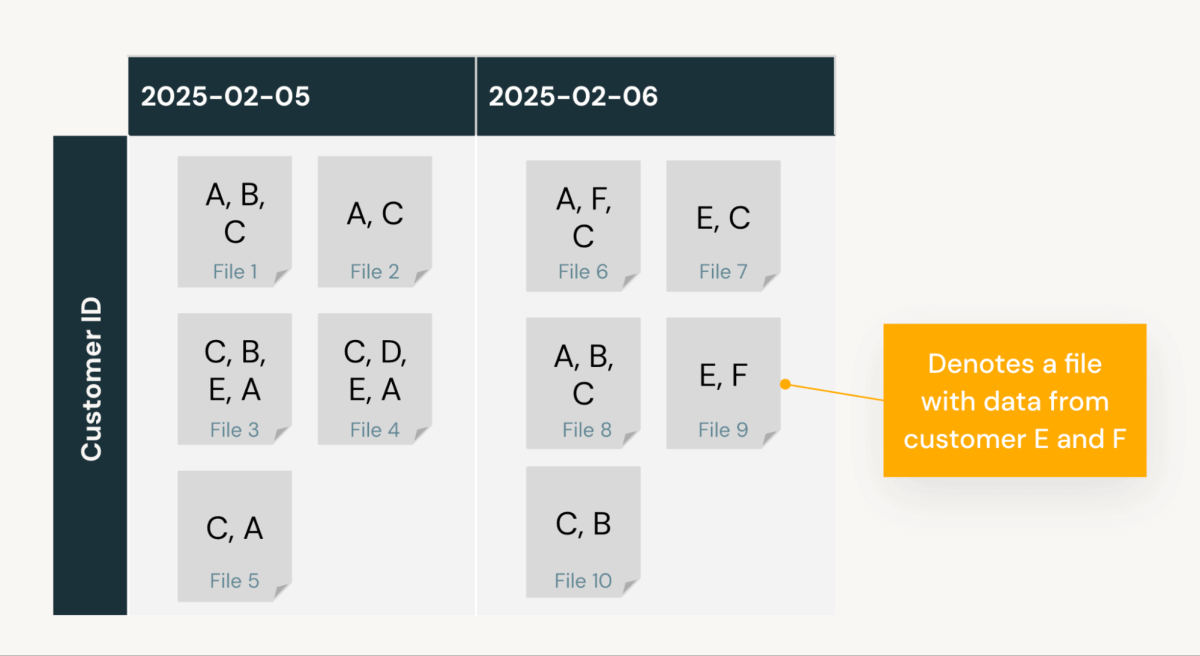
Supposons que le client exécute SELECT * FROM example_tbl WHERE date = '2025-02-05' AND customer_id = 'B'. Le moteur de requête exploite les statistiques de saut de données Delta (valeurs min/max, comptes nuls et enregistrements totaux par fichier) pour identifier les fichiers pertinents à analyser. L'élagage des lectures de fichiers inutiles est crucial, car il réduit le nombre de fichiers analysés pendant l'exécution de la requête, améliorant directement les performances des requêtes et réduisant les coûts de calcul. Moins une requête doit lire de fichiers, plus elle est rapide et efficace.
Dans ce cas, le moteur identifie 5 fichiers pour le 5 février, car la moitié des fichiers ont une valeur min/max pour la colonne date correspondant à cette date. Cependant, comme les statistiques de saut de données ne fournissent que des valeurs min/max, ces 5 fichiers ont tous un customer_id min/max qui suggère que le client B se trouve quelque part au milieu. Par conséquent, la requête doit analyser les 5 fichiers pour extraire les entrées du client B, ce qui entraîne un taux d'élagage de fichiers de 50 % (lecture de 5 fichiers sur 10).

Comme vous le voyez, le problème principal est que les données du client B ne sont pas colocalisées dans un seul fichier. Cela signifie que l'extraction de toutes les entrées pour le client B nécessite également la lecture d'une quantité importante d'entrées pour d'autres clients.
Existe-t-il un moyen d'améliorer l'élagage des fichiers et les performances des requêtes ici ? Le clustering liquide automatique peut améliorer les deux. Voici comment :
Derrière les coulisses du clustering liquide automatique : comment ça marche
Une fois activé, le clustering liquide automatique effectue en continu les trois étapes suivantes :
- Collecte de télémétrie pour déterminer si la table bénéficiera de l'introduction ou de l'évolution des clés de clustering liquide.
- Modélisation de la charge de travail pour comprendre et identifier les colonnes éligibles.
- Application de la sélection des colonnes et évolution des schémas de clustering basée sur une analyse coût-bénéfice.

