Présentation du mode temps réel dans Apache Spark™ Structured Streaming
Traitez les événements en quelques millisecondes grâce au nouveau déclencheur en temps réel de Spark
par Jerry Peng, Siying Dong, Abhay Bothra, Fatih Emekci, Karthikeyan Ramasamy, Navneeth Nair, Indrajit Roy, Matt Jones, Craig Lukasik et Ryan Nienhuis
- Traitement en flux en millisecondes : Spark Structured Streaming introduit le mode temps réel pour traiter les données en millisecondes, permettant une nouvelle classe d'applications à faible latence.
- Aucune réécriture requise : Les équipes peuvent activer le mode temps réel avec une simple modification de configuration — aucun replatforming ni refonte de code nécessaire.
- Maintenant en préversion publique : Disponible sur Databricks avec prise en charge des sources et sinks populaires ; idéal pour la détection de fraude, la personnalisation en direct et le service de caractéristiques ML.
Apache Spark™ Structured Streaming alimente depuis longtemps des pipelines critiques à grande échelle, de l'ETL en flux vers l'analytique quasi temps réel et le machine learning. Nous étendons maintenant cette capacité à une toute nouvelle classe de charges de travail avec le mode temps réel, un nouveau type de déclencheur qui traite les événements au fur et à mesure de leur arrivée, avec une latence de l'ordre de quelques dizaines de millisecondes.
Contrairement aux déclencheurs de micro-lots existants, qui traitent les données selon un calendrier fixe (déclencheur ProcessingTime) ou traitent toutes les données disponibles avant de s'arrêter (déclencheur AvailableNow), le mode temps réel traite les données en continu et émet les résultats dès qu'ils sont prêts. Cela permet des cas d'utilisation à latence ultra-faible tels que la détection de fraude, la personnalisation en direct et le service de caractéristiques de machine learning en temps réel, le tout sans modifier votre code existant ni revoir votre plateforme.
