Le mode temps réel d'Apache Spark pour le jeu vidéo : une meilleure approche pour la sessionisation en temps réel
Créez des pipelines de streaming avec état qui suivent des millions de sessions d'appareils de jeu actives, produisant des heartbeats en temps réel avec une latence inférieure à la seconde dans Apache Spark
par Neha Prabhu et Murali Talluri
- Découvrez comment le Real-Time Mode d'Apache Spark™ permet la sessionisation de jeux en temps réel pour des millions de sessions d'appareils actives
- Apprenez comment les minuteurs de transformWithState alimentent des heartbeats proactifs déclenchés par minuteur, générant des résultats de manière planifiée, indépendamment des données entrantes
- Découvrez comment le Real-Time Mode associé à transformWithState remplace les applications internes personnalisées et les moteurs de streaming externes, offrant une précision inférieure à la seconde pour le traitement des entrées et les sorties déclenchées par minuteur.
Dans le secteur des jeux vidéo, chaque milliseconde compte. Pour piloter la personnalisation en jeu, alimenter les moteurs de recommandation et prendre des décisions de planification dynamique du contenu, les plateformes doivent traiter les données de session de millions de joueurs dans le monde avec une latence inférieure à la seconde.
Aujourd'hui, répondre à ces exigences de latence ultra-faible ne nécessite plus une architecture décousue avec plusieurs moteurs. Dans ce blog, nous explorons une implémentation concrète d' Apache Spark Real-Time Mode. En exploitant le nouvel opérateur transformWithState pour une logique avec état complexe, nous démontrons comment Spark offre des performances de l'ordre de la milliseconde de bout en bout. Découvrez comment votre équipe peut accélérer le développement et concevoir des applications opérationnelles critiques en utilisant l'écosystème familier de Structured Streaming.
Présentation du cas d'usage
Du début à la fin de la partie : pourquoi le suivi des sessions est crucial
Pour les plateformes de jeux, savoir quels appareils sont actifs et pendant combien de temps n'est pas seulement une préoccupation d'infrastructure : cela stimule l'activité commerciale. Les données de session en temps réel alimentent des expériences personnalisées en jeu, soutiennent les moteurs de recommandation, éclairent les décisions de planification du contenu et fournissent des signaux sur l'état des appareils pour des millions de consoles et de PC. Les équipes opérationnelles les utilisent pour appliquer le contrôle parental et détecter des modèles de session anormaux.
Principes fondamentaux des événements de session
Les événements de session provenant des consoles et des PC sont acheminés vers des topics Kafka. Chaque événement comporte un ID d'appareil et un ID de session. L'ID d'appareil identifie la console ou le PC ; l'ID de session identifie la session de jeu. Une seule session peut être active par appareil à la fois.
Le pipeline gère quatre scénarios :
- Début de session (GameStart) : un événement de début arrive. Le pipeline stocke l'ID de session et l'heure de début, émet un événement SessionActive et enregistre un minuteur de temps de traitement de 30 secondes. Si une autre session était déjà active pour cet appareil, il met d'abord fin à l'ancienne.
- Heartbeat de session (Active) : le minuteur se déclenche toutes les 30 secondes. Le pipeline calcule now - start_time, émet un heartbeat SessionActive avec la durée actuelle et réenregistre le minuteur.
- Fin de session (GameEnd) : un événement de fin arrive et correspond à la session active. Le pipeline émet un SessionEnd avec la durée finale et efface l'état.
- Expiration de session (GameSessionTimeout) : le minuteur se déclenche et la durée calculée dépasse un maximum configurable. Au lieu d'émettre un heartbeat, le pipeline émet un SessionEnd avec un motif d'expiration et nettoie l'état.
Pourquoi Spark avec le Real-Time Mode change la donne
Spark Structured Streaming en mode micro-batch peut gérer la sessionisation avec état, mais lorsque le cas d'usage exige une précision inférieure à la seconde pour le traitement des entrées et les sorties déclenchées par minuteur, le mode micro-batch montre ses limites. Par le passé, cette lacune poussait les équipes à gérer un moteur spécialisé supplémentaire ou à concevoir des solutions sur mesure.
Avec Apache Flink : la gestion de l'état et les minuteurs peuvent être implémentés, mais adopter Flink signifie adopter tout un écosystème parallèle : un cluster distinct, un backend d'état, un modèle de déploiement, une pile de surveillance et une base de code, le tout aux côtés de la plateforme Databricks. Il en résulte une fragmentation de l'infrastructure, une complexité opérationnelle et le coût d'exploitation et de dotation en personnel d'un second moteur de streaming.
