Présentation de l'écosystème de stockage Databricks : gouverner le patrimoine de données de l'entreprise, où qu'il se trouve
Propulsé par le protocole open source OpenSharing, notre nouvel écosystème de partenaires de stockage apporte la Databricks Data Intelligence Platform directement sur votre infrastructure hybride et sur site, sans copier un seul octet.
par Rupal Jain et Denis Dubeau
- Le défi : les entreprises doivent conserver d'immenses volumes de données sur site, dans des clouds privés et dans des environnements en périphérie pour répondre à des exigences strictes de souveraineté des données et de conformité réglementaire, maintenir une faible latence en périphérie ou gérer une immense gravité des données, tout en apportant une AI et une gouvernance cloud modernes à ces environnements.
- De quoi s'agit-il : l'écosystème de stockage Databricks connecte nativement les plateformes de stockage hybrides et sur site à Databricks à l'aide du protocole OpenSharing. Cela permet aux entreprises d'établir une gouvernance centralisée des données et de déployer GenAI à l'échelle de l'ensemble de leur infrastructure hybride.
- Le résultat : grâce à une architecture sans copie, les entreprises peuvent exécuter Databricks Serverless Compute, Genie et des LLMs directement sur leurs ensembles de données sur site, sans copier un seul fichier. Cela transforme instantanément des données isolées en actifs actifs et prêts pour l'AI pour des cas d'usage avancés, tels que l'entraînement de modèles sur des données d'ingénierie confidentielles ou l'analyse de la télémétrie réseau sur place.
Les données qui ne peuvent pas être déplacées
Pendant des années, la stratégie de données des entreprises était simple : tout déplacer vers le cloud. Migrer les lacs de données et les entrepôts de données vers le cloud, et la gouvernance suivrait. C'était une belle histoire — jusqu'à ce que ce ne soit plus le cas.
Aujourd'hui, certaines des entreprises les plus sophistiquées au monde nous le disent clairement : elles ne peuvent pas — et ne veulent pas — déplacer toutes leurs données vers le cloud. Des fabricants de semi-conducteurs de premier plan entraînent des modèles sur des ensembles de données classifiés d'ingénierie qui ne doivent jamais quitter leurs locaux. Des sociétés de trading mondiales disposent de volumes massifs de données historiques de tick pour lesquelles l'aspect économique des frais de sortie du cloud rend la migration impossible. Les banques de premier rang ont adopté des stratégies « Hybrid Forever », modernisant le stockage sur site tout en maintenant une souveraineté stricte des données. De grandes entreprises pharmaceutiques réalisent quotidiennement des millions d'expériences sur des médicaments à partir de patrimoines de données sur site à l'échelle du pétaoctet, soumis à des contrôles réglementaires stricts.
Il ne s'agit pas de cas marginaux. Ils représentent un changement structurel dans la façon dont les entreprises conçoivent les données : de « Tout migrer » à « Tout gouverner ».
Les facteurs de ce changement sont réels et cumulatifs :
- Souveraineté des données et réglementation : Les services financiers, le secteur de la santé et les organismes gouvernementaux opèrent sous des mandats — GDPR, HIPAA, NIS2, règles de résidence des données spécifiques au secteur — qui exigent que les données restent dans des juridictions spécifiques ou des environnements isolés (air-gapped). La migration vers le cloud n'est pas facultative ; elle est légalement interdite pour certains ensembles de données.
- Gravité des données et coûts : À l'échelle du pétaoctet et de l'exaoctet, l'économie de la migration vers le cloud s'effondre complètement. Les frais de sortie, les coûts de stockage et le volume impressionnant de données rendent le modèle « déplacer une seule fois » financièrement non viable. Certains des plus grands détaillants au monde rapatrient activement leurs charges de travail analytiques du cloud vers une infrastructure sur site précisément pour cette raison.
- Latence et charges de travail en périphérie (edge) : Les charges de travail du commerce de détail, de la fabrication et des télécommunications nécessitent un accès à faible latence aux données sur site et en périphérie. Les fournisseurs de télécommunications ingèrent quotidiennement d'énormes volumes de télémétrie réseau sur site pour alimenter des opérations réseau basées sur l'AI qui ne peuvent tolérer les temps de trajet aller-retour vers le cloud.
- L'AI sur les données sombres (dark data) : De vastes stocks de données de sauvegarde, d'archives non structurées et d'ensembles de données secondaires — représentant des centaines d'exaoctets à l'échelle de l'entreprise — contiennent une valeur immense pour l'AI qui n'a jamais été exploitée car la gouvernance ne les atteignait pas.