Ce nouveau mode est contribué à l'open source Apache Spark et est maintenant disponible en préversion publique sur Databricks.
Dans cet article, nous aborderons :
- Ce qu'est le mode temps réel et comment il fonctionne
- Les types d'applications qu'il permet
- Comment vous pouvez commencer à l'utiliser dès aujourd'hui
Qu'est-ce que le mode temps réel ?
Le mode temps réel offre un traitement continu à faible latence dans Spark Structured Streaming, avec des latences p99 aussi basses que quelques millisecondes. Les équipes peuvent l'activer avec une simple modification de configuration — aucune réécriture ni replatforming requis — tout en conservant les mêmes API Structured Streaming qu'elles utilisent aujourd'hui.
Comment fonctionne le mode temps réel
Le mode temps réel exécute des tâches de streaming de longue durée qui planifient les étapes de manière concurrente. Les données circulent entre les tâches en mémoire à l'aide d'un shuffle en streaming, ce qui :
- Réduit la surcharge de coordination
- Supprime les délais de planification fixes du mode micro-lot
- Offre des performances constantes inférieures à la seconde
Dans les tests internes de Databricks, les latences p99 variaient de quelques millisecondes à environ 300 ms, en fonction de la complexité des transformations :
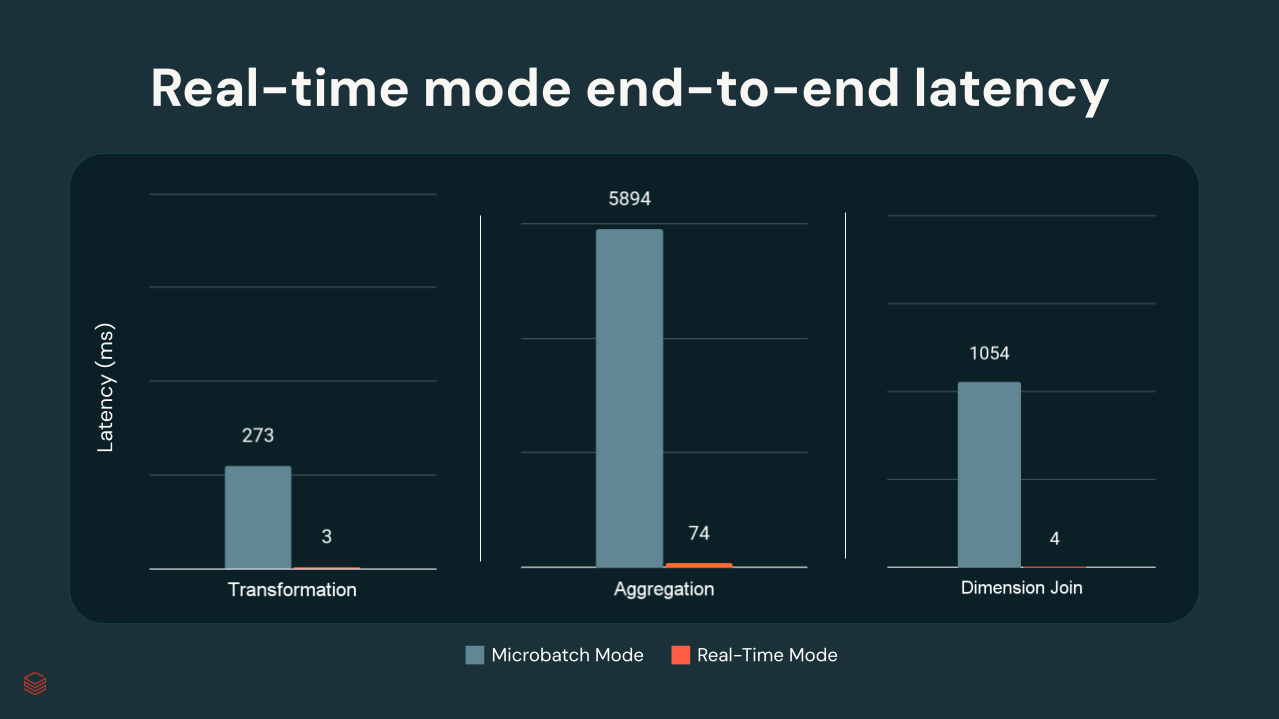
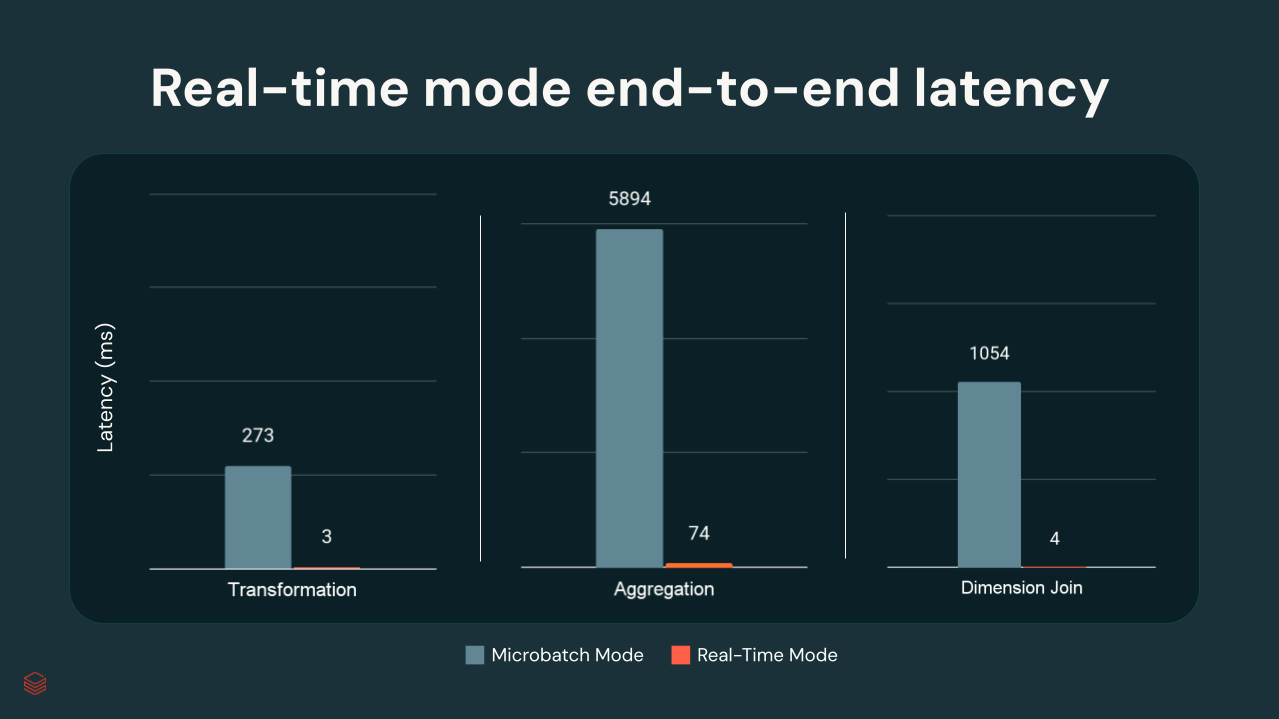{kind=link}
Applications et cas d'utilisation
Le mode temps réel est conçu pour les applications de streaming qui nécessitent un traitement à latence ultra-faible et des temps de réponse rapides, souvent dans le chemin critique des opérations commerciales.