Avec des solutions internes sur mesure : certaines équipes conçoivent leur propre service de sessionisation, par exemple un système d'acteurs basé sur Akka où chaque appareil dispose d'un acteur qui gère l'état de la session, les minuteurs et l'émission de heartbeats. Ces solutions entraînent la même surcharge infrastructurelle et opérationnelle que Flink, avec un défi supplémentaire : elles ne passent pas à l'échelle. Distribuer des millions d'acteurs avec état sur plusieurs nœuds est une tâche que vous devez concevoir vous-même. Ces systèmes fonctionnent au départ, mais finissent avec le temps en mode maintenance : assez stables pour fonctionner, mais difficiles à faire évoluer.
Aujourd'hui, le Real-Time Mode comble cette lacune pour les clients, en offrant une précision inférieure à la seconde avec les mêmes API Spark que les équipes utilisent déjà, le tout dans un seul moteur unifié.
Le Real-Time Mode avec transformWithState
transformWithState est un opérateur de nouvelle génération dans Spark Structured Streaming qui rend le traitement avec état complexe flexible et évolutif. Les fonctionnalités clés incluent la gestion d'état orientée objet, les types de données composites, la logique pilotée par minuteur, la prise en charge automatique du TTL et l'évolution des schémas. Associé au Real-Time Mode, il offre une précision inférieure à la seconde pour le traitement des entrées et les sorties déclenchées par minuteur.
Le cas d'usage de la sessionisation de jeu exige deux choses :
- Un traitement réactif : gérer les débuts et fins de session au fur et à mesure de leur arrivée.
- Une sortie proactive : générer un heartbeat pour chaque session active selon un calendrier planifié, indépendamment des données entrantes.
transformWithState offre ces deux fonctionnalités dans une seule classe StatefulProcessor avec deux méthodes dédiées.
handleInputRows() réagit aux événements Kafka entrants, en traitant les débuts et fins de session et en maintenant l'état de sessionisation au fur et à mesure de l'arrivée des événements.
handleExpiredTimer() gère tout ce qui se passe entre-temps, en se déclenchant pour produire des sorties proactives telles que des heartbeats et des expirations, que de nouvelles données soient arrivées ou non.