Le signal est indéniable. Nous avons reçu des demandes de centaines de clients réclamant explicitement une connectivité de stockage sur site et hybride vers Unity Catalog. Le marché du stockage défini par logiciel (SDS) représente des centaines de milliards de dollars en 2026, et les partenaires d'entreprise qui gèrent ce patrimoine — détenant collectivement plus de 2 zettaoctets de données sous gestion — construisent avec nous.
Présentation de l'écosystème de stockage Databricks
Aujourd'hui, nous sommes ravis d'annoncer l'écosystème de stockage défini par logiciel (SDS) de Databricks — une nouvelle catégorie de partenaires conçue sur mesure pour apporter la plateforme Databricks Intelligence Platform aux données d'entreprise, où qu'elles se trouvent : sur site, dans des clouds privés et dans des environnements en périphérie. Si vous êtes une entreprise qui gère aujourd'hui des pétaoctets de données sur ces plateformes, vous n'avez plus à choisir entre votre infrastructure de stockage hors cloud existante et Databricks AI.
Pendant trop longtemps, les entreprises ont dû choisir entre l'infrastructure de stockage sur site sur laquelle elles s'appuient et l'AI cloud-native qu'elles souhaitent créer. Forcer les clients à migrer d'immenses quantités de données à l'aide de pipelines complexes simplement pour débloquer cette intelligence est un modèle dépassé. En unissant ces partenaires de premier plan, nous mettons fin à ce compromis et apportons Databricks Intelligence directement là où se trouvent les données de l'entreprise. Mais ce lancement n'est que le premier jour. Nous posons les bases pour garantir que bientôt, chaque donnée hybride, structurée ou non structurée, soit instantanément prête pour l'AI générative sans jamais avoir à copier un seul octet. —Stephen Orban, SVP, Partenariats produits et écosystème, Databricks
Au cœur de cet écosystème se trouve OpenSharing, un protocole open source pour un partage de données sécurisé et gouverné. Nos partenaires de stockage implémentent des serveurs OpenSharing pour exposer directement leurs patrimoines de données à Databricks Serverless Compute. Le parcours est simple : le partenaire de stockage configure un point de terminaison OpenSharing, vous le connectez à Unity Catalog, et vous obtenez instantanément un accès sécurisé et gouverné à vos données sur site dans Databricks, sans migration de données.
Cette intégration fournit un catalogue unique et unifié pour l'ensemble de votre environnement hybride. Les clients peuvent désormais utiliser Databricks Serverless Compute, Genie, AgentBricks et l'entraînement de modèles pour interroger et analyser des données qui ne quittent jamais les locaux. Le résultat ? Aucun mouvement de données, aucune duplication de données et aucun risque de non-conformité.