Le mode temps réel dans Spark Structured Streaming a donné des résultats remarquables lors de nos premiers tests. Pour un pipeline d'autorisation de paiement critique, où nous effectuons le chiffrement et d'autres transformations, nous avons obtenu une latence de bout en bout P99 de seulement 15 millisecondes. Nous sommes optimistes quant à la mise à l'échelle de ce traitement à faible latence sur nos flux de données tout en respectant systématiquement des SLA stricts. —Raja Kanchumarthi, Lead Data Engineer, Network International

En plus du cas d'utilisation d'autorisation de paiement de Network International cité ci-dessus, plusieurs adopteurs précoces l'ont déjà utilisé pour alimenter un large éventail de charges de travail :
Détection de fraude dans les services financiers : Une banque mondiale traite les transactions par carte de crédit de Kafka en temps réel et signale les activités suspectes, le tout en moins de 200 millisecondes — réduisant le risque et le temps de réponse sans replatforming.
Expériences personnalisées dans le commerce de détail et les médias : Un fournisseur de streaming OTT met à jour les recommandations de contenu immédiatement après qu'un utilisateur a fini de regarder un spectacle. Une plateforme de commerce électronique de premier plan recalcule les offres de produits pendant que les clients naviguent — maintenant l'engagement élevé avec des boucles de rétroaction inférieures à la seconde.
État de session en direct et historique de recherche : Un site de voyage majeur suit et affiche les recherches récentes de chaque utilisateur en temps réel sur différents appareils. Chaque nouvelle requête met à jour le cache de session instantanément, permettant des résultats personnalisés et l'autocomplétion sans délai.
Service de caractéristiques ML en temps réel : Une application de livraison de nourriture met à jour des caractéristiques comme la localisation du conducteur et les temps de préparation en millisecondes. Ces mises à jour circulent directement dans les modèles de machine learning et les applications visibles par l'utilisateur, améliorant la précision des ETA et l'expérience client.
Ce ne sont là que quelques exemples. Le mode temps réel peut prendre en charge toute charge de travail qui bénéficie de la transformation des données en décisions en quelques millisecondes, des alertes de capteurs IoT et de la visibilité de la chaîne d'approvisionnement à la télémétrie de jeu en direct et à la personnalisation dans l'application.
Démarrer avec le mode temps réel
Le mode temps réel est maintenant disponible en préversion publique sur Databricks. Si vous utilisez déjà Structured Streaming, vous pouvez l'activer avec une seule configuration et une mise à jour du déclencheur — aucune réécriture requise.
Pour l'essayer dans DBR 16.4 ou une version ultérieure :
- Créez un cluster (nous recommandons le mode dédié) sur Databricks avec accès à la préversion publique.
Activez le mode temps réel en définissant la configuration suivante :
Utilisez le nouveau déclencheur dans votre requête :
Checkpointing
L'option trigger(RealTimeTrigger.apply(...)) active le nouveau mode d'exécution temps réel, vous permettant d'atteindre des latences de traitement inférieures à la seconde. RealTimeTrigger accepte un argument qui spécifie la fréquence à laquelle la requête effectue un checkpoint. Par exemple, trigger(RealTimeTrigger.apply(“x minutes”)) Par défaut, l'intervalle de checkpoint est de 5 minutes, ce qui convient à la plupart des cas d'utilisation. La réduction de cet intervalle augmente la fréquence des checkpoints, mais peut avoir un impact sur la latence. La plupart des sources et des sinks de streaming sont pris en charge, y compris Kafka, Kinesis et forEach pour écrire vers des systèmes externes.
Résumé
Le mode temps réel est idéal pour les cas d'utilisation qui exigent la latence la plus faible possible. Pour de nombreuses charges de travail analytiques, le mode micro-lot standard peut être plus rentable tout en répondant aux exigences de latence. Le mode temps réel introduit une légère surcharge système, nous recommandons donc de l'utiliser pour les pipelines critiques en termes de latence, tels que ceux décrits ci-dessus. La prise en charge de sources et de sinks supplémentaires s'étend, et nous travaillons activement à élargir la compatibilité et à réduire davantage la latence.
Pour plus de détails, veuillez consulter la documentation sur le mode temps réel pour les détails d'implémentation complets, les sources et sinks pris en charge, ainsi que des exemples de requêtes. Vous y trouverez tout ce dont vous avez besoin pour activer le nouveau déclencheur et configurer vos charges de travail de streaming.
Pour un aperçu plus large des nouveautés d'Apache Spark, y compris comment le mode temps réel s'inscrit dans l'évolution du moteur, regardez la keynote Spark de Michael Armbrust de DAIS 2025. Elle couvre les changements architecturaux derrière le prochain chapitre de Spark, avec le mode temps réel comme élément central de l'histoire.
Pour approfondir l'ingénierie derrière le mode temps réel, regardez notre session de plongée technique de nos ingénieurs, qui détaille la conception et l'implémentation.
Et pour voir comment le mode temps réel s'intègre dans la stratégie de streaming plus large sur Databricks, consultez le Guide complet du streaming sur la plateforme d'intelligence des données.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.