Comment ça marche : concevoir un pipeline de sessionisation de jeu en temps réel
Présentation de l'architecture du pipeline
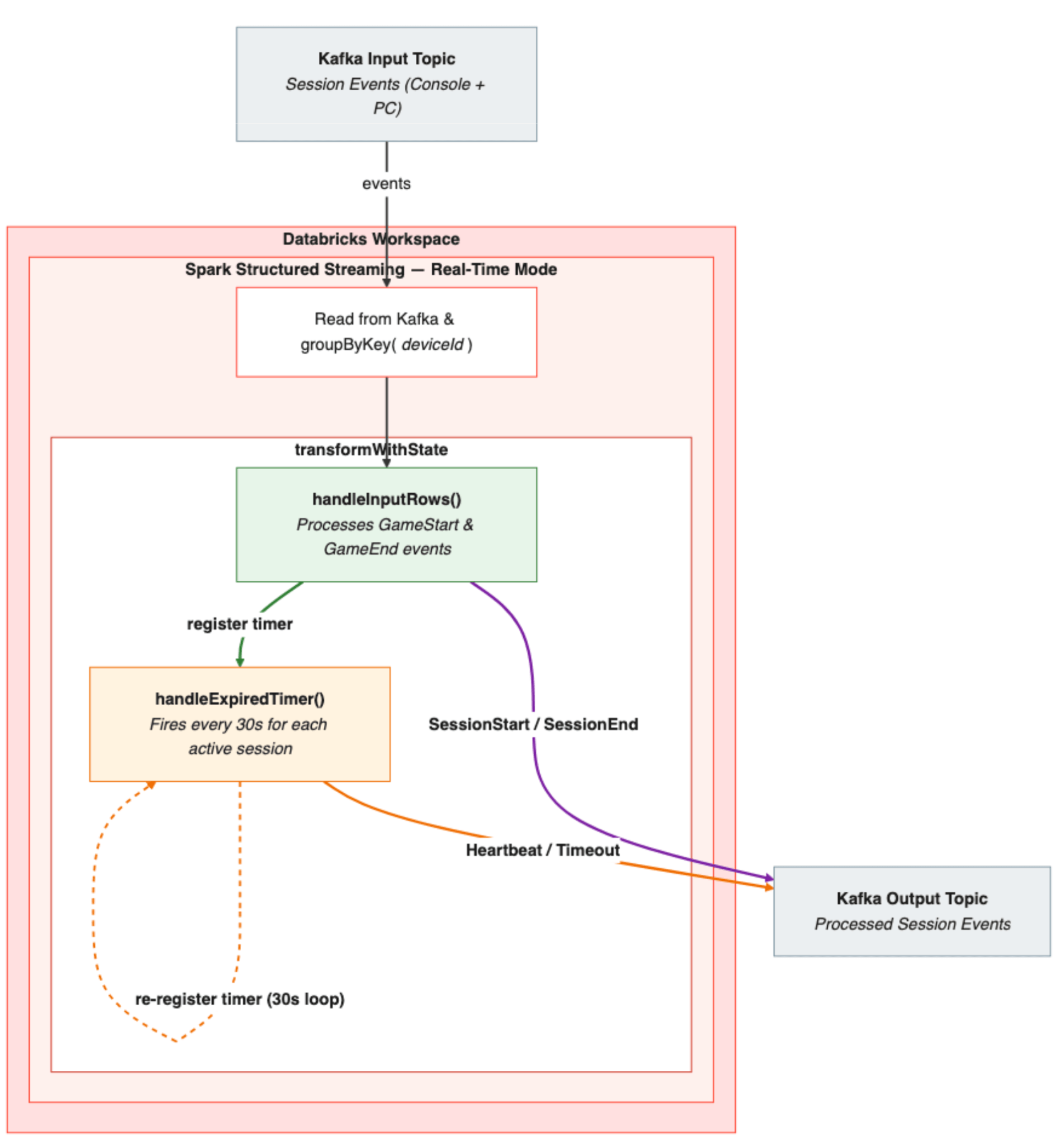
- Ingestion d'événements : les événements de session (débuts et fins) provenant des consoles et des PC arrivent sur des topics Kafka. Chaque événement est analysé et un deviceId est dérivé de l'identifiant spécifique à l'appareil.
- Regroupement avec état : le flux est regroupé par deviceId, ce qui garantit que tous les événements d'un appareil donné sont acheminés vers la même instance de processeur avec état.
- Traitement : transformWithState applique le processeur de sessionisation, qui utilise un MapState indexé par ID de session pour suivre la session active par appareil. Lorsqu'un début de session arrive, handleInputRows() stocke l'état de la session, émet un événement SessionActive et enregistre le premier minuteur de 30 secondes. À partir de ce moment, handleExpiredTimer() prend le relais, émettant des heartbeats toutes les 30 secondes et vérifiant les expirations. Lorsqu'un événement de fin de session arrive, handleInputRows() le récupère, émettant un SessionEnd avec la durée finale, effaçant l'état et arrêtant la boucle du minuteur.
- Sortie : les événements de session traités (débuts, heartbeats, fins et expirations) sont écrits au format JSON dans un topic Kafka de sortie, prêts à être consommés en aval.
Analyse approfondie de l'implémentation
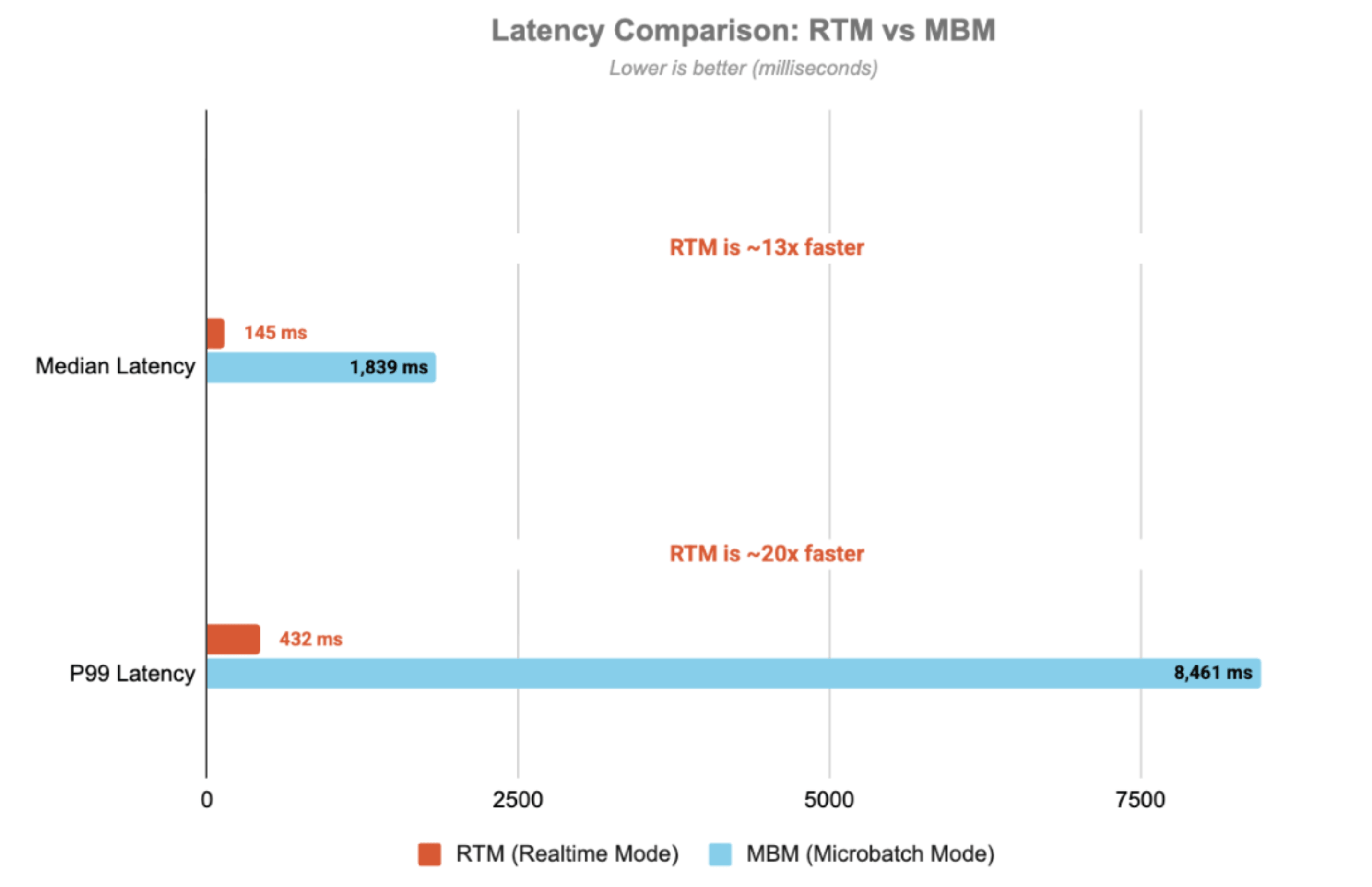
Pour une présentation détaillée de l'architecture, de l'implémentation du code et des considérations de production, consultez ce blog complémentaire , où nous détaillons le code de StatefulProcessor, le cycle de vie des minuteurs, les modèles de gestion d'état et la surveillance avec StreamingQueryListener. Les résultats suivants illustrent les caractéristiques de débit et de latence du pipeline, mettant en évidence les différences de latence significatives entre le mode micro-batch (MBM) et le Real-Time Mode (RTM) :
Débit
Pour valider le pipeline sous une charge réaliste, nous l'avons testé avec le débit soutenu suivant :
Métrique (par minute) | Valeur |
Événements d'entrée (débuts + fins de session) | ~500 k |
Nombre de sessions actives | ~4 M |
Enregistrements de heartbeat émis | ~8 M |
Amplification entrée-sortie | ~16x |
