Dans les coulisses de Lakebase
Ramification du cycle de développement (Partie 1)
par Cameron Casher et Kevin Hartman
Pendant trente ans, la base de données opérationnelle et la base de données analytique ont été deux artefacts, deux plans de gouvernance, deux budgets et, généralement, deux rotations de garde, connectés par un travail ETL écrit à la hâte et que personne ne veut posséder. Cette séparation n'était pas un choix de conception ; c'était une contrainte physique. OLTP et OLAP avaient des structures de stockage, des profils de calcul et des modes de défaillance véritablement différents, nous avons donc construit deux plateformes et les avons connectées après coup.
Cette contrainte se dissout. Lorsque le stockage est partagé, le calcul est sans serveur et isolé par charge de travail, et la gouvernance réside au niveau du catalogue, "opérationnel" et "analytique" cessent d'être des catégories architecturales pour devenir des modèles d'accès à la même base.
Pour tester si cela était réellement vrai en pratique, nous avons pris Backstage, le portail développeur interne de Spotify notoirement gourmand en état, l'avons détaché de sa base de données Postgres standard et l'avons pointé vers Databricks Lakebase. Tout au long de cette série en trois parties, nous explorerons ce qui arrive aux cycles de déploiement (Partie 1), à la gouvernance (Partie 2) et à FinOps (Partie 3) lorsque vous abaissez le mur entre l'application opérationnelle et la plateforme de données.
La Configuration : Pointer Backstage vers Lakebase
Lakebase expose une surface Postgres sans serveur (tirant parti de l'architecture de Neon en arrière-plan) qui réside dans la plateforme Databricks. Parce qu'il parle le protocole Postgres, Backstage ne sait pas et ne se soucie pas qu'il ne communique pas avec RDS.
Pour le connecter, il a fallu pointer app-config.yaml vers Lakebase et remplacer la recherche en mémoire par défaut de Backstage par PgSearchEngine. Un obstacle immédiat : Lakebase rejette les jetons d'accès personnels Databricks classiques, attendant un OAuth JWT à la place. La CLI fournit databricks postgres generate-database-credential qui génère un JWT limité et de courte durée pour un point de terminaison spécifique, l'approche prévue pour les applications et la CI. Pour ce POC, nous avons encapsulé cette commande dans un script cron léger qui réécrivait le DATABRICKS_TOKEN dans notre fichier .env toutes les 50 minutes pour gérer l'expiration du jeton.
Une fois l'authentification résolue, les migrations Knex se sont déroulées sans problème et le portail était opérationnel.
Le Branchement Modifie le Cycle de Développement de la Base de Données
La chose la plus sous-estimée dans un Postgres traditionnel n'est pas son ensemble de fonctionnalités ; c'est le tempo qu'il impose aux équipes qui le possèdent.