Il ne s'agit pas d'une simple aspiration de feuille de route. Les clients peuvent essayer ces intégrations dès aujourd'hui. Les partenaires qui développent ces intégrations suivent le Partner Well-Architected Framework — un modèle technique couvrant l'architecture, la sécurité et les critères de certification.
Les clients souhaitent décloisonner les silos de données et unifier l'ensemble de leur patrimoine de données et d'AI, y compris de grandes quantités de données qui se trouvent toujours sur site. Grâce aux partenaires de stockage sur site qui exploitent le protocole open source Open Sharing, les clients peuvent désormais unifier, gouverner et analyser de manière transparente l'ensemble de leur patrimoine de données dans Databricks Unity Catalog, libérant ainsi toute la valeur de leurs données dans la plateforme Databricks Data Intelligence Platform. —Jonathan Keller, VP, Gestion des produits, Databricks
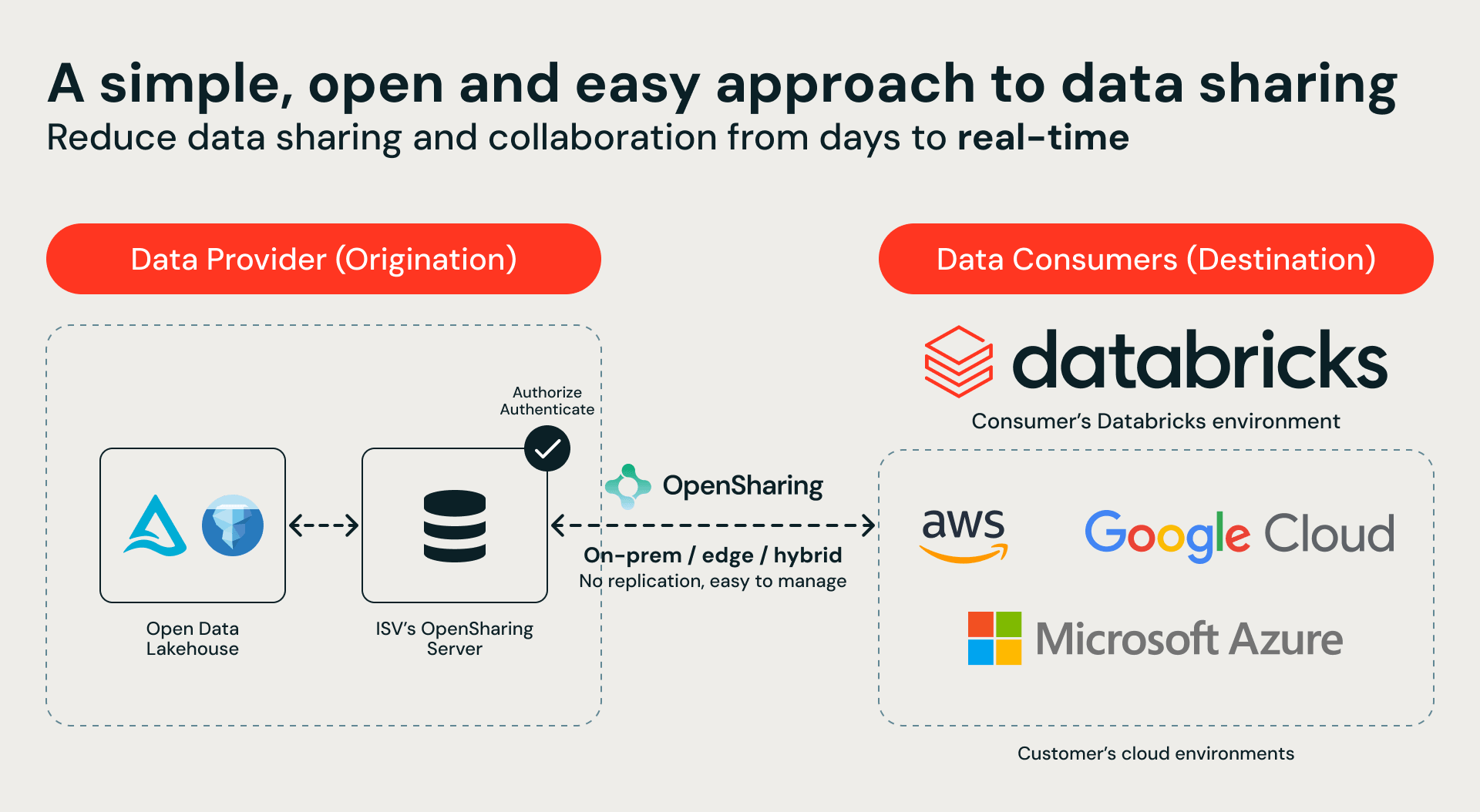
Nos partenaires de lancement
Nous sommes fiers d'annoncer des intégrations avec les principaux fournisseurs de stockage suivants :

MinIO — Disponibilité générale (démo, blog)
MinIO AIStor est la passerelle qui connecte de manière transparente la plateforme Databricks Data Intelligence Platform aux données d'entreprise qui ne peuvent pas être déplacées vers le cloud. En implémentant nativement le protocole ouvert Open Sharing au niveau de la couche de stockage, AIStor élimine la complexité et permet aux clients Databricks d'interroger efficacement les tables Apache Iceberg™️ et Delta locales en direct, sous la gouvernance complète de Unity Catalog. Il étend Serverless Compute, Genie et Agent Bricks aux données sur site, apportant toute la puissance de la plateforme Databricks aux données les plus critiques d'une entreprise.
Les initiatives d'AI et d'analytique sont souvent limitées par l'emplacement des données, en particulier dans les environnements ayant des exigences strictes en matière de sécurité, de souveraineté ou d'exploitation. En apportant OpenSharing de manière native à AIStor, nous permettons aux organisations d'exposer leurs données en toute sécurité là où elles se trouvent, tout en offrant à Databricks un accès transparent via des standards ouverts. Cela lève un obstacle majeur entre les données d'entreprise et l'AI, permettant aux organisations d'activer des données auparavant inaccessibles pour l'AI, l'analytique et les applications agentiques sans compromettre le contrôle. —Ugur Tigli, Directeur de la technologie, MinIO
Everpure (anciennement Pure Storage) — Aperçu privé (démo, blog)
Everpure et Databricks permettent aux organisations d'utiliser des données sur site directement dans le cloud, éliminant ainsi le besoin de réplication ou de duplication des données. Cela est possible grâce à un connecteur OpenSharing qui relie les données du stockage d'objets aux espaces de travail principaux de Databricks de manière sécurisée et contrôlée.