La grande majorité des sorties n'est pas déclenchée par les données entrantes : elle est entièrement générée par handleExpiredTimer(), qui émet de manière proactive des heartbeats selon un calendrier planifié.
Latence
La latence est mesurée de bout en bout, de l'horodatage du topic Kafka d'entrée à l'horodatage du topic de sortie. Avec le Real-Time Mode, le pipeline atteint une latence p99 de 432 ms, soit 20 fois plus rapide que le mode micro-batch.
Conclusion
Les cas d'usage comme la sessionisation de jeux nécessitent des pipelines qui vont au-delà du traitement des événements entrants — émission proactive de heartbeats de manière planifiée, suivi de millions de sessions simultanées et gestion efficace de l'état. Ce modèle ne se limite pas aux jeux. Tout cas de charge nécessitant des sorties déclenchées par timer — heartbeats IoT, suivi de sessions, alertes en temps réel, surveillance d'équipements — peut être conçu de la même manière.
Les timers dans transformWithState rendent cela possible. Une seule classe StatefulProcessor gère l'intégralité du cycle de vie de la session — le traitement réactif des entrées et la génération proactive de sorties déclenchées par timer. Associé au Real-Time Mode, les enregistrements d'entrée sont traités et les timers se déclenchent avec une précision inférieure à la seconde — pas lors du prochain intervalle de micro-lot (micro-batch), mais immédiatement. Le tout au sein de Databricks, sans moteur secondaire.
Si vous exécutez déjà des pipelines Structured Streaming en mode micro-batch et que vous envisagez un second moteur pour obtenir une latence plus faible, essayez d'abord le Real-Time Mode. Le passage de l'un à l'autre se fait par un simple changement de déclencheur (trigger) — pas de réécriture, pas de changement de plateforme :
Essayez par vous-même :
- Notebook d'accompagnement avec générateur de données : exécutez le pipeline complet de sessionisation de jeux et comparez vous-même la latence entre MBM et RTM.
- Guide de l'API transformWithState : variables d'état, timers, TTL et évolution du schéma
- Référence du Real-Time Mode : opérateurs pris en charge, modes d'exécution, sources, sinks et langages compatibles
Le Real-Time Mode est désormais en disponibilité générale.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.