Étape 1 : Analyse de la télémétrie
Predictive Optimization collecte et analyse les statistiques de scan des requêtes, telles que les prédicats de requête et les filtres JOIN, pour déterminer si une table bénéficierait du clustering liquide.
Avec notre exemple, Predictive Optimization détecte que les colonnes 'date' et 'customer_id' sont fréquemment interrogées.
Étape 2 : Modélisation de la charge de travail
Predictive Optimization évalue la charge de travail des requêtes et identifie les meilleures clés de clustering pour maximiser le saut de données.
Il apprend des modèles de requêtes passés et estime les gains de performance potentiels de différents schémas de clustering. En simulant des requêtes passées, il prédit l'efficacité avec laquelle chaque option réduirait la quantité de données analysées.
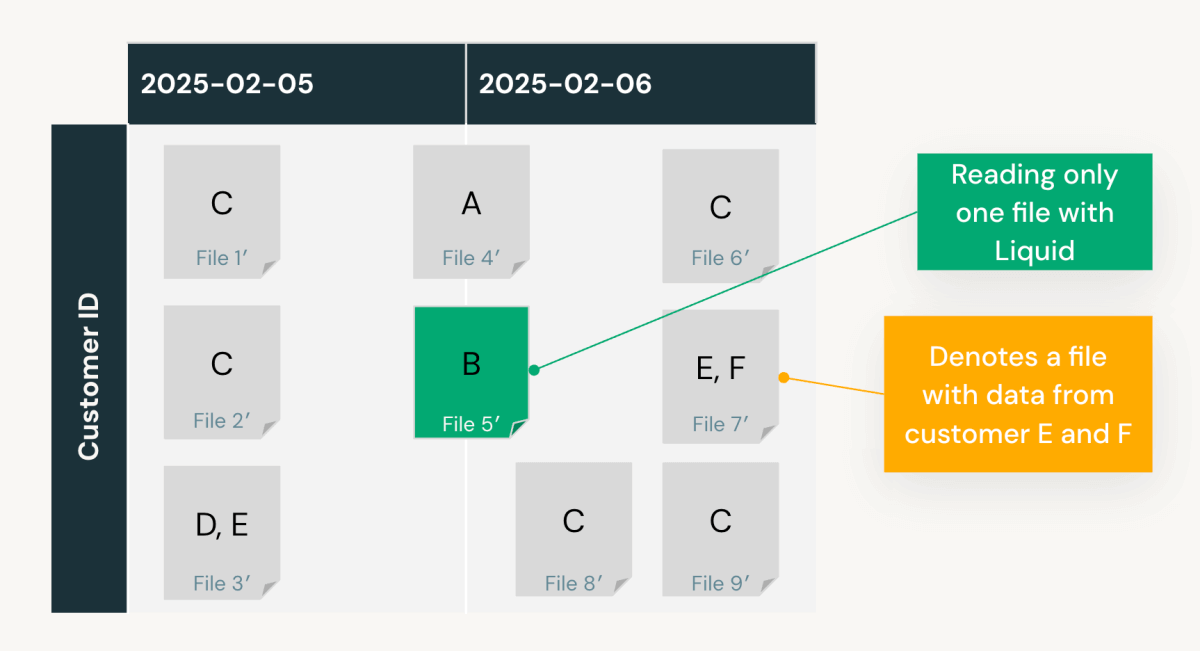
Dans notre exemple, en utilisant des analyses enregistrées sur ‘date’ et ‘customer_id’ et en supposant des requêtes cohérentes, Predictive Optimization calcule que :
- Le clustering par
‘date’lit 5 fichiers avec un taux d'élagage de 50 %. - Le clustering par
‘customer_id’lit environ 2 fichiers (estimation) avec un taux d'élagage de 80 %.- Le clustering par
‘date’et‘customer_id’(voir la disposition des données ci-dessous) ne lit qu'un seul fichier avec un taux d'élagage de 90 %.
- Le clustering par

Étape 3 : Optimisation coût-bénéfice
La plateforme Databricks garantit que toute modification des clés de clustering apporte un avantage de performance clair, car le clustering peut introduire une surcharge supplémentaire. Une fois que de nouveaux candidats clés de clustering sont identifiés, Predictive Optimization évalue si les gains de performance l'emportent sur les coûts. Si les avantages sont significatifs, il met à jour les clés de clustering sur les tables gérées par Unity Catalog.
Dans notre exemple, le clustering par ‘date’ et ‘customer_id’ entraîne un taux d'élagage des données de 90 %. Comme ces colonnes sont fréquemment interrogées, la réduction des coûts de calcul et l'amélioration des performances des requêtes justifient la surcharge du clustering.
Les clients en avant-première ont souligné la rentabilité de Predictive Optimization, en particulier sa faible surcharge par rapport à la conception manuelle des dispositions de données. Des entreprises comme CFC Underwriting ont signalé un coût total de possession réduit et des gains d'efficacité significatifs.
« Nous apprécions vraiment le clustering liquide automatique de Databricks car il nous assure d'avoir la disposition des données la plus optimisée dès le départ. Il nous a également fait gagner beaucoup de temps en éliminant le besoin d'un ingénieur pour maintenir la disposition des données. Grâce à cette fonctionnalité, nous avons constaté que nos coûts de calcul ont diminué même si nous avons augmenté notre volume de données. » —Nikos Balanis, Head of Data Platform, CFC
La fonctionnalité en résumé : Predictive Optimization choisit les clés de clustering liquide en votre nom, de sorte que les économies de coûts prévues grâce à l'élagage des données l'emportent sur le coût prévu du clustering.
Commencez dès aujourd'hui
Si vous n'avez pas encore activé Predictive Optimization, vous pouvez le faire en sélectionnant Activé à côté de Predictive Optimization dans la console de compte sous Paramètres > Activation des fonctionnalités.

Nouveau sur Databricks ? Depuis le 11 novembre 2024, Databricks a activé Predictive Optimization par défaut sur tous les nouveaux comptes Databricks, en exécutant des optimisations pour toutes vos tables gérées par Unity Catalog.
Commencez dès aujourd'hui en définissant CLUSTER BY AUTO sur vos tables gérées par Unity Catalog. Databricks Runtime 15.4+ est requis pour CRÉER de nouvelles tables AUTO ou ALTER des tables Liquid / non partitionnées existantes. Dans un avenir proche, le clustering liquide automatique sera activé par défaut pour les nouvelles tables gérées par Unity Catalog. Restez à l'écoute pour plus de détails.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.