Everpure et Databricks permettent aux organisations d'accéder à leurs données sur site et de les analyser directement depuis le cloud, sans avoir besoin de réplication ou de duplication. Déplacer continuellement des données entre différents environnements est coûteux et non viable à grande échelle. Les clients recherchent une approche plus simple qui équilibre les coûts, la conformité et la souveraineté des données tout en réduisant la complexité opérationnelle. —Chadd Kenney, VP, Gestion des produits, Everpure
Qumulo — Aperçu privé en juillet 2026 (blog)
Qumulo a intégré OpenSharing à son nouveau NeuralSearch, permettant aux clients de partager en toute sécurité les données stockées sur Qumulo avec Databricks dans des environnements core, cloud et edge, sans réplication, coûts supplémentaires ou complexité. Grâce à NeuralSearch, les utilisateurs peuvent découvrir des ensembles de données pertinents, y compris du contenu non structuré, via des requêtes en langage naturel, et partager de manière transparente ces tables préparées avec Databricks via OpenSharing.
Les entreprises ne peuvent plus se permettre le coût, la complexité et les délais liés à la copie de volumes massifs de données entre différents environnements, simplement pour prendre en charge l'AI et l'analyse. En combinant Qumulo NeuralSearch avec Databricks OpenSharing, les clients peuvent découvrir, gouverner et partager en toute sécurité des données tabulaires et non structurées dans des centres de données centraux, des sites edge et des clouds publics – en temps réel, sans déplacer les données elles-mêmes. Ensemble, nous aidons les entreprises à accélérer leurs initiatives AI, à unifier la gouvernance et à obtenir plus rapidement des insights à partir de données distribuées à l'échelle mondiale, tout en maintenant une source unique de vérité. —Brandon Whitelaw, SVP et responsable produit chez Qumulo
VAST Data — Aperçu privé en août 2026
VAST Data étend le système d'exploitation VAST AI avec la prise en charge d'OpenSharing pour aider les entreprises à connecter les workflows Databricks aux données résidant sur des infrastructures sur site et hybrides – sans nécessiter de migration ou de mouvement massif de données. Cette intégration offrira aux clients plus de flexibilité pour accéder aux données, les traiter et les opérationnaliser dans le cloud, les centres de données et les environnements d'infrastructure AI émergents, tout en prenant en charge les charges de travail modernes d'AI hybride et d'analyse.
L'infrastructure AI devient fondamentalement hybride. Les clients souhaitent de plus en plus pouvoir traiter les données là où cela est le plus logique sur les plans économique et opérationnel, tout en conservant un accès fluide entre les environnements. La prise en charge d'OpenSharing étend la capacité du système d'exploitation VAST AI à connecter les workflows Databricks aux données résidant sur des infrastructures cloud et sur site pour les applications modernes d'AI et d'analyse. Contrairement aux plateformes de stockage traditionnelles, VAST combine les services de données, le traitement distribué et l'orchestration de l'infrastructure AI dans un système d'exploitation unifié pour les données AI à grande échelle. —John Mao, vice-président, Alliances technologiques mondiales chez VAST Data
Et ensuite
Intégrations bientôt disponibles
En plus de nos partenaires de lancement, la dynamique au sein de l'écosystème du stockage continue de s'accélérer. Nous avons obtenu des engagements de Cohesity, Commvault, HPE, NetApp, Nutanix et Rubrik pour créer des intégrations natives d'ici la fin de l'année.
Collectivement, ces partenaires, ainsi que nos partenaires de lancement, gèrent des centaines d'exaoctets de données d'entreprise, englobant des médias non structurés haute performance, des archives de sauvegarde secondaires, du stockage cloud économique et des parcs de clouds privés hyperconvergés.
Libérer le potentiel des données non structurées
Le lancement d'aujourd'hui permet de gouverner pleinement les données structurées et tabulaires et de les rendre accessibles dans tout cet écosystème. Mais nous savons que de formidables opportunités résident dans les données non structurées : les images, les PDF, les vidéos, les scanners médicaux, les simulations d'ingénierie et les archives de sauvegarde qui représentent la majorité des données d'entreprise gérées — et la matière première de la prochaine génération de pipelines RAG et de modèles affinés.
Nous travaillons activement à l'extension du protocole OpenSharing avec des API Volumes, afin d'exposer les fichiers non structurés du stockage sur site directement à Databricks pour les charges de travail GenAI. Grâce à cela, les partenaires qui gèrent d'immenses parcs de données non structurées — des archives de médias et d'imagerie aux référentiels de sauvegarde d'entreprise — ouvriront la voie à une toute nouvelle catégorie de cas d'usage de l'AI pour leurs clients.
Voilà ce que signifie tout gouverner.
Rejoindre l'écosystème
Si vous êtes un fournisseur de stockage intéressé par le développement d'une intégration OpenSharing, consultez le Partner Well Architected Framework ou contactez l'équipe partenaire de Databricks pour commencer.
Si vous êtes une entreprise cliente et souhaitez connecter votre parc de stockage sur site à Databricks, contactez votre équipe de compte pour en savoir plus.
L'ère du "Tout migrer" est révolue. L'ère du "Tout gouverner" commence aujourd'hui.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.