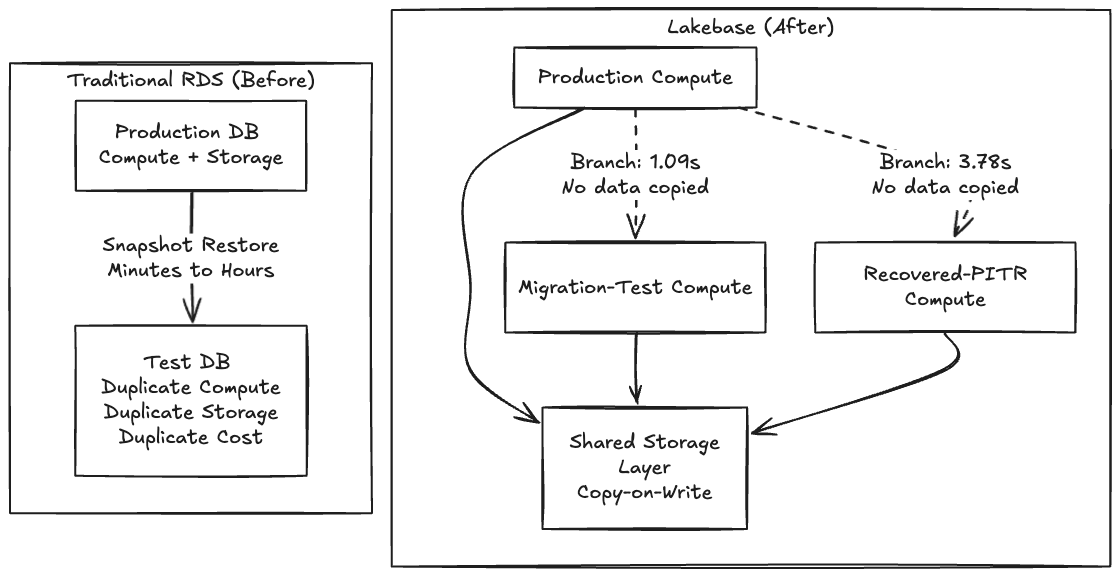
Thoughtworks a été un défenseur constant de Backstage en tant que fondation d'IDP à travers le Technology Radar, donc en plus d'être très familier avec l'outil, nous avons choisi Backstage pour ce POC car ses migrations de schéma sont notoirement fragiles et cela semblait être une opportunité parfaite pour tester une intégration Lakebase. Sur RDS traditionnel, tester une migration risquée signifie attendre des minutes ou des heures qu'un instantané soit restauré dans une instance parallèle. Parce que faire une copie est lent et coûteux, les équipes ne testent tout simplement pas. Elles croisent les doigts et exécutent la migration lors d'une fenêtre de maintenance.
Lorsque la création d'une copie devient gratuite, vous arrêtez de demander "ce changement est-il suffisamment sûr pour être exécuté ?" et commencez à demander "quelle branche de production veux-je essayer en premier ?"
Parce que Lakebase sépare le stockage du calcul à l'aide d'une architecture copy-on-write, la création d'une branche ne copie aucune donnée, elle crée un pointeur vers les mêmes pages sous-jacentes, et ne diverge qu'à l'écriture. C'est pourquoi l'opération est instantanée.
Une petite difficulté que la documentation ne rend pas évidente : le corps de la requête doit imbriquer tout à l'intérieur d'un objet spec, et vous devez spécifier ttl, expire_time, ou no_expiry. Sans cela, l'API renvoie "Expiration must be specified."
Le plan de contrôle l'a reconnu instantanément. La copie réelle du catalogue Backstage d'environ 63 Mo sur le plan de données a atterri en 1,09 seconde.
Récupération à un Instant Donné : Le Bouton Annuler
Le branchement et la récupération à un instant donné (PITR) sont essentiellement le même primitif : le branchement est juste PITR avec source_branch_time = now. Pour tester la récupération sur des données réellement supprimées, nous avons vidé notre table final_entities, faisant passer le compte de 32 à 0.
Nous avons ensuite créé une branche de récupération à partir d'un horodatage capturé quelques secondes avant la suppression :
Le temps écoulé de bout en bout était de 3,78 secondes.
La vérification des données a confirmé que la branche récupérée contenait les 32 entités ; la production était toujours à zéro, confirmant que la suppression était réelle et que les branches sont entièrement isolées. Notamment, nous avons demandé 22:56:02Z, mais Lakebase s'est aligné sur 22:55:50Z, 12 secondes plus tôt, en revenant au dernier enregistrement WAL. Cette granularité au niveau WAL est une mise en garde importante pour les flux de récupération sensibles au temps, mais le cycle d'incident s'est tout de même déroulé en moins d'une minute.
Lorsque l'état de la base de données devient un artefact bon marché et facile à cloner au lieu d'un volume EBS de 2 To, chaque opération risquée obtient un essai à blanc, et chaque incident obtient une annulation.
De la Capacité d'Infrastructure au Flux de Travail du Développeur
Comme montré ci-dessus, cela prouve que le branchement de base de données fonctionne – une copie en 1 seconde, une récupération en 4 secondes, et une application réelle qui ne fait pas la différence. Mais il y a un fossé entre "la base de données peut se brancher" et "mon équipe branche la base de données aussi naturellement qu'elle branche du code." Combler ce fossé est là où l'impact massif sur la productivité des développeurs peut être réalisé en gains objectifs.
Nous avons passé les derniers mois à travailler avec des équipes de développement pour répondre à une question spécifique : qu'arrive-t-il à la vélocité d'une équipe lorsque le branchement de base de données devient invisible – lorsqu'il ne s'agit pas d'une commande CLI que l'on exécute, mais de quelque chose qui se produit automatiquement dans le cadre de ce que vous faites déjà dans votre éditeur de choix ? Des travaux sont en cours sur une extension VS Code/Cursor qui synchronise automatiquement les branches git et de base de données pour le prouver -- mais l'outillage est secondaire par rapport à ce qu'il permet.
Ce que le Branchement Permet
D'après les équipes avec lesquelles nous avons eu de l'expérience, le cycle de sprint sans branchement de base de données ressemble à ceci :
- Créer une branche git pour le développement de fonctionnalités
- Écrire des objets mock pour chaque interface de base de données (MockUserRepository, MockOrderService...) à des fins de test
- Écrire des tests unitaires avec une base de données mockée ou en mémoire (H2, SQLite)
- Soumettre une PR, la faire réviser et fusionner le code
- Déployer sur un environnement de staging partagé
- Découvrir que la migration de schéma ne fonctionne pas avec des données réelles ou que la taille des données est un blocage
- Corriger la migration de schéma, redéployer, répéter
Avec la disponibilité de la fonctionnalité de branchement de base de données, le cycle de développement des fonctionnalités d'un développeur change :
- Créez une branche Git – une branche de base de données Lakebase peut être créée automatiquement en moins d'une seconde
- Votre IDE se connecte immédiatement à la base de données de la branche réelle
- Écrivez du code et exécutez des migrations sur des données de base de données réelles et en direct dès la première ligne de code
- Écrivez des tests d'intégration sur la base de données réelle – pas des mocks de base de données
- Plusieurs solutions peuvent être expérimentées, car le retour arrière des modifications de la base de données est trivial
- Poussez et ouvrez une PR – CI crée sa propre branche de base de données, valide le code et le schéma, publie un diff de schéma
- Les membres de l'équipe QA peuvent obtenir leur propre branche de base de données pour des tests destructeurs – peut être réinitialisée en quelques secondes
- Fusionnez – Une fois fusionné, le pipeline CD peut migrer les environnements en amont comme UAT et la production et nettoyer toutes les branches – code et données.
Les objets mock disparaissent. Les collisions de staging disparaissent. Le problème "ça marche sur ma machine mais ça casse en staging" disparaît, les développeurs obtiennent une base de données en direct pour essayer plusieurs solutions. Les modifications de la base de données qui étaient auparavant découvertes au déploiement sont maintenant détectées pendant le développement, où elles sont peu coûteuses à corriger. Des branches instantanées pour les tests de performance, des branches jetables et isolées pour les tests fonctionnels et une branche de travail pour les parties prenantes UAT deviennent triviales.
D'après notre expérience avec plusieurs équipes partenaires évaluant ce flux de travail, les objets mock représentent 20 à 30 % du code de test. Ce n'est pas une couverture de test – c'est une infrastructure de test. Une infrastructure qui diverge du comportement de production au fil du temps, créant une fausse confiance. Lorsque le branchement d'une base de données équivalente à la production ne coûte rien, le mocking devient le choix coûteux.
La question est maintenant de savoir combien de votre sprint vous consacrez à des solutions de contournement pour une contrainte qui n'existe plus.
Dans la deuxième partie de cette série, nous examinerons ce qu'il advient de la sécurité et de la conformité lorsque cette base de données opérationnelle est intégrée directement à Unity Catalog, la couche de gouvernance unifiée de Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.